利用Python+opencv+TensorFlow框架打造 一个试卷批改系统
本文编程采用Python语言,结合opencv库对图像进行处理,再利用TensorFlow框架下卷积神经网络 实现一个初步的简易试卷批改系统。
实现一个试卷批改系统,我将它主要分成俩个模块,第一个模块是图像识别,第二个模块是利用机器学习训练模型。
先说我们是如何训练模型的,对于一般的图像分类问题,利用卷积神经网络是一个不错的选择,卷积神经网络在图像分类的应用十分广泛,具体代码如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets('MNIST_data',one_hot=True)#下载mnist数据集
def compute_accuracy(v_xs,v_ys):
global prediction#定义全局变量
y_pre=sess.run(prediction,feed_dict={xs:v_xs,keep_prob:1})#
correct_prediction=tf.equal(tf.argmax(y_pre,1),tf.argmax(v_ys,1))#将实际值和预测值进行比较,返回Bool数据类型
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#将上面的bool类型转为float,求得矩阵中所有元素的平均值
result=sess.run(accuracy,feed_dict={xs:v_xs,ys:v_ys,keep_prob:1})#运行得到上面的平均值,这个值越大说明预测的越准确,因为都是0-1类型,所以平均值不超过1
return result
def weight_variable(shape):
initial=tf.truncated_normal(shape,stddev=0.1)#这个函数产生的随机数与均值的差距不会超过两倍的标准差
return tf.Variable(initial,dtype=tf.float32,name='weight')
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial,dtype=tf.float32,name='biases')
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')#strides第一个和第四个都是1,然后中间俩个代表x方向和y方向的步长,这个函数用来定义卷积神经网络
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
xs=tf.placeholder(tf.float32,[None,784])#输入是一个28*28的像素点的数据
ys=tf.placeholder(tf.float32,[None,10])
keep_prob=tf.placeholder(tf.float32)
x_image=tf.reshape(xs,[-1,28,28,1])#xs的维度暂时不管,用-1表示,28,28表示xs的数据,1表示该数据是一个黑白照片,如果是彩色的,则写成3
#卷积层1
W_conv1=weight_variable([5,5,1,32])#抽取一个5*5像素,高度是32的点,每次抽出原图像的5*5的像素点,高度从1变成32
b_conv1=bias_variable([32])
h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)#输出 28*28*32的图像
h_pool1=max_pool_2x2(h_conv1)##输出14*14*32的图像,因为这个函数的步长是2*2,图像缩小一半。
#卷积层2
W_conv2=weight_variable([5,5,32,64])#随机生成一个5*5像素,高度是64的点,抽出原图像的5*5的像素点,高度从32变成64
b_conv2=bias_variable([64])
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)#输出14*14*64的图像
h_pool2=max_pool_2x2(h_conv2)##输出7*7*64的图像,因为这个函数的步长是2*2,图像缩小一半。
#fully connected 1
W_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64])#将输出的h_pool2的三维数据变成一维数据,平铺下来,(-1)代表的是有多少个例子
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
#fully connected 2
W_fc2=weight_variable([1024,10])
b_fc2=bias_variable([10])
prediction=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)#输出层
#开始训练数据
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))#相当于loss(代价函数)
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)#训练函数,降低cross_entropy(loss),AdamOptimizer适用于大的神经网络
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(10000):
batch_xs,batch_ys=mnist.train.next_batch(250)#每次从mnist数据集里面拿100个数据训练
sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys,keep_prob:0.5})
if i%100==0:
print(compute_accuracy(mnist.test.images,mnist.test.labels))
save_path = saver.save(sess, "my_net/save_net.ckpt)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
测试下我们训练的准确率情况:训练10000次,每隔100次打印一次,最后的训练准确率大概是99%左右。
代码中使用的是mnist手写数字数据集,将图像分成10个类别,分别代表数字0-9,训练好的模型保存在my_net/save_net.ckpt里面,文件格式是.ckpt。
下一步工作是如何调用训练的模型。调用模型的方法很简单,首先需要重构一个和训练集一样的神经网络架构,注意这里不需要再训练数据了,直接调用模型就可以了,然后输入和mnist数据集相同格式的图片就能实现数字识别。如下代码 是如何重构模型以及调用模型的方法。(注意在保存和调用模型的代码中均有saver.restore(sess, “my_net/save_net.ckpt”)这段代码,唯一不同的是,保存代码用的是saver.save(sess, “my_net/save_net.ckpt”),调用代码用的是saver.restore(sess, “my_net/save_net.ckpt”)。)
import tensorflow as tf
import cv2
from PIL import Image
import numpy as np
def weight_variable(shape):
initial=tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial,dtype=tf.float32,name='weight')
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial,dtype=tf.float32,name='biases')
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
xs=tf.placeholder(tf.float32,[None,784])#输入是一个28*28的像素点的数据
keep_prob=tf.placeholder(tf.float32)
x_image=tf.reshape(xs,[-1,28,28,1])#xs的维度暂时不管,用-1表示,28,28表示xs的数据,1表示该数据是一个黑白照片,如果是彩色的,则写成3
#卷积层1
W_conv1=weight_variable([5,5,1,32])#抽取一个5*5像素,高度是32的点,每次抽出原图像的5*5的像素点,高度从1变成32
b_conv1=bias_variable([32])
h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)#输出 28*28*32的图像
h_pool1=max_pool_2x2(h_conv1)##输出14*14*32的图像,因为这个函数的步长是2*2,图像缩小一半。
#卷积层2
W_conv2=weight_variable([5,5,32,64])#随机生成一个5*5像素,高度是64的点,抽出原图像的5*5的像素点,高度从32变成64
b_conv2=bias_variable([64])
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)#输出14*14*64的图像
h_pool2=max_pool_2x2(h_conv2)##输出7*7*64的图像,因为这个函数的步长是2*2,图像缩小一半。
#fully connected 1
W_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64])#将输出的h_pool2的三维数据变成一维数据,平铺下来,(-1)代表的是有多少个例子
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
#fully connected 2
W_fc2=weight_variable([1024,10])
b_fc2=bias_variable([10])
prediction=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)#输出层
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess, "my_net/save_net.ckpt")
result= tf.argmax(prediction, 1)
#result= result.eval(feed_dict={xs:img, keep_prob: 1.0}, session=sess)
result=sess.run(prediction, feed_dict={xs:img,keep_prob: 1.0})
result1 =np.argmax(result,1)
print(result1)
# result = sess.run(prediction, feed_dict={x: data})
# print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
接下来我们来做一个测试,测试图片如下: 
对于上面的图片,我们先对图像进行一系列处理,让它符合我们的格式,代码如下:
import tensorflow as tf
import cv2
from PIL import Image
import numpy as np
img = cv2.imread("D:\\opencv_camera\\digits\\10.jpg")
res=cv2.resize(img,(28,28),interpolation=cv2.INTER_CUBIC)
#cv2.namedWindow("Image")
#print(img.shape)
#灰度化
emptyImage3=cv2.cvtColor(res,cv2.COLOR_BGR2GRAY)
cv2.imshow("a",emptyImage3)
cv2.waitKey(0)
#二值化
ret, bin = cv2.threshold(emptyImage3, 140, 255,cv2.THRESH_BINARY)
cv2.imshow("a",bin)
cv2.waitKey(0)
print(bin)
def normalizepic(pic):
im_arr = pic
im_nparr = []
for x in im_arr:
x=1-x/255
im_nparr.append(x)
im_nparr = np.array([im_nparr])
return im_nparr
#print(normalizepic(bin))
img=normalizepic(bin).reshape((1,784))
#print(img)
img= img.astype(np.float32)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
灰度化的图片如下: 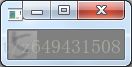
二值化的图片如下: 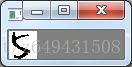
然后调用模型结果如下: 
结果是5,预测准确。
上面的是做测试结果,关于试卷识别,我们有下面的例子,图片如下: 
对这个图片我们要做的是提取方框内的分数,然后识别出来数字,进行统计,最后得出分数总和,保存起来,这就是整体思路。具体操作代码如下:
import numpy as np
import tensorflow as tf
import cv2
from PIL import Image
from skimage import data, util,measure,color
from skimage.measure import label
image = cv2.imread('D:\opencv_camera\digits\\12.jpg')
lower=np.array([50,50,150])
upper=np.array([140,140,250])
mask = cv2.inRange(image, lower, upper)
output1 = cv2.bitwise_and(image, image, mask=mask)
output=cv2.cvtColor(output1,cv2.COLOR_BGR2GRAY)
th2 = cv2.adaptiveThreshold(output,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,0)
# cv2.imshow("images",th2)
# cv2.waitKey(0)
roi=[]
for i in range(8):
img_roi = output1[260:310,35+55*i:80+58*i]
roi.append(img_roi)
#归一化
def normalizepic(pic):
im_arr = pic
im_nparr = []
for x in im_arr:
x=1-x/255
im_nparr.append(x)
im_nparr = np.array([im_nparr])
return im_nparr
########图片预处理##########
def weight_variable(shape):
initial=tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial,dtype=tf.float32,name='weight')
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial,dtype=tf.float32,name='biases')
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
xs=tf.placeholder(tf.float32,[None,784])#输入是一个28*28的像素点的数据
keep_prob=tf.placeholder(tf.float32)
x_image=tf.reshape(xs,[-1,28,28,1])#xs的维度暂时不管,用-1表示,28,28表示xs的数据,1表示该数据是一个黑白照片,如果是彩色的,则写成3
#卷积层1
W_conv1=weight_variable([5,5,1,32])#抽取一个5*5像素,高度是32的点,每次抽出原图像的5*5的像素点,高度从1变成32
b_conv1=bias_variable([32])
h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)#输出 28*28*32的图像
h_pool1=max_pool_2x2(h_conv1)##输出14*14*32的图像,因为这个函数的步长是2*2,图像缩小一半。
#卷积层2
W_conv2=weight_variable([5,5,32,64])#随机生成一个5*5像素,高度是64的点,抽出原图像的5*5的像素点,高度从32变成64
b_conv2=bias_variable([64])
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)#输出14*14*64的图像
h_pool2=max_pool_2x2(h_conv2)##输出7*7*64的图像,因为这个函数的步长是2*2,图像缩小一半。
#fully connected 1
W_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64])#将输出的h_pool2的三维数据变成一维数据,平铺下来,(-1)代表的是有多少个例子
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
#fully connected 2
W_fc2=weight_variable([1024,10])
b_fc2=bias_variable([10])
prediction=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)#输出层
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess, "my_net/save_net.ckpt")
result= tf.argmax(prediction, 1)
SUM=[]
for i in range(8):
output = cv2.cvtColor(roi[i], cv2.COLOR_BGR2GRAY)
th2 = cv2.adaptiveThreshold(output, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 0)
# cv2.imshow("images", th2)
# cv2.waitKey(0)
labels = label(th2, connectivity=2)
dst = color.label2rgb(labels)
a=[]
for region in measure.regionprops(labels):
minr, minc, maxr, maxc = region.bbox
# img = cv2.rectangle(dst, (minc -10 , minr - 10), (maxc + 10, maxr + 10), (0, 255, 0), 1)
ROI = th2[minr - 2:maxr + 2, minc - 2:maxc + 2]
if ROI.shape[1] < 10:
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))
ROI = cv2.erode(ROI, kernel, iterations=1)
ret, thresh2 = cv2.threshold(ROI, 0, 255, cv2.THRESH_BINARY_INV)
res = cv2.resize(thresh2, (28, 28), interpolation=cv2.INTER_CUBIC)
cv2.imshow("images", res)
cv2.waitKey(0)
img = normalizepic(res).reshape((1, 784))
img = img.astype(np.float32)
result=sess.run(prediction, feed_dict={xs:img,keep_prob: 1.0})
result1 =np.argmax(result,1)
print(result1)
a.append(result1)
if len(a)==2:
#print(a[1]*10+a[0])
SUM.append(a[1]*10+a[0])
else:
#print(a[0])
SUM.append(a[0])
print(sum(SUM))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
将最后的结果保存在列表中,得出结果。整个代码写到这里基本上就完成了,在图像处理过程中,需要掌握opencv的一些具体的操作,包括图像二值化,特定区域ROI提取,在对图像进行分割的时候用到了skimage库,这个库可以对不同连通区域的图像进行分割,非常方便实用。整个过程还存在一些问题需要完善,包括对于粘连的数字如何处理,之前查过一篇文献光学手写数字字符识别技术的研究,里面提到了一种用水滴法分割粘连字符,整个识别过程还存在一些不足,后续还有很大的改善空间。