机器学习1:k 近邻算法
k近邻算法(k-Nearest Neighbors, k-NN)是一种常用的分类和回归算法。它基于一个简单的假设:如果一个样本的k个最近邻居中大多数属于某一类别,那么该样本也很可能属于这个类别。

k近邻算法的步骤如下:
- 输入:训练集(包含已知类别的样本)和待分类样本。
- 计算待分类样本与训练集中所有样本之间的距离(常用的距离度量方法包括欧氏距离、曼哈顿距离等)。
- 选择距离待分类样本最近的k个样本作为邻居。
- 根据这k个邻居的类别标签,确定待分类样本的类别:如果有多数样本属于A类,那么待分类样本也归为A类;如果多数样本属于B类,那么待分类样本则归为B类。
- 输出:待分类样本的类别。
k近邻算法的主要特点包括:
- 简单易实现:算法主要基于距离计算和多数表决,概念和原理较直观。
- 非参数化学习:算法不对数据的分布做任何假设,因此适用于各种类型的数据。
- 适应性强:算法可以根据具体问题和数据特点选择合适的距离度量方法和邻居个数k。
在实际应用中,可以通过交叉验证等方法选择合适的k值和距离度量方法,以获得更好的分类效果。k近邻算法被广泛应用于模式识别、图像处理、推荐系统等领域。

欧氏距离(Euclidean Distance)是指在数学上计算两个点之间的距离的一种方法。对于二维平面上的两个点,它是通过计算这两个点的坐标差的平方和的平方根得到的。
假设有两个点A(x1, y1)和B(x2, y2),欧氏距离的计算公式如下:
d = sqrt((x2 - x1)^2 + (y2 - y1)^2)
其中,sqrt表示平方根,^ 表示乘方操作。
欧氏距离的特点是:
- 能够度量空间中两点之间的直线距离。
- 距离越小,表示两点越接近;距离越大,表示两点越远离。
- 欧氏距离可以应用于任意维度的数据,不仅仅局限于二维平面。
在机器学习和模式识别等领域,欧氏距离常用于聚类、分类以及特征匹配等任务中,通过比较样本之间的距离来进行相似性度量或分类判定。
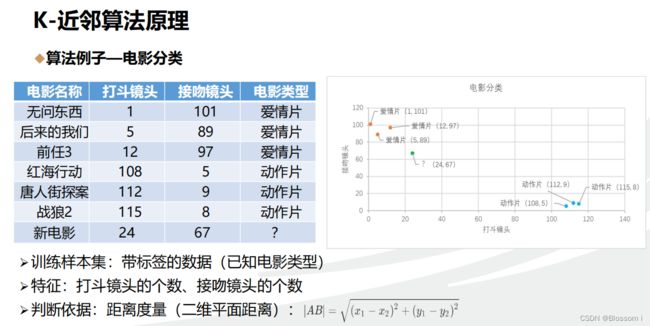
曼哈顿距离(Manhattan Distance),也称为城市街区距离或L1距离,是计算两个点之间的距离的一种度量方法。它得名于曼哈顿的城市规划布局,因为在曼哈顿城市街区中,要从一个十字路口到达另一个十字路口,只能沿着网格状的街道走,而不能直线穿越建筑物。
对于二维平面上的两个点A(x1, y1)和B(x2, y2),曼哈顿距离的计算公式如下:
d = |x2 - x1| + |y2 - y1|
其中 |x| 表示取 x 的绝对值。
曼哈顿距离的特点是:
- 它衡量的是沿着网格状路径从一个点到另一个点所需的步数。
- 曼哈顿距离忽略了直线距离,而关注了水平和垂直方向上的距离差异。
- 曼哈顿距离适用于需要考虑路径限制的问题,比如机器人导航、城市交通等领域。
曼哈顿距离不仅可以应用于二维平面,还可以推广到更高维的情况。在机器学习和数据挖掘领域,曼哈顿距离常用于聚类、分类和特征选择等任务中,用于衡量样本之间的相似性或者特征之间的差异。
举例:假设有一个二维坐标系,点A的坐标是(1, 3),点B的坐标是(4, 6)。现在我们要计算点A和点B之间的曼哈顿距离。
曼哈顿距离的计算公式是:d = |x2 - x1| + |y2 - y1|
根据这个公式,我们可以计算出点A和点B之间的曼哈顿距离为:
d = |4 - 1| + |6 - 3| = 3 + 3 = 6
这意味着,从点A移动到点B,沿着水平和垂直方向上的总移动步数是6。可以把曼哈顿距离看作是通过直角路径从一个点到达另一个点所需的最小步数。
将这个理解为在一个城市的街道上行走,曼哈顿距离衡量的是你只能沿着街道走的情况下,从一个地点到另一个地点所需的最短距离。在这个例子中,我们需要向右移动3个单位,向上移动3个单位,即水平方向上的距离差为3,垂直方向上的距离差为3,总步数为6。
棋盘距离(Chebyshev Distance),也称为切比雪夫距离或L∞距离,是计算两个点之间的距离的一种度量方法。它得名于俄罗斯数学家切比雪夫,他首先引入了这个概念。
对于二维平面上的两个点A(x1, y1)和B(x2, y2),
棋盘距离的计算公式如下:d = max(|x2 - x1|, |y2 - y1|)
其中 |x| 表示取 x 的绝对值。
棋盘距离的特点是:
- 它衡量的是沿着网格状路径从一个点到另一个点所需的最少步数。
- 棋盘距离忽略了直线距离,而只考虑水平和垂直方向上的距离差异。
- 棋盘距离适用于仅允许水平、垂直和对角行走的问题,比如在棋盘上移动、机器人导航等领域。
棋盘距离不仅可以应用于二维平面,还可以推广到更高维的情况。在图像处理、路径规划、聚类等领域,棋盘距离常用于衡量像素之间的差异、计算路径的最短距离,或者作为一种距离度量方法进行数据分析和模式识别。
假设我们有一个5x5的棋盘,棋盘上的每个格子表示一个点。现在我们要计算点A(2, 3)和点B(4, 1)之间的棋盘距离。
首先,我们可以通过观察两个点在棋盘上的位置,发现它们可以通过沿着网格状路径移动到达:
在这个路径中,我们可以看到我们需要向右移动两步,向下移动两步,即水平方向上的距离差为2,垂直方向上的距离差也为2。
根据棋盘距离的计算公式 d = max(|x2 - x1|, |y2 - y1|),我们可以取水平方向和垂直方向上距离差的最大值作为最终的棋盘距离。在这个例子中,最大值是2,所以点A和点B之间的棋盘距离就是2。
这个例子展示了棋盘距离的特点,它只考虑水平和垂直方向上的距离差异,并忽略了直线距离。在这个例子中,虽然两点之间的直线距离是√10≈3.16,但棋盘距离只计算了步数,即2步。

综合作业课后题
1. 假设有以下训练数据集,每个样本有两个特征(x1, x2)和对应的类别标签
(y):

现在给定一个测试样本 (6, 4),使用 k 近邻算法进行分类,其中 k=5。请
计算该测试样本的类别。
1) 请简述 k 近邻算法的算法步骤
2) 现在给定一个测试样本 (6, 4),使用 k 近邻算法进行分类,其中 k=5。
分别使用欧氏距离、曼哈顿距离和棋盘距离来计算测试样本与训练样本
之间的距离,并观察它们对最终分类结果的影响。
- k近邻算法的步骤如下:
- 计算测试样本与训练数据集中所有样本之间的距离
- 选择k个距离最近的样本,即为k个邻居
- 根据这k个邻居的类别标签,确定测试样本的类别:如果有多数样本属于A类,那么测试样本也归为A类;如果多数样本属于B类,那么测试样本则归为B类。
2.计算方法及分类结果如下:
使用欧氏距离来计算距离:
样本1:sqrt((3-6)^2 + (5-4)^2) ≈ 3.16,A类
样本2:sqrt((4-6)^2 + (2-4)^2) ≈ 2.83,A类
样本3:sqrt((7-6)^2 + (3-4)^2) ≈ 1.41,B类
样本4:sqrt((9-6)^2 + (6-4)^2) ≈ 3.61,B类
样本5:sqrt((5-6)^2 + (8-4)^2) ≈ 4.12,A类
样本6:sqrt((2-6)^2 + (6-4)^2) ≈ 4.47,B类
从上面的分类结果可以看出,欧氏距离将测试样本分类成了A类。
使用曼哈顿距离来计算距离:
样本1:|3-6| + |5-4| = 4,A类
样本2:|4-6| + |2-4| = 4,A类
样本3:|7-6| + |3-4| = 2,B类
样本4:|9-6| + |6-4| = 5,B类
样本5:|5-6| + |8-4| = 5,A类
样本6:|2-6| + |6-4| = 4,B类
从上面的分类结果可以看出,曼哈顿距离将测试样本分类成了A类。
使用棋盘距离来计算距离:
样本1:max(|3-6|, |5-4|) = 3,A类
样本2:max(|4-6|, |2-4|) = 2,A类
样本3:max(|7-6|, |3-4|) = 1,B类
样本4:max(|9-6|, |6-4|) = 3,B类
样本5:max(|5-6|, |8-4|) = 4,A类
样本6:max(|2-6|, |6-4|) = 4,B类
从上面的分类结果可以看出,棋盘距离也将测试样本分类成了A类。
综上所述,使用这三种距离计算方式,最终测试样本都被归类为A类。