王道数据结构课代表 - 考研数据结构 第六章 图 究极精华总结笔记
本篇博客是考研期间学习王道课程 传送门 的笔记,以及一整年里对数据结构知识点的理解的总结。希望对新一届的计算机考研人提供帮助!!!
关于对图章节知识点总结的十分全面,涵括了《王道数据结构》课程里的全部要点(本人来来回回过了三遍视频),其中还陆陆续续补充了许多内容,所以读者可以相信本篇博客对于考研数据结构“图”章节知识点的正确性与全面性;
但如果还有自主命题的学校,还需额外读者自行再观看对应学校的自主命题材料。
数据结构与算法笔记导航
- 第一章 绪论
(无)- 第二章 线性表
- 第三章 栈和队列
- 第四章 串-KMP(看毛片算法)
- 第五章 树和二叉树
- 第六章 图
⇦当前位置- 第七章 查找(B树、散列表)
- 第八章 排序 (内部排序:八大排序动图演示与实现 + 外部排序)
数据结构与算法 复试精简笔记 (未完成)- 408 全套初复试笔记汇总 传送门
如果本篇文章对大家起到帮助的话,跪求各位帅哥美女们,
求赞 、求收藏 、求关注!
你必考上研究生!我说的,耶稣来了也拦不住!

精准控时:
如果不实际操作代码,只是粗略过一下知识点,需花费 80 分钟左右过一遍
这个80分钟是我在后期冲刺复习多次尝试的时间,可以让我很好的在后期时间紧张的阶段下,合理分配复习时间;
但是刚开始看这份博客的读者也许会因为知识点陌生、笔记结构不太了解,花费许多时间,这都是正常的。
重点!!!学习一定要多总结多复习!重复、重复、再重复!!!
食用说明书:
第一遍学习王道课程时,我的笔记只有标题和截图,后来复习发现看只看图片,并不能很快的了解截图中要重点表达的知识点。
所以再第二遍复习中,我给每一张截图中标记了重点,以及每张图片上方总结了该图片对应的知识点以及自己的思考。
最后第三遍,查漏补缺。
所以 ,我把目录放在博客的前面,就是希望读者可以结合目录结构去更好的学习知识点,之后冲刺复习阶段脑海里可以浮现出该知识结构,做到对每一个知识点熟稔于心!
请读者放心!目录展示的知识点结构是十分合理的,可以放心使用该结构去记忆学习!
注意(⊙o⊙)!,每张图片上面的文字,都是该图对应的知识点总结,方便读者更快理解图片内容。
第6章 图
文章目录
- 第6章 图
-
- @[toc]
- 6.1 图的基本概念
-
- 6.1.1 基本概念
-
- 1.无向图和有向图
- 2.简单图、多重图
- 3.顶点的度、入度、出度
- 4.顶点-顶点的关系描述
- 5.连通图、强连通图
- 6.子图、生成子图
- 7.连通分量、强连通分量 - 极大连通
- 8.生成树、生成森林 - 极小连通
- 9.边的权、带权图/网
- 6.1.2 几种特殊的图
-
- 1.无向完全图和有向完全图
- 2.稀疏图和稠密图
- 3.树
- 6.1.3 小结
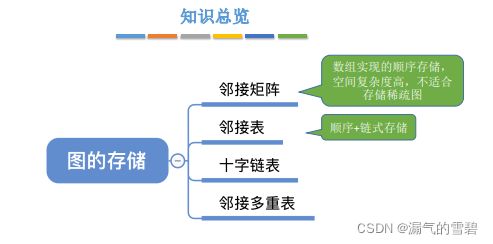
- 6.2 图的存储以及基本操作 P218
-
- 6.2.1 邻接矩阵(Adjacency Matrix)
-
- 1.算法思想
- 2.代码实现
- 3.性能分析 - 优缺点
- 4.邻接矩阵的性质
- 5.小结
- 6.2.2 邻接表(Adjacency List)
-
- 1.算法思想
- 2.代码实现
- 3.性能分析 - 优缺点
- 4.邻接矩阵对比邻接表
- 5.小结
- 6.2.3 十字链表(Orthogonal List)
-
- 1.算法思想
- 2.代码实现
- 3.性能分析
- 6.2.4 邻接多重表
-
- 1.算法思想
- 2.性能分析
- 3.代码实现
- 4.十字链表和邻接多重表小结
- 6.2.5 图的基本操作
-
- 1.Adjacent
- 2.Neighbors
- 3.InsertVertex
- 4.DeleteVertex
- 5.AddEdge
- 6.RemoveEdge
- 7.FirstNeighbor
- 8.NextNeighbor
- 9.其它
- 10.小结
- 6.3 图的遍历
-
- 6.3.1 广度优先搜索
-
- 1.算法思想
- 2.代码实现
- 3.性能分析
- 4.广度优先生成树
- 5.小结
- 6.3.2 深度优先搜索
-
- 1.算法思想
- 2.代码实现
- 3.性能分析
- 4.练习
- 5.深度优先生成树、生成森林
- 6.小结
- 6.3.3 图的遍历和图的连通性
-
- 1.无向图情况
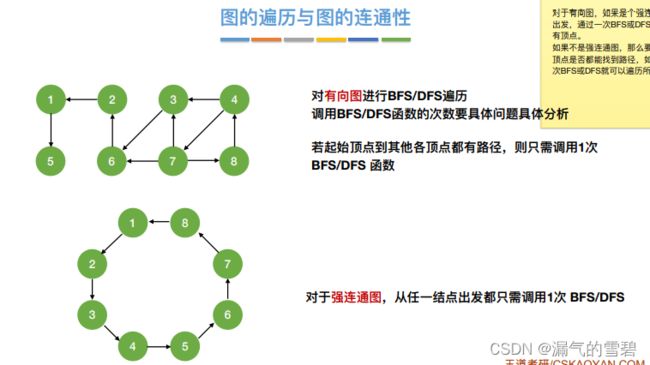
- 2.有向图情况
- 6.4 图的应用
-
- 6.4.1 最小生成树
-
- 1.定义
- 2.Prim算法
-
- 1)算法思想
- 2)性能分析
- 3)代码实现
- 3.Kruskal算法
-
- 1)算法实现
- 2)性能分析
- 3)代码实现
- 4.Prim和Kruskal小结
- 6.4.2 最短路径
-
- 1.概念
- 2.BFS算法
-
- 1)算法思想
- 2)代码实现
- 3)小结
- 3.Dijkstra算法
-
- 1)算法思想
- 2)性能分析
- 4.Floyd算法
-
- 1)算法思想
- 2)性能分析
- 3)代码实现
- 4)举例练习
- 5)小结
- 6.4.3 有向无环图描述表达式
-
- 1.有向无环图(DAG)
- 2.DAG描述表达式
- 3.构造DAG有向无环图
- 4.练习
- 6.4.4 拓扑排序
-
- 1.AOV网
- 2.拓扑排序
- 3.求拓扑排序算法思想
- 4.代码实现
- 5.性能分析
- 6.逆拓扑序列
- 7.小结
- 6.4.5 关键路径
-
- 1.AOE网
- 2.事件最早发生时间ve(k)
- 3、事件最迟发生时间vl(k)
- 4、活动最早开始时间e(i)
- 5、活动最迟开始时间l(i)
- 6、差额——时间余量
- 7.求关键路径算法思想
- 8.关键活动、关键路径的特性
- 9.具体代码实现(未全部实现)
- 10.小结
文章目录
- 第6章 图
-
- @[toc]
- 6.1 图的基本概念
-
- 6.1.1 基本概念
-
- 1.无向图和有向图
- 2.简单图、多重图
- 3.顶点的度、入度、出度
- 4.顶点-顶点的关系描述
- 5.连通图、强连通图
- 6.子图、生成子图
- 7.连通分量、强连通分量 - 极大连通
- 8.生成树、生成森林 - 极小连通
- 9.边的权、带权图/网
- 6.1.2 几种特殊的图
-
- 1.无向完全图和有向完全图
- 2.稀疏图和稠密图
- 3.树
- 6.1.3 小结
- 6.2 图的存储以及基本操作 P218
-
- 6.2.1 邻接矩阵(Adjacency Matrix)
-
- 1.算法思想
- 2.代码实现
- 3.性能分析 - 优缺点
- 4.邻接矩阵的性质
- 5.小结
- 6.2.2 邻接表(Adjacency List)
-
- 1.算法思想
- 2.代码实现
- 3.性能分析 - 优缺点
- 4.邻接矩阵对比邻接表
- 5.小结
- 6.2.3 十字链表(Orthogonal List)
-
- 1.算法思想
- 2.代码实现
- 3.性能分析
- 6.2.4 邻接多重表
-
- 1.算法思想
- 2.性能分析
- 3.代码实现
- 4.十字链表和邻接多重表小结
- 6.2.5 图的基本操作
-
- 1.Adjacent
- 2.Neighbors
- 3.InsertVertex
- 4.DeleteVertex
- 5.AddEdge
- 6.RemoveEdge
- 7.FirstNeighbor
- 8.NextNeighbor
- 9.其它
- 10.小结
- 6.3 图的遍历
-
- 6.3.1 广度优先搜索
-
- 1.算法思想
- 2.代码实现
- 3.性能分析
- 4.广度优先生成树
- 5.小结
- 6.3.2 深度优先搜索
-
- 1.算法思想
- 2.代码实现
- 3.性能分析
- 4.练习
- 5.深度优先生成树、生成森林
- 6.小结
- 6.3.3 图的遍历和图的连通性
-
- 1.无向图情况
- 2.有向图情况
- 6.4 图的应用
-
- 6.4.1 最小生成树
-
- 1.定义
- 2.Prim算法
-
- 1)算法思想
- 2)性能分析
- 3)代码实现
- 3.Kruskal算法
-
- 1)算法实现
- 2)性能分析
- 3)代码实现
- 4.Prim和Kruskal小结
- 6.4.2 最短路径
-
- 1.概念
- 2.BFS算法
-
- 1)算法思想
- 2)代码实现
- 3)小结
- 3.Dijkstra算法
-
- 1)算法思想
- 2)性能分析
- 4.Floyd算法
-
- 1)算法思想
- 2)性能分析
- 3)代码实现
- 4)举例练习
- 5)小结
- 6.4.3 有向无环图描述表达式
-
- 1.有向无环图(DAG)
- 2.DAG描述表达式
- 3.构造DAG有向无环图
- 4.练习
- 6.4.4 拓扑排序
-
- 1.AOV网
- 2.拓扑排序
- 3.求拓扑排序算法思想
- 4.代码实现
- 5.性能分析
- 6.逆拓扑序列
- 7.小结
- 6.4.5 关键路径
-
- 1.AOE网
- 2.事件最早发生时间ve(k)
- 3、事件最迟发生时间vl(k)
- 4、活动最早开始时间e(i)
- 5、活动最迟开始时间l(i)
- 6、差额——时间余量
- 7.求关键路径算法思想
- 8.关键活动、关键路径的特性
- 9.具体代码实现(未全部实现)
- 10.小结
6.1 图的基本概念
6.1.1 基本概念
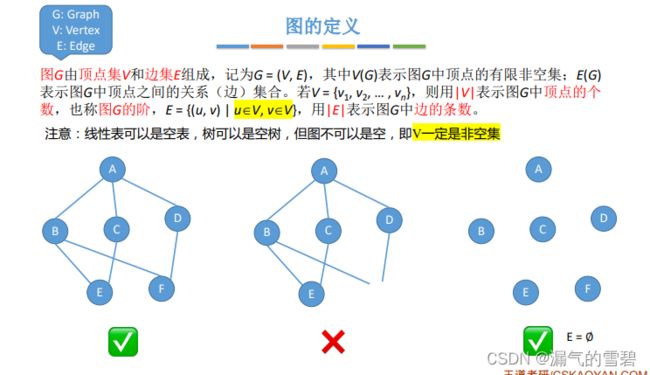
- 图G就是由 点集V 和 边集E 组成的。
- 点集不可以为空,边集可以为空。(一条边的两个点不能有一个为空)
- 图不可以是空图
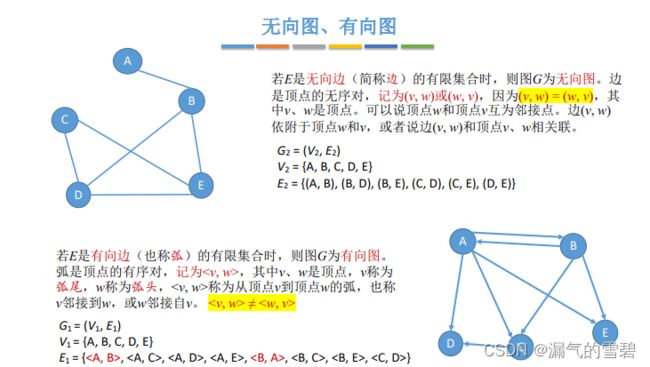
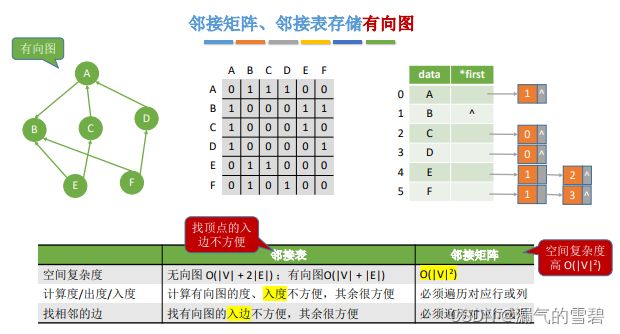
1.无向图和有向图
- 弧尾、弧头
- 有向边
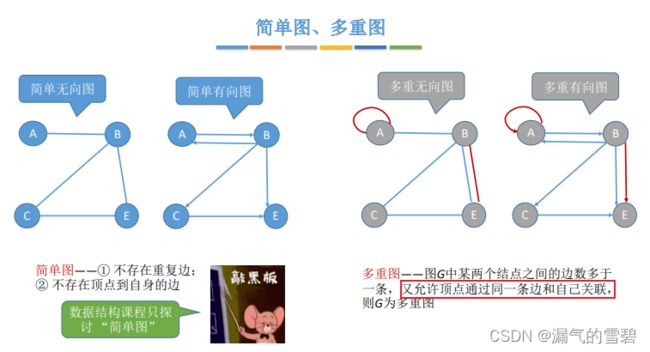
2.简单图、多重图
- 简单图:不存在重复的边
- 多重图:存在重复的边
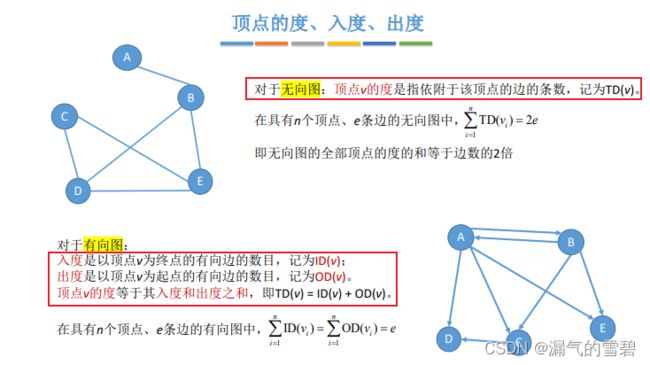
3.顶点的度、入度、出度
- 无向图
- 顶点的度
- 有向图
- 入度
- 出度
- 顶点的度 = 入度 + 出度
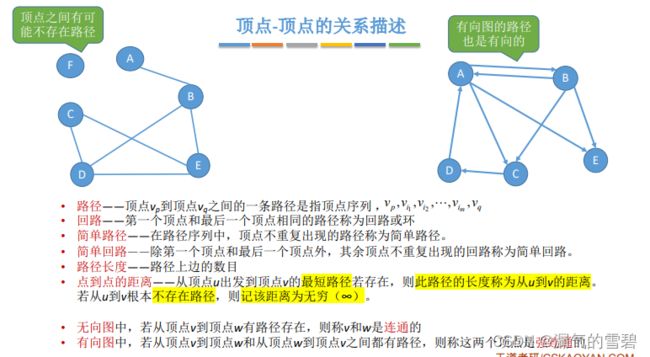
4.顶点-顶点的关系描述
- 路径:p --> … --> q
- 回路(环):特殊的路径(p --> … --> p)
- 简单路径:顶点不重复出现
- 简单回路:除了头顶点和尾顶点,其余顶点里不出现重复的顶点
- 路径长度:边的数目
- 点到点的距离:点到点的最短路径
- 连通性:无向图中,v — …— w (v,w之间是连通的)
- 强连通性:有向图中,既有v --> … --> w ,又有v <-- … <-- w,(v,w之间是强连通的)
5.连通图、强连通图
- 连通图:在无向图中,任意两个点连通
- 强连通图:在有向图中,任意两个点强连通
- 注意!强连通是指路径,并不是两点之间有直接相连来、回的箭头
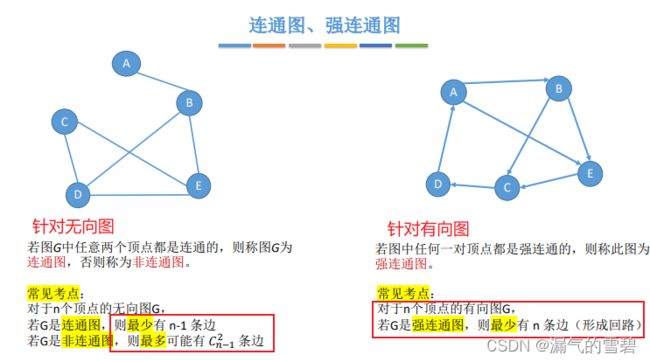
注意!!!
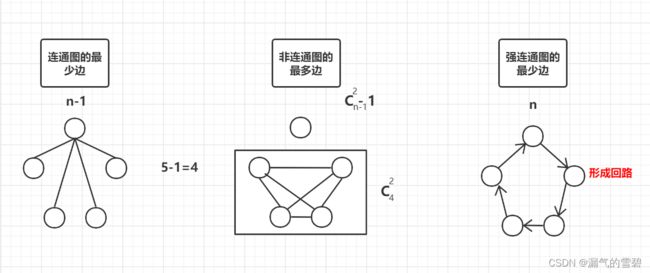
- 无向图中,连通图的最少边数,非连通图的最多边数
- 有向图中,强连通的最少边数
- 下面图里非连通图的最多便没有-1,写错了!!!
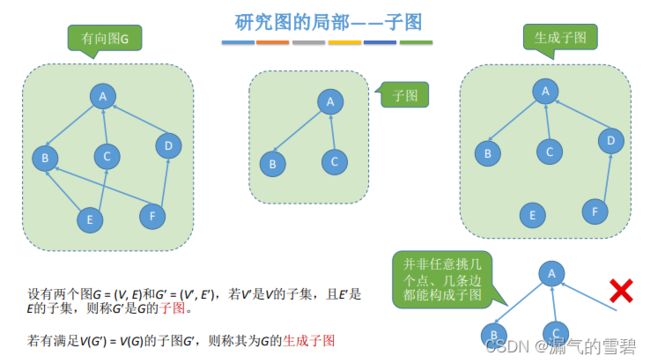
6.子图、生成子图
- 注意!子图虽然是 部分点集+部分边集,但是这些边、点都不是随便选的,一定要保证边的两个点存在
- 生成子图:子图包含原图的所有顶点,可以去掉一些边
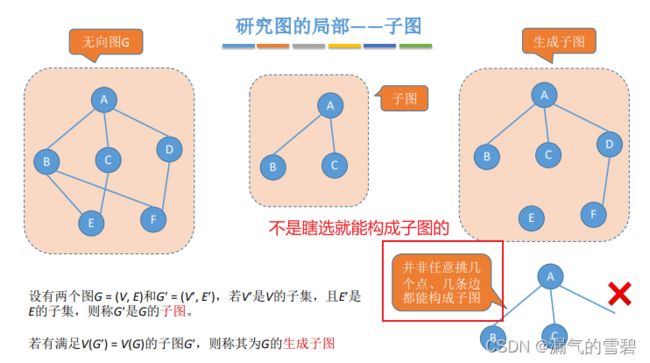
- 无向图的子图
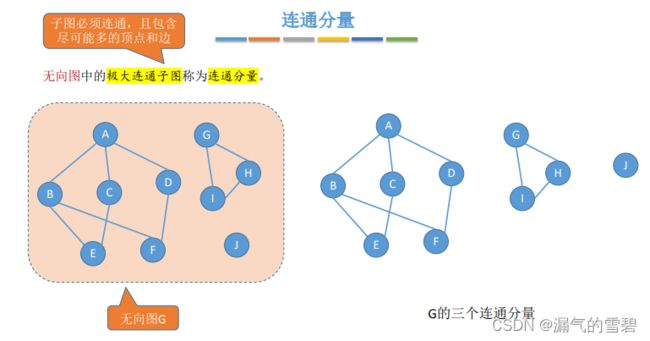
7.连通分量、强连通分量 - 极大连通
- 连通分量:在无向图中,极大的连通子图
- 1、子图
- 2、子图是连通的
- 3、极大:包含尽可能多的边和点
- 强连通分量:在有向图中,极大的强连通子图
- 注意对极大概念的体会

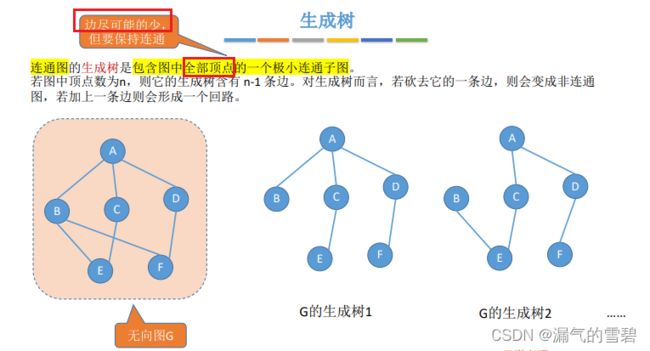
8.生成树、生成森林 - 极小连通
- 生成树:对于连通图,包含图中所有顶点的极小连通子图
- 1、针对于连通图,没有强连通图
- 2、所有顶点
- 3、极小连通子图(目前理解,保证在所有顶点和连通的前提之下,尽可能少边)
- 注意和生成子图做区别,生成子图只需要有全部顶点,而生成树还需要极小边
- 对于一个连通图的生成树不唯一
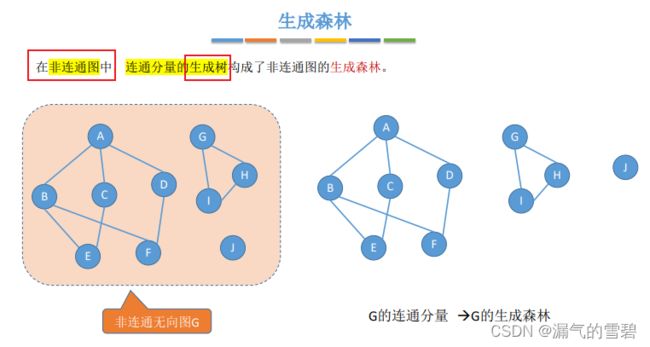
- 生成森林:对于非连通图,各连通分量的生成树组成了生成森林
9.边的权、带权图/网
- 权值:边的权
- 带权路径长度:路径上所有边的权值之和

6.1.2 几种特殊的图
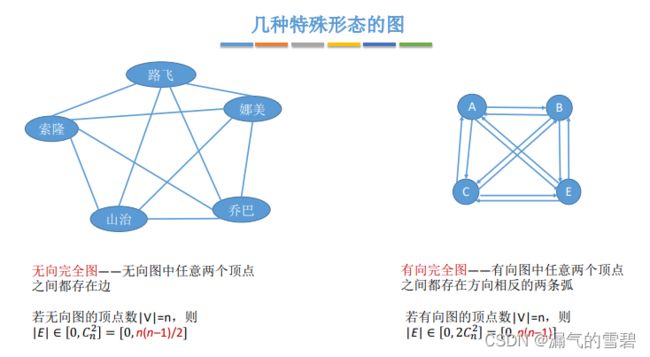
1.无向完全图和有向完全图
- 完全图:任意两个点之间存在直接连通的边
- 无向完全图:有n(n-1)/2条边
- 有向完全图:有n(n-1)条边
2.稀疏图和稠密图
-
稀疏图
e < nlogn
-
稠密图
3.树
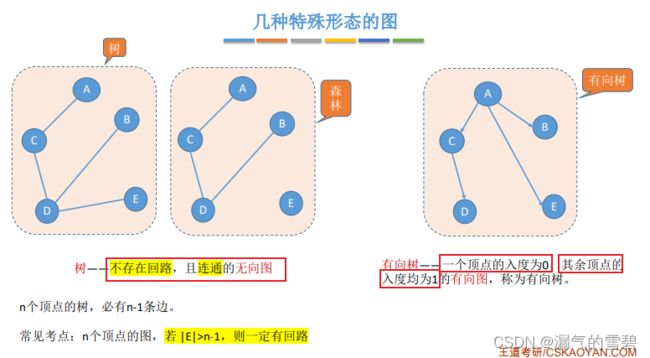
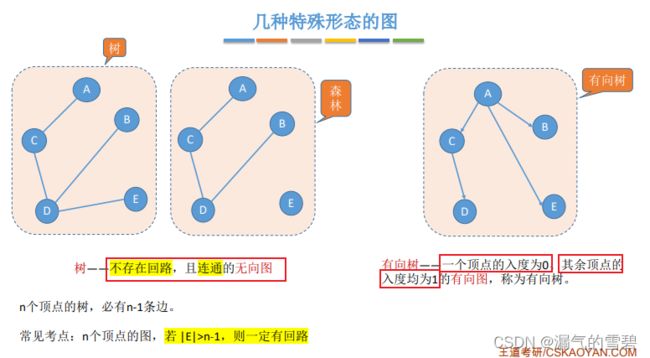
- 树:极小连通图,极大无环图。少一条边就不连通,多一条边就出现环
- n个顶点的树,其边数是n-1
- 所以,连通图要想存在回路,边的数目要大于n-1
- 注意!!!树是连通图,有向树不保证是强连通图
6.1.3 小结

6.2 图的存储以及基本操作 P218
6.2.1 邻接矩阵(Adjacency Matrix)
1.算法思想
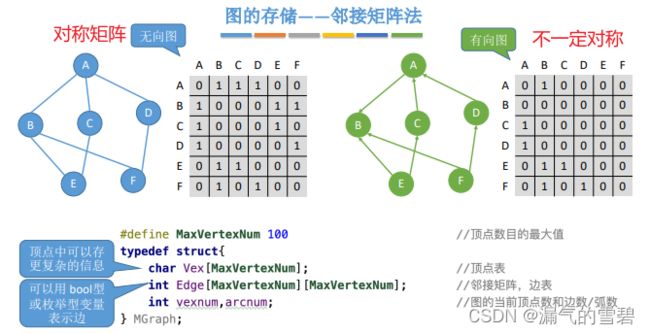
- 思考
- 1)计算顶点的度、入度、出度?
- 2)查找与顶点相连的边?
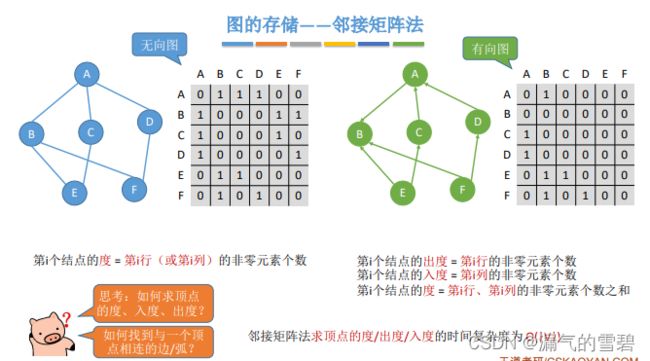
- 当使用邻接矩阵存储带权图时,需要注意的点!

2.代码实现
- 1)王道代码
// 邻接矩阵法
#define MAX_VERTEX_NUMBER 100 // 顶点数目的最大值
typedef struct
{
char vexter[MAX_VERTEX_NUMBER]; // 顶点表
int edge[MAX_VERTEX_NUMBER][MAX_VERTEX_NUMBER]; // 边表
int vexNum, arcNum; // 图的当前 顶点数 和 边数
} MGraph;
- 2)严蔚敏代码
#define VERTEX_MAX_SIZE 100 // 最大顶点数
#define MAXINIT 1024 // 表示最大值
typedef char VertexType; // 顶点的数据类型,假设为char
typedef int ArcType; // 边的数据类型,假设为int(权值)
typedef struct
{
VertexType vers[VERTEX_MAX_SIZE]; // 顶点表
ArcType arcs[VERTEX_MAX_SIZE][VERTEX_MAX_SIZE]; // 邻接矩阵
int verNum, arcNum; // 图当前的顶点数和边数
} AMGraph;
// 确定顶点ver在图G的顶点表中的位置
int LocateVex(AMGraph G, VertexType ver)
{
for (int i = 0; i < G.verNum; i++)
{
if (G.vers[i] == ver)
{
return i;
}
}
return -1; // ver不存在,返回-1
}
// 采用邻接矩阵创建图,该算法时间复杂度O(n^2)
bool CreateUDN(AMGraph &G)
{
int i, j, info, rows, columns;
VertexType v1, v2;
cin >> G.verNum >> G.arcNum; // 输入总顶点数、总边数
for (i = 0; i < G.verNum; i++)
{
cin >> G.vers[i]; // 依次输入顶点的信息
}
memset(G.arcs, MAXINIT, sizeof(G.arcs));
for (j = 0; j < G.arcNum; j++) // 构造邻接矩阵
{
cin >> v1 >> v2 >> info; // 输入一条边依附的顶点以及权值
rows = LocateVex(G, v1); // 确定v1、v2的位置
columns = LocateVex(G, v2);
G.arcs[rows][columns] = info;
G.arcs[columns][rows] = info;
}
return true;
}
- 以上两个版本,大差不差。严蔚敏的版本多了创建的操作。
3.性能分析 - 优缺点
- 空间复杂度:O(n)顶点表 + O(n^2)边表 = O(n^2)
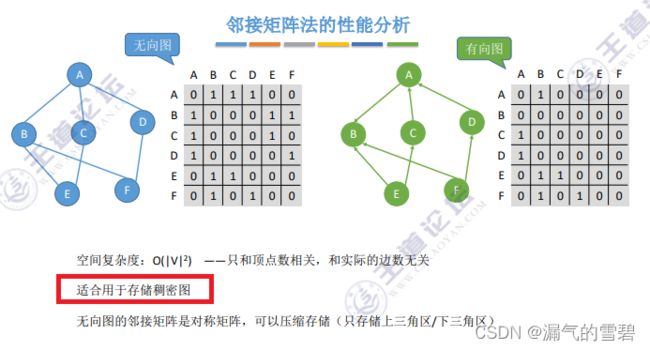
| 邻接矩阵 | 优点 | 缺点 |
|---|---|---|
| 1 | 判断两个顶点之间是否有边很方便 | 增加、删除顶点不方便 |
| 2 | 计算各点的度很方便 | 统计边的数量不方便 |
| 3 | 空间复杂度高,导致只适合存储稠密图 |
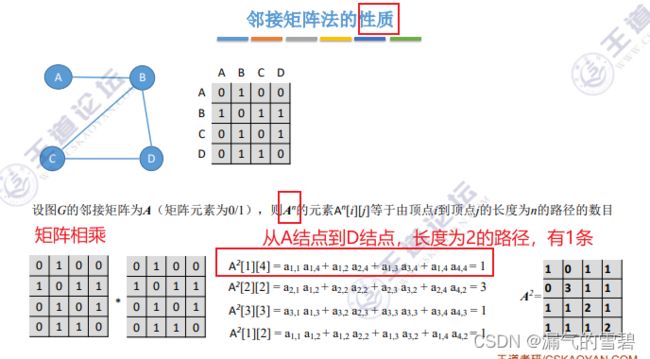
4.邻接矩阵的性质
- 分析下图红框的式子:
- a[1] [2] * a[2] [4] :
- ① a[1] [2]等于1,说明A到B存在边
- ② a[2] [4]等于1,说明B到D存在边
- ③ 所以乘积等于1,说明A到D之间存在路径,A–>B–>D
- 注意A^n里的n的含义,代表路径长度
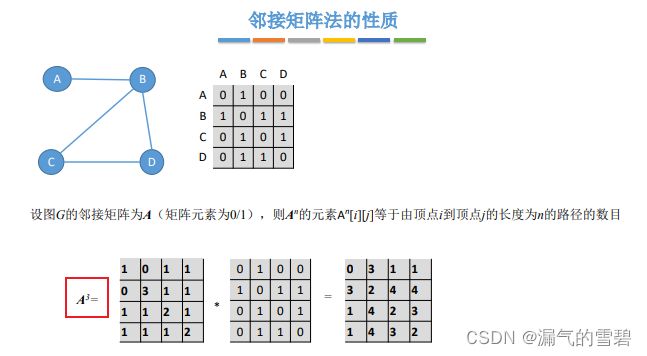
5.小结

6.2.2 邻接表(Adjacency List)
-
上一节提到的邻接矩阵法,空间复杂度高,不适合存储稀疏图
-
邻接表是图的一种链式存储结构,适用存储稀疏图
1.算法思想
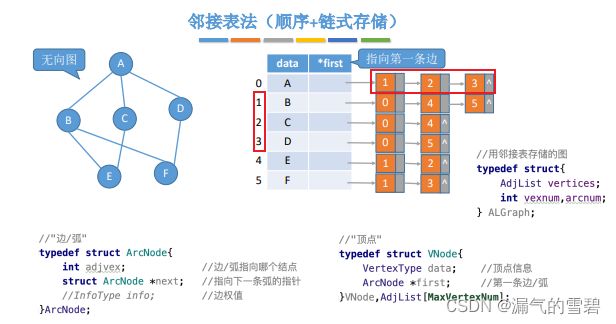
- 顺序存储点,链式存储边(顺点链边)
- **易混淆点!**虽然说是链式存储边,但是上面的边结构体里,只设置了一个顶点(端点),并不能很好的表示一条边
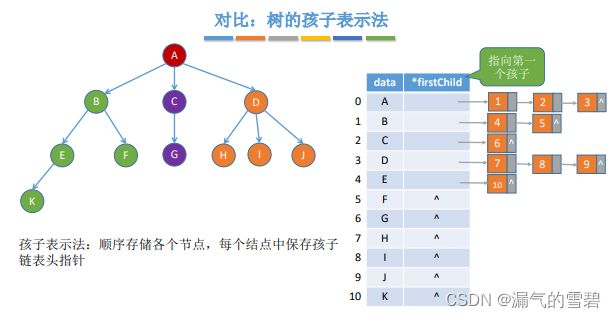
- 所以才和下面提到 “树的孩子表示法” 相似
- 这也造就了邻接表法存储无向图时,存储了冗余数据的缺陷,因为边结点不能很好的表示一条完整的边,故只能是私有的,无法共享(这几句话看不懂的话,等学习完邻接多重表再回来对比,就明白了)
2.代码实现
- 1)王道代码
// ? 邻接表法
#define MAX_VERTEX_NUMBER 100
// ! 弧
typedef struct ArcNode
{
int adjvex; // 弧指向哪个结点
struct ArcNode *next; // 指向下一条弧的指针
} ArcNode;
// ! 邻接表的顶点
typedef struct VNode
{
char data; // 顶点的信息
ArcNode *first; // 第一条弧
} VNode, AdjList[MAX_VERTEX_NUMBER];
// ! 使用邻接表存储的图
typedef struct
{
AdjList vertices;
int verNum, arcNum;
} ALGraph;
- 2)严蔚敏代码
- CreateUDN()函数的时间复杂度O(n^2)
3.性能分析 - 优缺点
- 正是上面提到的边结构体里只有一个点属性,所以在存储无向图时,多存储了一份边的数据(缺点1)
- 无向图:
- ① 空间复杂度:O(|V| + 2|E|)
- ② 找顶点的度:遍历该顶点的边链即可
- 有向图:
- ① 空间复杂度:O(|V| + |E|)
- ② 出度:遍历该顶点的边链即可
- ③ 入度(很麻烦):遍历所有结点的边链(缺点2)
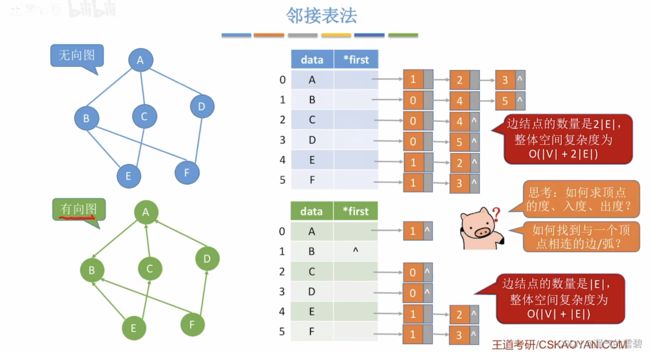
- 邻接表法里的边链的结点顺序不是唯一的(缺点3)
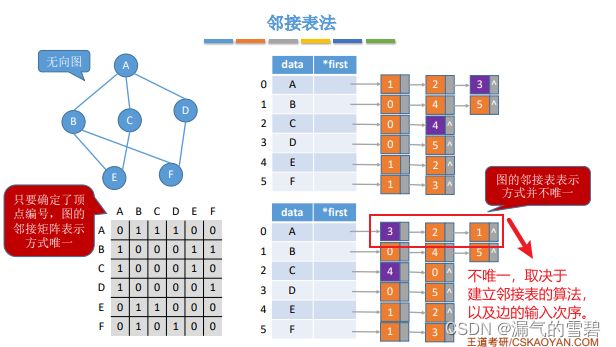
4.邻接矩阵对比邻接表
| 邻接矩阵 | 优点 | 缺点 |
|---|---|---|
| 1 | 判断两个顶点之间是否有边很方便 | 增加、删除顶点不方便 |
| 2 | 计算各点的度很方便 | 统计边的数量不方便O(n^2) |
| 3 | 空间复杂度高,导致只适合存储稠密图O(n^2) |
| 邻接表法 | 缺点 | 优点 |
|---|---|---|
| 1 | 判断顶点之间是否有边不方便 | 增加、删除顶点很方便 |
| 2 | 计算点的入度不方便 | 统计边的数目方便O(n+e) |
| 3 | 结点的链表顺序不唯一 | 空间效率高,适用于稀疏图O(n+e) |
| 4 | 无向图多了一份边的冗余数据 |
5.小结
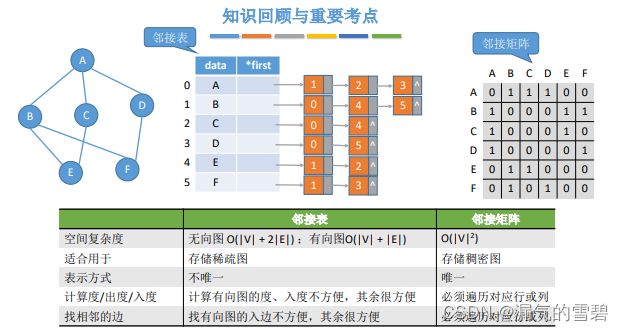
6.2.3 十字链表(Orthogonal List)
1.算法思想
- 1)之前两种存储方法的不足
- 2)十字链表法能够解决计算入度麻烦的不足
- 十字链表是有向图的另一种链式存储结构。可以看成是将有向图的邻接表和逆邻接表结合起来得到的一种链表
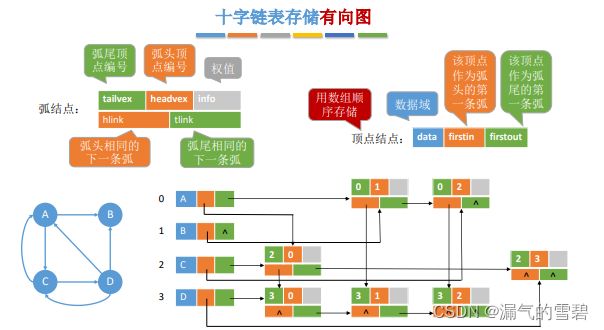
- 上图看不懂,可以看下代码,核心就是十字链表法的 “顶点和弧” 的结构都有了改变
- 顶点有了对入边和出边的分类
- 弧不仅设置两个顶点(两顶点不同)表示边,而且表示的是有向边。还有两个不同的弧结点指针
- 这样的设计就使得边达到了共享的效果,多个顶点可以指向同一条边,消除了邻接表里冗余数据的问题
- 所以,正是由于这样的点和弧的结构设计,使得十字链表法只适用于有向图
2.代码实现
- 1)王道代码
// ? 十字链表法
#define MAX_VERTEX_NUMBER 100
// ! 弧结点
typedef struct OLNode
{
int headVex; // 弧头顶点编号
int tailVex; // 弧尾顶点编号
int info; // 权值
struct OLNode *hLink; // 弧头顶点相同的下一条弧
struct OLNode *tLink; // 弧尾顶点相同的下一条弧
} OLNode;
// ! 十字链表的顶点
typedef struct VexNode
{
char data; // 顶点的信息
OLNode *firstIn; // 第一条以该顶点为弧头的弧
OLNode *firstOut; // 第一条以该顶点为弧尾的弧
} VexNode, CrossList[MAX_VERTEX_NUMBER];
// ! 使用邻接表存储的图
typedef struct
{
CrossList vertices;
int verNum, arcNum;
} OLGraph;
- 2)严蔚敏代码
- 建立十字链表的时间复杂度和建立邻接表的时间复杂度相同
3.性能分析
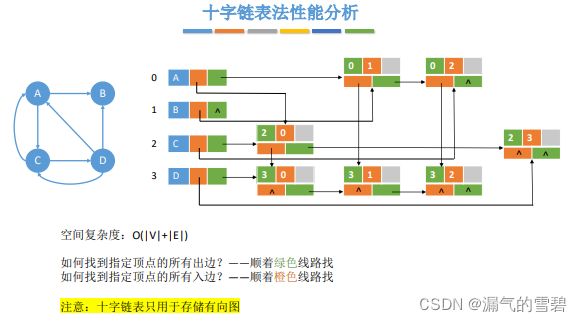
- 空间复杂度:顶点表 + 弧结点链,O(|V| + |E|)
- 邻接表法的入度问题:遍历hLink指针即可
6.2.4 邻接多重表
1.算法思想
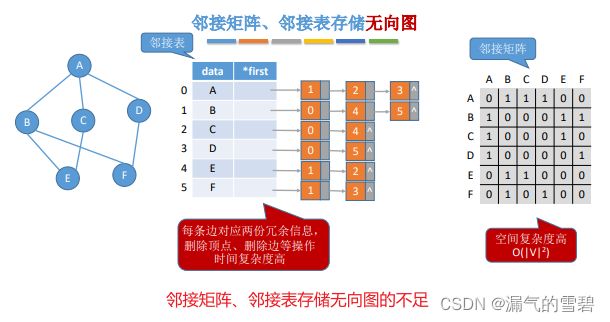
1)对无向图的存储是否有更优的方案呢?
- 如果使用上面的三种方式存储无向图,会出现一下这些问题:
- 1、邻接矩阵法:空间复杂度高
- 2、邻接表法:
- 存储了冗余数据(两份边)
- 删除顶点、边等操作,时间复杂度高(有冗余数据)
- 3、十字链表法:只适用于有向图
2)邻接多重表存储无向图
- 邻接多重表是无向图的另一种链式存储结构
- 看了代码和下面截图,你会发现邻接多重表不就是十字链表的盗版吗?直接把有向图版本改成无向图版本就是了
- 顶点结点:不分入边和出边了,就一个弧结点
- 弧结点:不分头结点和尾结点了,倒是两个弧结点指针还在
- 下图中的弧(0, 1),因为是无向图,所以用(1, 0)表示也是可以的
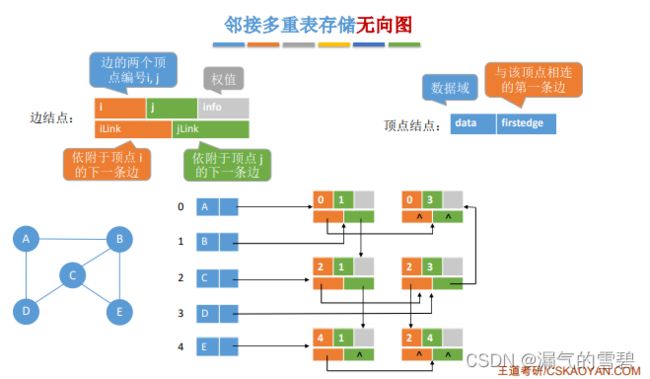
- 删除一条边
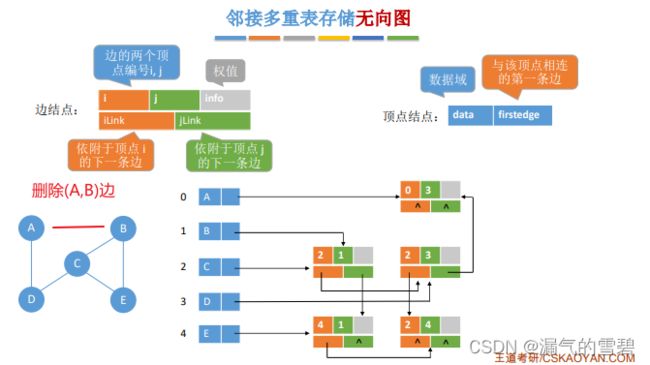
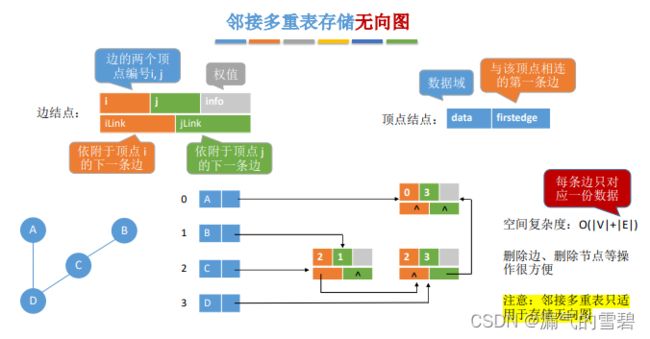
2.性能分析
- 邻接多重表只适用于存储无向图
- 空间夫复杂度:O(|V| + |E|),没有冗余数据了
- 删除边、点变得很方便了
3.代码实现
- 1)王道代码
// ? 邻接多重表
#define MAX_VERTEX_NUMBER 100
// ! 弧结点
typedef struct ArcNode
{
int iVex, jVex; // 弧的两个点
int info; // 权值
struct ArcNode *iLink, *jLink; // 依附各自顶点的下一条边
} ArcNode;
// ! 邻接多重表的顶点
typedef struct VexNode
{
char data; // 顶点的信息
ArcNode *firstEdge; // 与该顶点相连的第一条边
} VexNode, AdjList[MAX_VERTEX_NUMBER];
// ! 使用邻接表存储的图
typedef struct
{
AdjList vertices; // 存储图中顶点的数组
int verNum, arcNum;
} AMLGraph;
4.十字链表和邻接多重表小结
- 十字链表和邻接多重表考察代码频率较低

6.2.5 图的基本操作
- 因为考研中基本是考察邻接矩阵和邻接表两种存储结构,所以在本小节中也是讨论这两种结构的情况

1.Adjacent
// 判断图G是否存在边或(x,y)
bool Adjacent(Graph g, int x, int y)
// 邻接矩阵:O(1)
return (a[x][y]!=0); // 不为空,存在边
// 邻接表法
// 最好情况:遍历第一条边就找到了
故时间复杂度:O(1)
// 最坏情况,遍历到最后一条边也没找到,因为顶点只能连接n-1条边,也就是|V|-1条边
故时间复杂度:O(|V|)
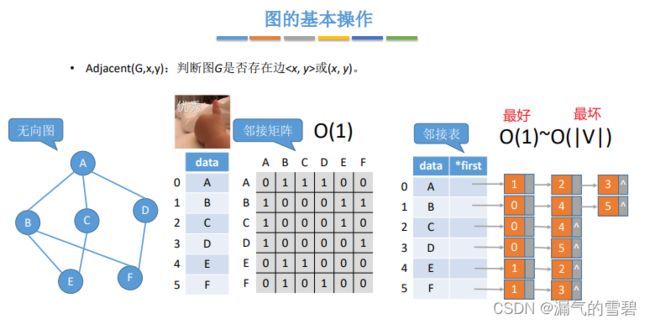
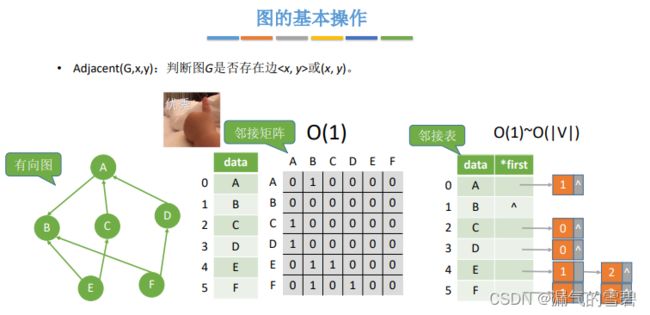
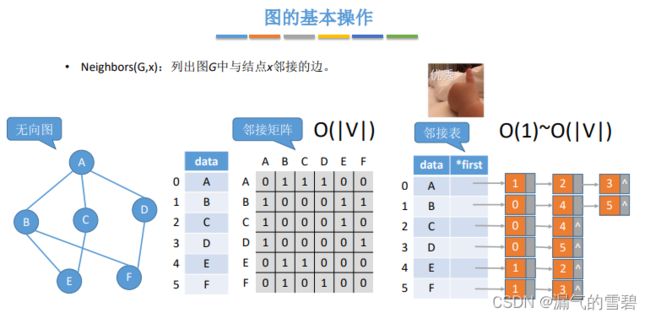
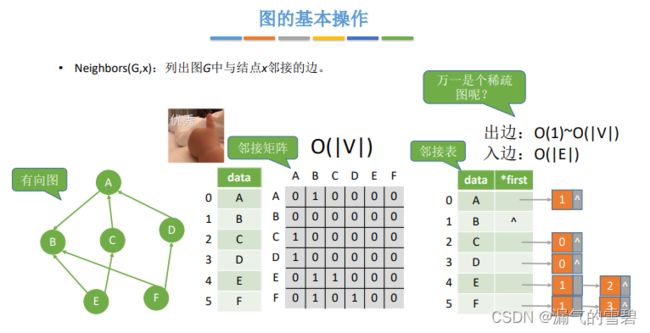
2.Neighbors
// 列出图G中与结点x邻接的边
int Neighbors(Graph g, int x)
// 邻接矩阵
遍历 x行 或者 x列,总数之和
// 邻接矩阵
// 出边情况
O(1): 0或者O(1)条边
o(|V|): 连接了|V|-1条边
// 入边情况
O(|E|): 遍历所有的边结点
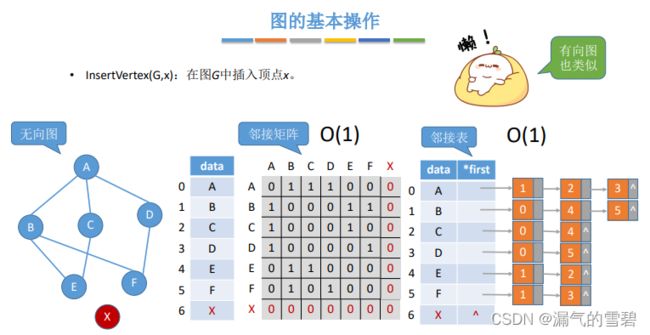
3.InsertVertex
// 在图G中插入顶点x
bool InsertVertex(Graph g, char x)
// 邻接矩阵
二维数组的赋0操作在初始化数组的时候就已经完成
故只需要对顶点数组的相应位置进行赋值操作即可 O(1)
// 邻接表
在顶点数组的相应位置进行赋值操作即可 O(1)
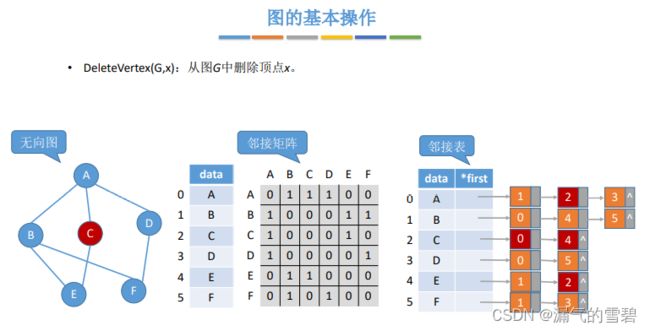
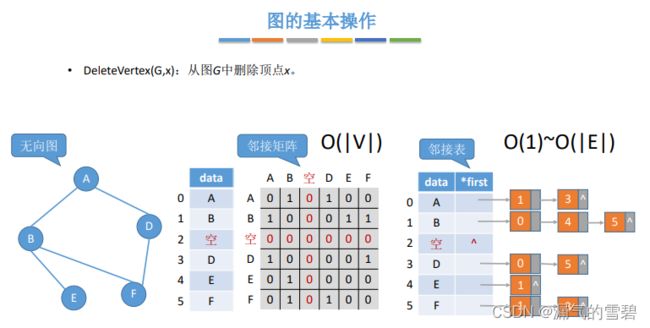
4.DeleteVertex
// 在图G中删除顶点x
bool DeleteVertex(Graph g, int x)
// 邻接矩阵 O(|V|)
1、看下图中标红的0,在删除顶点表、边表之后,如果把后面元素前移,那么就会有大量的元素移动,开销太大
2、所以直接将两个表的对应位置赋0,在在顶点结构体里设置一个bool的变量,判断此处是否为空位置
// 邻接表法
// 无向图
1、该结点的first指针为空,不存在与它向连的边 O(1)
2、遍历x结点的结点链发现有|V|-1条,就是说和每一个顶点它都相连了,这时就需要遍历所有结点的结点链(去删除冗余边)
最坏的情况:在遍历所有顶点的结点链的过程,和x相连的弧结点每次都在最后被找到,时间复杂度 O(|E|)
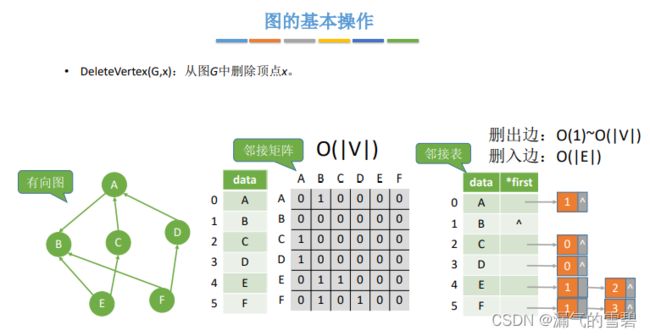
// 有向图
// 出边
遍历x顶点的弧结点链即可 O(1)~O(|V|),x最多连接|V|-1条边
// 入边
遍历所有边 O(|E|)
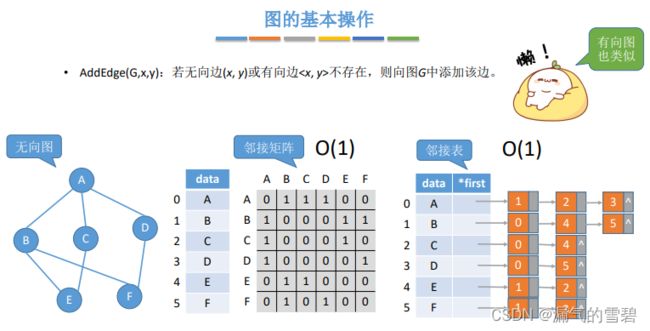
5.AddEdge
- 修改矩阵对应位置的值即可 O(1)
- 弧结点链采用头插法即可O(1),无向边插入两次(冗余数据)
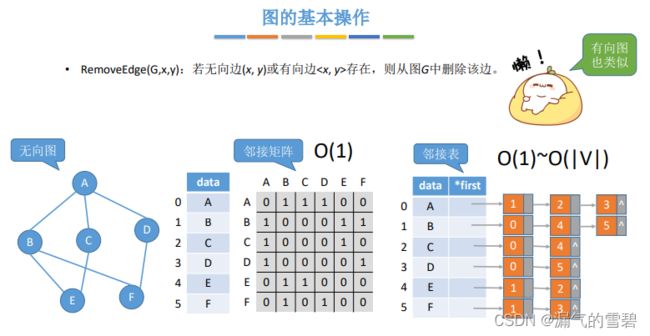
6.RemoveEdge
7.FirstNeighbor
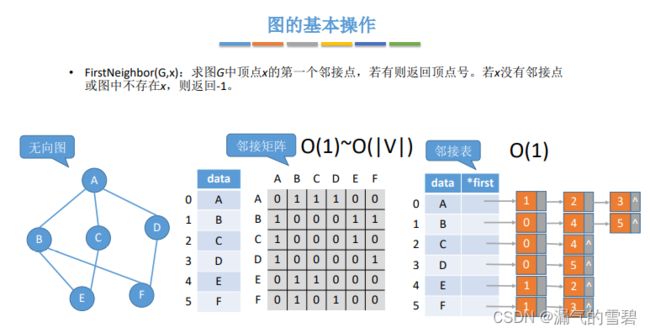
- 邻接表 - 找出边邻接点
- 遍历第一个结点的第一个弧结点就找到了 O(1)
- 遍历完所有边 O(|E|)
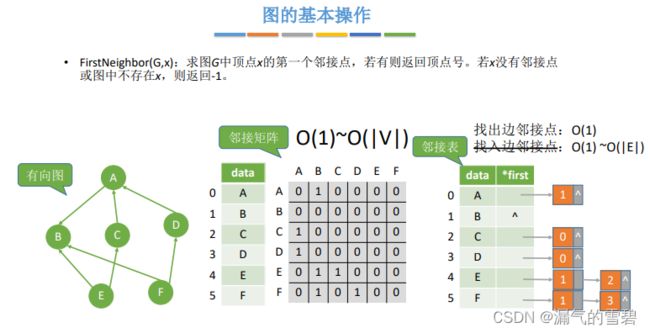
8.NextNeighbor
9.其它
10.小结

6.3 图的遍历
6.3.1 广度优先搜索
1.算法思想
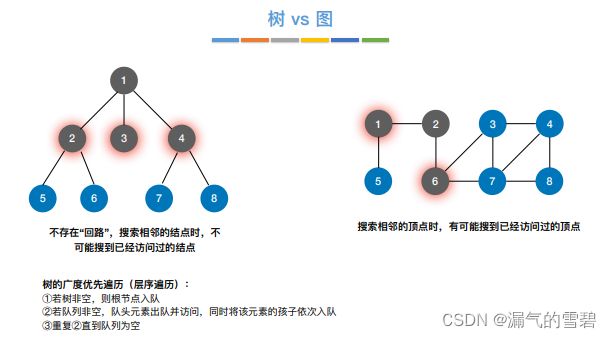
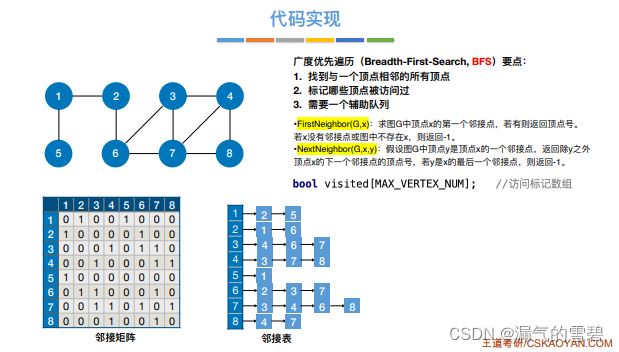
2.代码实现
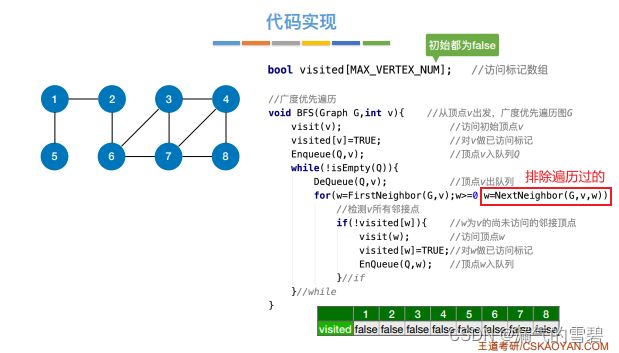
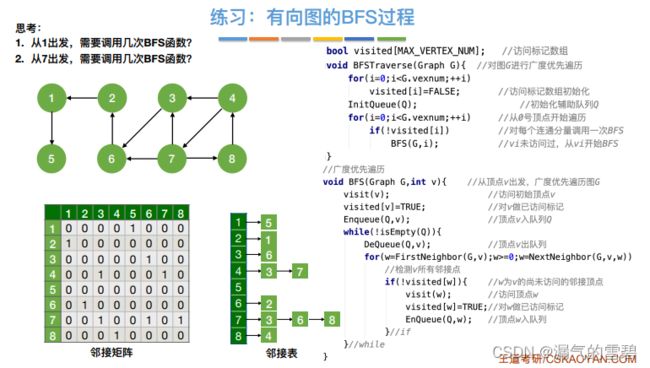
- 因为邻接表法的表示法不唯一,这就造成了遍历序列可能也不唯一
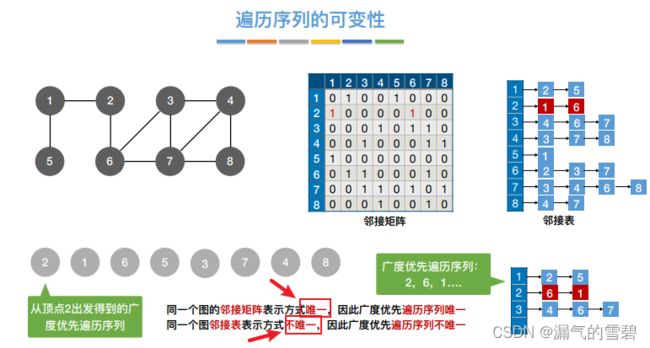
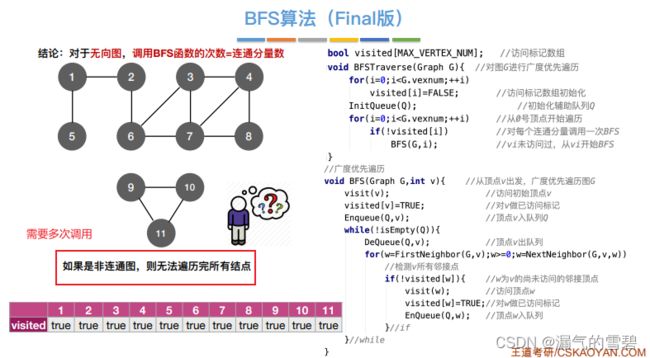
- 存在问题:如果是非连通图,就无法一次遍历完所有结点。图中存在几个连通分量,就需要调用几次BFS算法
- 下图中红框标出的代码区就是改进 : 加一个循环for
- 下图的代码是王道书里的版本,从0开始遍历,图中的例子又是从1开始,注意别错了
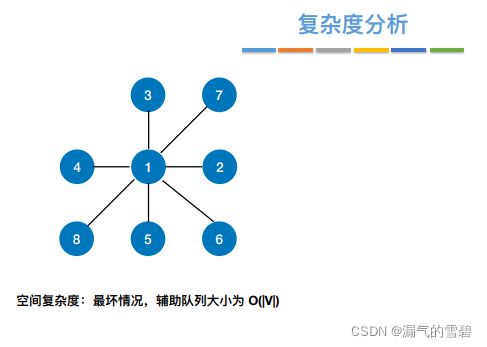
3.性能分析
- 1)空间复杂度源于辅助队列的大小
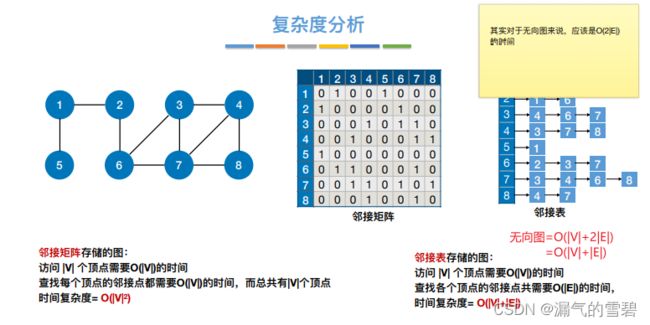
- 2)算法时间的主要开销主要来自于:
- 1、访问各个顶点
- 2、探索各条边
- 邻接矩阵法的时间复杂度:O(|V|)+ O(|V|^2)= O(|V|^2)
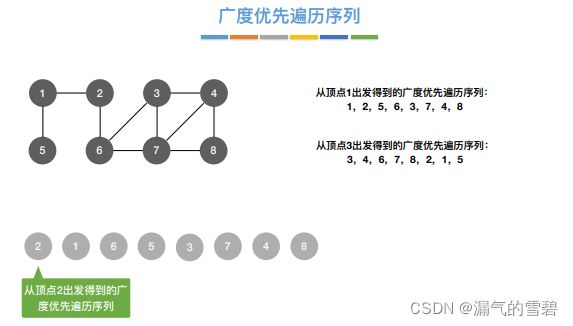
4.广度优先生成树
- 邻接表存储的图,对应的广度优先生成树不唯一
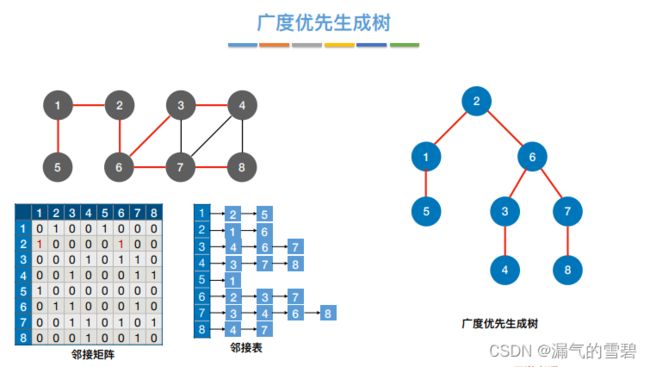
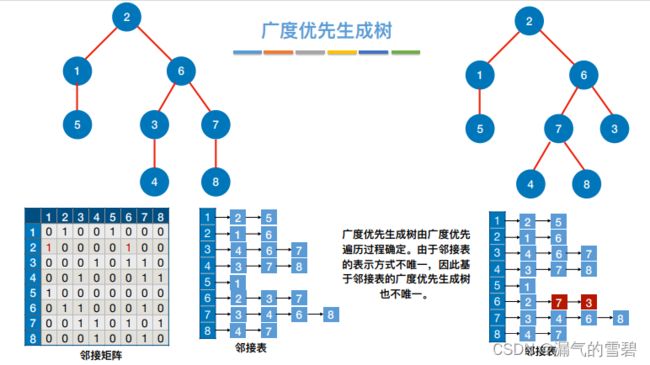
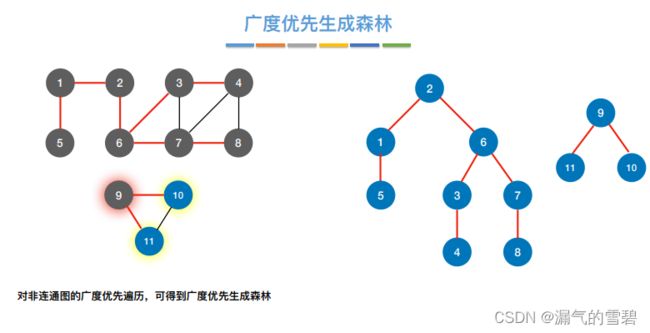
5.小结

6.3.2 深度优先搜索
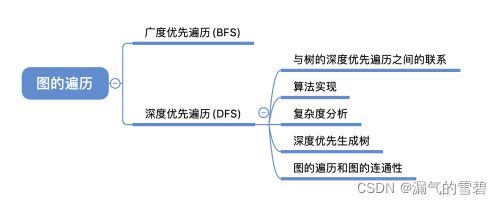
1.算法思想
- 1)对比树的深度优先遍历
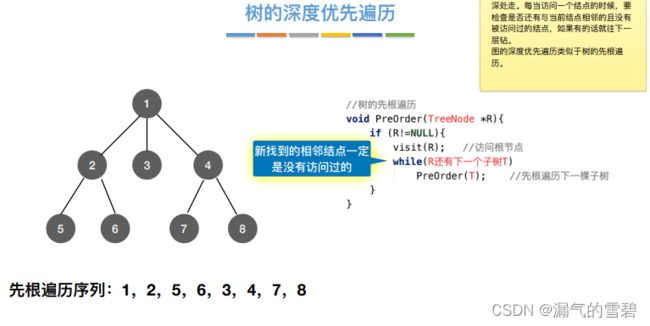
- 2)图的遍历,新找到的相邻结点不能保证没有被访问过,所以需要设置一个辅助数组visited[]
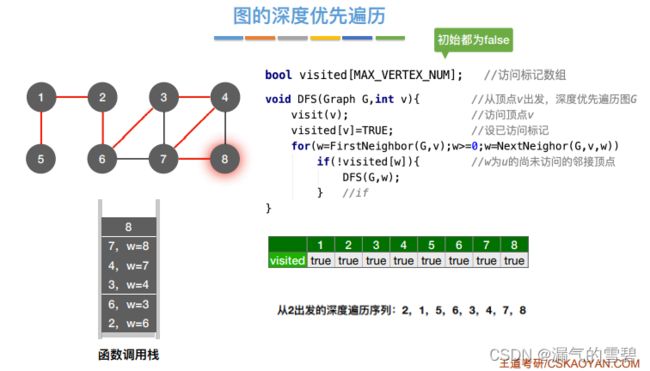
- 3)算法存在的问题
2.代码实现
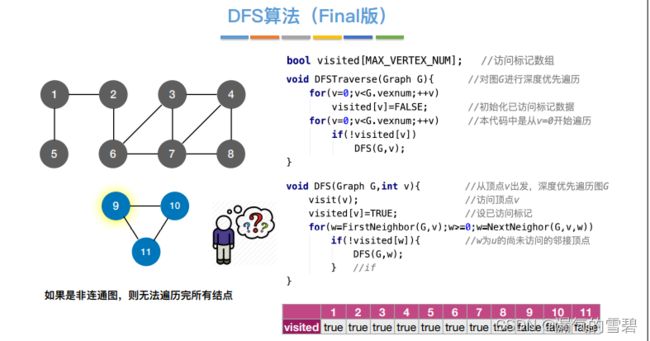
3.性能分析
- 1)题目没明确要求,空间复杂度默认采用最坏情况
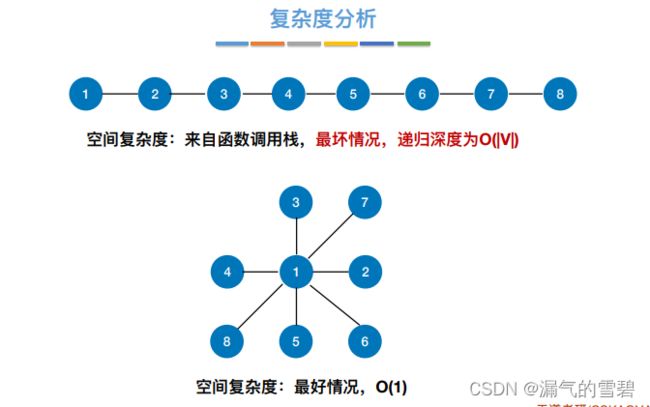
- 2)深度优先和广度优先情况类似,自己回顾
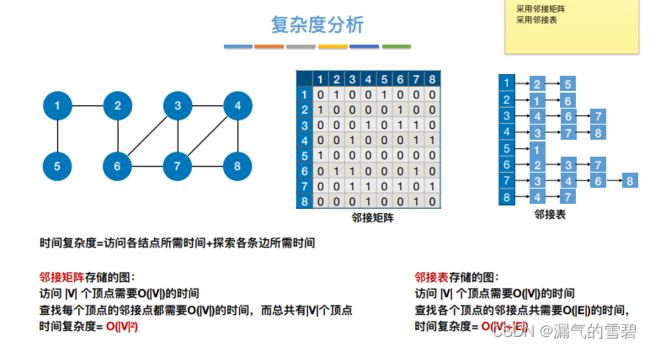
4.练习
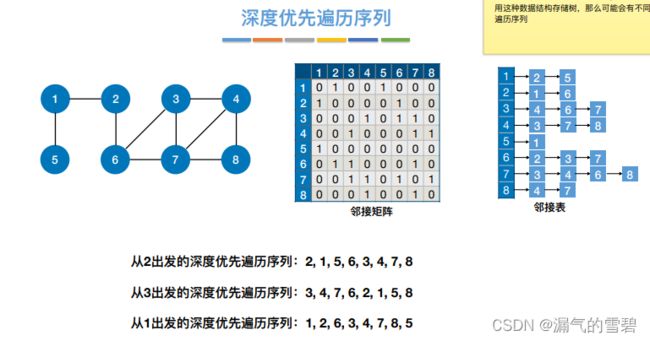
- 邻接矩阵不唯一,深度优先遍历序列也不唯一
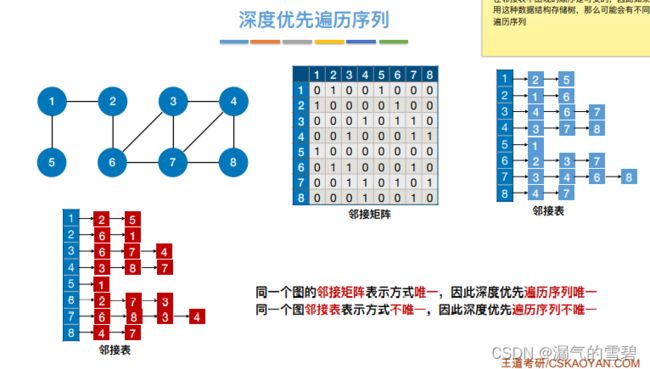
5.深度优先生成树、生成森林
- 1)深度优先生成树
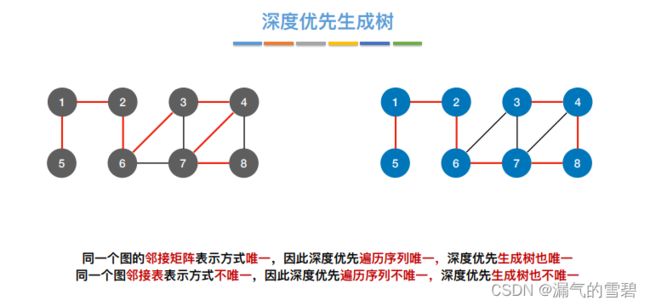
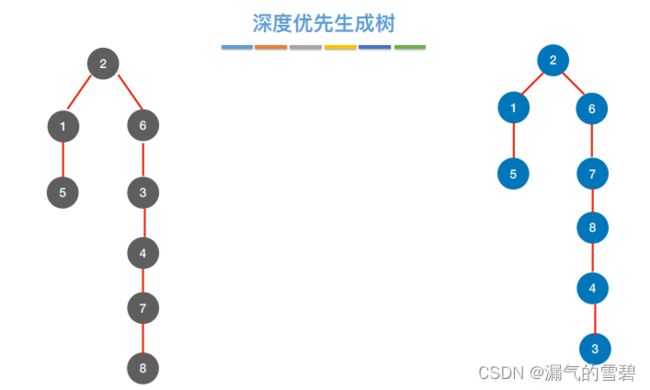
- 2)深度优先生成森林
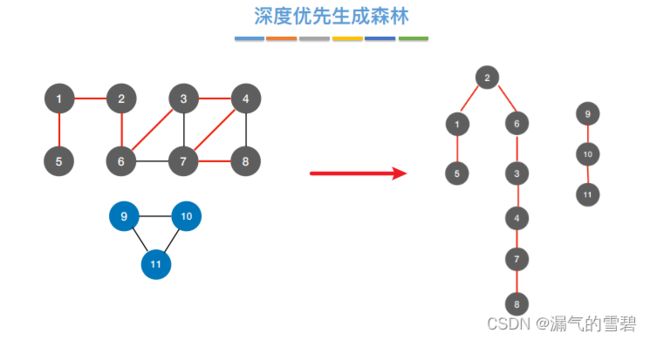
6.小结
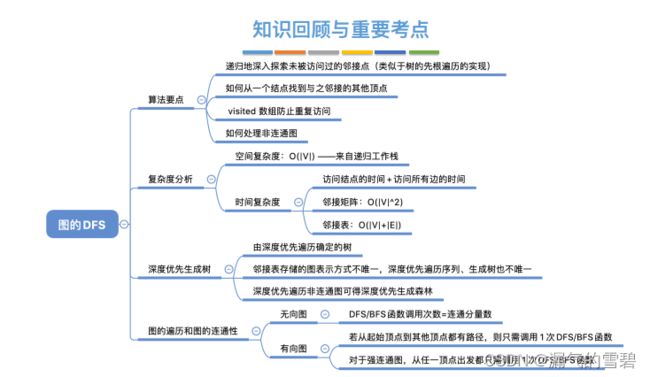
6.3.3 图的遍历和图的连通性
1.无向图情况
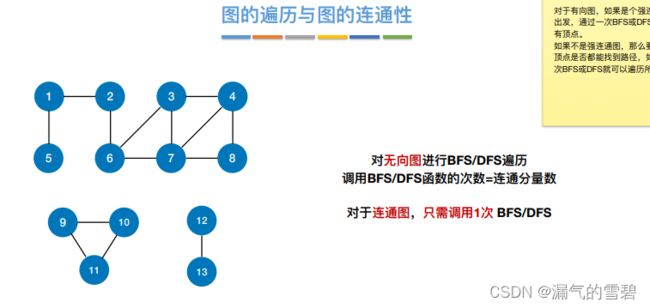
2.有向图情况
6.4 图的应用
6.4.1 最小生成树

1.定义
- 最小生成树:对于一个带权连通无向图,在其所有的生成树中,边的权值之和最小的生成树 = 最小代价生成树
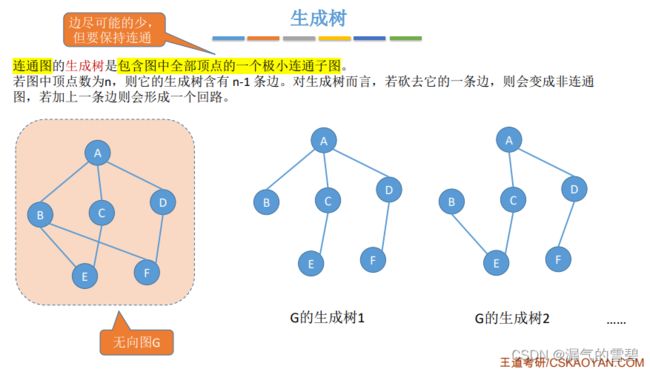
-
最小生成树不唯一(形态不同,权值和相同)
-
最小生成树 = 最大连通无环图,边数 = 顶点数 - 1;多一条回路,少一条不连通
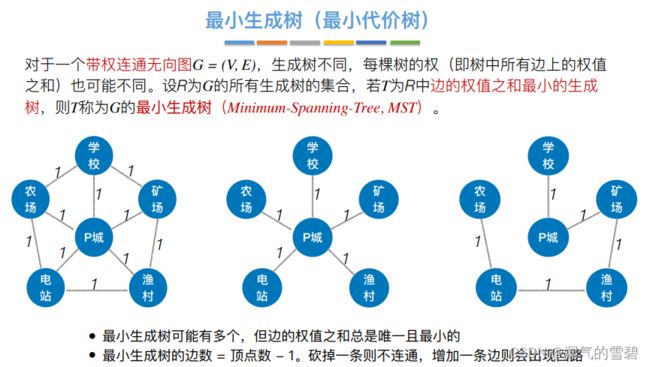
- 连通图 --> 生成树
- 非连通图 --> 生成森林
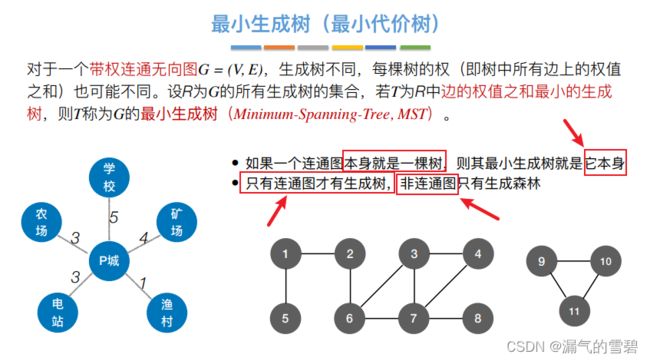

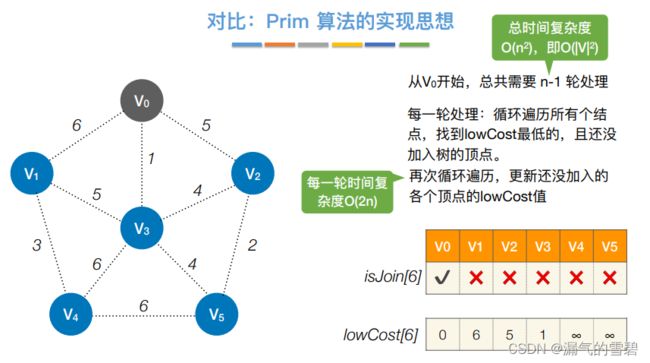
2.Prim算法
Prim算法的执行过程十分类似于寻找图的最短路径的Dijkstra算法(见下节)
1)算法思想
- 举例介绍
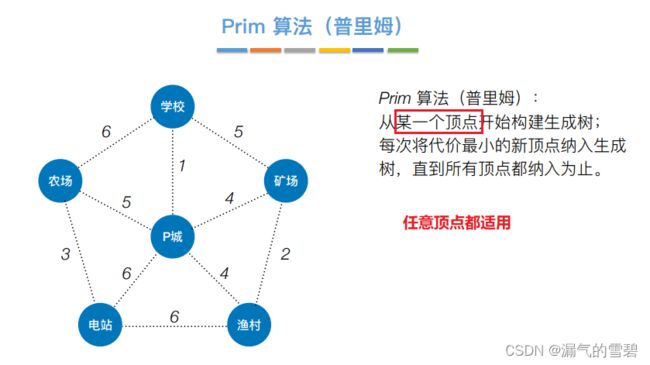
- 得到两个生成树,都符合条件,故生成树不唯一
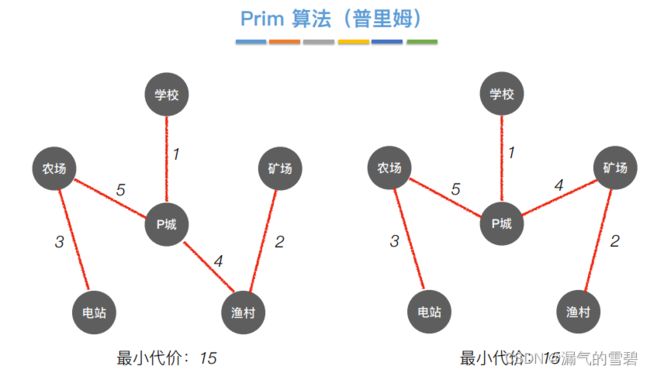
下面开始正式介绍算法的思想过程
- 需要使用到的数组数组:isJoin标记数组、lowCost最小代价数组
- 并不要求从v0开始,只是从v0开始方便介绍算法过程
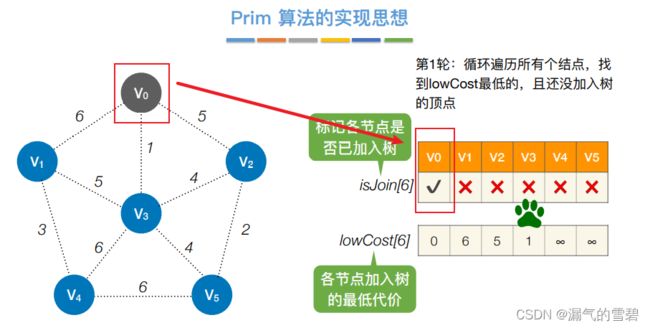
- 加入新顶点,更新辅助数组
- ① 第一轮
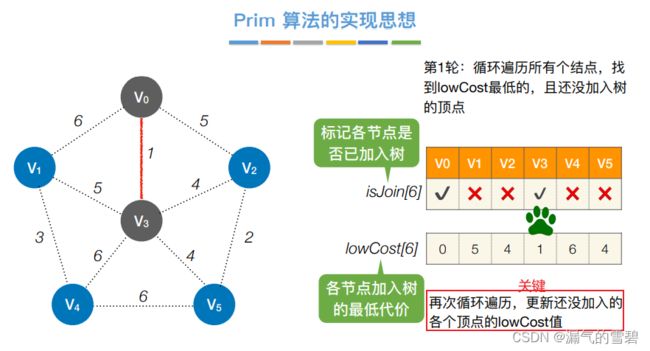
- ② 第二轮

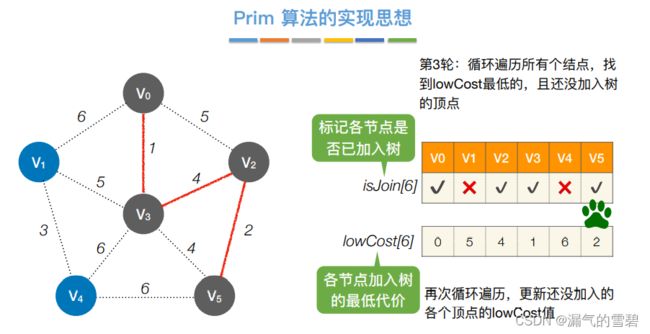
- ③ 第三轮
- ④ 第四轮
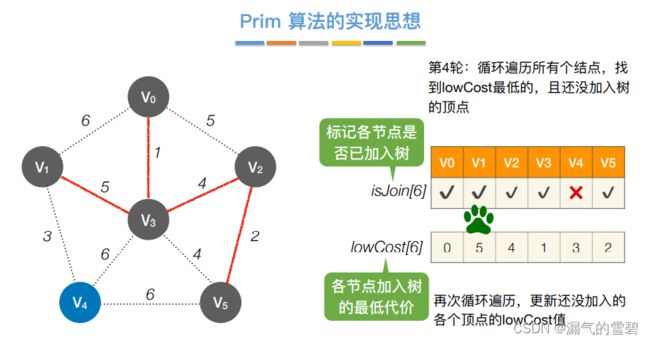
- ⑤ 第五轮
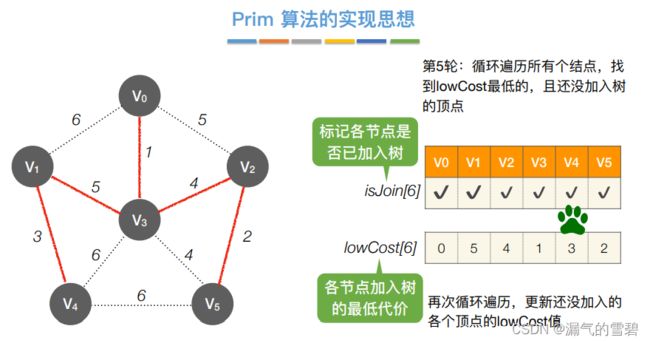
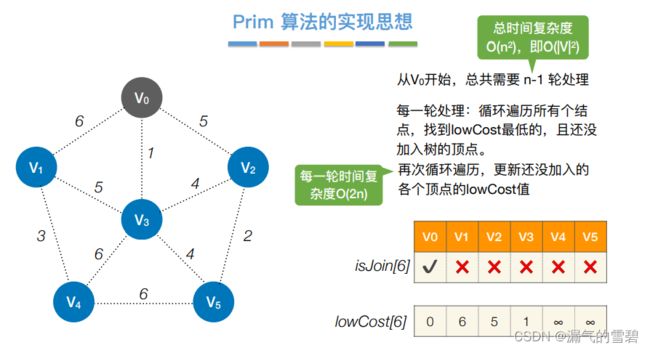
2)性能分析
- 下图中对时间复杂度的解释十分清楚,结合下面的代码应该能理解
- Prim的时间复杂度为O(n^2),不依赖于|E|
- 由上面时间复杂度可知它适用于求解边稠密的图的最小生成树
3)代码实现
-
先总结下代码关键:(牢牢记住三步)
- 1、加入点
isJoin[i] = true;- 2、更新最低代价数组
for (j = 1; j < verNum; j++) // 本循环使用来更新isJoin[],lowCost[]数组信息 { if (!isJoin[j]) { if (edge[i][j] < lowCost[j]) { lowCost[j] = edge[i][j]; } } }- 3、查找下一个要加入的点
// 本循环用来选择加入的新结点 temp = 100; for (k = 1; k < verNum; k++) { if (!isJoin[k]) { if (lowCost[k] < temp) { temp = lowCost[k]; i = k; // ! 这一步就很妙,下一轮更新数据全靠i // i记录下一个要加入的新结点 } } } cout << lowCost[i] << " "; // 每轮循环输出加入的边的代价 flag++; // 每轮循环结束,代表有一个新结点加入 -
完整代码(王道)
#include
using namespace std;
#define MAX_SIZE 16
int ver, arc; // 输入的点数、边数
int edge[MAX_SIZE][MAX_SIZE]; // 邻接矩阵法
void PrimAlgorithm(int edge[MAX_SIZE][MAX_SIZE], int verNum)
{
bool isJoin[MAX_SIZE]; // ! 记录各结点是否已加入
int lowCost[MAX_SIZE]; // ! 记录 未加入结点 加入 结点集 的最小代价
memset(isJoin, false, sizeof(isJoin));
memset(lowCost, 100, sizeof(lowCost)); // 将这些数组初始化
int flag = 1; // 记录已经加入几个点,默认为1,就是初始加入的结点
int i = 0, j, k, temp;
lowCost[i] = 0; // ! 可省略
while (flag < verNum) // (flag == verNum)还循环个头!
{
isJoin[i] = true;
for (j = 1; j < verNum; j++) // 本循环使用来更新isJoin[],lowCost[]数组信息
{
if (!isJoin[j])
{
if (edge[i][j] < lowCost[j])
{
lowCost[j] = edge[i][j];
}
}
}
// 本循环用来选择加入的新结点
temp = 100;
for (k = 1; k < verNum; k++)
{
if (!isJoin[k])
{
if (lowCost[k] < temp)
{
temp = lowCost[k];
i = k; // ! 这一步就很妙,下一轮更新数据全靠i
}
}
}
cout << lowCost[i] << " "; // 每轮循环输出加入的边的代价
flag++;
}
}
int main()
{
cin >> ver >> arc;
for (int i = 0; i < ver; i++)
{
for (int j = 0; j < ver; j++)
{
cin >> edge[i][j];
}
}
PrimAlgorithm(edge, ver);
}
3.Kruskal算法
1)算法实现
- 举例
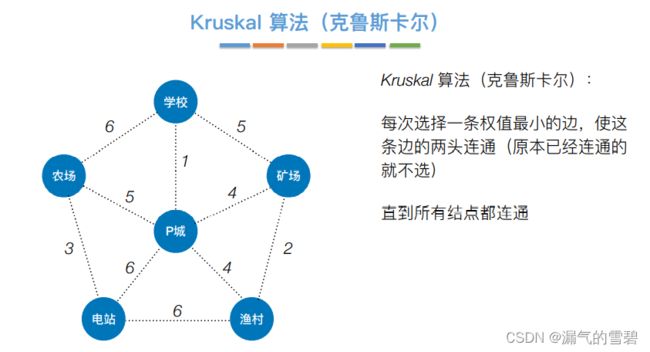
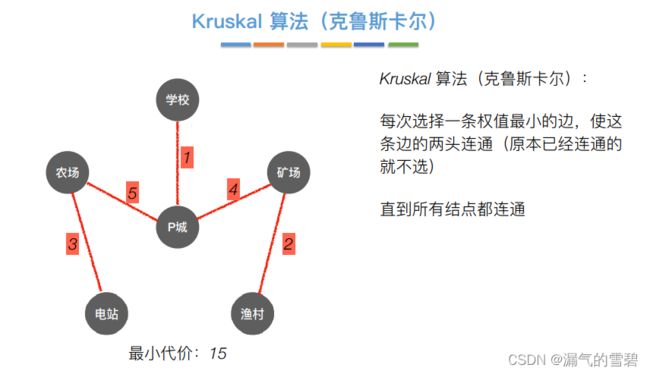
下面开始正式介绍算法思想过程
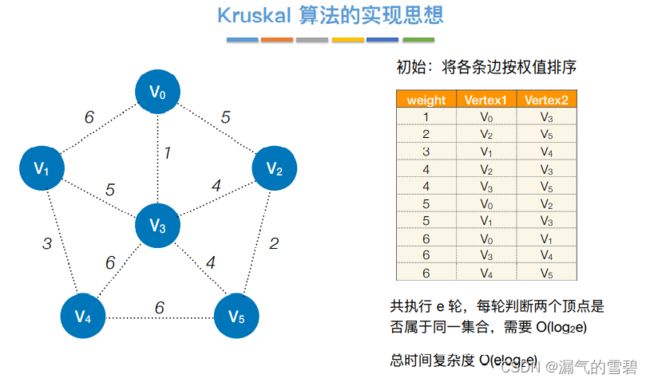
- ① 各边权值排序
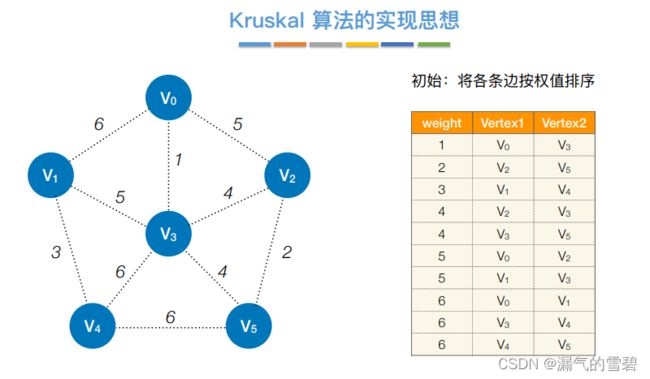
- ② 第一轮
- 关于并查集的解释在 3)代码实现 里
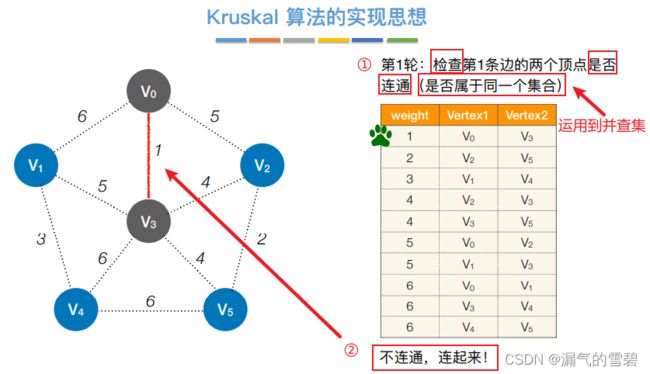
- ③ 第二轮
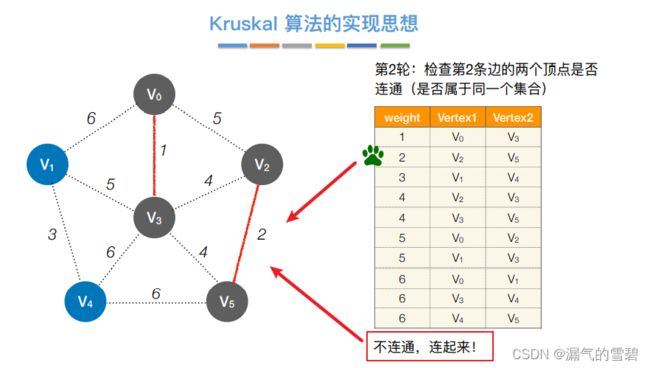
- ④ 第三轮
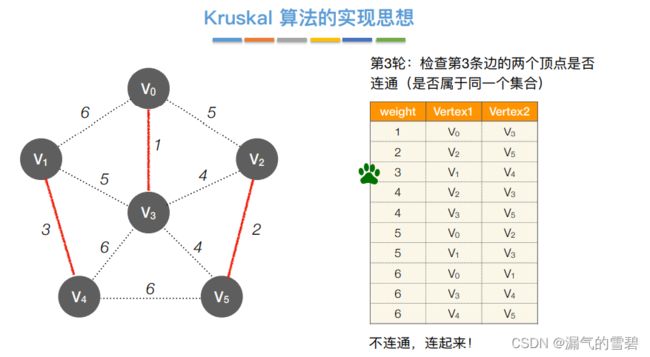
- ⑤ 第四轮
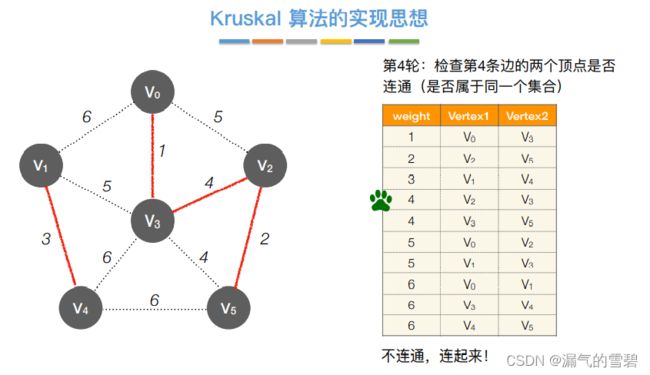
- ⑥ 第五轮
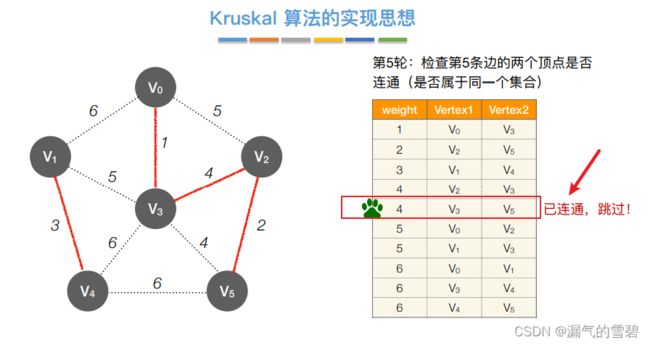
- ⑦ 第六轮
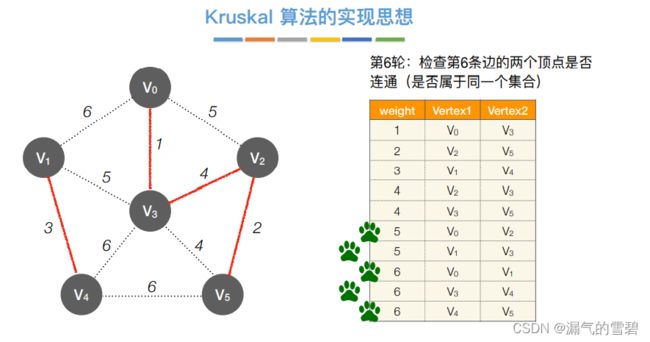
2)性能分析
- 时间复杂度为O(|E|log|E|),因此,Kruskal算法适用于边稀疏而顶点较多的图
3)代码实现
- 并查集是用来判断结点之间是否属于同一个集合
// 实现并查集其实很简单,不需要实现操作,等到加入新边的时候调用就行
FindRoot(int parent[],int s){
int x = s;
while(parent[x]>0)
x = parent[x];
return x;
}
void kruskal(){
int num = 1,i,vex1,vex2;
int parent[520]; // 并查集数组
memset(parent, 0 , sizeof(parent)); // 初始化parent数组
for(num = 1,i = 1; num < vertexNum; i++){ // vertexNum已经按权值从小到大排序好了
vex1 = FindRoot(parent,edge[i].from);
vex2 = FindRoot(parent,edge[i].to); // 查找边的两个的老大
if(vex1!=vex2){ // 两个老大不同,表示不属于一个集合,说明可以加入新边
cout<4.Prim和Kruskal小结

6.4.2 最短路径
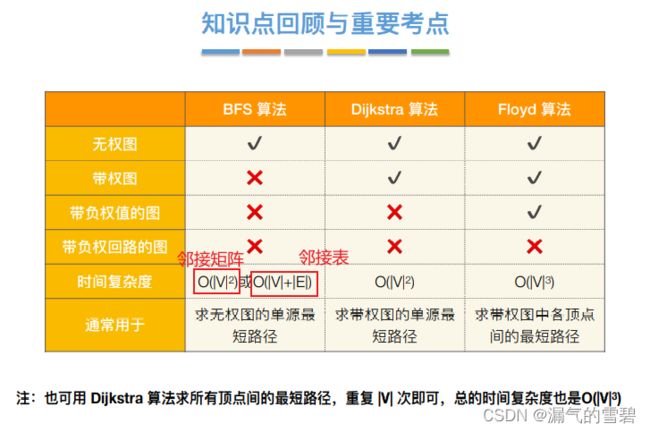
1.概念
- 最短路径问题有两大分类:
- 1、单源最短路径
- ① BFS
- ② Dijkstra
- 2、各顶点间的最短路径
- ① Floyd

2.BFS算法
1)算法思想
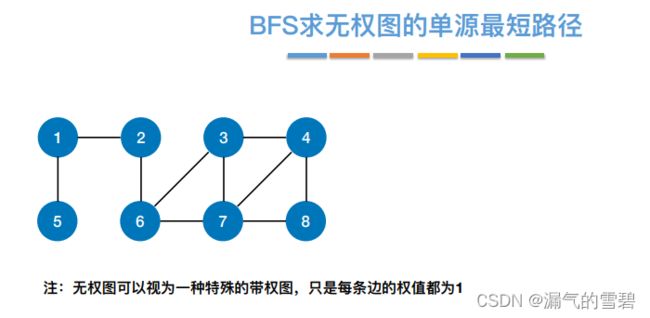
- 对图的广度优先遍历即可得到root顶点到各结点的最短路径长度,树最宽也就导致树最矮
- path[]数组是为了记录最短路径经过的结点
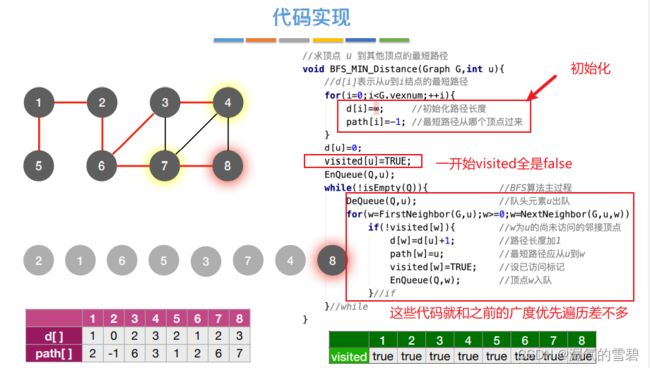
2)代码实现
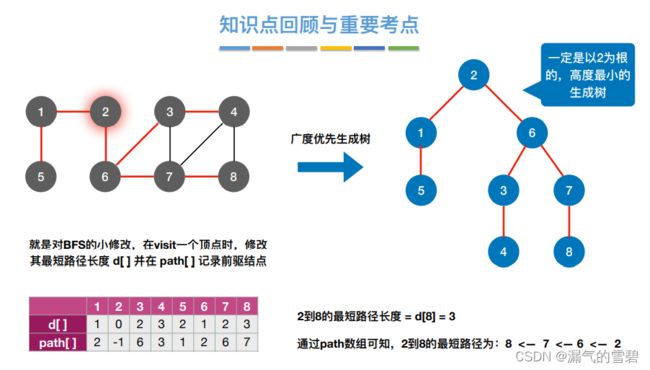
3)小结
3.Dijkstra算法
- BFS算法计算最短路径的缺陷:不适用于带权图的计算
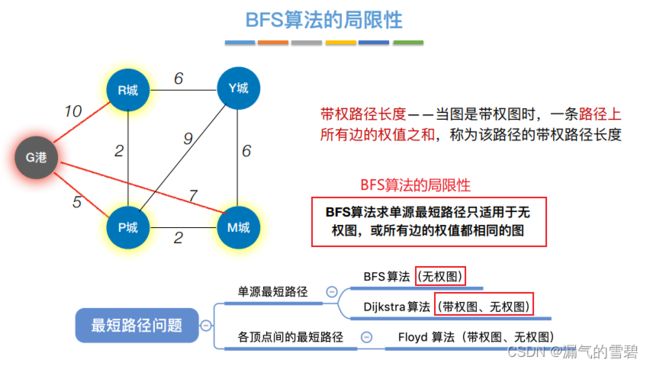
1)算法思想
- Dijkstra

- ① 初始化
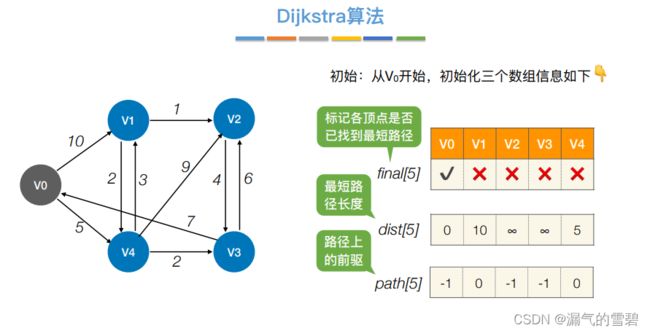
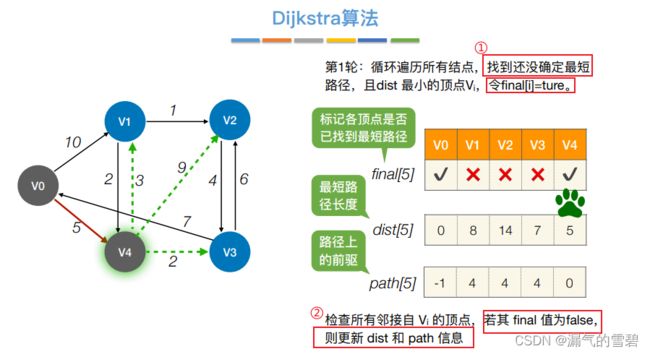
- ② 第一轮
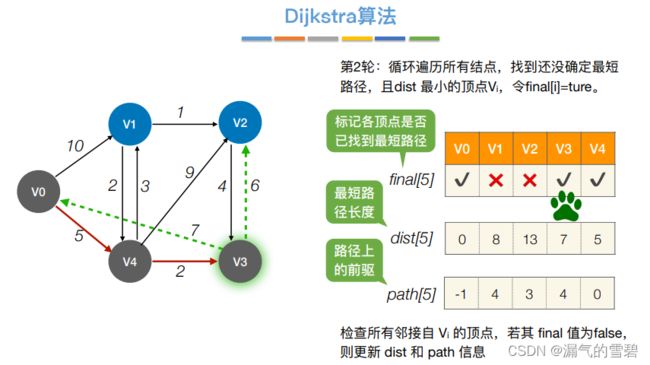
- ③ 第二轮
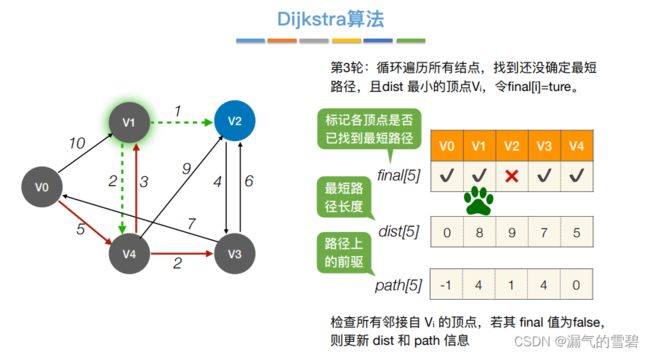
- ④ 第三轮
- ⑤ 第四轮
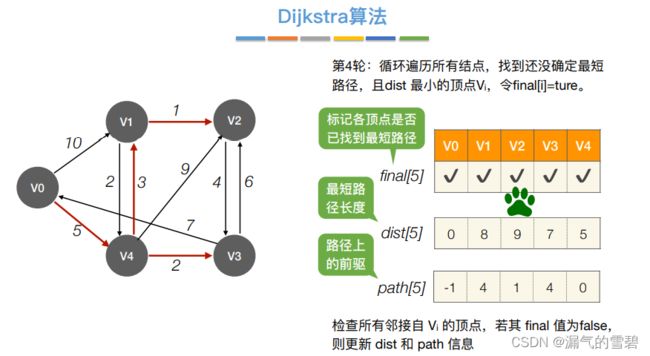
- ⑥ 输出结果
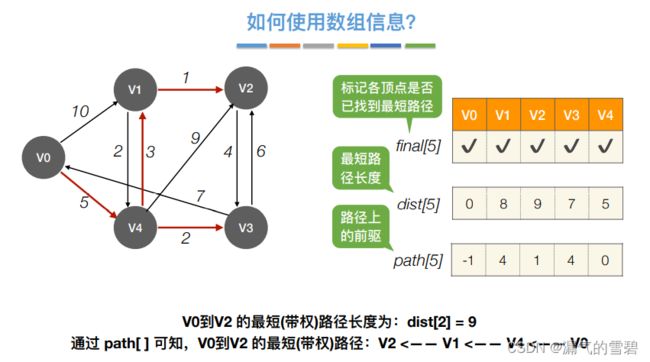
2)性能分析
- Dijkstra算法是基于贪心策略
- 邻接矩阵和邻接表的时间复杂度都是O(|V|^2)
- 下面是伪代码
- n-1轮处理,处理n-1各结点
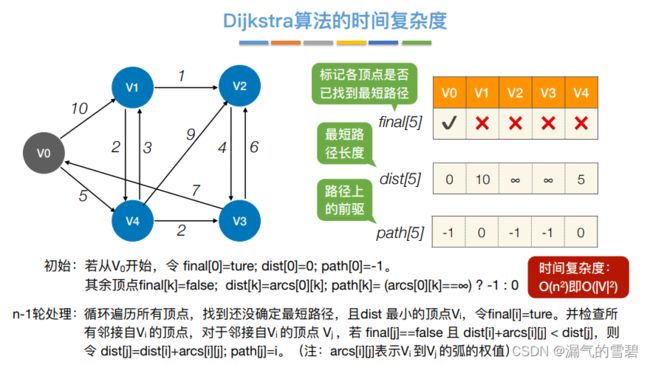
- Dijkstra算法不适用有负权值的带权图
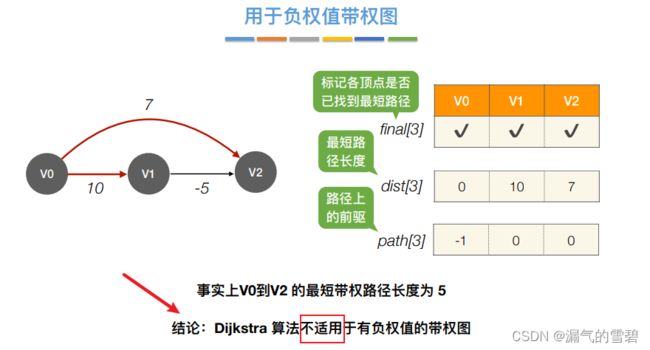
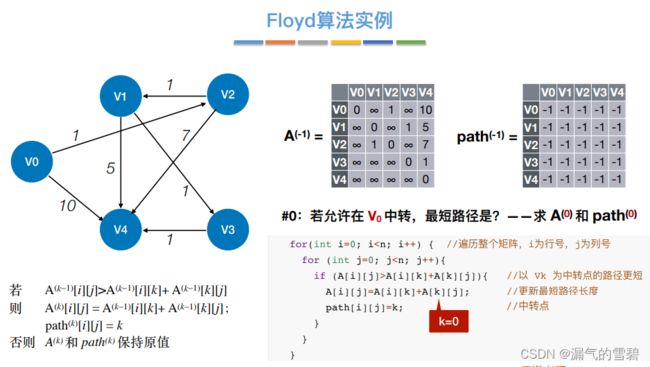
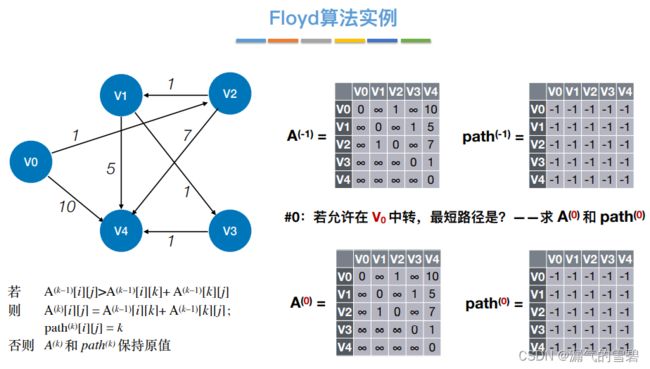
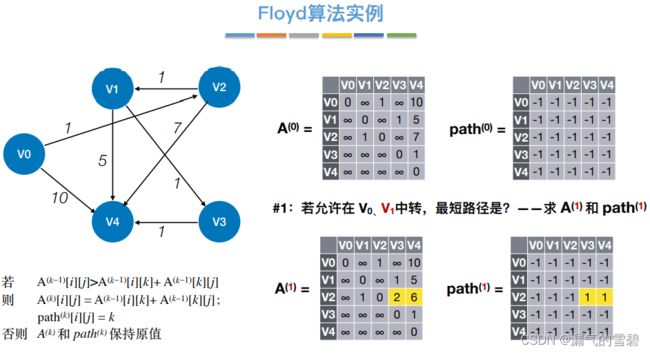
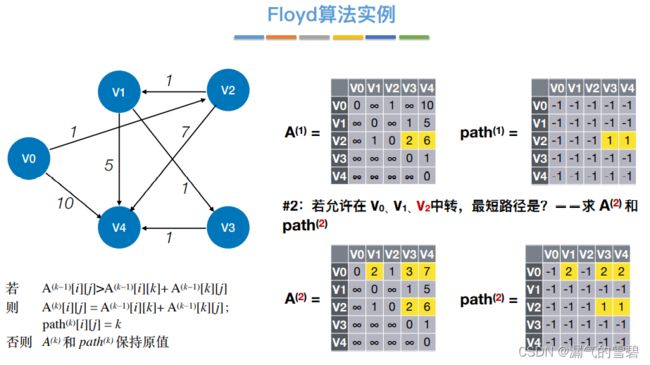
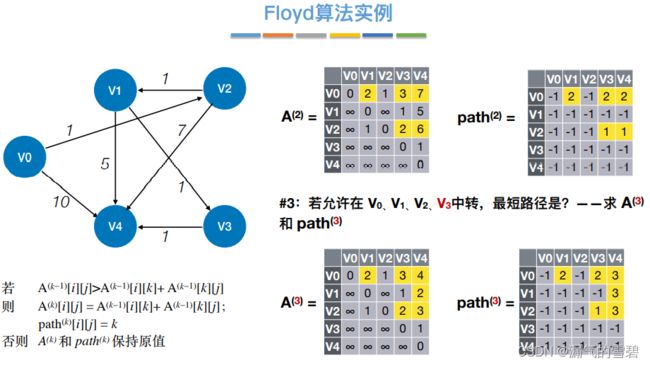
4.Floyd算法

1)算法思想
- 关键思想:每次循环,容许一个新的结点当作中转点;这样各顶点间的最短路径就又更新了

-
① 初始,中转{}
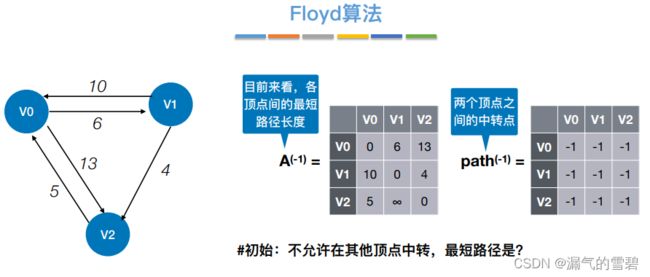
-
② 中转{v0}
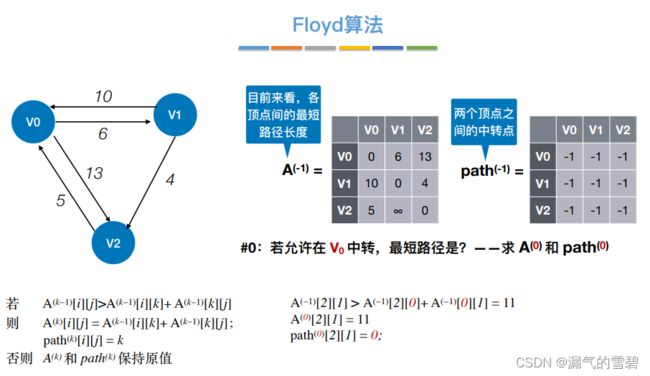
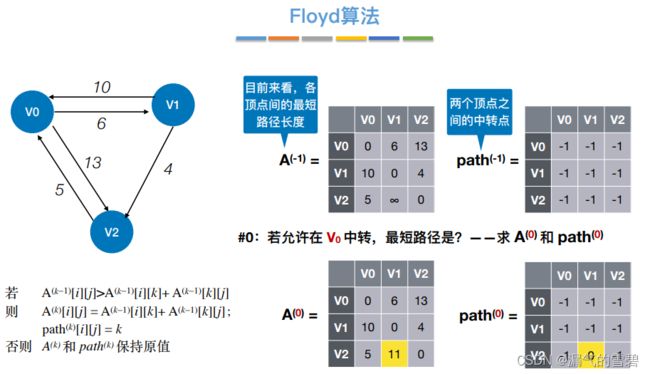
- ③ 中转{v0、v1}

- ④ 中转{v0、v1、v2}
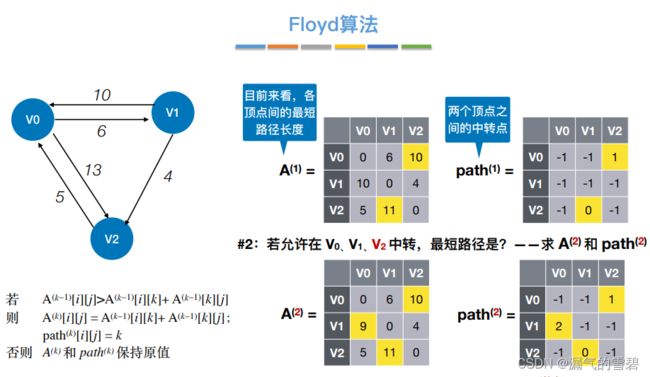
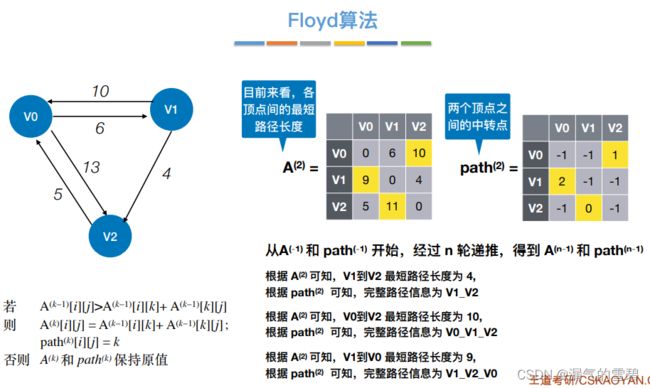
2)性能分析
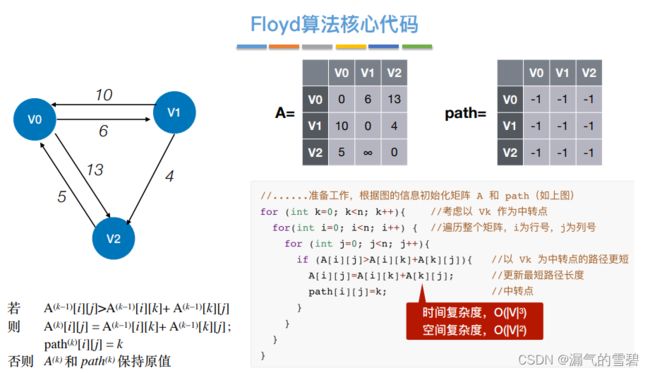
- 时间复杂度:3层嵌套for循环,O(|V|^3)
- 也可以轮流将每个顶点作为原点,并且在所有边权值均非负时,运行依次Dijkstra算法,O(|V|2)*|V|=O(|V|3)
- 空间复杂度:两个辅助数组
3)代码实现
4)举例练习
问题
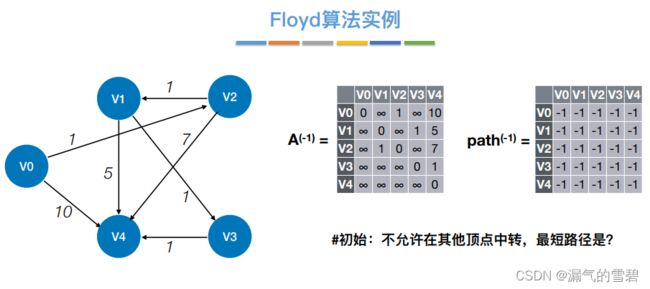
解

- 考试可能让你手写A数组
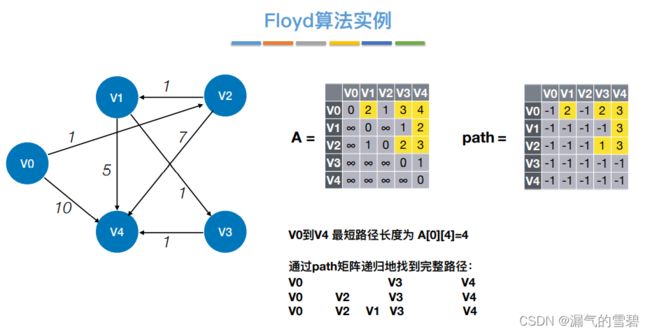
5)小结
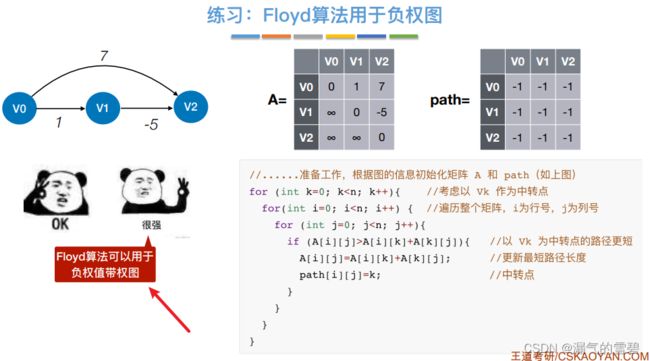

6.4.3 有向无环图描述表达式
1.有向无环图(DAG)
- 有向无环图(Directed Acyclic Graph):有向图 + 不存在环
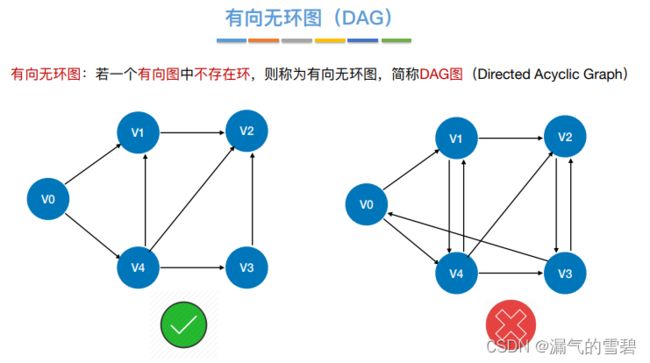
2.DAG描述表达式
- 出现重复部分,可压缩
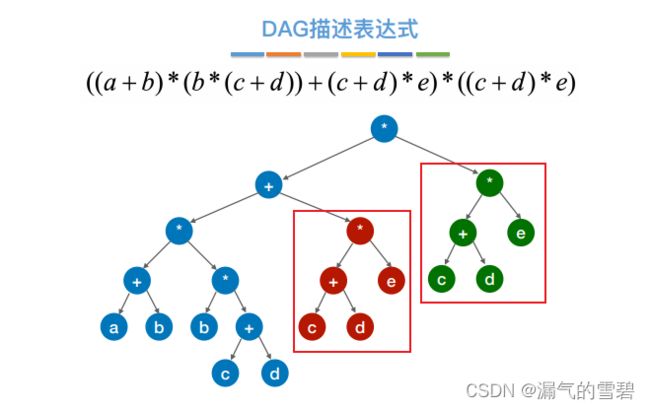


- 最终结果
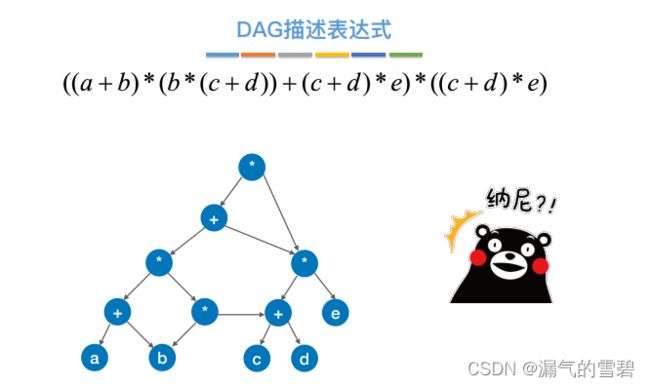
3.构造DAG有向无环图
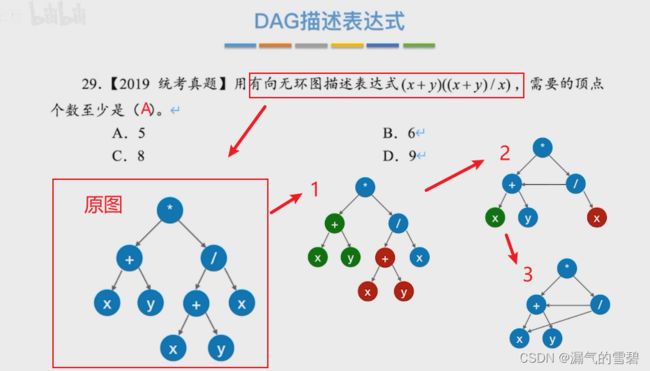
- 咸鱼算法 —— 用于构造有向无环图
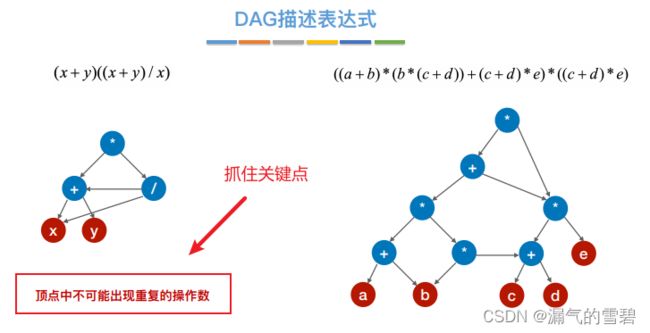
- ① 初始构造
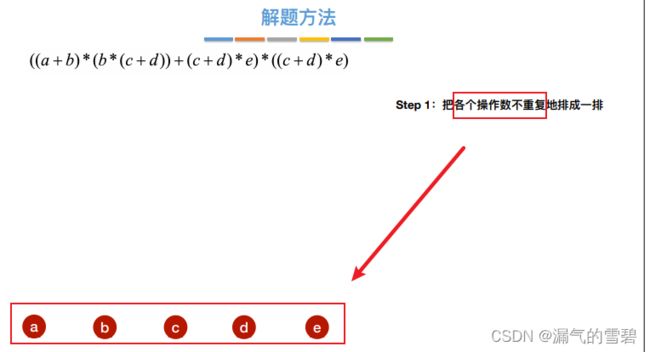
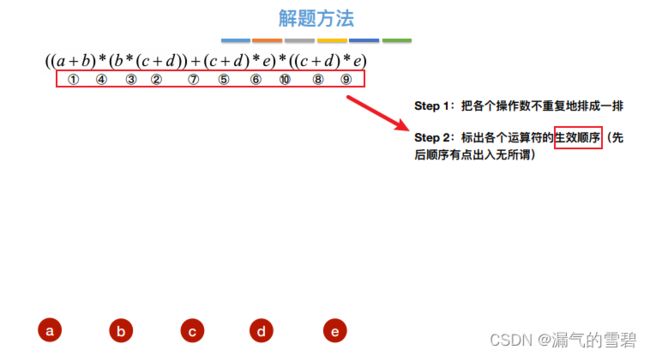
- ② 标明顺序
- ③ 顺序加入运算符(分层)
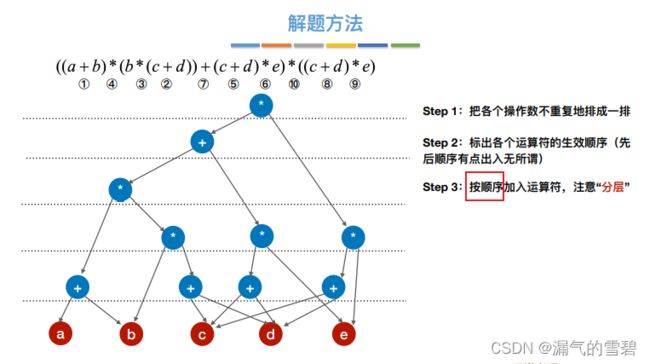
- ④ 检测是否存在重复,合体
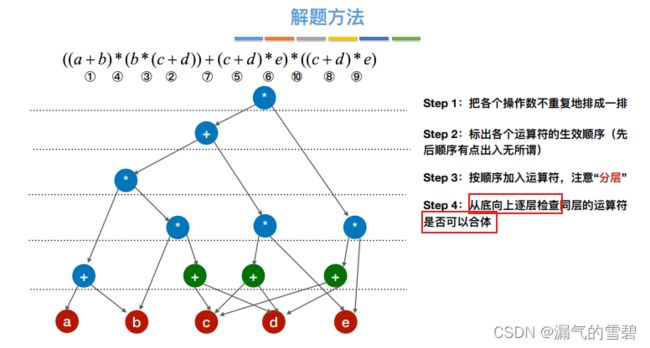
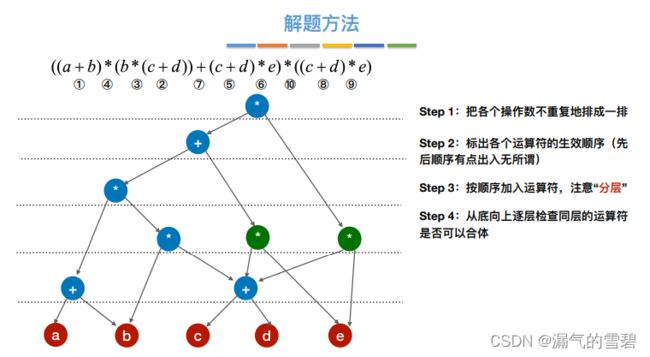
- ⑤ 最终结果
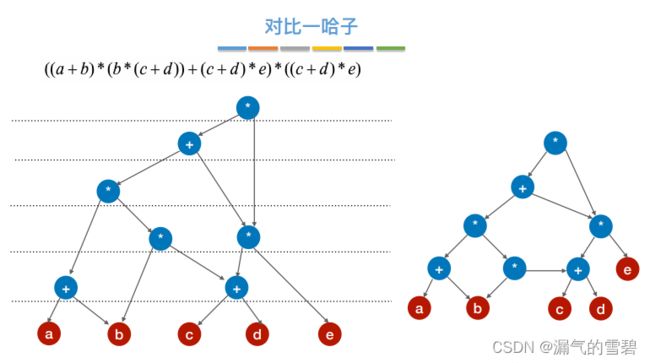
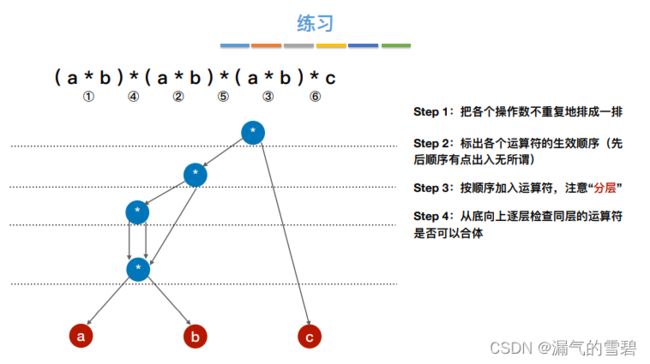
4.练习
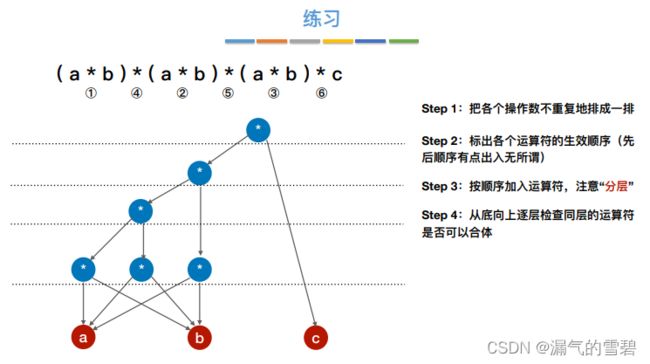
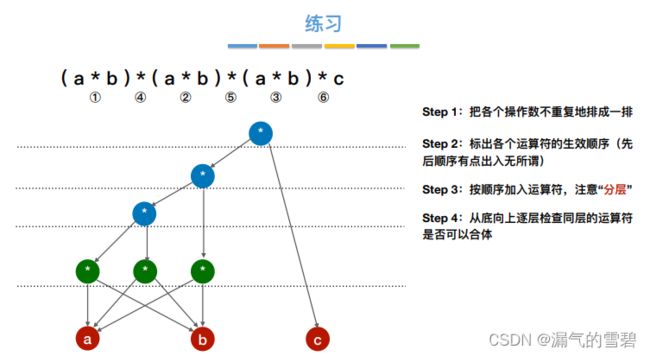
- 由于第二步里设置的运算符顺序不唯一,导致最后的结果图也不同
无小结
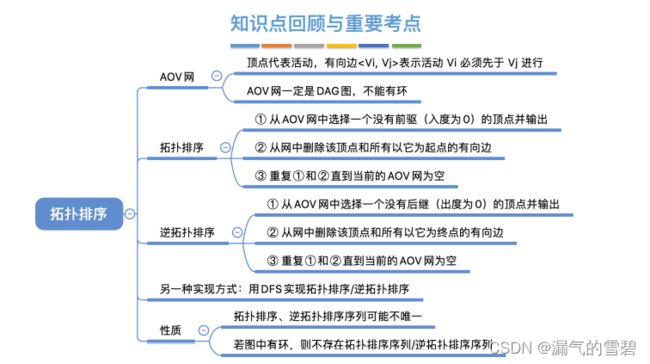
6.4.4 拓扑排序
1.AOV网
- AOV:顶点表示活动的网(Activity On Vertex Network)
- DAG表示一个工程(工程就是活动的顺序序列集合)
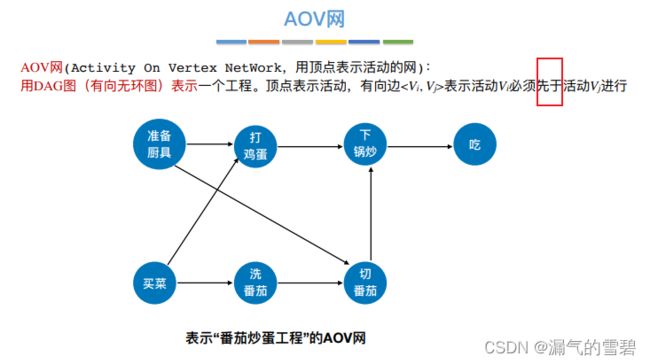
- 举个反例
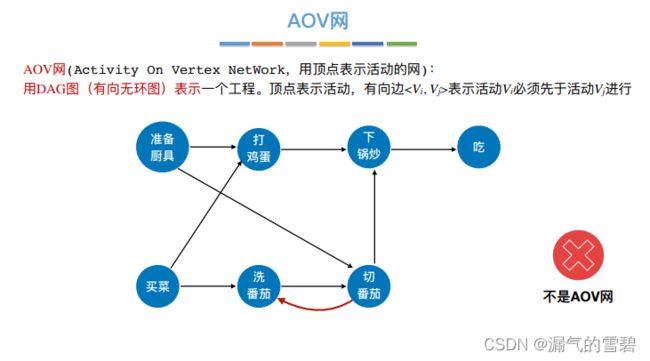
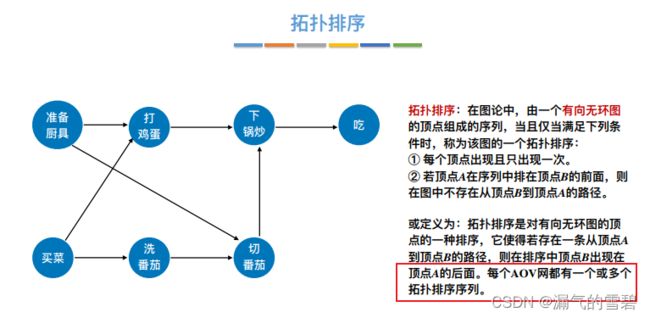
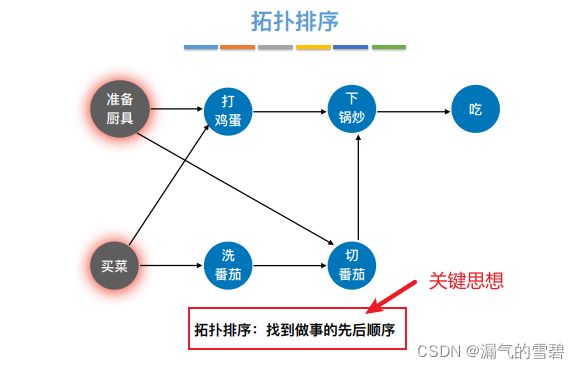
2.拓扑排序
- 针对有向图,具体定义看下图
- 每个AOV网的拓扑排序序列不唯一
3.求拓扑排序算法思想
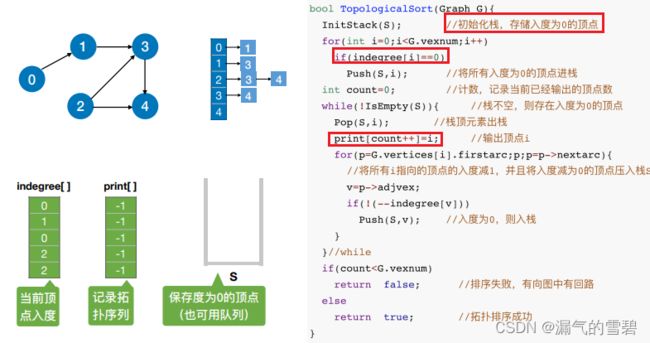
步骤总结:
- 1、找点入栈(入度为0的点)
- 2、栈顶出栈,对出栈元素操作
- ① 删除该结点和所有以它为起点的有向边
- ② 修改入度数组、拓扑路线数组

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NVRP89o7-1642514497431)(第6章 图_img/image-
4.代码实现
- 本代码是基于邻接表的实现

- 王道书上代码
#include
using namespace std;
// ? 已经成功实现 —— 基于邻接表实现
#define MAX_VERTEX_NUM 100
int verNum, arcNum; // 图的顶点数和边数
int x, y;
int inDegree[MAX_VERTEX_NUM]; // 记录顶点入度
int print[MAX_VERTEX_NUM]; // 记录拓扑序列
typedef struct ArcNode // 边链表结点
{
int adjvex;
// int info; // 边的权值
struct ArcNode *nextArc;
} ArcNode;
typedef struct VNode // 顶点表结点
{
int data;
ArcNode *firstArc;
} VNode, AdjList[MAX_VERTEX_NUM];
typedef struct
{
AdjList vertices; // 邻接表
int verNum, arcNum; // 图的顶点数和弧数
} Graph; // Graph是以邻接表存储的图类型
bool TopologicalSort(Graph g)
{
stack s; // 声明辅助栈,用于存储入度为0的顶点
for (int i = g.verNum; i > 0; i--) // 为了让编号比较小的顶点先出栈 (晚进栈)
{
if (inDegree[i] == 0)
{
s.push(i); // 将初始所有入度为0的顶点入栈
}
}
int count = 0; // 计数,记录当前已经输出的顶点数
while (!s.empty()) // 栈非空,表示还存在入度为0的顶点
{
int flag;
int v;
ArcNode *p;
flag = s.top();
s.pop(); // 栈顶元素出栈
print[count++] = flag; // 记录输出的顶点
// 本段循环的目的:由于输出栈顶元素这个操作,所以需要对与栈顶顶点相连的顶点的入度减一
for (p = g.vertices[flag].firstArc; p != NULL; p = p->nextArc)
{
v = p->adjvex;
if (!(--inDegree[v]))
{
s.push(v); // 入度为0,入栈
}
}
}
if (count < g.verNum)
{
return false; // 拓扑排序失败,存在回路
}
return true; // 拓扑排序成功
}
int main()
{
cin >> verNum >> arcNum;
Graph graph;
graph.verNum = verNum;
graph.arcNum = arcNum;
memset(inDegree, 0, sizeof(inDegree));
memset(print, -1, sizeof(print));
for (int i = 1; i <= verNum; i++)
{
graph.vertices[i].firstArc = NULL;
}
for (int i = 1; i <= arcNum; i++)
{
cin >> x >> y;
inDegree[y]++;
ArcNode *arc = (ArcNode *)malloc(sizeof(ArcNode));
arc->adjvex = y;
arc->nextArc = graph.vertices[x].firstArc;
graph.vertices[x].firstArc = arc;
}
if (TopologicalSort(graph))
{
for (int i = 0; i < verNum; i++)
{
cout << "v" << print[i] << " ";
}
}
return 0;
}
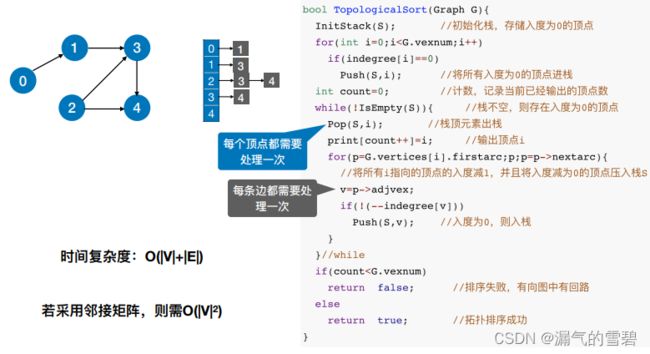
5.性能分析
- 邻接表情况的时间复杂度:每个顶点都被处理一次;每条边都被处理一次 O(|V|+|E|)
- 邻接矩阵:O(|V|^2)
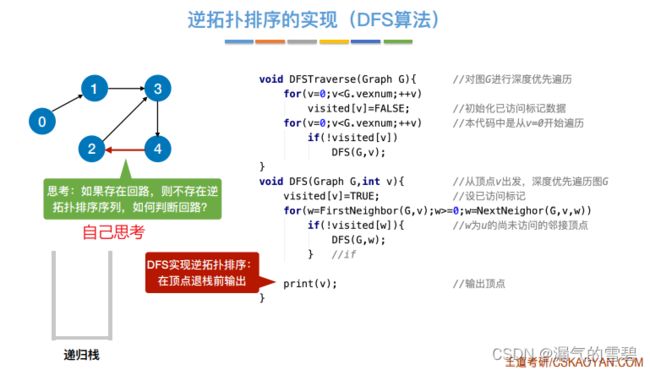
6.逆拓扑序列
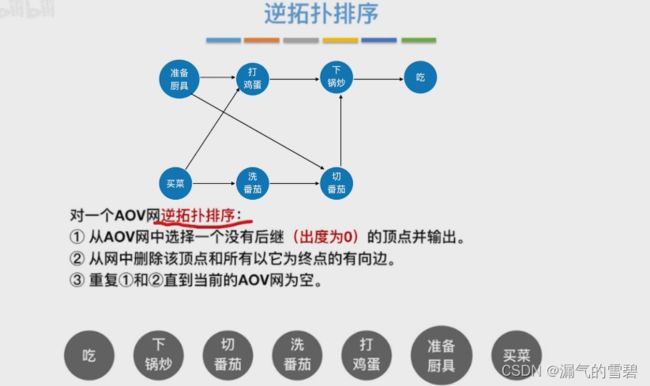

- 还可以借助DFS算法去输出逆拓扑排序序列
- 综合题第九题

7.小结
6.4.5 关键路径
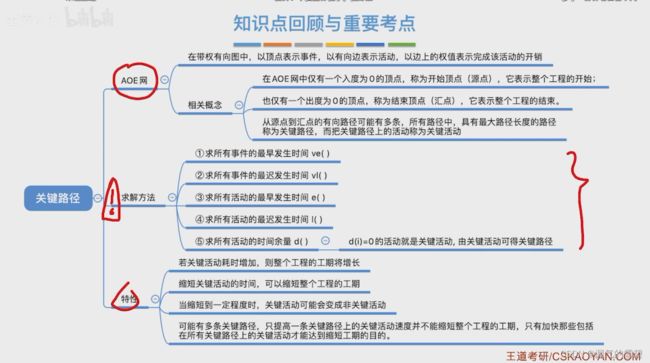
1.AOE网
- Activity On Edge Network,还是有向无环图
- 边代表活动,是一个持续的过程;点代表事件,是瞬间发生的
- AOE网的两个性质
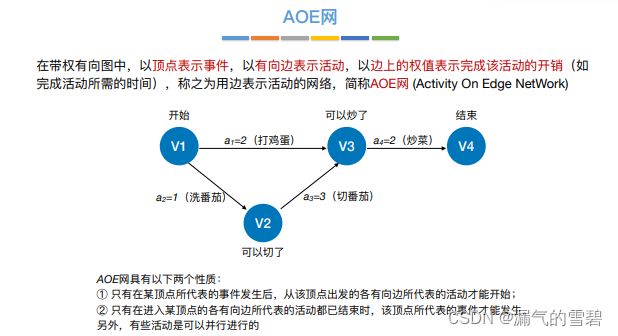
- 在AOE网中只能有一个开始顶点和结束顶点

- 关键路径:最大路径长度的路径(完成工程最少需要的时间)
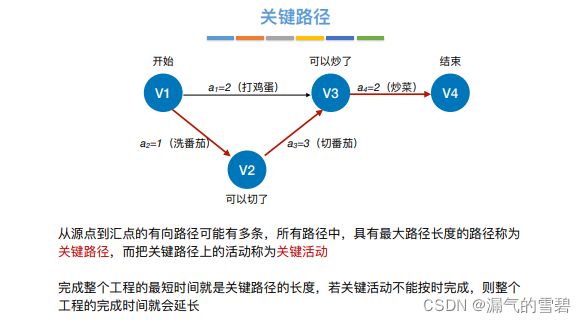
2.事件最早发生时间ve(k)
- 注意!!!是事件,不是活动
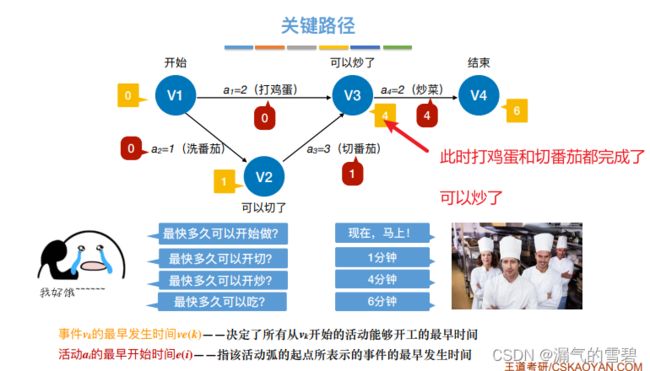
3、事件最迟发生时间vl(k)
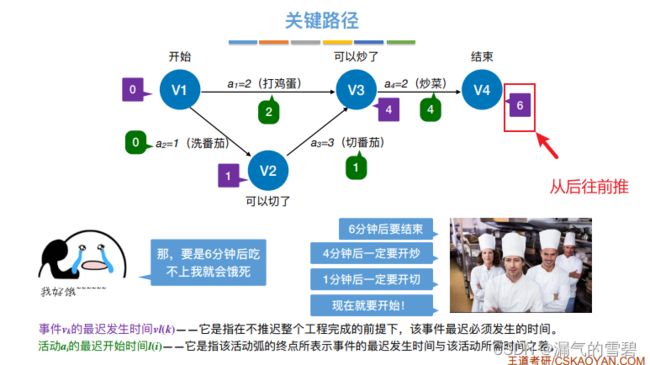
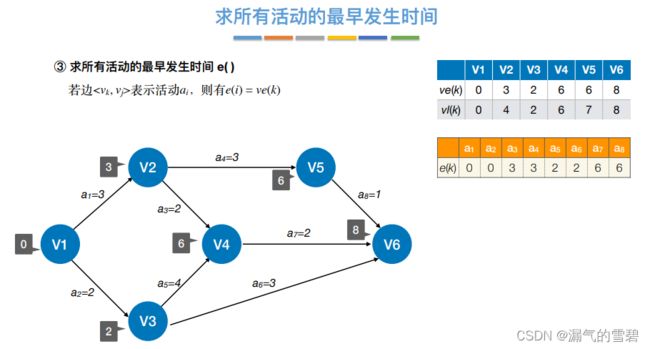
4、活动最早开始时间e(i)
5、活动最迟开始时间l(i)
- 如果e(i)和l(i)看不懂定义,看下面例子就懂了
6、差额——时间余量
- 时间余量:活动的最早开始时间 - 最迟开始时间 = 该活动最多能拖多久
- 关键活动 = 时间余量为0,不能拖延的活动。所以可以通过时间余量来判断是否为关键活动
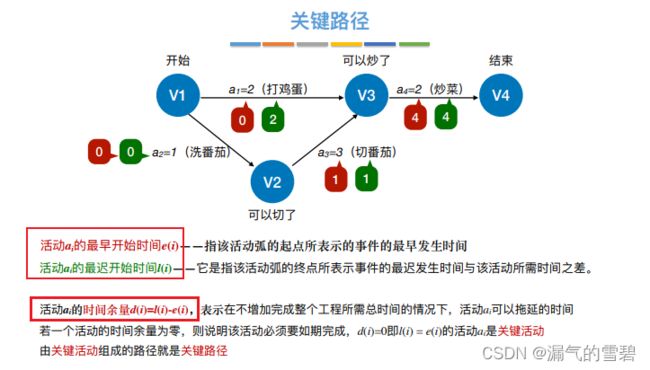
7.求关键路径算法思想
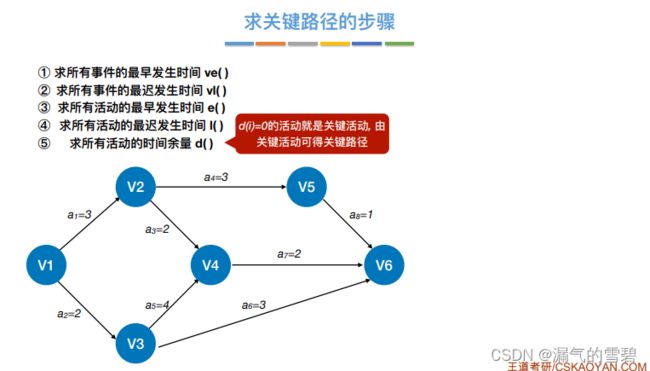
- ① 先得到拓扑序列,在按照拓扑序列顺序求ve()
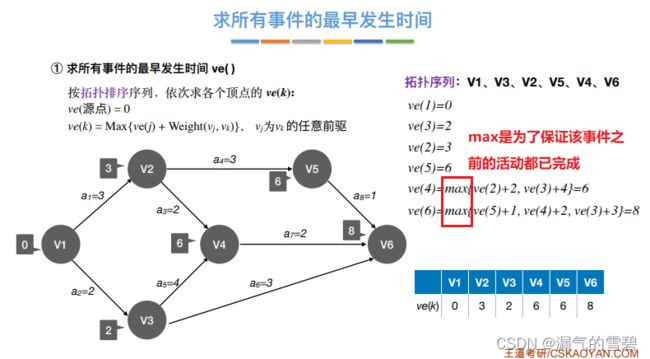
- ② 先得到逆拓扑排序序列
- 每个点看出边,比如v2,就看
和 ;v3就看 和
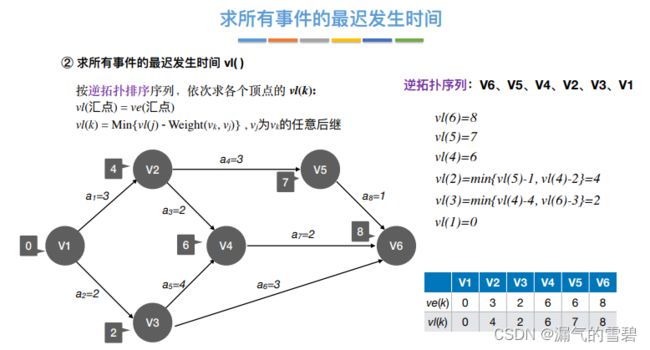
- ③ 活动的最早发生时间取决于弧尾的那个事件的最早开始时间
- 注意!!!活动数不一定等于事件数(点数不一定等于边数)
- ④ 活动的最迟发生时间与活动最早发生时间e()原理差不多,看看上面的笔记
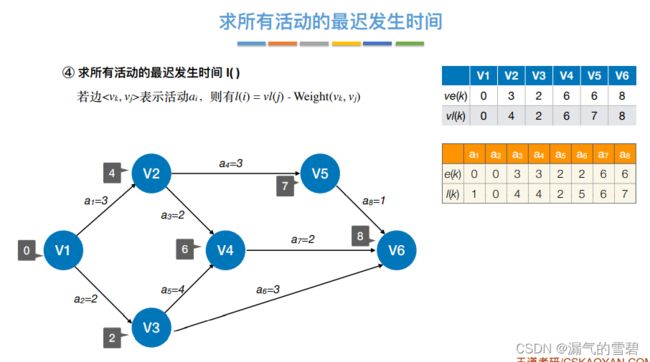
- ⑤ 根据活动余量得到关键路径
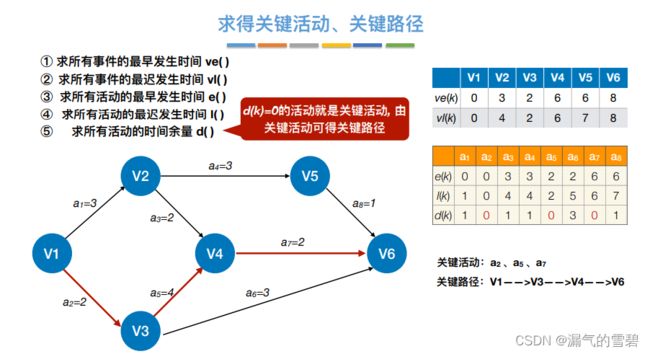
8.关键活动、关键路径的特性
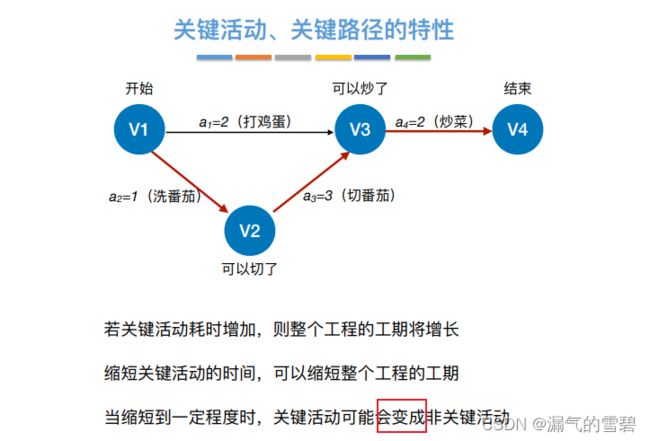
- 下面对关键活动、关键路径的一些特性的分析
- 时刻记住,关键活动就是时间余量为0的活动,也就是不能拖延的活动
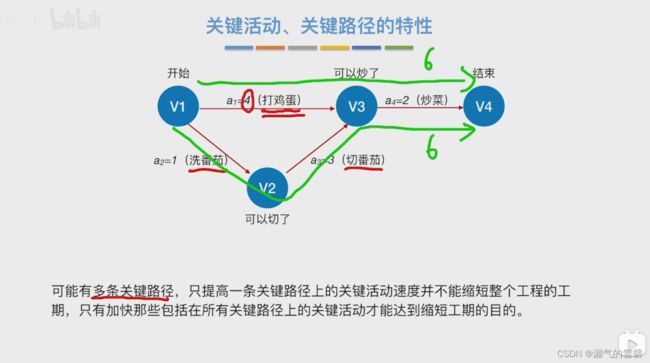
- 在AOE网中的关键路径不一定唯一
9.具体代码实现(未全部实现)
#include
using namespace std;
#define MAX_VERTEX_NUM 16
#define MAX_ARC_NUM 128
int verNum, arcNum; // 图的顶点数和边数
int x, y, z;
int inDegree[MAX_VERTEX_NUM]; // 记录顶点入度
int print[MAX_VERTEX_NUM]; // 记录拓扑序列
int ve[MAX_VERTEX_NUM]; // 事件的最早发生时间
int vl[MAX_VERTEX_NUM]; // 事件的最迟发生时间
int e[MAX_ARC_NUM]; // 活动的最早发生时间
int l[MAX_ARC_NUM]; // 活动的最迟发生时间
int d[MAX_ARC_NUM]; // 活动的时间余量
typedef struct ArcNode // 边链表结点
{
int adjvex;
int info; // 边的权值
struct ArcNode *nextArc;
} ArcNode;
typedef struct VNode // 顶点表结点
{
int data;
ArcNode *firstArc;
} VNode, AdjList[MAX_VERTEX_NUM];
typedef struct {
AdjList vertices; // 邻接表
int verNum, arcNum; // 图的顶点数和弧数
} Graph; // Graph是以邻接表存储的图类型
// !!! 第一步:先求拓扑序列
bool TopologicalSort(Graph g) {
stack s; // 声明辅助栈,用于存储入度为0的顶点
for (int i = 1; i <= g.verNum; i++)
{
if (inDegree[i] == 0)
{
s.push(i); // 将初始所有入度为0的顶点入栈
}
}
int count = 0; // 计数,记录当前已经输出的顶点数
while (!s.empty()) // 栈非空,表示还存在入度为0的顶点
{
int flag;
int v;
ArcNode *p;
flag = s.top();
s.pop(); // 栈顶元素出栈
print[count++] = flag; // 记录输出的顶点
// 本段循环的目的,因为输出栈顶元素,与栈顶顶点相连的顶点的入度减一
for (p = g.vertices[flag].firstArc; p != NULL; p = p->nextArc) {
v = p->adjvex;
if (!(--inDegree[v]))
{
s.push(v); // 入度为0,入栈
}
}
}
if (count < g.verNum) {
return false; // 拓扑排序失败,存在回路
}
return true; // 拓扑排序成功
}
// !!! 第二步:
void EarlistTimeOfVertex(Graph graph, int veList[])
{
for (int i = 0; i < graph.verNum; i++) // 一共有verNum个事件
{
int flag = print[i];
for (int j = 1; j <= graph.verNum; j++)
{
ArcNode *tempArc = graph.vertices[i].firstArc;
while (tempArc != NULL)
{
if (tempArc->adjvex == flag)
{
ve[flag] = max(ve[flag], ve[j] + tempArc->info);
}
tempArc = tempArc->nextArc;
}
}
}
}
void LatestTimeOfVertex(int vlList[])
{
}
void EarlistTimeOfEdge(int eList[])
{
}
void LatestTimeOfEdge(int lList[])
{
}
void CriticalPath(Graph g)
{
}
int main()
{
cin >> verNum >> arcNum;
Graph graph;
graph.verNum = verNum;
graph.arcNum = arcNum;
memset(inDegree, 0, sizeof(inDegree));
memset(print, -1, sizeof(print));
for (int i = 1; i <= verNum; i++)
{
graph.vertices[i].firstArc = NULL;
}
for (int i = 1; i <= arcNum; i++)
{
cin >> x >> y >> z;
inDegree[y]++;
ArcNode *arc = (ArcNode *)malloc(sizeof(ArcNode));
arc->adjvex = y;
arc->info = z;
arc->nextArc = graph.vertices[x].firstArc;
graph.vertices[x].firstArc = arc;
}
if (TopologicalSort(graph))
{
for (int i = 0; i < verNum; i++)
{
cout << "v" << print[i] << " ";
}
}
if (TopologicalSort(graph))
{
EarlistTimeOfVertex(graph, ve);
for (int i = 1; i <= verNum; i++)
{
cout << ve[i] << " , ";
}
}
return 0;
}
10.小结

不实际操作代码,只是粗略过一下知识点,只需 75 分钟左右过一遍