开放定址法
分离链接法由于需要实现两个数据结构,并且需要使用指针操作(分配内存非常耗时),这就使得分离链接法的速度稍慢。开放定址法是另一种解决冲突问题的方法,它不需要任何指针操作,所以性能也就稍微好一点。开放定址法是指,在产生冲突时,就尝试向后找到一个空的单元来存放关键字。开放定址法的算法为
其中,![]() 为产生冲突时重新计算的索引值,
为产生冲突时重新计算的索引值,![]() 为哈希函数,
为哈希函数,![]() 为为解决冲突引入的跟i有关的函数。使用开放定址法时,所有的关键字都要放在散列表中,所以需要的散列表要比分离链接法大(分离链接法关键字都存在链表中)。开放定址法中装填因子λ<=0.5,这是因为当装填因子超过0.5时,插入和删除的开销将会明显的增大,并且TableSize也应该为素数(为了在一定程度上解决冲突和分配不均问题)。并且在平方探测法中,只有<=0.5的装填因子和素数的TableSize才能保证每次探测都能找到一个空单元来存放新元素。
为为解决冲突引入的跟i有关的函数。使用开放定址法时,所有的关键字都要放在散列表中,所以需要的散列表要比分离链接法大(分离链接法关键字都存在链表中)。开放定址法中装填因子λ<=0.5,这是因为当装填因子超过0.5时,插入和删除的开销将会明显的增大,并且TableSize也应该为素数(为了在一定程度上解决冲突和分配不均问题)。并且在平方探测法中,只有<=0.5的装填因子和素数的TableSize才能保证每次探测都能找到一个空单元来存放新元素。
对于开放定址法来说,一次成功的插入实际上等价于一次不成功的查找,这两者的操作是完全相同的,区别仅仅在于当探测到空单元时,执行的是插入还是返回查找失败的信息。
1.线性探测法
在这种方法中,通常选择![]() ,当
,当![]() 时,即没有发生冲突的插入,当发生冲突时,使
时,即没有发生冲突的插入,当发生冲突时,使 从1开始递增,相当于逐个遍历散列值后面的单元,直到找到空单元以插入元素。这个方法容易产生聚集问题,因为被散列到同一个位置的元素可能会形成一个区块。当λ=0.5时,每一次成功的插入只需要平均2.5次探测,而成功的查找则需要平均1.5次探测。当λ增大时,开销将会逐渐大到不能接受,所以希望λ<=0.5.
从1开始递增,相当于逐个遍历散列值后面的单元,直到找到空单元以插入元素。这个方法容易产生聚集问题,因为被散列到同一个位置的元素可能会形成一个区块。当λ=0.5时,每一次成功的插入只需要平均2.5次探测,而成功的查找则需要平均1.5次探测。当λ增大时,开销将会逐渐大到不能接受,所以希望λ<=0.5.
//散列:线性探测法
#include
#include
#include
#define empty -1//单元为空的记号
typedef struct hashlist {//哈希表
int size;
int* val;
}hl;
int nextprime(int doublesize) {//找到大于元素个数的最小素数
int flag = 1;
for (int i = doublesize + 1;; i++) {
for (int j = 2; j <= sqrt(i); j++) {
if (i % j == 0) {
flag = 0;
break;
}
}
if (flag == 1) {
return i;
}
}
}
hl* CreatHashlist() {//初始化哈希表
hl* p = (hl*)malloc(sizeof(hl));
if (p == NULL) {
printf("内存不足\n");
return NULL;
}
int sizet = nextprime(42);
p->size = sizet;
p->val = (int*)malloc(sizeof(int) * p->size);
for (int i = 0; i < p->size; i++) {
p->val[i] = empty;//将所有单元置为空
}
return p;
}
int hash(hl* p, int i) {//hash函数,返回散列的下标
return i % p->size;
}
int hash1(hl* p, int i, int j) {//线性探测法函数,F(i)=i
return hash(p, i) + j % p->size;//由于线性探测法的下标变化与+1是等价的,且调用函数开销大,所以直接逐个遍历散列值之后的各个单元即可
}
void insert(hl* p, int x) {//在对应下标处插入元素
int index = hash1(p, x, 0);
for (int j = 1;; j++) {
if (p->val[index] == empty) {
p->val[index] = x;
break;
}
index = (index + 1) % p->size;//索引每次+1
}
}
int* find(hl* p,int x) {//找到x第一次出现的地址
int index = hash1(p, x, 0);
for (int j = 0;; j++) {
if (p->val[index] == empty || p->val[index] == x) {
return p->val+index;//找到则返回指针,否则返回空单元的指针
}
index = (index + 1) % p->size;//索引每次+1
}
}
void delete(hl* p, int x) {
//对于开放定址法,删除最好使用懒惰删除,只需要给要删除元素做一个记号
//这只需要使用find找到该元素即可,正常的删除会使表中出现空位置,可能会导致find失败
}
int main() {
hl* phl = CreatHashlist();
for (int i = 0; i <= 10; i++) {//插入0-10
insert(phl, i);
}
for (int i = 43; i <= 53; i++) {
insert(phl, i);
}
printf("%d\n", *find(phl, 5));
return 0;
} 2.平方探测法
为了解决线性探测法的聚集问题,流行的选择是![]() .但是对于平方探测法来说,只有当λ<=0.5并且TableSize为素数时,才能保证每一次都能插入成功。下面给出证明:
.但是对于平方探测法来说,只有当λ<=0.5并且TableSize为素数时,才能保证每一次都能插入成功。下面给出证明:
当没有发生冲突时,可以直接插入。问题出在发生冲突的时候:
证明从索引值开始的![]() 个位置是互异的,即
个位置是互异的,即![]() ,假设与
,假设与 为
为![]() 自变量的两个不同取值,那么假设这两个值能够指向同一个位置,那么则有
自变量的两个不同取值,那么假设这两个值能够指向同一个位置,那么则有
又因为![]() 为素数,显然
为素数,显然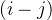 与
与![]() 均不可能是
均不可能是![]() 的因子,又有与互异,所以
的因子,又有与互异,所以![]() ,且
,且 ![]() , 所以
, 所以![]() ,那么等式显然是不成立的,则假设失败,得证。
,那么等式显然是不成立的,则假设失败,得证。
当表中的关键字数量多于![]() 哪怕一个时,插入都有可能是失败的。对于极端情况,所有的关键字都散列在了同一个位置,那么在前
哪怕一个时,插入都有可能是失败的。对于极端情况,所有的关键字都散列在了同一个位置,那么在前![]() 个元素插入时是没有问题的,当再插入一个冲突元素时,就有
个元素插入时是没有问题的,当再插入一个冲突元素时,就有![]() ,那么这个时候就可能出现
,那么这个时候就可能出现![]() ,即插入失败。
,即插入失败。
当表的大小不是素数时,任何一次插入都可能是危险的。例如,表的大小为16,那么就可能只有1,4,9处可以插入,那么当插入第四个冲突元素时,插入就会失败,所以保证表的大小为素数也是非常重要的。
//散列:平方探测法
#include
#include
#include
#define empty -1
typedef struct hashlist {
int size;
int* val;
}hl;
int nextprime(int doublesize) {
int flag = 1;
for (int i = doublesize + 1;; i++) {
for (int j = 2; j <= sqrt(i); j++) {
if (i % j == 0) {
flag = 0;
break;
}
}
if (flag == 1) {
return i;
}
}
}
hl* CreatHashlist() {//哈希表初始化
hl* p = (hl*)malloc(sizeof(hl));
if (p == NULL) {
printf("内存不足\n");
return NULL;
}
int sizet = nextprime(42);
p->size = sizet;
p->val = (int*)malloc(sizeof(int) * p->size);
for (int i = 0; i < p->size; i++) {
p->val[i] = empty;
}
return p;
}
int hash(hl* p, int i) {//hash函数,返回散列的下标
return i % p->size;
}
int hash1(hl* p, int i, int j) {//平方探测法函数
return hash(p, i) + (j * j) % p->size;
}
void insert(hl* p, int x) {//插入
int index = hash1(p, x, 0);
for (int j = 1;; j++) {
if (p->val[index] == empty) {
p->val[index] = x;
break;
}
index = (index + 2 * j - 1) % p->size;//平方探测法下标变化规律,调用函数开销过大
}
}
int* find(hl* p,int x) {//找到x第一次出现的地址
int index = hash1(p, x, 0);
for (int j = 1;; j++) {
if (p->val[index] == empty || p->val[index] == x) {
return p->val+index;
}
index = (index + 2 * j - 1) % p->size;
}
}
void delete(hl* p, int x) {
//对于开放定址法,删除最好使用懒惰删除,只需要给要删除元素做一个记号
//这只需要使用find找到该元素即可,正常的删除会使表中出现空位置,可能会导致find失败
}
int main() {
hl* phl = CreatHashlist();
for (int i = 0; i <= 10; i++) {//插入0-10
insert(phl, i);
}
for (int i = 43; i <= 53; i++) {
insert(phl, i);
}
printf("%d\n", *find(phl, 43));
return 0;
} 3.双散列
双散列具有两个散列函数,通常取![]() ,如果
,如果![]() 选择不恰当,那么其危害将是非常大的。例如,这样的函数可以起到良好的效果,其中R是小于TableSize的素数。但是当表的大小为10时,并且
选择不恰当,那么其危害将是非常大的。例如,这样的函数可以起到良好的效果,其中R是小于TableSize的素数。但是当表的大小为10时,并且![]() 的结果为5,那么在产生冲突的情况下,就只有一个备选位置,所以
的结果为5,那么在产生冲突的情况下,就只有一个备选位置,所以![]() 的选择是至关重要的,使表的大小为素数也是一个很好的选择,当表大小为11时,它至少多提供了一个备选位置。由于双散列有两个散列函数,所以它的性能也较差。
的选择是至关重要的,使表的大小为素数也是一个很好的选择,当表大小为11时,它至少多提供了一个备选位置。由于双散列有两个散列函数,所以它的性能也较差。
//散列:双散列
//双散列的实现方法与之前的两种方法类似,只是多了一个hash函数
#include
#include
#include
#define empty -1
typedef struct hashlist {
int size;
int* val;
}hl;
int nextprime(int doublesize) {
int flag = 1;
for (int i = doublesize + 1;; i++) {
for (int j = 2; j <= sqrt(i); j++) {
if (i % j == 0) {
flag = 0;
break;
}
}
if (flag == 1) {
return i;
}
}
}
hl* CreatHashlist() {//哈希表初始化
hl* p = (hl*)malloc(sizeof(hl));
if (p == NULL) {
printf("内存不足\n");
return NULL;
}
int sizet = nextprime(42);
p->size = sizet;
p->val = (int*)malloc(sizeof(int) * p->size);
for (int i = 0; i < p->size; i++) {
p->val[i] = empty;
}
return p;
}
int hash(hl* p, int x) {//hash函数,返回散列的下标
return x % p->size;
}
int hash1(hl* p, int x, int j) {
return hash(p, x) + (j * (x+1)) % p->size;//假设hash2函数就为x+1
}
void insert(hl* p, int x) {//插入
for (int j = 0;; j++) {
int index = hash1(p, x, j);//每次插入都要调用一次函数,开销很大
if (p->val[index] == empty) {
p->val[index] = x;
break;
}
}
}
int* find(hl* p,int x) {//找到x第一次出现的地址
for (int j = 0;; j++) {
int index = hash1(p, x, j);
if (p->val[index] == empty || p->val[index] == x) {
return p->val+index;
}
}
}
void delete(hl* p, int x) {
//对于开放定址法,删除最好使用懒惰删除,只需要给要删除元素做一个记号
//这只需要使用find找到该元素即可,正常的删除会使表中出现空位置,可能会导致find失败
}
int main() {
hl* phl = CreatHashlist();
for (int i = 0; i <= 10; i++) {//插入0-10
insert(phl, i);
}
for (int i = 43; i <= 53; i++) {
insert(phl, i);
}
printf("%d\n", *find(phl, 4));
return 0;
} 开放定址法的删除:
开放定址法中的删除必须要使用懒惰删除,这是因为发生冲突时,关键字可能已经绕过了这个元素存在了其他位置,并且在进行查找时,终止条件是要么找到该元素,要么遇到空单元。如果不使用懒惰删除,那么绕过这个元素之后存储的其他关键字都没有办法再查找到了,因为find函数执行到这个空单元就会退出。