HBU_神经网络与深度学习 实验12 循环神经网络:梯度爆炸实验
目录
- 一、梯度爆炸实验
-
- 1. 梯度打印函数
- 2. 复现梯度爆炸现象
- 3. 使用梯度截断解决梯度爆炸问题
- 二、实验Q&A
一、梯度爆炸实验
造成简单循环网络较难建模长程依赖问题的原因有两个:梯度爆炸和梯度消失。一般来讲,循环网络的梯度爆炸问题比较容易解决,一般通过权重衰减或梯度截断可以较好地来避免;对于梯度消失问题,更加有效的方式是改变模型,比如通过长短期记忆网络LSTM来进行缓解。
本节将首先进行复现简单循环网络中的梯度爆炸问题,然后尝试使用梯度截断的方式进行解决。这里采用长度为20的数据集进行实验,训练过程中将进行输出 W W W, U U U, b b b的梯度向量的范数,以此来衡量梯度的变化情况。
1. 梯度打印函数
使用custom_print_log实现了在训练过程中打印梯度的功能,custom_print_log需要接收runner的实例,并通过model.named_parameters()获取该模型中的参数名和参数值. 这里我们分别定义W_list, U_list和b_list,用于分别存储训练过程中参数 W , U W, U W,U和 b b b的梯度范数。
import torch
W_list = []
U_list = []
b_list = []
# 计算梯度范数
def custom_print_log(runner):
model = runner.model
W_grad_l2, U_grad_l2, b_grad_l2 = 0, 0, 0
for name, param in model.named_parameters():
if name == "rnn_model.W":
W_grad_l2 = torch.norm(param.grad, p=2).numpy()
if name == "rnn_model.U":
U_grad_l2 = torch.norm(param.grad, p=2).numpy()
if name == "rnn_model.b":
b_grad_l2 = torch.norm(param.grad, p=2).numpy()
print(f"[Training] W_grad_l2: {W_grad_l2:.5f}, U_grad_l2: {U_grad_l2:.5f}, b_grad_l2: {b_grad_l2:.5f} ")
W_list.append(W_grad_l2)
U_list.append(U_grad_l2)
b_list.append(b_grad_l2)
2. 复现梯度爆炸现象
为了更好地复现梯度爆炸问题,使用SGD优化器将批大小和学习率调大,学习率为0.2,同时在计算交叉熵损失时,将reduction设置为sum,表示将损失进行累加。 代码实现如下:
import os
from torch.utils.data import Dataset
import torch.nn as nn
import torch.nn.functional as F
def load_data(data_path):
# 加载训练集
train_examples = []
train_path = os.path.join(data_path, "train.txt")
with open(train_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
train_examples.append((seq, label))
# 加载验证集
dev_examples = []
dev_path = os.path.join(data_path, "dev.txt")
with open(dev_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
dev_examples.append((seq, label))
# 加载测试集
test_examples = []
test_path = os.path.join(data_path, "test.txt")
with open(test_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
test_examples.append((seq, label))
return train_examples, dev_examples, test_examples
class DigitSumDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, idx):
example = self.data[idx]
seq = torch.tensor(example[0], dtype=torch.int64)
label = torch.tensor(example[1], dtype=torch.int64)
return seq, label
def __len__(self):
return len(self.data)
class SRN(nn.Module):
def __init__(self, input_size, hidden_size, W_attr=None, U_attr=None, b_attr=None):
super(SRN, self).__init__()
# 嵌入向量的维度
self.input_size = input_size
# 隐状态的维度
self.hidden_size = hidden_size
# 定义模型参数W,其shape为 input_size x hidden_size
self.W = nn.Parameter(
nn.init.xavier_uniform_(torch.as_tensor(torch.randn([input_size, hidden_size]), dtype=torch.float32),
gain=1.0))
# 定义模型参数U,其shape为hidden_size x hidden_size
self.U = nn.Parameter(
nn.init.xavier_uniform_(torch.as_tensor(torch.randn([hidden_size, hidden_size]), dtype=torch.float32),
gain=1.0))
# 定义模型参数b,其shape为 1 x hidden_size
self.b = nn.Parameter(
nn.init.xavier_uniform_(torch.as_tensor(torch.randn([1, hidden_size]), dtype=torch.float32), gain=1.0))
# 初始化向量
def init_state(self, batch_size):
hidden_state = torch.zeros([batch_size, self.hidden_size], dtype=torch.float32)
return hidden_state
# 定义前向计算
def forward(self, inputs, hidden_state=None):
# inputs: 输入数据, 其shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size = inputs.shape
# 初始化起始状态的隐向量, 其shape为 batch_size x hidden_size
if hidden_state is None:
hidden_state = self.init_state(batch_size)
# 循环执行RNN计算
for step in range(seq_len):
# 获取当前时刻的输入数据step_input, 其shape为 batch_size x input_size
step_input = inputs[:, step, :]
# 获取当前时刻的隐状态向量hidden_state, 其shape为 batch_size x hidden_size
hidden_state = F.tanh(torch.matmul(step_input, self.W) + torch.matmul(hidden_state, self.U) + self.b)
return hidden_state
class Embedding(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super(Embedding, self).__init__()
W_attr = nn.init.xavier_uniform_(
torch.as_tensor(torch.randn([num_embeddings, embedding_dim]), dtype=torch.float32), gain=1.0)
self.W = nn.Parameter(W_attr)
def forward(self, inputs):
# 根据索引获取对应词向量
embs = self.W[inputs]
return embs
class Model_RNN4SeqClass(nn.Module):
def __init__(self, model, num_digits, input_size, hidden_size, num_classes):
super(Model_RNN4SeqClass, self).__init__()
# 传入实例化的RNN层,例如SRN
self.rnn_model = model
# 词典大小
self.num_digits = num_digits
# 嵌入向量的维度
self.input_size = input_size
# 定义Embedding层
self.embedding = Embedding(num_digits, input_size)
# 定义线性层
self.linear = nn.Linear(hidden_size, num_classes)
def forward(self, inputs):
# 将数字序列映射为相应向量
inputs_emb = self.embedding(inputs)
# 调用RNN模型
hidden_state = self.rnn_model(inputs_emb)
# 使用最后一个时刻的状态进行数字预测
logits = self.linear(hidden_state)
return logits
class Accuracy():
def __init__(self, is_logist=True):
"""
输入:
- is_logist: outputs是logits还是激活后的值
"""
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logits = is_logist
def update(self, outputs, labels):
"""
输入:
- outputs: 预测值, shape=[N,class_num]
- labels: 标签值, shape=[N,1]
"""
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1:
if self.is_logist:
# logits判断是否大于0
preds = torch.tensor((outputs >= 0), dtype=torch.float32)
else:
# 如果不是logits,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = torch.tensor((outputs >= 0.5), dtype=torch.float32)
else:
# 多分类时,使用'torch.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1)
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X)
loss = self.loss_fn(logits, y) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
self.optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step != 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
self.dev_losses.append((global_step, dev_loss))
dev_score = self.metric.accumulate()
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
model_state_dict = torch.load(model_path)
self.model.load_state_dict(model_state_dict)
import random
import numpy as np
import torch.utils.data as io
np.random.seed(0)
random.seed(0)
torch.manual_seed(0)
# 训练轮次
num_epochs = 50
# 学习率
lr = 0.2
# 输入数字的类别数
num_digits = 10
# 将数字映射为向量的维度
input_size = 32
# 隐状态向量的维度
hidden_size = 32
# 预测数字的类别数
num_classes = 19
# 批大小
batch_size = 64
# 模型保存目录
save_dir = "./checkpoints"
# 可以设置不同的length进行不同长度数据的预测实验
length = 20
print(f"\n====> Training SRN with data of length {length}.")
# 加载长度为length的数据
data_path = f"./datasets/{length}"
train_examples, dev_examples, test_examples = load_data(data_path)
train_set, dev_set, test_set = DigitSumDataset(train_examples), DigitSumDataset(dev_examples),DigitSumDataset(test_examples)
train_loader = io.DataLoader(train_set, batch_size=batch_size)
dev_loader = io.DataLoader(dev_set, batch_size=batch_size)
test_loader = io.DataLoader(test_set, batch_size=batch_size)
# 实例化模型
base_model = SRN(input_size, hidden_size)
model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)
# 指定优化器
optimizer = torch.optim.SGD(lr=lr, params=model.parameters())
# 定义评价指标
metric = Accuracy()
# 定义损失函数
loss_fn = nn.CrossEntropyLoss(reduction="sum")
# 基于以上组件,实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 进行模型训练
model_save_path = os.path.join(save_dir, f"srn_explosion_model_{length}.pdparams")
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=1,
save_path=model_save_path, custom_print_log=custom_print_log)
代码执行结果:
====> Training SRN with data of length 20.
[Train] epoch: 0/50, step: 0/250, loss: 187.33890
[Training] W_grad_l2: 12.80044, U_grad_l2: 22.88142, b_grad_l2: 10.71495
[Train] epoch: 0/50, step: 1/250, loss: 221.42429
[Training] W_grad_l2: 103.24734, U_grad_l2: 147.62785, b_grad_l2: 31.35710
[Train] epoch: 0/50, step: 2/250, loss: 533.94275
[Training] W_grad_l2: 200.61131, U_grad_l2: 179.43280, b_grad_l2: 34.30972
[Train] epoch: 0/50, step: 3/250, loss: 3125.18799
[Training] W_grad_l2: 5363.01709, U_grad_l2: 2369.35498, b_grad_l2: 472.42404
[Train] epoch: 0/50, step: 4/250, loss: 644.62512
[Training] W_grad_l2: 2.24192, U_grad_l2: 3.76618, b_grad_l2: 0.66577
[Train] epoch: 1/50, step: 5/250, loss: 4674.04590
[Training] W_grad_l2: 292.04446, U_grad_l2: 87.62698, b_grad_l2: 15.49041
[Train] epoch: 1/50, step: 6/250, loss: 3304.71484
[Training] W_grad_l2: 0.10429, U_grad_l2: 0.13475, b_grad_l2: 0.02382
[Train] epoch: 1/50, step: 7/250, loss: 4171.73486
[Training] W_grad_l2: 118.46206, U_grad_l2: 87.97267, b_grad_l2: 15.55152
[Train] epoch: 1/50, step: 8/250, loss: 5873.05127
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 1/50, step: 9/250, loss: 5518.92188
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 2/50, step: 10/250, loss: 14051.46973
[Training] W_grad_l2: 167.58211, U_grad_l2: 54.09096, b_grad_l2: 9.56202
[Train] epoch: 2/50, step: 11/250, loss: 10258.56445
[Training] W_grad_l2: 48.85305, U_grad_l2: 80.35914, b_grad_l2: 14.20563
[Train] epoch: 2/50, step: 12/250, loss: 12806.06055
[Training] W_grad_l2: 1.39469, U_grad_l2: 2.26087, b_grad_l2: 0.39967
[Train] epoch: 2/50, step: 13/250, loss: 10320.66113
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 2/50, step: 14/250, loss: 5947.06348
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 3/50, step: 15/250, loss: 16426.29688
[Training] W_grad_l2: 13.94977, U_grad_l2: 7.98273, b_grad_l2: 1.41116
[Train] epoch: 3/50, step: 16/250, loss: 13908.14258
[Training] W_grad_l2: 5.54336, U_grad_l2: 4.11152, b_grad_l2: 0.72682
[Train] epoch: 3/50, step: 17/250, loss: 11615.14160
[Training] W_grad_l2: 41.29199, U_grad_l2: 14.34644, b_grad_l2: 2.53612
[Train] epoch: 3/50, step: 18/250, loss: 9731.16016
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 3/50, step: 19/250, loss: 5904.46826
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 4/50, step: 20/250, loss: 15839.67969
[Training] W_grad_l2: 45.88194, U_grad_l2: 14.83257, b_grad_l2: 2.62205
[Train] epoch: 4/50, step: 21/250, loss: 10346.28027
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 4/50, step: 22/250, loss: 9398.32129
[Training] W_grad_l2: 18.86115, U_grad_l2: 18.33976, b_grad_l2: 3.24204
[Train] epoch: 4/50, step: 23/250, loss: 8853.66797
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 4/50, step: 24/250, loss: 5783.11133
[Training] W_grad_l2: 93.83669, U_grad_l2: 30.01829, b_grad_l2: 5.30653
[Train] epoch: 5/50, step: 25/250, loss: 12470.64551
[Training] W_grad_l2: 13.36645, U_grad_l2: 10.21049, b_grad_l2: 1.80498
[Train] epoch: 5/50, step: 26/250, loss: 8159.63916
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 5/50, step: 27/250, loss: 8182.23340
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 5/50, step: 28/250, loss: 9197.79492
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 5/50, step: 29/250, loss: 6247.08203
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 6/50, step: 30/250, loss: 16289.69043
[Training] W_grad_l2: 2.04862, U_grad_l2: 0.41925, b_grad_l2: 0.07411
[Train] epoch: 6/50, step: 31/250, loss: 13671.92188
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 6/50, step: 32/250, loss: 12502.65820
[Training] W_grad_l2: 3.08236, U_grad_l2: 3.67292, b_grad_l2: 0.64929
[Train] epoch: 6/50, step: 33/250, loss: 13132.63379
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 6/50, step: 34/250, loss: 8423.58691
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 7/50, step: 35/250, loss: 17256.08008
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 7/50, step: 36/250, loss: 12182.63770
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 7/50, step: 37/250, loss: 7526.67578
[Training] W_grad_l2: 14.88452, U_grad_l2: 18.91519, b_grad_l2: 3.34377
[Train] epoch: 7/50, step: 38/250, loss: 7036.78418
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 7/50, step: 39/250, loss: 8003.67529
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 8/50, step: 40/250, loss: 11239.62207
[Training] W_grad_l2: 6.87094, U_grad_l2: 3.56482, b_grad_l2: 0.63018
[Train] epoch: 8/50, step: 41/250, loss: 12077.02441
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 8/50, step: 42/250, loss: 11625.23145
[Training] W_grad_l2: 5.20250, U_grad_l2: 8.56643, b_grad_l2: 1.51435
[Train] epoch: 8/50, step: 43/250, loss: 12196.15137
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 8/50, step: 44/250, loss: 7177.89307
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 9/50, step: 45/250, loss: 10777.11914
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 9/50, step: 46/250, loss: 14977.98242
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 9/50, step: 47/250, loss: 10350.30957
[Training] W_grad_l2: 11.65160, U_grad_l2: 18.49328, b_grad_l2: 3.26918
[Train] epoch: 9/50, step: 48/250, loss: 6477.22266
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 9/50, step: 49/250, loss: 5376.66846
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 10/50, step: 50/250, loss: 12403.22559
[Training] W_grad_l2: 0.00024, U_grad_l2: 0.00012, b_grad_l2: 0.00002
[Train] epoch: 10/50, step: 51/250, loss: 6592.66406
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 10/50, step: 52/250, loss: 11439.09473
[Training] W_grad_l2: 1.56623, U_grad_l2: 1.62696, b_grad_l2: 0.28761
[Train] epoch: 10/50, step: 53/250, loss: 12249.81445
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 10/50, step: 54/250, loss: 6840.93408
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 11/50, step: 55/250, loss: 13341.84473
[Training] W_grad_l2: 0.67569, U_grad_l2: 0.34548, b_grad_l2: 0.06107
[Train] epoch: 11/50, step: 56/250, loss: 11743.45898
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 11/50, step: 57/250, loss: 10782.78809
[Training] W_grad_l2: 0.33544, U_grad_l2: 0.11154, b_grad_l2: 0.01972
[Train] epoch: 11/50, step: 58/250, loss: 13857.56055
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 11/50, step: 59/250, loss: 7357.09082
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 12/50, step: 60/250, loss: 16929.53711
[Training] W_grad_l2: 0.05002, U_grad_l2: 0.02564, b_grad_l2: 0.00453
[Train] epoch: 12/50, step: 61/250, loss: 13916.70117
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 12/50, step: 62/250, loss: 9060.12500
[Training] W_grad_l2: 16.93189, U_grad_l2: 5.63067, b_grad_l2: 0.99537
[Train] epoch: 12/50, step: 63/250, loss: 9910.73242
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 12/50, step: 64/250, loss: 8733.37793
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 13/50, step: 65/250, loss: 13043.52734
[Training] W_grad_l2: 18.48808, U_grad_l2: 16.34453, b_grad_l2: 2.88933
[Train] epoch: 13/50, step: 66/250, loss: 8138.76221
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 13/50, step: 67/250, loss: 5749.21826
[Training] W_grad_l2: 14.79613, U_grad_l2: 4.93287, b_grad_l2: 0.87202
[Train] epoch: 13/50, step: 68/250, loss: 9617.81543
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 13/50, step: 69/250, loss: 7404.71631
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 14/50, step: 70/250, loss: 11643.27734
[Training] W_grad_l2: 0.00001, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 14/50, step: 71/250, loss: 8856.23438
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 14/50, step: 72/250, loss: 11863.52637
[Training] W_grad_l2: 0.00005, U_grad_l2: 0.00005, b_grad_l2: 0.00001
[Train] epoch: 14/50, step: 73/250, loss: 13513.31152
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 14/50, step: 74/250, loss: 8890.45605
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 15/50, step: 75/250, loss: 13421.10645
[Training] W_grad_l2: 0.06677, U_grad_l2: 0.03423, b_grad_l2: 0.00605
[Train] epoch: 15/50, step: 76/250, loss: 11220.67383
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 15/50, step: 77/250, loss: 16039.65820
[Training] W_grad_l2: 0.00245, U_grad_l2: 0.00269, b_grad_l2: 0.00048
[Train] epoch: 15/50, step: 78/250, loss: 13568.98633
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 15/50, step: 79/250, loss: 5841.26953
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 16/50, step: 80/250, loss: 16642.44922
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 16/50, step: 81/250, loss: 12916.13965
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 16/50, step: 82/250, loss: 6913.00586
[Training] W_grad_l2: 0.00001, U_grad_l2: 0.00001, b_grad_l2: 0.00000
[Train] epoch: 16/50, step: 83/250, loss: 8483.00977
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 16/50, step: 84/250, loss: 8196.67480
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 17/50, step: 85/250, loss: 16244.62402
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 17/50, step: 86/250, loss: 11895.55762
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 17/50, step: 87/250, loss: 11601.02539
[Training] W_grad_l2: 0.00164, U_grad_l2: 0.00180, b_grad_l2: 0.00032
[Train] epoch: 17/50, step: 88/250, loss: 13944.12988
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 17/50, step: 89/250, loss: 11223.18066
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 18/50, step: 90/250, loss: 13846.51465
[Training] W_grad_l2: 0.00049, U_grad_l2: 0.00025, b_grad_l2: 0.00004
[Train] epoch: 18/50, step: 91/250, loss: 7171.44922
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 18/50, step: 92/250, loss: 10672.98145
[Training] W_grad_l2: 0.00085, U_grad_l2: 0.00094, b_grad_l2: 0.00017
[Train] epoch: 18/50, step: 93/250, loss: 9026.11035
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 18/50, step: 94/250, loss: 6807.05176
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 19/50, step: 95/250, loss: 9696.35742
[Training] W_grad_l2: 0.03264, U_grad_l2: 0.01673, b_grad_l2: 0.00296
[Train] epoch: 19/50, step: 96/250, loss: 8199.69922
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 19/50, step: 97/250, loss: 8391.02051
[Training] W_grad_l2: 0.00047, U_grad_l2: 0.00052, b_grad_l2: 0.00009
[Train] epoch: 19/50, step: 98/250, loss: 9808.52051
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 19/50, step: 99/250, loss: 9336.93262
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 20/50, step: 100/250, loss: 15274.14258
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Evaluate] dev score: 0.09000, dev loss: 7846.89233
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.09000
[Train] epoch: 20/50, step: 101/250, loss: 10259.34277
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 20/50, step: 102/250, loss: 9982.84766
[Training] W_grad_l2: 0.00165, U_grad_l2: 0.00181, b_grad_l2: 0.00032
[Train] epoch: 20/50, step: 103/250, loss: 14995.16016
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 20/50, step: 104/250, loss: 6560.11768
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 21/50, step: 105/250, loss: 10999.02246
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 21/50, step: 106/250, loss: 8244.53418
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 21/50, step: 107/250, loss: 12131.26367
[Training] W_grad_l2: 0.00176, U_grad_l2: 0.00194, b_grad_l2: 0.00034
[Train] epoch: 21/50, step: 108/250, loss: 13989.75781
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 21/50, step: 109/250, loss: 10198.82715
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 22/50, step: 110/250, loss: 15357.15430
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 22/50, step: 111/250, loss: 9868.65723
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 22/50, step: 112/250, loss: 8153.82080
[Training] W_grad_l2: 0.00089, U_grad_l2: 0.00098, b_grad_l2: 0.00017
[Train] epoch: 22/50, step: 113/250, loss: 11364.12988
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 22/50, step: 114/250, loss: 8860.96484
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 23/50, step: 115/250, loss: 10234.20117
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 23/50, step: 116/250, loss: 12677.90137
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 23/50, step: 117/250, loss: 8991.14258
[Training] W_grad_l2: 0.00006, U_grad_l2: 0.00007, b_grad_l2: 0.00001
[Train] epoch: 23/50, step: 118/250, loss: 13968.18164
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 23/50, step: 119/250, loss: 9658.68945
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 24/50, step: 120/250, loss: 13687.06543
[Training] W_grad_l2: 0.01260, U_grad_l2: 0.00646, b_grad_l2: 0.00114
[Train] epoch: 24/50, step: 121/250, loss: 11339.29883
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 24/50, step: 122/250, loss: 10719.04297
[Training] W_grad_l2: 0.00010, U_grad_l2: 0.00011, b_grad_l2: 0.00002
[Train] epoch: 24/50, step: 123/250, loss: 12494.19629
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 24/50, step: 124/250, loss: 7506.58984
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 25/50, step: 125/250, loss: 14300.32422
[Training] W_grad_l2: 0.00208, U_grad_l2: 0.00107, b_grad_l2: 0.00019
[Train] epoch: 25/50, step: 126/250, loss: 9153.97949
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 25/50, step: 127/250, loss: 8500.09766
[Training] W_grad_l2: 0.00155, U_grad_l2: 0.00170, b_grad_l2: 0.00030
[Train] epoch: 25/50, step: 128/250, loss: 4254.71240
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 25/50, step: 129/250, loss: 5834.34229
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 26/50, step: 130/250, loss: 12999.72070
[Training] W_grad_l2: 0.00849, U_grad_l2: 0.00435, b_grad_l2: 0.00077
[Train] epoch: 26/50, step: 131/250, loss: 10089.78223
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 26/50, step: 132/250, loss: 8588.38574
[Training] W_grad_l2: 0.00027, U_grad_l2: 0.00029, b_grad_l2: 0.00005
[Train] epoch: 26/50, step: 133/250, loss: 11303.15234
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 26/50, step: 134/250, loss: 9777.67090
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 27/50, step: 135/250, loss: 15848.89453
[Training] W_grad_l2: 0.04723, U_grad_l2: 0.02421, b_grad_l2: 0.00428
[Train] epoch: 27/50, step: 136/250, loss: 11304.50488
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 27/50, step: 137/250, loss: 11285.15820
[Training] W_grad_l2: 0.00090, U_grad_l2: 0.00099, b_grad_l2: 0.00018
[Train] epoch: 27/50, step: 138/250, loss: 18248.30273
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 27/50, step: 139/250, loss: 13651.54004
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 28/50, step: 140/250, loss: 15971.62695
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 28/50, step: 141/250, loss: 8274.06152
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 28/50, step: 142/250, loss: 9668.96387
[Training] W_grad_l2: 0.00102, U_grad_l2: 0.00112, b_grad_l2: 0.00020
[Train] epoch: 28/50, step: 143/250, loss: 14575.00098
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 28/50, step: 144/250, loss: 12399.66211
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 29/50, step: 145/250, loss: 7627.72314
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 29/50, step: 146/250, loss: 9080.53906
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 29/50, step: 147/250, loss: 11665.07715
[Training] W_grad_l2: 0.00010, U_grad_l2: 0.00011, b_grad_l2: 0.00002
[Train] epoch: 29/50, step: 148/250, loss: 11238.30664
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 29/50, step: 149/250, loss: 6378.89502
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 30/50, step: 150/250, loss: 12288.31836
[Training] W_grad_l2: 0.00244, U_grad_l2: 0.00125, b_grad_l2: 0.00022
[Train] epoch: 30/50, step: 151/250, loss: 14163.93262
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 30/50, step: 152/250, loss: 9839.56055
[Training] W_grad_l2: 0.00147, U_grad_l2: 0.00162, b_grad_l2: 0.00029
[Train] epoch: 30/50, step: 153/250, loss: 9842.53125
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 30/50, step: 154/250, loss: 5727.59082
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 31/50, step: 155/250, loss: 17700.87500
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 31/50, step: 156/250, loss: 15288.11914
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 31/50, step: 157/250, loss: 12650.82715
[Training] W_grad_l2: 0.00028, U_grad_l2: 0.00031, b_grad_l2: 0.00005
[Train] epoch: 31/50, step: 158/250, loss: 11290.38672
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 31/50, step: 159/250, loss: 6661.02637
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 32/50, step: 160/250, loss: 10388.16797
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 32/50, step: 161/250, loss: 6543.99316
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 32/50, step: 162/250, loss: 9286.30762
[Training] W_grad_l2: 0.00133, U_grad_l2: 0.00147, b_grad_l2: 0.00026
[Train] epoch: 32/50, step: 163/250, loss: 13614.16309
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 32/50, step: 164/250, loss: 11944.65234
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 33/50, step: 165/250, loss: 12746.70312
[Training] W_grad_l2: 0.00001, U_grad_l2: 0.00001, b_grad_l2: 0.00000
[Train] epoch: 33/50, step: 166/250, loss: 12451.53027
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 33/50, step: 167/250, loss: 11421.63770
[Training] W_grad_l2: 0.00093, U_grad_l2: 0.00102, b_grad_l2: 0.00018
[Train] epoch: 33/50, step: 168/250, loss: 7188.96680
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 33/50, step: 169/250, loss: 3836.26123
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 34/50, step: 170/250, loss: 11686.43945
[Training] W_grad_l2: 0.00013, U_grad_l2: 0.00007, b_grad_l2: 0.00001
[Train] epoch: 34/50, step: 171/250, loss: 8389.69922
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 34/50, step: 172/250, loss: 8526.55859
[Training] W_grad_l2: 0.00026, U_grad_l2: 0.00029, b_grad_l2: 0.00005
[Train] epoch: 34/50, step: 173/250, loss: 12285.33789
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 34/50, step: 174/250, loss: 9106.56250
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 35/50, step: 175/250, loss: 8454.10254
[Training] W_grad_l2: 0.03103, U_grad_l2: 0.01591, b_grad_l2: 0.00281
[Train] epoch: 35/50, step: 176/250, loss: 11969.20215
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 35/50, step: 177/250, loss: 13146.08301
[Training] W_grad_l2: 0.00141, U_grad_l2: 0.00155, b_grad_l2: 0.00027
[Train] epoch: 35/50, step: 178/250, loss: 12432.66016
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 35/50, step: 179/250, loss: 3555.55029
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 36/50, step: 180/250, loss: 9353.03809
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 36/50, step: 181/250, loss: 11563.58691
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 36/50, step: 182/250, loss: 11003.02148
[Training] W_grad_l2: 0.00104, U_grad_l2: 0.00115, b_grad_l2: 0.00020
[Train] epoch: 36/50, step: 183/250, loss: 11676.89160
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 36/50, step: 184/250, loss: 5814.96533
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 37/50, step: 185/250, loss: 14266.54590
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 37/50, step: 186/250, loss: 10666.87012
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 37/50, step: 187/250, loss: 10307.74707
[Training] W_grad_l2: 0.00027, U_grad_l2: 0.00029, b_grad_l2: 0.00005
[Train] epoch: 37/50, step: 188/250, loss: 10051.11426
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 37/50, step: 189/250, loss: 7561.17383
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 38/50, step: 190/250, loss: 11939.53125
[Training] W_grad_l2: 0.00006, U_grad_l2: 0.00003, b_grad_l2: 0.00001
[Train] epoch: 38/50, step: 191/250, loss: 7412.40234
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 38/50, step: 192/250, loss: 11027.68750
[Training] W_grad_l2: 0.00053, U_grad_l2: 0.00058, b_grad_l2: 0.00010
[Train] epoch: 38/50, step: 193/250, loss: 12288.12988
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 38/50, step: 194/250, loss: 7519.22852
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 39/50, step: 195/250, loss: 15555.64551
[Training] W_grad_l2: 0.00001, U_grad_l2: 0.00001, b_grad_l2: 0.00000
[Train] epoch: 39/50, step: 196/250, loss: 6800.20361
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 39/50, step: 197/250, loss: 10476.46973
[Training] W_grad_l2: 0.00171, U_grad_l2: 0.00189, b_grad_l2: 0.00033
[Train] epoch: 39/50, step: 198/250, loss: 10641.51172
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 39/50, step: 199/250, loss: 8737.14551
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 40/50, step: 200/250, loss: 15496.15332
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Evaluate] dev score: 0.07000, dev loss: 8014.69385
[Train] epoch: 40/50, step: 201/250, loss: 11015.66504
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 40/50, step: 202/250, loss: 10963.15918
[Training] W_grad_l2: 0.00010, U_grad_l2: 0.00011, b_grad_l2: 0.00002
[Train] epoch: 40/50, step: 203/250, loss: 10046.79004
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 40/50, step: 204/250, loss: 7274.72607
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 41/50, step: 205/250, loss: 12988.49316
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 41/50, step: 206/250, loss: 12241.19531
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 41/50, step: 207/250, loss: 10923.40527
[Training] W_grad_l2: 0.00100, U_grad_l2: 0.00111, b_grad_l2: 0.00020
[Train] epoch: 41/50, step: 208/250, loss: 12497.59961
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 41/50, step: 209/250, loss: 7158.05762
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 42/50, step: 210/250, loss: 13276.44141
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 42/50, step: 211/250, loss: 11243.46680
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 42/50, step: 212/250, loss: 13018.43652
[Training] W_grad_l2: 0.00101, U_grad_l2: 0.00111, b_grad_l2: 0.00020
[Train] epoch: 42/50, step: 213/250, loss: 15701.31543
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 42/50, step: 214/250, loss: 7933.63818
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 43/50, step: 215/250, loss: 10078.30078
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 43/50, step: 216/250, loss: 9068.29590
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 43/50, step: 217/250, loss: 8521.89746
[Training] W_grad_l2: 0.00069, U_grad_l2: 0.00076, b_grad_l2: 0.00013
[Train] epoch: 43/50, step: 218/250, loss: 9149.67383
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 43/50, step: 219/250, loss: 8709.76367
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 44/50, step: 220/250, loss: 13547.79883
[Training] W_grad_l2: 0.00039, U_grad_l2: 0.00020, b_grad_l2: 0.00004
[Train] epoch: 44/50, step: 221/250, loss: 8860.18555
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 44/50, step: 222/250, loss: 8646.51074
[Training] W_grad_l2: 0.00085, U_grad_l2: 0.00093, b_grad_l2: 0.00016
[Train] epoch: 44/50, step: 223/250, loss: 8830.33105
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 44/50, step: 224/250, loss: 7352.51172
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 45/50, step: 225/250, loss: 16419.32031
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 45/50, step: 226/250, loss: 13410.05957
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 45/50, step: 227/250, loss: 13341.73438
[Training] W_grad_l2: 0.00030, U_grad_l2: 0.00033, b_grad_l2: 0.00006
[Train] epoch: 45/50, step: 228/250, loss: 10030.79688
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 45/50, step: 229/250, loss: 5539.03809
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 46/50, step: 230/250, loss: 13512.27637
[Training] W_grad_l2: 0.00003, U_grad_l2: 0.00001, b_grad_l2: 0.00000
[Train] epoch: 46/50, step: 231/250, loss: 14611.07617
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 46/50, step: 232/250, loss: 10650.63281
[Training] W_grad_l2: 0.00027, U_grad_l2: 0.00030, b_grad_l2: 0.00005
[Train] epoch: 46/50, step: 233/250, loss: 12361.43750
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 46/50, step: 234/250, loss: 8018.79004
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 47/50, step: 235/250, loss: 11428.12012
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 47/50, step: 236/250, loss: 8994.90527
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 47/50, step: 237/250, loss: 10632.74219
[Training] W_grad_l2: 0.00049, U_grad_l2: 0.00054, b_grad_l2: 0.00010
[Train] epoch: 47/50, step: 238/250, loss: 8809.86621
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 47/50, step: 239/250, loss: 8077.95605
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 48/50, step: 240/250, loss: 10156.91895
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 48/50, step: 241/250, loss: 10494.73730
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 48/50, step: 242/250, loss: 13274.91602
[Training] W_grad_l2: 0.00015, U_grad_l2: 0.00017, b_grad_l2: 0.00003
[Train] epoch: 48/50, step: 243/250, loss: 12249.39453
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 48/50, step: 244/250, loss: 7779.82617
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 49/50, step: 245/250, loss: 15581.33301
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 49/50, step: 246/250, loss: 11992.26172
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 49/50, step: 247/250, loss: 10676.45410
[Training] W_grad_l2: 0.00086, U_grad_l2: 0.00094, b_grad_l2: 0.00017
[Train] epoch: 49/50, step: 248/250, loss: 7199.88428
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Train] epoch: 49/50, step: 249/250, loss: 5154.56885
[Training] W_grad_l2: 0.00000, U_grad_l2: 0.00000, b_grad_l2: 0.00000
[Evaluate] dev score: 0.05000, dev loss: 9239.83667
[Train] Training done!
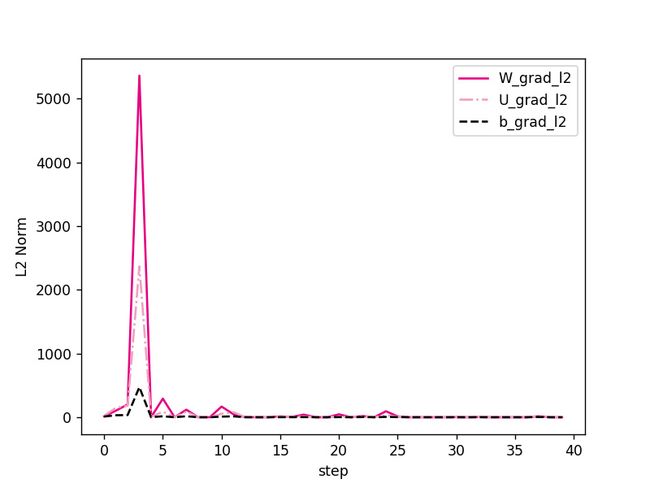
接下来,可以获取训练过程中关于 W \boldsymbol{W} W, U \boldsymbol{U} U和 b \boldsymbol{b} b参数梯度的L2范数,并将其绘制为图片以便展示,相应代码如下:
import matplotlib.pyplot as plt
def plot_grad(W_list, U_list, b_list, save_path, keep_steps=40):
# 开始绘制图片
plt.figure()
# 默认保留前40步的结果
steps = list(range(keep_steps))
plt.plot(steps, W_list[:keep_steps], "r-", color="#e4007f", label="W_grad_l2")
plt.plot(steps, U_list[:keep_steps], "-.", color="#f19ec2", label="U_grad_l2")
plt.plot(steps, b_list[:keep_steps], "--", color="#000000", label="b_grad_l2")
plt.xlabel("step")
plt.ylabel("L2 Norm")
plt.legend(loc="upper right")
plt.savefig(save_path)
plt.show()
print("image has been saved to: ", save_path)
save_path = f"./images/6.8.pdf"
plot_grad(W_list, U_list, b_list, save_path)
代码执行结果:
image has been saved to: ./images/6.8.pdf
图8展示了在训练过程中关于 W \boldsymbol{W} W, U \boldsymbol{U} U和 b \boldsymbol{b} b参数梯度的L2范数,可以看到经过学习率等方式的调整,梯度范数急剧变大,而后梯度范数几乎为0. 这是因为 Tanh \text{Tanh} Tanh为 Sigmoid \text{Sigmoid} Sigmoid型函数,其饱和区的导数接近于0,由于梯度的急剧变化,参数数值变的较大或较小,容易落入梯度饱和区,导致梯度为0,模型很难继续训练.
接下来,使用该模型在测试集上进行测试。
print(f"Evaluate SRN with data length {length}.")
# 加载训练过程中效果最好的模型
model_path = os.path.join(save_dir, f"srn_explosion_model_{length}.pdparams")
runner.load_model(model_path)
# 使用测试集评价模型,获取测试集上的预测准确率
score, _ = runner.evaluate(test_loader)
print(f"[SRN] length:{length}, Score: {score: .5f}")
代码执行结果:
Evaluate SRN with data length 20.
[SRN] length:20, Score: 0.09000
3. 使用梯度截断解决梯度爆炸问题
梯度截断是一种可以有效解决梯度爆炸问题的启发式方法,当梯度的模大于一定阈值时,就将它截断成为一个较小的数。一般有两种截断方式:按值截断和按模截断.本实验使用按模截断的方式解决梯度爆炸问题。
按模截断是按照梯度向量 g \boldsymbol{g} g的模进行截断,保证梯度向量的模值不大于阈值 b b b,裁剪后的梯度为:
g = { g , ∣ ∣ g ∣ ∣ ≤ b b ∣ ∣ g ∣ ∣ ∗ g , ∣ ∣ g ∣ ∣ > b . \boldsymbol{g} = \left\{\begin{matrix} \boldsymbol{g}, & ||\boldsymbol{g}||\leq b \\ \frac{b}{||\boldsymbol{g}||} * \boldsymbol{g}, & ||\boldsymbol{g}||\gt b \end{matrix} \right.. g={g,∣∣g∣∣b∗g,∣∣g∣∣≤b∣∣g∣∣>b.当梯度向量 g \boldsymbol{g} g的模不大于阈值 b b b时, g \boldsymbol{g} g数值不变,否则对 g \boldsymbol{g} g进行数值缩放。
在飞桨中,可以使用paddle.nn.ClipGradByNorm进行按模截断. 在代码实现时,将ClipGradByNorm传入优化器,优化器在反向迭代过程中,每次梯度更新时默认可以对所有梯度裁剪。
在引入梯度截断之后,将重新观察模型的训练情况。这里我们重新实例化一下:模型和优化器,然后组装runner,进行训练。代码实现如下:
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X)
loss = self.loss_fn(logits, y.long()) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
nn.utils.clip_grad_norm_(parameters=self.model.parameters(), max_norm=20, norm_type=2)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
self.optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y.long()).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)
# 清空梯度列表
W_list.clear()
U_list.clear()
b_list.clear()
# 实例化模型
base_model = SRN(input_size, hidden_size)
model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)
# 实例化优化器
optimizer = torch.optim.SGD(lr=lr, params=model.parameters())
# 定义评价指标
metric = Accuracy()
# 定义损失函数
loss_fn = nn.CrossEntropyLoss(reduction="sum")
# 实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 训练模型
model_save_path = os.path.join(save_dir, f"srn_fix_explosion_model_{length}.pdparams")
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=1, save_path=model_save_path,
custom_print_log=custom_print_log)
代码执行结果:
[Train] epoch: 0/50, step: 0/250, loss: 191.19113
[Training] W_grad_l2: 9.77142, U_grad_l2: 23.22682, b_grad_l2: 9.16278
[Train] epoch: 0/50, step: 1/250, loss: 187.56467
[Training] W_grad_l2: 8.46478, U_grad_l2: 24.14869, b_grad_l2: 7.10875
[Train] epoch: 0/50, step: 2/250, loss: 193.40569
[Training] W_grad_l2: 50.47985, U_grad_l2: 136.29224, b_grad_l2: 44.76708
[Train] epoch: 0/50, step: 3/250, loss: 195.68423
[Training] W_grad_l2: 112.39294, U_grad_l2: 320.93066, b_grad_l2: 87.15885
[Train] epoch: 0/50, step: 4/250, loss: 147.48045
[Training] W_grad_l2: 141.51849, U_grad_l2: 591.13690, b_grad_l2: 151.20932
[Train] epoch: 1/50, step: 5/250, loss: 318.99515
[Training] W_grad_l2: 80.89488, U_grad_l2: 304.44910, b_grad_l2: 58.74624
[Train] epoch: 1/50, step: 6/250, loss: 233.86252
[Training] W_grad_l2: 209.59471, U_grad_l2: 1378.73865, b_grad_l2: 204.37102
[Train] epoch: 1/50, step: 7/250, loss: 352.67581
[Training] W_grad_l2: 176.79764, U_grad_l2: 749.02509, b_grad_l2: 212.31845
[Train] epoch: 1/50, step: 8/250, loss: 219.71185
[Training] W_grad_l2: 169.25214, U_grad_l2: 309.05920, b_grad_l2: 199.30928
[Train] epoch: 1/50, step: 9/250, loss: 121.58805
[Training] W_grad_l2: 3.78787, U_grad_l2: 18.88976, b_grad_l2: 2.65012
[Train] epoch: 2/50, step: 10/250, loss: 341.84805
[Training] W_grad_l2: 156.48119, U_grad_l2: 660.51111, b_grad_l2: 132.69991
[Train] epoch: 2/50, step: 11/250, loss: 209.82550
[Training] W_grad_l2: 49.50648, U_grad_l2: 203.17143, b_grad_l2: 24.69456
[Train] epoch: 2/50, step: 12/250, loss: 277.09592
[Training] W_grad_l2: 37.81555, U_grad_l2: 149.59578, b_grad_l2: 27.77646
[Train] epoch: 2/50, step: 13/250, loss: 375.88141
[Training] W_grad_l2: 20.87064, U_grad_l2: 71.49055, b_grad_l2: 12.83915
[Train] epoch: 2/50, step: 14/250, loss: 338.67651
[Training] W_grad_l2: 16.23294, U_grad_l2: 51.78161, b_grad_l2: 9.09618
[Train] epoch: 3/50, step: 15/250, loss: 306.98975
[Training] W_grad_l2: 38.25795, U_grad_l2: 109.93618, b_grad_l2: 17.39710
[Train] epoch: 3/50, step: 16/250, loss: 381.57932
[Training] W_grad_l2: 174.19510, U_grad_l2: 727.13422, b_grad_l2: 105.70969
[Train] epoch: 3/50, step: 17/250, loss: 218.69853
[Training] W_grad_l2: 12.05313, U_grad_l2: 57.75293, b_grad_l2: 7.10639
[Train] epoch: 3/50, step: 18/250, loss: 374.06793
[Training] W_grad_l2: 80.52458, U_grad_l2: 337.75372, b_grad_l2: 38.09431
[Train] epoch: 3/50, step: 19/250, loss: 328.68008
[Training] W_grad_l2: 30.82356, U_grad_l2: 78.80839, b_grad_l2: 14.12911
[Train] epoch: 4/50, step: 20/250, loss: 470.73502
[Training] W_grad_l2: 1.80580, U_grad_l2: 6.87490, b_grad_l2: 1.21887
[Train] epoch: 4/50, step: 21/250, loss: 354.41638
[Training] W_grad_l2: 6.61070, U_grad_l2: 20.54463, b_grad_l2: 3.70227
[Train] epoch: 4/50, step: 22/250, loss: 485.67642
[Training] W_grad_l2: 24.79909, U_grad_l2: 85.50935, b_grad_l2: 15.53261
[Train] epoch: 4/50, step: 23/250, loss: 440.30240
[Training] W_grad_l2: 18.70813, U_grad_l2: 53.18816, b_grad_l2: 9.56029
[Train] epoch: 4/50, step: 24/250, loss: 233.88213
[Training] W_grad_l2: 8.54661, U_grad_l2: 22.29770, b_grad_l2: 4.05093
[Train] epoch: 5/50, step: 25/250, loss: 695.55774
[Training] W_grad_l2: 2.71526, U_grad_l2: 15.77157, b_grad_l2: 2.79018
[Train] epoch: 5/50, step: 26/250, loss: 412.37729
[Training] W_grad_l2: 3.36551, U_grad_l2: 10.51555, b_grad_l2: 1.89840
[Train] epoch: 5/50, step: 27/250, loss: 501.36252
[Training] W_grad_l2: 49.83090, U_grad_l2: 137.60265, b_grad_l2: 24.91082
[Train] epoch: 5/50, step: 28/250, loss: 321.77728
[Training] W_grad_l2: 2.35236, U_grad_l2: 8.76782, b_grad_l2: 1.59452
[Train] epoch: 5/50, step: 29/250, loss: 372.68298
[Training] W_grad_l2: 24.01344, U_grad_l2: 85.48050, b_grad_l2: 15.46340
[Train] epoch: 6/50, step: 30/250, loss: 543.83826
[Training] W_grad_l2: 4.33859, U_grad_l2: 27.45318, b_grad_l2: 4.86343
[Train] epoch: 6/50, step: 31/250, loss: 395.03445
[Training] W_grad_l2: 23.17645, U_grad_l2: 82.34039, b_grad_l2: 14.77127
[Train] epoch: 6/50, step: 32/250, loss: 585.34637
[Training] W_grad_l2: 1.45077, U_grad_l2: 7.59205, b_grad_l2: 1.34537
[Train] epoch: 6/50, step: 33/250, loss: 507.69449
[Training] W_grad_l2: 2.86118, U_grad_l2: 14.20463, b_grad_l2: 2.52609
[Train] epoch: 6/50, step: 34/250, loss: 308.46017
[Training] W_grad_l2: 20.69995, U_grad_l2: 102.18697, b_grad_l2: 18.37080
[Train] epoch: 7/50, step: 35/250, loss: 472.00446
[Training] W_grad_l2: 0.82326, U_grad_l2: 5.57303, b_grad_l2: 0.98587
[Train] epoch: 7/50, step: 36/250, loss: 516.27734
[Training] W_grad_l2: 0.74205, U_grad_l2: 4.92206, b_grad_l2: 0.87072
[Train] epoch: 7/50, step: 37/250, loss: 408.66208
[Training] W_grad_l2: 1.65438, U_grad_l2: 8.58168, b_grad_l2: 1.52129
[Train] epoch: 7/50, step: 38/250, loss: 428.17535
[Training] W_grad_l2: 28.45753, U_grad_l2: 122.00581, b_grad_l2: 21.85336
[Train] epoch: 7/50, step: 39/250, loss: 328.52570
[Training] W_grad_l2: 415.37390, U_grad_l2: 2004.61938, b_grad_l2: 522.95270
[Train] epoch: 8/50, step: 40/250, loss: 629.92450
[Training] W_grad_l2: 0.27509, U_grad_l2: 1.51462, b_grad_l2: 0.26789
[Train] epoch: 8/50, step: 41/250, loss: 506.09866
[Training] W_grad_l2: 0.59996, U_grad_l2: 2.76971, b_grad_l2: 0.48995
[Train] epoch: 8/50, step: 42/250, loss: 543.18964
[Training] W_grad_l2: 0.93258, U_grad_l2: 5.23325, b_grad_l2: 0.92587
[Train] epoch: 8/50, step: 43/250, loss: 400.14301
[Training] W_grad_l2: 1.51683, U_grad_l2: 6.08513, b_grad_l2: 1.07791
[Train] epoch: 8/50, step: 44/250, loss: 203.32805
[Training] W_grad_l2: 2.26183, U_grad_l2: 9.32313, b_grad_l2: 1.65490
[Train] epoch: 9/50, step: 45/250, loss: 752.19086
[Training] W_grad_l2: 19.96792, U_grad_l2: 82.96874, b_grad_l2: 14.90662
[Train] epoch: 9/50, step: 46/250, loss: 608.55566
[Training] W_grad_l2: 0.72788, U_grad_l2: 3.48143, b_grad_l2: 0.61580
[Train] epoch: 9/50, step: 47/250, loss: 426.03839
[Training] W_grad_l2: 0.52636, U_grad_l2: 2.28876, b_grad_l2: 0.40497
[Train] epoch: 9/50, step: 48/250, loss: 447.48242
[Training] W_grad_l2: 0.48772, U_grad_l2: 1.88767, b_grad_l2: 0.33413
[Train] epoch: 9/50, step: 49/250, loss: 241.74951
[Training] W_grad_l2: 0.96201, U_grad_l2: 3.77636, b_grad_l2: 0.66883
[Train] epoch: 10/50, step: 50/250, loss: 775.85211
[Training] W_grad_l2: 5.33461, U_grad_l2: 26.82533, b_grad_l2: 4.75926
[Train] epoch: 10/50, step: 51/250, loss: 452.99133
[Training] W_grad_l2: 37.08391, U_grad_l2: 145.14255, b_grad_l2: 26.42453
[Train] epoch: 10/50, step: 52/250, loss: 553.39581
[Training] W_grad_l2: 3.69806, U_grad_l2: 15.11574, b_grad_l2: 2.69326
[Train] epoch: 10/50, step: 53/250, loss: 372.81415
[Training] W_grad_l2: 1.04727, U_grad_l2: 4.40822, b_grad_l2: 0.78608
[Train] epoch: 10/50, step: 54/250, loss: 320.23892
[Training] W_grad_l2: 1.84182, U_grad_l2: 7.61932, b_grad_l2: 1.35106
[Train] epoch: 11/50, step: 55/250, loss: 624.58929
[Training] W_grad_l2: 0.47815, U_grad_l2: 2.37153, b_grad_l2: 0.41962
[Train] epoch: 11/50, step: 56/250, loss: 435.28894
[Training] W_grad_l2: 0.95783, U_grad_l2: 3.69599, b_grad_l2: 0.65429
[Train] epoch: 11/50, step: 57/250, loss: 596.54883
[Training] W_grad_l2: 1.46154, U_grad_l2: 4.65418, b_grad_l2: 0.82502
[Train] epoch: 11/50, step: 58/250, loss: 545.00629
[Training] W_grad_l2: 22.01771, U_grad_l2: 81.26826, b_grad_l2: 14.45291
[Train] epoch: 11/50, step: 59/250, loss: 323.95773
[Training] W_grad_l2: 1.37802, U_grad_l2: 5.94170, b_grad_l2: 1.05170
[Train] epoch: 12/50, step: 60/250, loss: 615.00995
[Training] W_grad_l2: 11.08852, U_grad_l2: 34.19068, b_grad_l2: 6.07254
[Train] epoch: 12/50, step: 61/250, loss: 469.65771
[Training] W_grad_l2: 0.38698, U_grad_l2: 1.63167, b_grad_l2: 0.28863
[Train] epoch: 12/50, step: 62/250, loss: 453.96539
[Training] W_grad_l2: 0.81325, U_grad_l2: 3.35823, b_grad_l2: 0.59422
[Train] epoch: 12/50, step: 63/250, loss: 504.82281
[Training] W_grad_l2: 0.07228, U_grad_l2: 0.29156, b_grad_l2: 0.05155
[Train] epoch: 12/50, step: 64/250, loss: 398.26767
[Training] W_grad_l2: 1.00136, U_grad_l2: 4.09523, b_grad_l2: 0.72422
[Train] epoch: 13/50, step: 65/250, loss: 856.22394
[Training] W_grad_l2: 4.78301, U_grad_l2: 19.79457, b_grad_l2: 3.50541
[Train] epoch: 13/50, step: 66/250, loss: 570.50568
[Training] W_grad_l2: 4.21683, U_grad_l2: 18.76416, b_grad_l2: 3.36973
[Train] epoch: 13/50, step: 67/250, loss: 535.81598
[Training] W_grad_l2: 2.42237, U_grad_l2: 14.70659, b_grad_l2: 2.60170
[Train] epoch: 13/50, step: 68/250, loss: 443.29031
[Training] W_grad_l2: 17.85309, U_grad_l2: 69.50076, b_grad_l2: 12.39782
[Train] epoch: 13/50, step: 69/250, loss: 254.30666
[Training] W_grad_l2: 0.02699, U_grad_l2: 0.09636, b_grad_l2: 0.01704
[Train] epoch: 14/50, step: 70/250, loss: 769.59619
[Training] W_grad_l2: 0.02251, U_grad_l2: 0.11110, b_grad_l2: 0.01964
[Train] epoch: 14/50, step: 71/250, loss: 611.08374
[Training] W_grad_l2: 0.04356, U_grad_l2: 0.16630, b_grad_l2: 0.02940
[Train] epoch: 14/50, step: 72/250, loss: 601.93488
[Training] W_grad_l2: 0.02282, U_grad_l2: 0.08605, b_grad_l2: 0.01521
[Train] epoch: 14/50, step: 73/250, loss: 439.51086
[Training] W_grad_l2: 0.01753, U_grad_l2: 0.06287, b_grad_l2: 0.01111
[Train] epoch: 14/50, step: 74/250, loss: 286.03436
[Training] W_grad_l2: 0.03454, U_grad_l2: 0.12448, b_grad_l2: 0.02201
[Train] epoch: 15/50, step: 75/250, loss: 611.28265
[Training] W_grad_l2: 0.02976, U_grad_l2: 0.13437, b_grad_l2: 0.02375
[Train] epoch: 15/50, step: 76/250, loss: 488.25687
[Training] W_grad_l2: 0.02460, U_grad_l2: 0.09282, b_grad_l2: 0.01641
[Train] epoch: 15/50, step: 77/250, loss: 438.82996
[Training] W_grad_l2: 0.02485, U_grad_l2: 0.09129, b_grad_l2: 0.01614
[Train] epoch: 15/50, step: 78/250, loss: 452.48483
[Training] W_grad_l2: 0.04533, U_grad_l2: 0.16255, b_grad_l2: 0.02874
[Train] epoch: 15/50, step: 79/250, loss: 333.81598
[Training] W_grad_l2: 0.03861, U_grad_l2: 0.13948, b_grad_l2: 0.02466
[Train] epoch: 16/50, step: 80/250, loss: 722.21979
[Training] W_grad_l2: 0.03179, U_grad_l2: 0.14711, b_grad_l2: 0.02601
[Train] epoch: 16/50, step: 81/250, loss: 570.22260
[Training] W_grad_l2: 0.03117, U_grad_l2: 0.11662, b_grad_l2: 0.02062
[Train] epoch: 16/50, step: 82/250, loss: 684.67377
[Training] W_grad_l2: 0.02442, U_grad_l2: 0.09012, b_grad_l2: 0.01593
[Train] epoch: 16/50, step: 83/250, loss: 505.09085
[Training] W_grad_l2: 0.04857, U_grad_l2: 0.17410, b_grad_l2: 0.03078
[Train] epoch: 16/50, step: 84/250, loss: 254.97507
[Training] W_grad_l2: 0.02458, U_grad_l2: 0.08649, b_grad_l2: 0.01529
[Train] epoch: 17/50, step: 85/250, loss: 696.44666
[Training] W_grad_l2: 0.02517, U_grad_l2: 0.11410, b_grad_l2: 0.02017
[Train] epoch: 17/50, step: 86/250, loss: 478.31757
[Training] W_grad_l2: 0.04080, U_grad_l2: 0.14988, b_grad_l2: 0.02650
[Train] epoch: 17/50, step: 87/250, loss: 583.07446
[Training] W_grad_l2: 0.02456, U_grad_l2: 0.09157, b_grad_l2: 0.01619
[Train] epoch: 17/50, step: 88/250, loss: 373.84607
[Training] W_grad_l2: 0.02610, U_grad_l2: 0.09351, b_grad_l2: 0.01653
[Train] epoch: 17/50, step: 89/250, loss: 314.42816
[Training] W_grad_l2: 0.04260, U_grad_l2: 0.15265, b_grad_l2: 0.02699
[Train] epoch: 18/50, step: 90/250, loss: 792.36621
[Training] W_grad_l2: 0.03893, U_grad_l2: 0.18452, b_grad_l2: 0.03262
[Train] epoch: 18/50, step: 91/250, loss: 472.27164
[Training] W_grad_l2: 0.03707, U_grad_l2: 0.14368, b_grad_l2: 0.02540
[Train] epoch: 18/50, step: 92/250, loss: 485.72617
[Training] W_grad_l2: 0.02111, U_grad_l2: 0.07699, b_grad_l2: 0.01361
[Train] epoch: 18/50, step: 93/250, loss: 371.19275
[Training] W_grad_l2: 0.03144, U_grad_l2: 0.11256, b_grad_l2: 0.01990
[Train] epoch: 18/50, step: 94/250, loss: 383.76270
[Training] W_grad_l2: 0.08130, U_grad_l2: 0.29460, b_grad_l2: 0.05208
[Train] epoch: 19/50, step: 95/250, loss: 756.48389
[Training] W_grad_l2: 0.04021, U_grad_l2: 0.18058, b_grad_l2: 0.03192
[Train] epoch: 19/50, step: 96/250, loss: 559.54700
[Training] W_grad_l2: 0.03753, U_grad_l2: 0.13745, b_grad_l2: 0.02430
[Train] epoch: 19/50, step: 97/250, loss: 528.15204
[Training] W_grad_l2: 0.04760, U_grad_l2: 0.17444, b_grad_l2: 0.03084
[Train] epoch: 19/50, step: 98/250, loss: 600.12183
[Training] W_grad_l2: 0.06080, U_grad_l2: 0.21757, b_grad_l2: 0.03846
[Train] epoch: 19/50, step: 99/250, loss: 368.66388
[Training] W_grad_l2: 0.04178, U_grad_l2: 0.14703, b_grad_l2: 0.02599
[Train] epoch: 20/50, step: 100/250, loss: 792.64258
[Training] W_grad_l2: 0.04776, U_grad_l2: 0.21265, b_grad_l2: 0.03759
[Evaluate] dev score: 0.10000, dev loss: 382.45891
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.10000
[Train] epoch: 20/50, step: 101/250, loss: 516.07452
[Training] W_grad_l2: 0.04342, U_grad_l2: 0.16856, b_grad_l2: 0.02980
[Train] epoch: 20/50, step: 102/250, loss: 500.69739
[Training] W_grad_l2: 0.03642, U_grad_l2: 0.13945, b_grad_l2: 0.02465
[Train] epoch: 20/50, step: 103/250, loss: 467.18439
[Training] W_grad_l2: 0.06183, U_grad_l2: 0.22105, b_grad_l2: 0.03908
[Train] epoch: 20/50, step: 104/250, loss: 274.28052
[Training] W_grad_l2: 0.05663, U_grad_l2: 0.20102, b_grad_l2: 0.03554
[Train] epoch: 21/50, step: 105/250, loss: 569.93799
[Training] W_grad_l2: 0.03797, U_grad_l2: 0.15851, b_grad_l2: 0.02802
[Train] epoch: 21/50, step: 106/250, loss: 487.18765
[Training] W_grad_l2: 0.06914, U_grad_l2: 0.25442, b_grad_l2: 0.04498
[Train] epoch: 21/50, step: 107/250, loss: 486.01822
[Training] W_grad_l2: 0.05838, U_grad_l2: 0.21538, b_grad_l2: 0.03808
[Train] epoch: 21/50, step: 108/250, loss: 457.77261
[Training] W_grad_l2: 0.08986, U_grad_l2: 0.32108, b_grad_l2: 0.05676
[Train] epoch: 21/50, step: 109/250, loss: 273.37070
[Training] W_grad_l2: 0.03570, U_grad_l2: 0.12518, b_grad_l2: 0.02213
[Train] epoch: 22/50, step: 110/250, loss: 795.20685
[Training] W_grad_l2: 0.04763, U_grad_l2: 0.22253, b_grad_l2: 0.03934
[Train] epoch: 22/50, step: 111/250, loss: 497.72177
[Training] W_grad_l2: 0.09207, U_grad_l2: 0.34856, b_grad_l2: 0.06162
[Train] epoch: 22/50, step: 112/250, loss: 626.21545
[Training] W_grad_l2: 0.06433, U_grad_l2: 0.24591, b_grad_l2: 0.04347
[Train] epoch: 22/50, step: 113/250, loss: 624.10425
[Training] W_grad_l2: 0.09338, U_grad_l2: 0.33334, b_grad_l2: 0.05893
[Train] epoch: 22/50, step: 114/250, loss: 319.29843
[Training] W_grad_l2: 0.08050, U_grad_l2: 0.28789, b_grad_l2: 0.05090
[Train] epoch: 23/50, step: 115/250, loss: 781.84900
[Training] W_grad_l2: 0.05492, U_grad_l2: 0.23252, b_grad_l2: 0.04111
[Train] epoch: 23/50, step: 116/250, loss: 559.74945
[Training] W_grad_l2: 0.07090, U_grad_l2: 0.25424, b_grad_l2: 0.04495
[Train] epoch: 23/50, step: 117/250, loss: 514.08350
[Training] W_grad_l2: 0.16059, U_grad_l2: 0.58927, b_grad_l2: 0.10418
[Train] epoch: 23/50, step: 118/250, loss: 618.23492
[Training] W_grad_l2: 0.23796, U_grad_l2: 0.84827, b_grad_l2: 0.14997
[Train] epoch: 23/50, step: 119/250, loss: 334.38132
[Training] W_grad_l2: 0.05135, U_grad_l2: 0.17963, b_grad_l2: 0.03176
[Train] epoch: 24/50, step: 120/250, loss: 522.97986
[Training] W_grad_l2: 0.05167, U_grad_l2: 0.20602, b_grad_l2: 0.03642
[Train] epoch: 24/50, step: 121/250, loss: 406.95230
[Training] W_grad_l2: 0.11420, U_grad_l2: 0.42310, b_grad_l2: 0.07480
[Train] epoch: 24/50, step: 122/250, loss: 534.93158
[Training] W_grad_l2: 0.07722, U_grad_l2: 0.29196, b_grad_l2: 0.05162
[Train] epoch: 24/50, step: 123/250, loss: 483.66696
[Training] W_grad_l2: 0.22309, U_grad_l2: 0.79461, b_grad_l2: 0.14048
[Train] epoch: 24/50, step: 124/250, loss: 345.03830
[Training] W_grad_l2: 0.18420, U_grad_l2: 0.66166, b_grad_l2: 0.11698
[Train] epoch: 25/50, step: 125/250, loss: 768.36322
[Training] W_grad_l2: 0.05788, U_grad_l2: 0.26272, b_grad_l2: 0.04645
[Train] epoch: 25/50, step: 126/250, loss: 564.27356
[Training] W_grad_l2: 0.23731, U_grad_l2: 0.85484, b_grad_l2: 0.15114
[Train] epoch: 25/50, step: 127/250, loss: 398.69714
[Training] W_grad_l2: 0.30371, U_grad_l2: 1.11747, b_grad_l2: 0.19758
[Train] epoch: 25/50, step: 128/250, loss: 519.03778
[Training] W_grad_l2: 0.20870, U_grad_l2: 0.74111, b_grad_l2: 0.13104
[Train] epoch: 25/50, step: 129/250, loss: 288.87057
[Training] W_grad_l2: 0.25591, U_grad_l2: 0.88748, b_grad_l2: 0.15693
[Train] epoch: 26/50, step: 130/250, loss: 583.62122
[Training] W_grad_l2: 0.18332, U_grad_l2: 0.67106, b_grad_l2: 0.11868
[Train] epoch: 26/50, step: 131/250, loss: 303.59576
[Training] W_grad_l2: 0.40967, U_grad_l2: 1.47360, b_grad_l2: 0.26060
[Train] epoch: 26/50, step: 132/250, loss: 507.28894
[Training] W_grad_l2: 0.41239, U_grad_l2: 1.52059, b_grad_l2: 0.26896
[Train] epoch: 26/50, step: 133/250, loss: 487.75787
[Training] W_grad_l2: 1.81127, U_grad_l2: 6.40808, b_grad_l2: 1.13365
[Train] epoch: 26/50, step: 134/250, loss: 465.28333
[Training] W_grad_l2: 6.86590, U_grad_l2: 24.18522, b_grad_l2: 4.29168
[Train] epoch: 27/50, step: 135/250, loss: 889.74316
[Training] W_grad_l2: 1.32950, U_grad_l2: 5.19310, b_grad_l2: 0.91848
[Train] epoch: 27/50, step: 136/250, loss: 488.07901
[Training] W_grad_l2: 0.76371, U_grad_l2: 2.73544, b_grad_l2: 0.48398
[Train] epoch: 27/50, step: 137/250, loss: 460.74127
[Training] W_grad_l2: 0.80551, U_grad_l2: 2.76716, b_grad_l2: 0.48984
[Train] epoch: 27/50, step: 138/250, loss: 386.53308
[Training] W_grad_l2: 0.73056, U_grad_l2: 2.49342, b_grad_l2: 0.44137
[Train] epoch: 27/50, step: 139/250, loss: 329.22372
[Training] W_grad_l2: 2.57977, U_grad_l2: 8.88547, b_grad_l2: 1.57358
[Train] epoch: 28/50, step: 140/250, loss: 728.03632
[Training] W_grad_l2: 12.47762, U_grad_l2: 48.33199, b_grad_l2: 8.59636
[Train] epoch: 28/50, step: 141/250, loss: 474.65793
[Training] W_grad_l2: 9.65037, U_grad_l2: 31.08562, b_grad_l2: 5.54780
[Train] epoch: 28/50, step: 142/250, loss: 505.27750
[Training] W_grad_l2: 1.17885, U_grad_l2: 5.11764, b_grad_l2: 0.90645
[Train] epoch: 28/50, step: 143/250, loss: 457.62567
[Training] W_grad_l2: 5.44920, U_grad_l2: 19.90851, b_grad_l2: 3.53903
[Train] epoch: 28/50, step: 144/250, loss: 225.77400
[Training] W_grad_l2: 3.27857, U_grad_l2: 11.61075, b_grad_l2: 2.05656
[Train] epoch: 29/50, step: 145/250, loss: 713.90149
[Training] W_grad_l2: 5.65601, U_grad_l2: 19.04732, b_grad_l2: 3.41096
[Train] epoch: 29/50, step: 146/250, loss: 522.90784
[Training] W_grad_l2: 6.31978, U_grad_l2: 22.24848, b_grad_l2: 3.95472
[Train] epoch: 29/50, step: 147/250, loss: 378.13211
[Training] W_grad_l2: 18.13773, U_grad_l2: 63.55255, b_grad_l2: 11.34153
[Train] epoch: 29/50, step: 148/250, loss: 481.19626
[Training] W_grad_l2: 1.92164, U_grad_l2: 7.35265, b_grad_l2: 1.30156
[Train] epoch: 29/50, step: 149/250, loss: 327.97861
[Training] W_grad_l2: 3.55192, U_grad_l2: 13.25147, b_grad_l2: 2.35748
[Train] epoch: 30/50, step: 150/250, loss: 722.47461
[Training] W_grad_l2: 0.44697, U_grad_l2: 2.03402, b_grad_l2: 0.35976
[Train] epoch: 30/50, step: 151/250, loss: 441.30203
[Training] W_grad_l2: 0.62440, U_grad_l2: 2.53977, b_grad_l2: 0.44926
[Train] epoch: 30/50, step: 152/250, loss: 660.94727
[Training] W_grad_l2: 1.99606, U_grad_l2: 8.74432, b_grad_l2: 1.54723
[Train] epoch: 30/50, step: 153/250, loss: 470.68372
[Training] W_grad_l2: 1.03312, U_grad_l2: 3.96718, b_grad_l2: 0.70366
[Train] epoch: 30/50, step: 154/250, loss: 379.60251
[Training] W_grad_l2: 7.13931, U_grad_l2: 27.50143, b_grad_l2: 4.88306
[Train] epoch: 31/50, step: 155/250, loss: 553.07172
[Training] W_grad_l2: 17.43257, U_grad_l2: 79.21697, b_grad_l2: 14.17403
[Train] epoch: 31/50, step: 156/250, loss: 440.17993
[Training] W_grad_l2: 4.64605, U_grad_l2: 18.48370, b_grad_l2: 3.29749
[Train] epoch: 31/50, step: 157/250, loss: 473.67340
[Training] W_grad_l2: 0.20177, U_grad_l2: 0.33312, b_grad_l2: 0.05896
[Train] epoch: 31/50, step: 158/250, loss: 395.59137
[Training] W_grad_l2: 1.73493, U_grad_l2: 6.62678, b_grad_l2: 1.17348
[Train] epoch: 31/50, step: 159/250, loss: 218.99725
[Training] W_grad_l2: 2.17103, U_grad_l2: 7.84011, b_grad_l2: 1.39408
[Train] epoch: 32/50, step: 160/250, loss: 747.70410
[Training] W_grad_l2: 0.71057, U_grad_l2: 3.35710, b_grad_l2: 0.59379
[Train] epoch: 32/50, step: 161/250, loss: 442.45825
[Training] W_grad_l2: 0.32682, U_grad_l2: 1.35352, b_grad_l2: 0.23948
[Train] epoch: 32/50, step: 162/250, loss: 415.09149
[Training] W_grad_l2: 0.39100, U_grad_l2: 1.91560, b_grad_l2: 0.33909
[Train] epoch: 32/50, step: 163/250, loss: 435.92953
[Training] W_grad_l2: 0.71442, U_grad_l2: 2.72450, b_grad_l2: 0.48210
[Train] epoch: 32/50, step: 164/250, loss: 325.57718
[Training] W_grad_l2: 0.36851, U_grad_l2: 1.56556, b_grad_l2: 0.27717
[Train] epoch: 33/50, step: 165/250, loss: 793.42340
[Training] W_grad_l2: 8.32177, U_grad_l2: 37.43041, b_grad_l2: 6.63148
[Train] epoch: 33/50, step: 166/250, loss: 432.23706
[Training] W_grad_l2: 4.78768, U_grad_l2: 19.45620, b_grad_l2: 3.45940
[Train] epoch: 33/50, step: 167/250, loss: 524.43274
[Training] W_grad_l2: 0.02629, U_grad_l2: 0.16905, b_grad_l2: 0.02989
[Train] epoch: 33/50, step: 168/250, loss: 394.25488
[Training] W_grad_l2: 0.04333, U_grad_l2: 0.16930, b_grad_l2: 0.02993
[Train] epoch: 33/50, step: 169/250, loss: 320.10721
[Training] W_grad_l2: 0.14476, U_grad_l2: 0.58138, b_grad_l2: 0.10279
[Train] epoch: 34/50, step: 170/250, loss: 808.38318
[Training] W_grad_l2: 0.15002, U_grad_l2: 0.66476, b_grad_l2: 0.11753
[Train] epoch: 34/50, step: 171/250, loss: 482.18402
[Training] W_grad_l2: 0.06380, U_grad_l2: 0.25286, b_grad_l2: 0.04471
[Train] epoch: 34/50, step: 172/250, loss: 594.60901
[Training] W_grad_l2: 0.09255, U_grad_l2: 0.41634, b_grad_l2: 0.07361
[Train] epoch: 34/50, step: 173/250, loss: 579.72833
[Training] W_grad_l2: 0.05771, U_grad_l2: 0.22548, b_grad_l2: 0.03986
[Train] epoch: 34/50, step: 174/250, loss: 304.89725
[Training] W_grad_l2: 0.12119, U_grad_l2: 0.47525, b_grad_l2: 0.08402
[Train] epoch: 35/50, step: 175/250, loss: 629.12091
[Training] W_grad_l2: 0.14744, U_grad_l2: 0.72347, b_grad_l2: 0.12791
[Train] epoch: 35/50, step: 176/250, loss: 485.96179
[Training] W_grad_l2: 0.15254, U_grad_l2: 0.61887, b_grad_l2: 0.10942
[Train] epoch: 35/50, step: 177/250, loss: 680.21686
[Training] W_grad_l2: 0.06201, U_grad_l2: 0.33932, b_grad_l2: 0.05999
[Train] epoch: 35/50, step: 178/250, loss: 569.68115
[Training] W_grad_l2: 0.16826, U_grad_l2: 0.65774, b_grad_l2: 0.11629
[Train] epoch: 35/50, step: 179/250, loss: 259.51276
[Training] W_grad_l2: 0.29621, U_grad_l2: 1.18090, b_grad_l2: 0.20880
[Train] epoch: 36/50, step: 180/250, loss: 680.92993
[Training] W_grad_l2: 0.20047, U_grad_l2: 0.86832, b_grad_l2: 0.15354
[Train] epoch: 36/50, step: 181/250, loss: 555.39246
[Training] W_grad_l2: 0.10910, U_grad_l2: 0.45220, b_grad_l2: 0.07997
[Train] epoch: 36/50, step: 182/250, loss: 451.33124
[Training] W_grad_l2: 0.08206, U_grad_l2: 0.36479, b_grad_l2: 0.06451
[Train] epoch: 36/50, step: 183/250, loss: 418.85043
[Training] W_grad_l2: 0.13312, U_grad_l2: 0.52059, b_grad_l2: 0.09206
[Train] epoch: 36/50, step: 184/250, loss: 357.14185
[Training] W_grad_l2: 0.51523, U_grad_l2: 2.06333, b_grad_l2: 0.36486
[Train] epoch: 37/50, step: 185/250, loss: 766.47217
[Training] W_grad_l2: 0.92030, U_grad_l2: 4.13558, b_grad_l2: 0.73141
[Train] epoch: 37/50, step: 186/250, loss: 520.01825
[Training] W_grad_l2: 1.68845, U_grad_l2: 6.75492, b_grad_l2: 1.19543
[Train] epoch: 37/50, step: 187/250, loss: 539.30206
[Training] W_grad_l2: 3.18834, U_grad_l2: 13.07576, b_grad_l2: 2.32568
[Train] epoch: 37/50, step: 188/250, loss: 431.76535
[Training] W_grad_l2: 0.82095, U_grad_l2: 3.21347, b_grad_l2: 0.56837
[Train] epoch: 37/50, step: 189/250, loss: 291.44812
[Training] W_grad_l2: 0.89525, U_grad_l2: 3.45306, b_grad_l2: 0.61122
[Train] epoch: 38/50, step: 190/250, loss: 575.34015
[Training] W_grad_l2: 4.81738, U_grad_l2: 21.06639, b_grad_l2: 3.73524
[Train] epoch: 38/50, step: 191/250, loss: 361.94189
[Training] W_grad_l2: 8.44933, U_grad_l2: 35.94495, b_grad_l2: 6.45556
[Train] epoch: 38/50, step: 192/250, loss: 588.10669
[Training] W_grad_l2: 1.23509, U_grad_l2: 5.33085, b_grad_l2: 0.94274
[Train] epoch: 38/50, step: 193/250, loss: 584.35583
[Training] W_grad_l2: 0.19344, U_grad_l2: 0.73743, b_grad_l2: 0.13047
[Train] epoch: 38/50, step: 194/250, loss: 399.83795
[Training] W_grad_l2: 0.58027, U_grad_l2: 2.26542, b_grad_l2: 0.40083
[Train] epoch: 39/50, step: 195/250, loss: 699.31354
[Training] W_grad_l2: 2.88793, U_grad_l2: 12.20120, b_grad_l2: 2.15953
[Train] epoch: 39/50, step: 196/250, loss: 513.17999
[Training] W_grad_l2: 5.33526, U_grad_l2: 22.02499, b_grad_l2: 3.92009
[Train] epoch: 39/50, step: 197/250, loss: 596.40887
[Training] W_grad_l2: 4.38561, U_grad_l2: 19.37138, b_grad_l2: 3.43784
[Train] epoch: 39/50, step: 198/250, loss: 486.26877
[Training] W_grad_l2: 8.89735, U_grad_l2: 33.60418, b_grad_l2: 5.97258
[Train] epoch: 39/50, step: 199/250, loss: 288.00137
[Training] W_grad_l2: 2.22265, U_grad_l2: 8.42923, b_grad_l2: 1.49599
[Train] epoch: 40/50, step: 200/250, loss: 425.10037
[Training] W_grad_l2: 15.55009, U_grad_l2: 63.82328, b_grad_l2: 11.51327
[Evaluate] dev score: 0.03000, dev loss: 330.23109
[Train] epoch: 40/50, step: 201/250, loss: 308.38739
[Training] W_grad_l2: 11.66664, U_grad_l2: 45.38746, b_grad_l2: 7.90562
[Train] epoch: 40/50, step: 202/250, loss: 398.68341
[Training] W_grad_l2: 16.91875, U_grad_l2: 69.24651, b_grad_l2: 12.40443
[Train] epoch: 40/50, step: 203/250, loss: 452.95187
[Training] W_grad_l2: 0.13746, U_grad_l2: 0.51200, b_grad_l2: 0.09053
[Train] epoch: 40/50, step: 204/250, loss: 471.17160
[Training] W_grad_l2: 1.05342, U_grad_l2: 3.95703, b_grad_l2: 0.69974
[Train] epoch: 41/50, step: 205/250, loss: 892.60681
[Training] W_grad_l2: 0.84092, U_grad_l2: 3.14111, b_grad_l2: 0.55575
[Train] epoch: 41/50, step: 206/250, loss: 435.45654
[Training] W_grad_l2: 3.27569, U_grad_l2: 12.27817, b_grad_l2: 2.17331
[Train] epoch: 41/50, step: 207/250, loss: 561.98560
[Training] W_grad_l2: 1.91952, U_grad_l2: 6.73629, b_grad_l2: 1.20833
[Train] epoch: 41/50, step: 208/250, loss: 410.02911
[Training] W_grad_l2: 5.91541, U_grad_l2: 21.52220, b_grad_l2: 3.82746
[Train] epoch: 41/50, step: 209/250, loss: 290.04156
[Training] W_grad_l2: 16.20754, U_grad_l2: 21.47470, b_grad_l2: 6.59859
[Train] epoch: 42/50, step: 210/250, loss: 741.79272
[Training] W_grad_l2: 0.13282, U_grad_l2: 0.74420, b_grad_l2: 0.13156
[Train] epoch: 42/50, step: 211/250, loss: 406.98758
[Training] W_grad_l2: 0.03407, U_grad_l2: 0.11467, b_grad_l2: 0.02027
[Train] epoch: 42/50, step: 212/250, loss: 550.06519
[Training] W_grad_l2: 0.04555, U_grad_l2: 0.21582, b_grad_l2: 0.03815
[Train] epoch: 42/50, step: 213/250, loss: 541.97528
[Training] W_grad_l2: 0.06888, U_grad_l2: 0.22357, b_grad_l2: 0.03953
[Train] epoch: 42/50, step: 214/250, loss: 366.08701
[Training] W_grad_l2: 0.04317, U_grad_l2: 0.18110, b_grad_l2: 0.03202
[Train] epoch: 43/50, step: 215/250, loss: 673.69501
[Training] W_grad_l2: 0.20530, U_grad_l2: 1.02855, b_grad_l2: 0.18183
[Train] epoch: 43/50, step: 216/250, loss: 488.06934
[Training] W_grad_l2: 0.04315, U_grad_l2: 0.06728, b_grad_l2: 0.01189
[Train] epoch: 43/50, step: 217/250, loss: 654.52783
[Training] W_grad_l2: 0.19216, U_grad_l2: 1.12917, b_grad_l2: 0.19962
[Train] epoch: 43/50, step: 218/250, loss: 491.76245
[Training] W_grad_l2: 0.08175, U_grad_l2: 0.26554, b_grad_l2: 0.04695
[Train] epoch: 43/50, step: 219/250, loss: 386.74698
[Training] W_grad_l2: 0.08926, U_grad_l2: 0.40291, b_grad_l2: 0.07123
[Train] epoch: 44/50, step: 220/250, loss: 516.45050
[Training] W_grad_l2: 0.12212, U_grad_l2: 0.55350, b_grad_l2: 0.09785
[Train] epoch: 44/50, step: 221/250, loss: 430.12985
[Training] W_grad_l2: 0.07644, U_grad_l2: 0.25611, b_grad_l2: 0.04528
[Train] epoch: 44/50, step: 222/250, loss: 669.72510
[Training] W_grad_l2: 0.15180, U_grad_l2: 1.07324, b_grad_l2: 0.18973
[Train] epoch: 44/50, step: 223/250, loss: 644.41235
[Training] W_grad_l2: 0.03684, U_grad_l2: 0.11893, b_grad_l2: 0.02103
[Train] epoch: 44/50, step: 224/250, loss: 402.68860
[Training] W_grad_l2: 0.05198, U_grad_l2: 0.21871, b_grad_l2: 0.03867
[Train] epoch: 45/50, step: 225/250, loss: 655.98285
[Training] W_grad_l2: 0.26711, U_grad_l2: 1.03185, b_grad_l2: 0.18242
[Train] epoch: 45/50, step: 226/250, loss: 469.73831
[Training] W_grad_l2: 0.09585, U_grad_l2: 0.33275, b_grad_l2: 0.05883
[Train] epoch: 45/50, step: 227/250, loss: 440.35995
[Training] W_grad_l2: 0.26552, U_grad_l2: 1.86198, b_grad_l2: 0.32917
[Train] epoch: 45/50, step: 228/250, loss: 366.95670
[Training] W_grad_l2: 0.03560, U_grad_l2: 0.11629, b_grad_l2: 0.02056
[Train] epoch: 45/50, step: 229/250, loss: 324.47607
[Training] W_grad_l2: 0.08875, U_grad_l2: 0.38430, b_grad_l2: 0.06794
[Train] epoch: 46/50, step: 230/250, loss: 780.87921
[Training] W_grad_l2: 0.37266, U_grad_l2: 1.99958, b_grad_l2: 0.35350
[Train] epoch: 46/50, step: 231/250, loss: 445.09885
[Training] W_grad_l2: 0.08733, U_grad_l2: 0.34090, b_grad_l2: 0.06027
[Train] epoch: 46/50, step: 232/250, loss: 648.11053
[Training] W_grad_l2: 0.15186, U_grad_l2: 0.76739, b_grad_l2: 0.13566
[Train] epoch: 46/50, step: 233/250, loss: 471.24243
[Training] W_grad_l2: 0.09038, U_grad_l2: 0.29421, b_grad_l2: 0.05202
[Train] epoch: 46/50, step: 234/250, loss: 415.12180
[Training] W_grad_l2: 0.08884, U_grad_l2: 0.31844, b_grad_l2: 0.05630
[Train] epoch: 47/50, step: 235/250, loss: 607.35223
[Training] W_grad_l2: 0.34305, U_grad_l2: 1.49894, b_grad_l2: 0.26499
[Train] epoch: 47/50, step: 236/250, loss: 533.97662
[Training] W_grad_l2: 0.13209, U_grad_l2: 0.35441, b_grad_l2: 0.06266
[Train] epoch: 47/50, step: 237/250, loss: 349.45224
[Training] W_grad_l2: 0.24583, U_grad_l2: 1.61124, b_grad_l2: 0.28485
[Train] epoch: 47/50, step: 238/250, loss: 397.48767
[Training] W_grad_l2: 0.05553, U_grad_l2: 0.18197, b_grad_l2: 0.03217
[Train] epoch: 47/50, step: 239/250, loss: 352.43097
[Training] W_grad_l2: 0.17168, U_grad_l2: 0.84171, b_grad_l2: 0.14882
[Train] epoch: 48/50, step: 240/250, loss: 809.35669
[Training] W_grad_l2: 0.63682, U_grad_l2: 3.78852, b_grad_l2: 0.66977
[Train] epoch: 48/50, step: 241/250, loss: 569.18591
[Training] W_grad_l2: 0.23340, U_grad_l2: 0.66855, b_grad_l2: 0.11822
[Train] epoch: 48/50, step: 242/250, loss: 603.24976
[Training] W_grad_l2: 0.47132, U_grad_l2: 2.23316, b_grad_l2: 0.39482
[Train] epoch: 48/50, step: 243/250, loss: 496.09125
[Training] W_grad_l2: 0.37963, U_grad_l2: 1.22443, b_grad_l2: 0.21652
[Train] epoch: 48/50, step: 244/250, loss: 254.58241
[Training] W_grad_l2: 0.29842, U_grad_l2: 1.56366, b_grad_l2: 0.27654
[Train] epoch: 49/50, step: 245/250, loss: 582.82874
[Training] W_grad_l2: 0.54533, U_grad_l2: 1.19369, b_grad_l2: 0.21105
[Train] epoch: 49/50, step: 246/250, loss: 594.29456
[Training] W_grad_l2: 0.66277, U_grad_l2: 3.22464, b_grad_l2: 0.57019
[Train] epoch: 49/50, step: 247/250, loss: 441.39444
[Training] W_grad_l2: 1.01475, U_grad_l2: 3.09549, b_grad_l2: 0.54741
[Train] epoch: 49/50, step: 248/250, loss: 506.79800
[Training] W_grad_l2: 0.86782, U_grad_l2: 2.82057, b_grad_l2: 0.49902
[Train] epoch: 49/50, step: 249/250, loss: 369.00723
[Training] W_grad_l2: 1.85944, U_grad_l2: 7.22667, b_grad_l2: 1.27900
[Evaluate] dev score: 0.04000, dev loss: 519.86024
[Train] Training done!
在引入梯度截断后,获取训练过程中关于 W \boldsymbol{W} W, U \boldsymbol{U} U和 b \boldsymbol{b} b参数梯度的L2范数,并将其绘制为图片以便展示,相应代码如下:
save_path = f"./images/6.9.pdf"
plot_grad(W_list, U_list, b_list, save_path, keep_steps=100)
代码执行结果:
image has been saved to: ./images/6.9.pdf
图9展示了引入按模截断的策略之后,模型训练时参数梯度的变化情况。可以看到,随着迭代步骤的进行,梯度始终保持在一个有值的状态,表明按模截断能够很好地解决梯度爆炸的问题.

接下来,使用梯度截断策略的模型在测试集上进行测试。
print(f"Evaluate SRN with data length {length}.")
# 加载训练过程中效果最好的模型
model_path = os.path.join(save_dir, f"srn_fix_explosion_model_{length}.pdparams")
runner.load_model(model_path)
# 使用测试集评价模型,获取测试集上的预测准确率
score, _ = runner.evaluate(test_loader)
print(f"[SRN] length:{length}, Score: {score: .5f}")
代码执行结果:
Evaluate SRN with data length 20.
[SRN] length:20, Score: 0.10000
由于为复现梯度爆炸现象,改变了学习率,优化器等,因此准确率相对比较低。但由于采用梯度截断策略后,在后续训练过程中,模型参数能够被更新优化,因此准确率有一定的提升。
二、实验Q&A
什么是范数,什么是L2范数,这里为什么要打印梯度范数?
范数一般用来度量某个向量空间(或矩阵)中的每个向量的长度或大小,L2范数相当于各个范数的平方和。
由于本次实验的主要内容是梯度爆炸,所以此处梯度范数的目的是监测梯度的变化。
梯度截断解决梯度爆炸问题的原理是什么?
在梯度的值超出可接受范围值时,直接重置梯度值。