LLM实战(一)| 使用LLM抽取关键词
抽取关键词是NLP的常见任务之一,常用的方法有TFIDF、PageRank、TextRank方法等等。在Bert时代,可以使用KeyBERT(https://github.com/MaartenGr/KeyBERT)来抽取关键词,在ChatGPT时代,KeyBERT也扩展支持了LLM,本文我们将介绍使用KeyBERT的LLM功能来抽取关键词。
下面使用Mistral 7B大模型来抽取关键词,由于transformer库不支持Mistral 7B,因此安装sentence-transformers
pip install --upgrade git+https://github.com/UKPLab/sentence-transformerspip install keybert ctransformers[cuda]pip install --upgrade git+https://github.com/huggingface/transformers
加载模型
加载模型并卸载模型50层到GPU,这样会减少RAM的使用,转而使用VRAM。如果遇到内存错误,可以继续减少此参数(gpu_layers)。
from ctransformers import AutoModelForCausalLM# Set gpu_layers to the number of layers to offload to GPU.# Set to 0 if no GPU acceleration is available on your system.model = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF",model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf",model_type="mistral",gpu_layers=50,hf=True)
使用sentence-transformers加载完模型之后,我们就可以继续使用transformers库来构建pipeline,包括tokenizer。
from transformers import AutoTokenizer, pipeline# Tokenizertokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")# Pipelinegenerator = pipeline(model=model, tokenizer=tokenizer,task='text-generation',max_new_tokens=50,repetition_penalty=1.1)
Prompt工程
先看一个简单的例子
>>> response = generator("What is 1+1?")>>> print(response[0]["generated_text"])"""What is 1+1?A: 2"""
下面我们看一下关键词抽取的效果
prompt = """I have the following document:* The website mentions that it only takes a couple of days to deliver but I still have not received mineExtract 5 keywords from that document."""response = generator(prompt)print(response[0]["generated_text"])
输出如下结果:
"""I have the following document:* The website mentions that it only takes a couple of days to deliver but I still have not received mineExtract 5 keywords from that document.**Answer:**1. Website2. Mentions3. Deliver4. Couple5. Days"""
如果我们希望无论输入文本如何,输出的结构都保持一致,我们就必须给LLM举一个例子。这就是更高级的提示工程的用武之地。与大多数大型语言模型一样,Mistral 7B需要特定的提示格式,如下图所示:
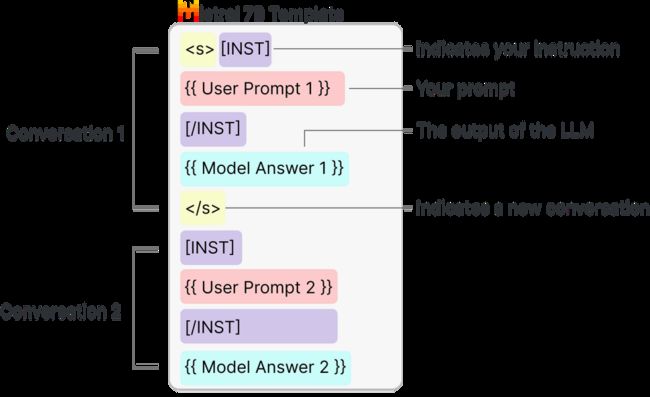
基于上述Mistral 7B Prompt模板,我们构建关键词抽取Prompt,包括Example Prompt和Keyword Prompt,Example Prompt是抽取关键词的一个Prompt样例,Keyword Prompt是让LLM输出关键词的Prompt,下面展示一个例子:
example_prompt = """[INST]I have the following document:- The website mentions that it only takes a couple of days to deliver but I still have not received mine.Please give me the keywords that are present in this document and separate them with commas.Make sure you to only return the keywords and say nothing else. For example, don't say:"Here are the keywords present in the document"[/INST] meat, beef, eat, eating, emissions, steak, food, health, processed, chicken"""
Keyword Prompt充分利用了KeyBERT的 [DOCUMENT] 标签表示下面是文档:
keyword_prompt = """[INST]I have the following document:- [DOCUMENT]Please give me the keywords that are present in this document and separate them with commas.Make sure you to only return the keywords and say nothing else. For example, don't say:"Here are the keywords present in the document"[/INST]"""
关键词抽取的完整Prompt需要合并Example Prompt和Keyword Prompt,代码如下:
>>> prompt = example_prompt + keyword_prompt>>> print(prompt)"""[INST]I have the following document:- The website mentions that it only takes a couple of days to deliver but I still have not received mine.Please give me the keywords that are present in this document and separate them with commas.Make sure you to only return the keywords and say nothing else. For example, don't say:"Here are the keywords present in the document"[/INST] meat, beef, eat, eating, emissions, steak, food, health, processed, chicken[INST]I have the following document:- [DOCUMENT]Please give me the keywords that are present in this document and separate them with commas.Make sure you to only return the keywords and say nothing else. For example, don't say:"Here are the keywords present in the document"[/INST]"""
使用KeyLLM抽取关键词
from keybert.llm import TextGenerationfrom keybert import KeyLLM# Load it in KeyLLMllm = TextGeneration(generator, prompt=prompt)kw_model = KeyLLM(llm)
documents = ["The website mentions that it only takes a couple of days to deliver but I still have not received mine.","I received my package!","Whereas the most powerful LLMs have generally been accessible only through limited APIs (if at all), Meta released LLaMA's model weights to the research community under a noncommercial license."]keywords = kw_model.extract_keywords(documents)
输出如下内容:
[['deliver','days','website','mention','couple','still','receive','mine'],['package', 'received'],['LLM','API','accessibility','release','license','research','community','model','weights','Meta']]
可以随意使用提示来指定要提取的关键字类型、关键字的长度,甚至如果LLM是多语言的,还可以使用哪种语言返回关键字。
切换其他LLM,比如ChatGPT,可以参考:https://maartengr.github.io/KeyBERT/guides/llms.html
更高效使用KeyLLM抽取关键词
在成千上万个文档上重复使用LLM并不是最有效的方法!其实,我们可以对文档先进行聚类,然后再提取关键词。其工作原理如下:首先,我们embedding所有文档,并将它们转换为数字表示;其次,找出哪些文档彼此最相似,假设高度相似的文档将具有相同的关键字,因此不需要为所有文档提取关键字。第三,只从每个聚类中的一个文档中提取关键字,并将关键字分配给同一聚类中的所有文档。

from keybert import KeyLLMfrom sentence_transformers import SentenceTransformer# Extract embeddingsmodel = SentenceTransformer('BAAI/bge-small-en-v1.5')embeddings = model.encode(documents, convert_to_tensor=True)# Load it in KeyLLMkw_model = KeyLLM(llm)# Extract keywordskeywords = kw_model.extract_keywords(documents,embeddings=embeddings,threshold=.5)
threshold增加到大约.95将识别几乎相同的文档,而将其设置为大约.5将识别关于相同主题的文档。
输出关键词如下:
>>> keywords[['deliver','days','website','mention','couple','still','receive','mine'],['deliver','days','website','mention','couple','still','receive','mine'],['LLaMA','model','weights','release','noncommercial','license','research','community','powerful','LLMs','APIs']]
在这个示例中,我们可以看到前两个文档被聚集在一起,并接收到相同的关键字。我们没有将所有三个文档都传递给LLM,而是只传递了两个文档。如果你有成千上万的文档,这可以大大加快速度。
更高效使用KeyBERT和KeyLLM抽取关键词
之前的例子中,我们手动将文档embedding传递给KeyLLM,基本上是对关键字进行零样本提取。我们可以利用KeyBERT来进一步扩展这个例子。由于KeyBERT可以生成关键字并对文档,我们可以利用它不仅简化管道,而且向LLM建议一些关键字。这些建议的关键字可以帮助LLM决定要使用的关键字。此外,它允许KeyBERT中的所有内容与KeyLLM一起使用!

使用KeyBERT和KeyLLM抽取关键词只需要三行代码,如下:
from keybert import KeyLLM, KeyBERT# Load it in KeyLLMkw_model = KeyBERT(llm=llm, model='BAAI/bge-small-en-v1.5')# Extract keywordskeywords = kw_model.extract_keywords(documents, threshold=0.5)
输出如下:
>>> keywords[['deliver','days','website','mention','couple','still','receive','mine'],['deliver','days','website','mention','couple','still','receive','mine'],['LLaMA','model','weights','release','license','research','community','powerful','LLMs','APIs','accessibility']]
参考文献:
[1] https://towardsdatascience.com/introducing-keyllm-keyword-extraction-with-llms-39924b504813
[2] https://maartengr.github.io/KeyBERT/guides/keyllm.html