ReLU激活函数
LeakyReLU激活函数的具体用法请查看此篇博客:LeakyReLU激活函数
ReLU(Rectified Linear Unit)激活函数是深度学习中最常用的激活函数之一,它的数学表达式如下:


在这里,(x) 是输入,(f(x)) 是输出。ReLU激活函数的使用非常简单,它将输入(x)的所有负值变为零,而保持正值不变。这个激活函数具有以下用途和优点:
(1) 非线性映射:ReLU引入了非线性性质,使神经网络可以学习和表示非线性函数关系。这对于捕捉复杂的数据模式和特征非常重要。
(2)计算高效:ReLU计算非常简单,因为它只涉及一个比较和一个取最大值的操作。这使得训练神经网络更加高效。
(3) 缓解梯度消失问题:相比于一些其他激活函数,如Sigmoid和Tanh,ReLU在反向传播时有更大的梯度,可以缓解梯度消失问题,有助于更好地训练深层神经网络。
(4) 稀疏激活性质:在训练期间,一些神经元可能会因为输入值小于零而变得不活跃,这有助于网络的稀疏表示,从而增强了特征的分离性。
虽然ReLU激活函数有很多优点,但也存在一个缺点,即它可能导致神经元的"死亡"问题。这发生在训练期间,当某个神经元的权重更新导致该神经元对所有输入都产生负值输出,从而在以后的训练中一直保持不活跃。为了缓解这个问题,可以使用一些变种,如Leaky ReLU、Parametric ReLU(PReLU)或Exponential Linear Unit(ELU),它们允许小的负值输出,以提高训练的稳定性。选择哪种激活函数取决于具体的任务和网络架构。
本文主要包括以下内容:
- 1. nn.ReLU的常见用法
- 2. ReLU激活函数图像实现
- 3.ReLU激活函数与Leaky ReLU 函数的不同之处
1. nn.ReLU的常见用法
在深度学习框架(如PyTorch、TensorFlow等)中,nn.ReLU 是一个常用的ReLU激活函数的实现。它通常用于神经网络层的构建,以引入非线性映射。以下是一个简单的示例,说明如何在PyTorch中使用nn.ReLU函数构建一个具有ReLU激活的神经网络层:
import torch
import torch.nn as nn
# 创建一个具有ReLU激活函数的全连接层
input_size = 10
output_size = 5
# 构建神经网络层
layer = nn.Linear(input_size, output_size)
activation = nn.ReLU()
# 输入数据
input_data = torch.randn(1, input_size) # 1个样本,输入特征维度为input_size
# 前向传播
output = layer(input_data)
output_with_relu = activation(output)
# 输出
print("Linear层输入:")
print(input_data)
print("原始输出:")
print(output)
print("经过ReLU激活后的输出:")
print(output_with_relu)
#输出结果
#Linear层输入:
#tensor([[ 0.3462, 0.1461, 0.5487, 0.4915, -0.4398, -0.9100, -0.9388, -0.0821, 0.1354, -0.7431]])
#原始输出:
#tensor([[ 0.3832, -0.0762, 0.3498, -0.0882, -0.0115]], grad_fn=)
#经过ReLU激活后的输出:
#tensor([[0.3832, 0.0000, 0.3498, 0.0000, 0.0000]], grad_fn=)
在上述示例中,我们首先导入PyTorch库,并使用nn.Linear创建一个全连接层,然后使用nn.ReLU创建一个ReLU激活函数。接着,我们使用随机生成的输入数据进行前向传播,并观察激活前后的输出结果。
nn.ReLU函数实际上是一个可以应用于PyTorch神经网络层的操作,而不是单独的数学函数。它是深度学习框架的一部分,使得构建神经网络层更加方便和高效。我们可以根据需要在神经网络中的不同层之间插入ReLU激活函数,以引入非线性性质。
2. ReLU激活函数图像实现
要输出ReLU函数的图像,我们可以使用Python的Matplotlib库。首先,确保已经安装了Matplotlib。然后,可以使用以下示例代码来绘制ReLU函数的图像:
import numpy as np
import matplotlib.pyplot as plt
# 定义ReLU函数
def relu(x):
return np.maximum(0, x)
# 生成一系列输入值
x = np.linspace(-5, 5, 100)
# 计算ReLU函数的输出
y = relu(x)
# 绘制ReLU函数图像
plt.plot(x, y, label='ReLU', color='b')
plt.xlabel('Input')
plt.ylabel('Output')
plt.title('ReLU Function')
plt.axhline(0, color='black', linewidth=0.5, linestyle='--')
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend()
plt.show()
运行此段代码,即可得到LeakyReLU函数图像
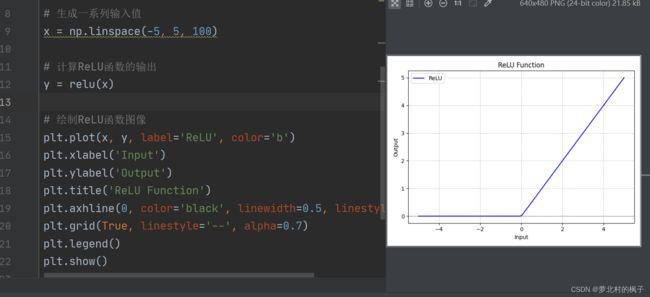
这段代码首先定义了一个ReLU函数 relu(x),然后生成一系列输入值 x,计算ReLU函数的输出 y,最后使用Matplotlib绘制了ReLU函数的图像。
运行这段代码将显示一个包含ReLU函数图像的窗口,其中x轴表示输入值,y轴表示ReLU函数的输出。图中的ReLU函数将所有负数部分映射为零,而正数部分保持不变。
ReLU(Rectified Linear Unit)函数和Leaky ReLU函数都是用于神经网络中的激活函数,它们在引入非线性性质时有些不同。以下是它们的主要区别:
3.ReLU激活函数与Leaky ReLU 函数的不同之处
(1) ReLU (Rectified Linear Unit) 函数:
-
ReLU函数是非常简单的激活函数,其数学表示为:

-
对于正数输入,ReLU不做任何修改,保持不变。
-
对于负数输入,ReLU将其映射为零,即输出为零。
-
ReLU函数是分段线性的,具有非常快的计算速度。
-
主要问题是可能导致神经元的"死亡",即在训练中,某些神经元可能永远保持不活跃。
(2) Leaky ReLU 函数:
-
Leaky ReLU是对ReLU的改进,旨在解决ReLU的"死亡"问题。
-
Leaky ReLU函数引入一个小的斜率(通常接近零)以处理负数输入,其数学表示为:

-
其中,α是一个小正数,通常在接近零的范围内,例如0.01。
-
Leaky ReLU允许负数部分不完全变为零,从而在反向传播时具有梯度,有助于减轻梯度消失问题。
选择使用哪种激活函数通常取决于具体的问题和网络架构。ReLU通常在许多情况下表现良好,但可能需要小心处理"死亡"神经元的问题。Leaky ReLU是一个改进,可以减轻这个问题,但需要选择适当的(\alpha)值。在实践中,通常会尝试不同的激活函数,并根据性能选择最适合的那个。