PF_PACKET
PF_PACKET
瞅代码的时候,看到一个很奇特的socket,sock=socket(PF_PACKET, SOCK_RAW, htons(0x8888))
那什么是PF_PACKET?我在网上翻了一下,找到了一片不错的文章,详细
sock_raw(注意一定要在root下使用)原始套接字编程可以接收到本机网卡上的数据帧或者数据包,对于监听网络的流量和分析是很有作用的.一共可以有3种方式创建这种socket
1.socket(AF_INET, SOCK_RAW, IPPROTO_TCP|IPPROTO_UDP|IPPROTO_ICMP)发送接收ip数据包,不能用IPPROTO_IP,因为如果是用了IPPROTO_IP,系统根本就不知道该用什么协议。
2.socket(PF_PACKET, SOCK_RAW, htons(ETH_P_IP|ETH_P_ARP|ETH_P_ALL))发送接收以太网数据帧
3.socket(AF_INET, SOCK_PACKET, htons(ETH_P_IP|ETH_P_ARP|ETH_P_ALL))过时了,不要用啊
1.介绍
在linux中提供了PF_PACKET接口可以操作链路层的数据。
2.使用方法
定义一个pf_packet = socket(PF_SOCKET, SOCK_RAW, htons(ETH_P_RARP));
就可以利用函数sendto和recefrom来读取和发送链路层的数据包了(当然,发送ARP包,上面第三个参数要变为 htons(ETH_P_ARP),或者IP的包为ETH_P_IP,可查看文件/usr/include/linux/if_ether.h文件看到所有支持的协议)。
3.在使用SOCK_RAW, SOCK_DGRAM和SOCK_PACKET的区别
在socket的第一个参数使用PF_PACKET的时候,上述三种socket的类型都可以使用。但是有区别。
(1)使用SOCK_RAW发送的数据必须包含链路层的协议头,接受得到的数据包,包含链路层协议头。而使用SOCK_DGRAM则都不含链路层的协议头。
(2)SOCK_PACKET也是可以使用的,但是已经废弃,以后不保证还能支持,不推荐使用。
(3)在使用SOCK_RAW或SOCK_DGRAM和SOCK_PACKET时,在sendto和recvfrom中使用的地址类型不同,前两者使用sockaddr_ll类型的地址,而后者使用sockaddr类型的地址。
(4)如socket的第一个参数使用PF_INET,第二个参数使用SOCK_RAW,则可以得到原始的IP包。
1. 什么PF_PACKET类型的socket
创建socket的函数如下:
fd = socket(int domain, int type, int protocol)
基于TCP/IP的传输层实现的:
文件传送协议ftp,基于tcp实现,用下面的方式创建socket:
fd = socket(AF_INET, SOCK_STREAM, IPPTORO_TCP)
自动地址分配协议dhcp,基于udp实现,用下面的方式创建socket:
fd = socket(AF_INET, SOCK_DGRAM, IPPTORO_UDP)
基于TCP/IP的网络层实现的:
消息控制协议icmp,基于raw ip实现,用下面的方式创建socket:
fd = socket(AF_INET, SOCK_RAW, IPPTORO_ICMP)
组播控制协议igmp,基于raw ip实现,用下面的方式创建socket:
fd = socket(AF_INET, SOCK_RAW, IPPTORO_IGMP)
socket是基于tcp/ip的网络编程接口,用于收发数据报,设置接收内核的某些状态以及事件。pf_packet类型的socket,是用来与驱动层面收发数据报的,接收和发送报文包含链路层信息,详细的信息参考:http://swoolley.org/man.cgi/7/packet。
socket的介绍使用,编程参考:https://blog.csdn.net/somyjun/article/details/84303074
2. PF_PACKET类型socket应用场合
抓包,分析(如tcpdump)
所有链接层的报文,单播、组播、广播,目的MAC地址,IP地址是设备本身配置的,或者是其他设备的,都通过socket发给用户态的抓包、分析程序。
一般链路层在处理收到的报文时,会依据目的MAC、目的IP地址,如果它们不是设备本身配置的(还有一些广播、组播除外),都会丢弃。因此,需要设置设备网络设备为混杂模式(promiscuous)。
struct packet_mreq mr;
memset(&mr,0,sizeof(mr));
mr.mf_ifindex = dev_id;
mr.mr_type = PACKET_MR_PROMISC; // 用于激活混杂模式以接受所有网络包;
fd = socket(PF_PACKET, SOCK_RAW, ETH_P_ALL) // 所有类型的报文
setsockopt(fd, SOL_PACKET, PACKET_ADD_MEMBERSHIP,&mr,sizeof(mr))
跑在用户态的网络协议
Linux内核并不是纯粹的操作系统,它实现了很多功能,包括二三层协议。一方面考虑到性能,另一方面移植性,现在有不少网络设备产商,二三层协议的实现是放在用户态的。
fd = socket(PF_PACKET, SOCK_RAW, ETH_P_8021Q) // linux/if_ether.h,8021Q类型的报文
3. 数据层面:驱动程序怎么把报文送到相应的socket buffer
Linux内核,网络收报文有两个接口:
int netif_rx_ni(struct sk_buff *skb) // loopback,tun之类的设备收报文调用
int netif_rx(struct sk_buff *skb) // 中断上下文调用
上面两个接口的区别与实现,请查看相应的源代码。
内核在收报文处理方式,有NAPI和非NAPI两张模式,参考下面的图。

区别在于非NAPI方式,在中断上下文里构造sk_buff,完成数据的拷贝后放到相关的队列里,底半部处理过程就是deque,然后传递给相关的处理模块,这种方式,CPU可能会陷入频繁的中断,无法处理别的任务;NAPI方式是一中Polling方式,中断上下文激活Polling,在底半部调用驱动的收报文接口。
open_softirq(NET_RX_SOFTIRQ, net_rx_action) // softirq,底半部
前面过了下linux驱动收包的机制,重点来了,收到的报文,沿着怎样的路径送到咱们上面讲的pf_packet类型的socket buffer的呢?
在底半部的softirq,都会调用这个函数:
int __netif_receive_skb(struct sk_buff *skb)
int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
下面来看看这个函数的重点逻辑部分(代码里vlan相关的部分略去):
list_for_each_entry_rcu(ptype, &ptype_all, list) { // 第一次循环,ptype_all,未绑定到设备的ETH_ALL类似的socket
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) { // 第二次循环,ptype_all,绑定到设备的ETH_ALL类似的socket
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
void dev_add_pack(struct packet_type *pt)
{
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
static inline struct list_head *ptype_head(const struct packet_type *pt)
{
if (pt->type == htons(ETH_P_ALL)) // AF_PACKET类型的socket,要接收所有类型的报文
return pt->dev ? &pt->dev->ptype_all : &ptype_all;
else
return pt->dev ? &pt->dev->ptype_specific :&ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
从上面四个函数的逻辑就可看出,如果有类似tcpdump这样的在用户态抓包分析的程序,就调用deliver_skb。
这里逻辑上的讲究是:
1)dev->ptype_all : ptype_all,用户态的pf_packet类型的套接字如果有bind到某个设备,就是设备单独维护的链表dev->ptype_all。
2)pt_prev初始化是NULL的指针,linux内核维护的双向链表,链表头不是个有意义的实体,所以,每次循环结束,最后一个ptype要等到后面的判断代码再执行一遍:
pt_prev = NULL; // 初始化是空指针
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype; // 赋值,下一次才会执行
}
if(pt_prev){ // 不为空,执行
if(unlikely(skb_orphan_frags_rx(skb,GFP_ATOMIC)))
goto drop;
else
// 这里执行最后一次回调,既然是最后一次调用,sbk就不需要clone了,这个就是与调用deliver_skb的区别
ret = pt_prev->func(skb,skb->dev,pt_prev,orig_dev);
}
下面来看看这个函数:
static inline int deliver_skb(struct sk_buff *skb,struct packet_type *pt_prev,struct net_device *orig_dev)
{
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
return -ENOMEM;
refcount_inc(&skb->users); // 增加计数,释放时用的;
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev); // 函数指针,在下面的函数赋值
}
在af_packet.c这个文件里,这个函数是创建socket:
static int packet_create(struct net *net, struct socket *sock, int protocol,int kern)
{
struct packet_sock *po;
po->prot_hook.func = packet_rcv; // func回调函数
if (proto) {
po->prot_hook.type = proto;
register_prot_hook(sk); // 注册到ptype_all链表中
}
}
再来看看这个收包处理函数:
static int packet_rcv(struct sk_buff *skb, struct net_device *dev,struct packet_type *pt, struct net_device *orig_dev)
{
if (skb_shared(skb)) { // deliver_skb函数调用了refcount_inc,需要skb_clone
struct sk_buff *nskb = skb_clone(skb, GFP_ATOMIC);
if (nskb == NULL)
goto drop_n_acct;
if (skb_head != skb->data) {
skb->data = skb_head;
skb->len = skb_len;
}
consume_skb(skb);
skb = nskb;
}
spin_lock(&sk->sk_receive_queue.lock);
po->stats.stats1.tp_packets++;
sock_skb_set_dropcount(sk, skb);
__skb_queue_tail(&sk->sk_receive_queue, skb); // 添加到队列尾巴
spin_unlock(&sk->sk_receive_queue.lock);
sk->sk_data_ready(sk); // 唤醒处于TASK_INTERRUPTIBLE的等待线程
}
到这里,驱动到socket buffer,这条路就通了。
4. 数据层面:内核驱动可以与用户态零拷贝吗?
socket buffer到用户态,在调用recvfrom接收报文时,是存在数据从内核态拷贝到用户态的,另外也会导致内核态和用户态的频繁切换。
下面探讨下,用户态和内核态数据零拷贝的可行性方案!
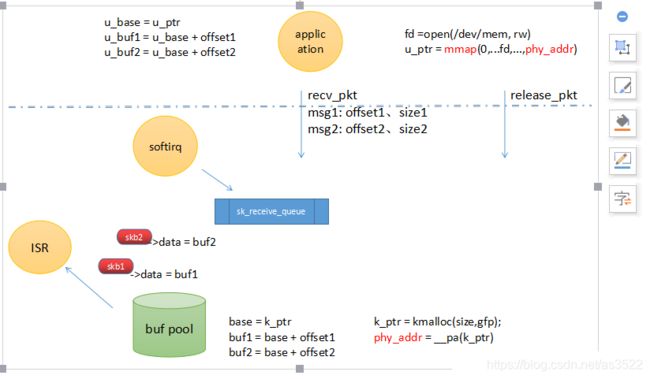
上图所示,描述了试想可行的改动方案:
1)创建buf_pool,其原理基于内核态和用户态虚拟地址,其实都对应一个物理地址,既然这样,我们创建一个基于这个基准地址的buf poll。它们通过操作自己的内存池控制块,来共同管理内存。不同空间,虽然是两个不同的基地址,k_ptr和u_ptr,其实,它们是在不同地址空间的映射而已,对于物理内存,是同样的。然后,每次操作,传递的是,与自己的基地址的偏移,到了另外一个空间,基地址加上这个偏移地址,不就是要访问的地址了。
fd =open(/dev/mem, rw)
u_ptr = mmap(0,...fd,...,phy_addr) // phy_addr,通过sys_call获得
recv_pkt msg1: offset1、size1 // 消息传递的是偏移和大小
原文1:https://blog.csdn.net/somyjun/article/details/84589579
原文2:https://www.cnblogs.com/cdwodm/archive/2012/09/22/2698163.html