Redis:I/O模型
前言
前一篇概览 Redis:概览 中提到Redis使用了IO多路复用模型,所以单线程的Redis也很快。所以本篇主要讲解Linux相关的I/O模型。
关于I/O我们可学了不少,java.io包下面的类全是关于I/O的操作。I/O就是Input/Output,是指输入/输出。
我们都知道I/O大致可以分为BIO、NIO、AIO。BIO就是Blocking I/O(阻塞IO);NIO就是Non-Blocking I/O(非阻塞IO);AIO就是Asynchronous I/O(异步IO)。
说到这里就不得不说一下阻塞/非阻塞、同步/异步了。阻塞/非阻塞和同步/异步完全是不同的概念,不要混为一谈。
- 同步和异步:关注的是消息通信机制 。调用方发出一个调用后,响应方在没有产生结果之前,都不会响应,也就是说响应方必须要产生了结果才能返回该调用,这就是同步;如果响应方在没有产生结果之前,就立即响应了,至于真正的结果,往往通过回调的方式反馈给调用方,这就是异步。
- 阻塞和非阻塞:关注的是调用方在等待调用结果时的状态。调用方发出一个调用后,响应方在没有产生结果之前,调用方一直被挂起,不能做其他的事(敌不动,我不动),这就说明是阻塞的;如果响应方在没有产生结果之前,调用方可以去做别的事,隔一段时间再来检查调用是否返回了结果,这就是非阻塞的。
可以看到描述同步和异步的时候,只关心消息通信的机制,并不关心调用方的状态;而描述阻塞和非阻塞的时候,只关心调用方的状态,而不用关心消息通信机制。
举个例子
你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下",然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过回电这种方式来回调。
还是这个例子
你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。
所有的系统I/O都分为两个阶段:等待就绪和执行操作。
Linux的I/O模型主要有五类:阻塞 I/O(blocking IO)、非阻塞 I/O(nonblocking IO)、I/O 多路复用( IO multiplexing)、信号驱动 I/O( signal driven IO)、异步 I/O(asynchronous IO)。
BIO
BIO模式,数据的读取写入必须阻塞在一个线程内等待其完成。其操作流程如下
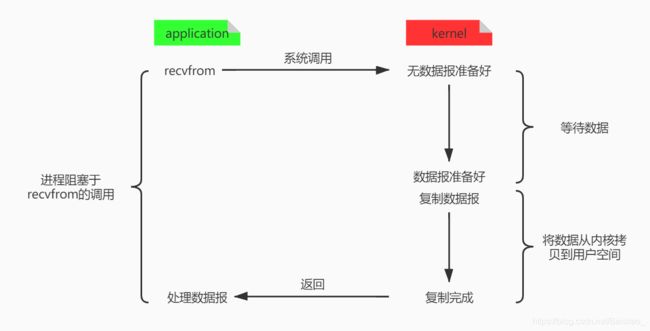
当调用方调用了recvfrom这个系统调用,kernel就开始了BIO的第一个阶段:准备数据。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。对用户进程来说,自己会被阻塞。当kernel等到数据准备好了,它就会将数据从kernel中拷贝到用户空间,然后kernel返回结果,用户进程才解除阻塞的状态,重新运行起来。
调用方从发起调用到收到响应,无论是等待就绪阶段还是执行操作阶段,一直都是被阻塞的,这种IO模型就是BIO。
NIO
NIO是同步非阻塞IO,其操作流程如下

当调用方调用了recvfrom这个系统调用,如果kernel中的数据还没有准备好,会立刻返回一个error,调用方并不会被阻塞。对调用方来说,它发起一个read操作后,并不需要等待,而是马上就得到了一个响应。调用方判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作,在两次调用期间,可以进行别的操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的系统调用,那么它马上就将数据拷贝到了用户内存,然后返回。
可以看到NIO相对于BIO的改进主要是等待就绪阶段,需要不断的发起调用来检查响应方是否已经准备就绪,而后面的执行操作阶段与BIO一致。
IO多路复用
NIO模型中,应用进程一直在以轮询的方式调用系统函数recvfrom,轮询会消耗大量的CPU资源。为了改进这个问题,于是出现了IO多路复用模型,IO多路复用模型中,轮询由内核来完成。内核可以监视多个描述符的读/写等事件,一旦某个描述符就绪(可读或者可写),就能够将发生的事件通知给关心的应用程序去处理该事件。IO多路复用模型如下

乍看之下,IO复用模型和BIO模型似乎区别不大,并且BIO模型只需要调用一个系统函数(recvfrom)而IO多路复用需要调用两个系统函数(select和recvfrom)。IO多路复用模型的优势就是内核可以监视多个描述符的读/写等事件,也就是说一个线程可以处理多个连接,只有有任意的描述符可读或者可写,内核就通知对应的应用进程去处理。
IO多路复用的实现机制可以分成三类:select、poll、epoll。
select是最初实现IO多路复用的版本、poll是对select的优化,而epoll是对poll的优化。
select方式实现的IO多路复用模型存在如下三个问题:
- 被监控的文件描述符集合有限制,一般32位默认是1024个。64位默认是2048。
cat /proc/sys/fs/file-max命令可以查看 - 文件描述符集合需要从用户空间拷贝到内核空间的问题
- 当被监控的文件描述符中某些有数据可读的时候,希望能够从通知中得到有可读事件的文件描述符列表,而不是需要遍历整个文件描述符集合。
poll方式只解决了第一个问题,也就是解除了被监控的文件描述符集合的限制。只有epoll解决了后面两个问题。
对于用户空间和内核空间的数据拷贝问题,epoll通过内核与用户空间mmap(内存映射)同一块内存来解决。mmap将用户空间的一块地址和内核空间的一块地址,同时映射到相同的一块物理内存地址,使得这块物理内存对内核和对用户均可见,减少用户态和内核态之间的数据拷贝。
epoll不是轮询的方式遍历文件描述符集合,不会随着文件描述符数目的增加效率下降。只有活跃可用的文件描述符才会调用回调函数。即epoll最大的优点就在于只关注可读或者可写的文件描述符。
信号驱动IO
信号驱动 I/O( signal driven IO)首先Socket进行信号驱动IO,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。过程如下图所示

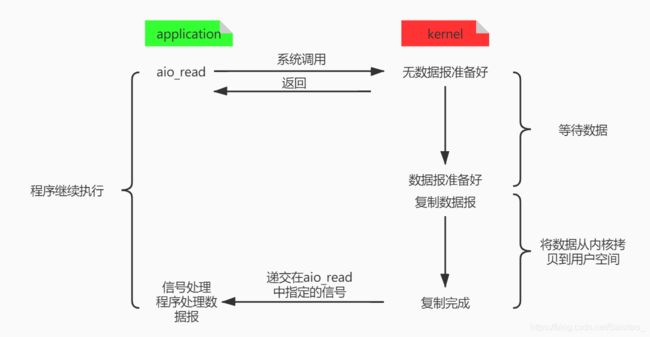
异步IO
异步 I/O(asynchronous IO):用户进程进行aio_read系统调用之后,无论内核数据是否准备好,都会直接返回给用户进程。用户进程可以去做别的事情。等到socket数据准备好了,内核直接复制数据给用户进程,然后从内核向进程发送通知。IO两个阶段,进程都是非阻塞的。异步过程如下图所示:
总结
本文主要介绍了Linux操作系统中的五种I/O模型,一些应用软件、java.io或者java.nio包下的类也是基于这些IO模型的封装,所提供的上层API。理解IO模型非常重要,它能帮助我们构建跟高效的网络服务器。
参考
- https://www.zhihu.com/question/19732473/answer/20851256
- https://www.zhihu.com/question/41706901
- 《Unix网络编程》