ld GCC
libdl.so的基本使用
2014年02月06日 16:01:09 黄俊东 阅读数:13553更多
所属专栏: linux高级编程
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/caihongshijie6/article/details/18950351
一、 使用libdl.so库
动态库加载原理
动态库中函数的查找已经封装成哭libdl.so
libdl.so里面有4个函数:
dlopen//打开一个动态库
dlsym//在打开的动态库里找一个函数
dlclose//关闭动态库
dlerror//返回错误
dl.c
-
#include -
#include -
int main(){ -
void* handler = dlopen("./libdemo1.so",RTLD_LAZY); -
int (*fun)(int,int) = dlsym(handler,"add"); -
int result = fun(34,25); -
printf("the result of teo number is %d\n",result); -
}
在命令行中输入的命令:
[fedora@localhost day02_r3]$ gcc dl.c -odl -ldl
[fedora@localhost day02_r3]$ ./ld
----------------------------------libdl.so的基本使用的小结----------------------------------------
只需要记住一个头文件,和四个函数即可:
头文件:#include
四个函数:
dlopen//打开一个动态库
dlsym//在打开的动态库里找一个函数
dlclose//关闭动态库
dlerror//返回错误
头文件和上面的四个函数的用法都不需要死记,旺季的时候man一下即可。。。。。
总结:
1. 编译连接动态库
2. 使用动态库
3. 怎么配置让程序调用动态库
4. 掌握某些工具的使用 nm ldd lddconfig objdump strit(去掉多余的信息)
===========================================================================================================================================================================================================================================================================
g++ test.cc -lglog -lgflags -lpthread -o test
===========================================================================================================================================================================================================================================================================
glog
一、安装配置
1、简介
google 出的一个C++轻量级日志库,支持以下功能:
![]()
◆ 参数设置,以命令行参数的方式设置标志参数来控制日志记录行为;
◆ 严重性分级,根据日志严重性分级记录日志;
◆ 可有条件地记录日志信息;
◆ 条件中止程序。丰富的条件判定宏,可预设程序终止条件;
◆ 异常信号处理。程序异常情况,可自定义异常处理过程;
◆ 支持debug功能;
◆ 自定义日志信息;
◆ 线程安全日志记录方式;
◆ 系统级日志记录;
◆ google perror风格日志信息;
◆ 精简日志字符串信息![]()
2、安装
下载地址:https://code.google.com/p/google-glog/downloads/list
解压安装:
tar zxvf glog-0.3.3.tar.gz && cd glog-0.3.3 && ./configure && make头文件目录为 /src/glog ,链接库为 .libs/libglog.{a,so}
帮助文档为 doc/glog.html 或直接访问以下 URL: http://google-glog.googlecode.com/svn/trunk/doc/glog.html
3、简单 Demo
#include
int main(int argc,char* argv[])
{
LOG(INFO) << "Hello,GLOG!";
} 链接时,需要 -lglog ,也可能会需要 -lunwind -lpthread (有一次遇到的,记不起来了,一般不需要)
执行时,可使用 ./glogdemo 将日志输出到 stderr,可使用 valgrind 检测,未发现内存泄漏。
((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((((
The libunwind project
The primary goal of this project is to define a portable and efficient C programming interface (API) to determine the call-chain of a program. The API additionally provides the means to manipulate the preserved (callee-saved) state of each call-frame and to resume execution at any point in the call-chain (non-local goto). The API supports both local (same-process) and remote (across-process) operation. As such, the API is useful in a number of applications. Some examples include:
exception handling
The libunwind API makes it trivial to implement the stack-manipulation aspects of exception handling.
debuggers
The libunwind API makes it trivial for debuggers to generate the call-chain (backtrace) of the threads in a running program.
introspection
It is often useful for a running thread to determine its call-chain. For example, this is useful to display error messages (to show how the error came about) and for performance monitoring/analysis.
efficient setjmp()
With libunwind, it is possible to implement an extremely efficient version of setjmp(). Effectively, the only context that needs to be saved consists of the stack-pointer(s).
本项目的主要目标是定义可移植的、高效的C编程接口(API),以确定程序的调用链。API还提供了操作每个调用帧的保留(被调用者保存)状态和在调用链中的任何点(非本地goto)恢复执行的方法。API同时支持本地(同进程)和远程(跨进程)操作。因此,API在很多应用程序中都很有用。一些例子包括:
异常处理
libunwind API使得实现异常处理的堆栈操作方面变得非常简单。
调试器
libunwind API使得调试器在运行的程序中生成线程的调用链(回溯)变得很琐碎。
反省
对于正在运行的线程来说,确定其调用链通常是有用的。例如,这对于显示错误消息(显示错误是如何产生的)以及性能监视/分析非常有用。
有效setjmp()
使用libun.,可以实现一个极其高效的setjmp()版本。实际上,唯一需要保存的上下文由堆栈指针组成。
))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))
{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{
- 在CentOS 6.3 64bit上安装libunwind库
-
发布时间:2018-01-19 来源:网络 上传者:用户
关键字:
发表文章 - 摘要:libunwind库为基于64位CPU和操作系统的程序提供了基本的堆栈辗转开解功能,32位操作系统不要安装。其中包括用于输出堆栈跟踪的API、用于以编程方式辗转开解堆栈的API以及支持C++异常处理机制的API。64bit操作系统必须安装libunwind库所有的libunwind库在http://ftp.yzu.edu.tw/nongnu/libunwind/目前最新版是1.1,更新于2012.10下面是安装过程。wgethttp://download.savannah.g
- libunwind库为基于64位CPU和操作系统的程序提供了基本的堆栈辗转开解功能,32位操作系统不要安装。其中包括用于输出堆栈跟踪的API、用于以编程方式辗转开解堆栈的API以及支持C++异常处理机制的API。
64bit操作系统必须安装libunwind库
所有的libunwind库在
http://ftp.yzu.edu.tw/nongnu/libunwind/目前最新版是1.1,更新于2012.10

下面是安装过程。
wget http://download.savannah.gnu.org/releases/libunwind/libunwind-1.1.tar.gz
tar zxvf libunwind-1.1.tar.gz
cd libunwind-1.1
CFLAGS=-fPIC ./configure #添加编译参数
make CFLAGS=-fPIC
make CFLAGS=-fPIC install
参考文献
[1].http://www.cnblogs.com/littlehb/archive/2013/04/15/3021478.html - 以上是在CentOS 6.3 64bit上安装libunwind库的内容,更多 的内容,请您使用右上方搜索功能获取相关信息。
}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}
[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[
setjmp和longjmp用法
本文转自:http://blog.csdn.net/wuhong40/article/details/6155838,感谢原文作者。
前不久在阅读Quake3源代码的时候,看到一个陌生的函数:setjmp,一番google和查询后,觉得有必要针对setjmp和longjmp这对函数写一篇blog,总结一下。
setjmp和longjmp是C语言独有的,只有将它们结合起来使用,才能达到程序控制流有效转移的目的,按照程序员的预先设计的意图,去实现对程序中可能出现的异常进行集中处理。
先来看一下这两个函数的定义吧:
setjmp和longjmp的函数原型在setjmp.h中
函数原型:
int setjmp(jmp_buf envbuf);setjmp函数用缓冲区envbuf保存系统堆栈的内容,以便后续的longjmp函数使用。setjmp函数初次启用时返回0值。
void longjmp(jmp_buf envbuf, int val);longjmp函数中的参数envbuf是由setjmp函数所保存的堆栈环境,参数val设置setjmp函数的返回值。longjmp函数本身是没有返回值的,它执行后跳转到保存envbuf参数的setjmp函数调用,并由setjmp函数调用返回,此时setjmp函数的返回值就是val。
上面的说明有点拗口,通俗的解释是:先调用setjmp,用变量envbuf记录当前的位置,然后调用longjmp,返回envbuf所记录的位置,并使setjmp的返回值为val。当时用longjmp时,envbuf的内容被销毁了。其实这里的“位置”一词真正的含义是栈定指针。
接着让我们看一个小例子吧:
![]()
#include
#include
jmp_buf buf;
banana(){
printf("in banana() \n");
longjmp(buf,1);
printf("you'll never see this,because i longjmp'd");
}
main()
{
if(setjmp(buf))
printf("back in main\n");
else{
printf("first time through\n");
banana();
}
} ![]()
(代码段引自《C专家编程》:p)
这段代码的打印结果是:
first time through
in banana()
back in main
仔细看一下应该更能体会这对函数的作用了吧。
setjmp/longjmp的最大用处是错误恢复,类似try ...catch...
他们的功能比goto强多了,goto只能在函数体内跳来跳去,而setjmp/longjmp可以在到过的所有位置间。
从java、.net世界来的兄弟们也许会很不屑于这对函数,也许会觉得这样的功能会使代码的可读性变差。不过请别忘了,这里是C的世界,每个世界有每个世界的哲学,OO只是方法学的一种,而不是全部。quake3是用C写的,据看过其代码的前辈说,其模块化非常好,所以这也是我看quake3代码的初衷。(哦,算了吧,写游戏不是随便说说的...)
注:
我第一次看到setjmp是在quake3代码的Com_Init中,
![]()
/*
=================
Com_Init
=================
*/
void Com_Init( char *commandLine ) {
char *s;
Com_Printf( "%s %s %s\n", Q3_VERSION, CPUSTRING, __DATE__ );
if ( setjmp (abortframe) ) {
Sys_Error ("Error during initialization");
}
....![]()
卡马克在这里也是当catch用的,其中的一句注释是这么写的:
jmp_buf abortframe; // an ERR_DROP occured, exit the entire frame继续读吧,在代码中慢慢体会吧...
]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]
{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{
jmp_buf的使用,结构定义为数组
今天看《C专家编程》第7章第8节,最后提到用setjmp/longjmp从信号终恢复。顺便敲了代码看看效果,就对其中jmp_buf这个结构感兴趣。查看一下,发现/usr/include/setjmp.h中是这么定义的: 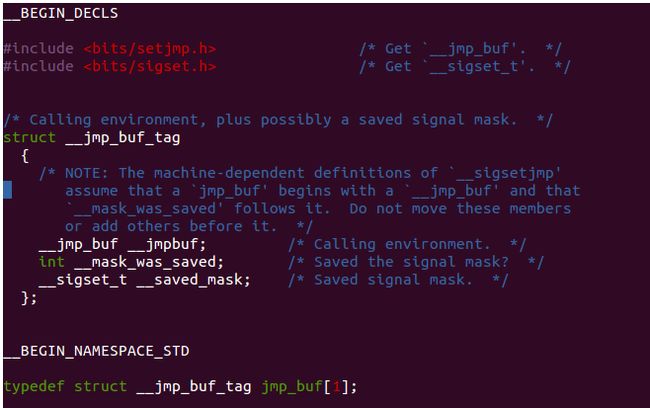
图1
另外__jmp_buf的定义在/usr/include/i386-linux-gnu/bits/setjmp.h: 
图2
图1定义方式很奇怪,即 将一个结构定义成由一个成员的数组 ,刚开始不理解为什么,上网搜了一下,发现2005年云风大神已经有博客了。
文章讲得很简略,细细一想,发现了其中的奥秘:
其实这个小的trick主要利用了C语言中数组的性质:我们假设定义jmp_buf buf;
1. 我们用jmp_buf定义一个变量的时候,相当于定义了一个只有一个成员的数组(按照typedef,jmp_buf数据类型就是一个数组类型,因此用它定义的变量也是数组,只不过这个数组比较特殊,数组的成员是一个结构);我们知道定义数组的时候,编译器会分配内存,那么我们定义这个变量大小就是sizeof(jmp_buf)。
2. 我们知道数组名在直接传递的时候会退化成指针,因此可以起到传址的作用。
链接文章中提到在声明的时候可以把数据分配到堆栈(stack)上,我想说,这样就是利用上面提到的。假设我们在一个函数里面声明一个变量,那么变量会被压入stack中,而传递参数或者访问结构的时候传递指针就可以了。
这就是数组的两头都占好的特性吧,定义时候能直接分配好地址,使用的时候还能把数组名当指针用。
再参考:
setjmp 的正确使用
}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}
[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[[
#include
#include
/* Calling environment, plus possibly a saved signal mask. */
struct __jmp_buf_tag {
/* NOTE: The machine-dependent definitions of `__sigsetjmp'
assume that a `jmp_buf' begins with a `__jmp_buf' and that
`__mask_was_saved' follows it. Do not move these members
or add others before it. */
__jmp_buf __jmpbuf; /* Calling environment. */
int __mask_was_saved; /* Saved the signal mask? */
__sigset_t __saved_mask; /* Saved signal mask. */
};
__BEGIN_NAMESPACE_STD typedef struct __jmp_buf_tag jmp_buf[1];
可以看到类型jmp_buf被定义为结构体struct __jmp_buf_tag的一维数组,这样做至少有两个好处:
在声明jmp_buf时,可以把数据分配到堆栈上
作为参数传递时则作为一个指针
我们目前只关心__jmp_buf __jmpbuf,也就是注释中提到的calling environment,其他的我们在后文中提到sigsetjmp()/siglongjmp()时再提。在/usr/include/i386-linux-gnu/bits/setjmp.h中找到__jmp_buf的定义如下:
#ifndef _ASM
typedef int __jmp_buf[6];
#endif
看来这里的整形数组就是保存栈上下文的地方了。
]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]
二、使用方法
1、错误级别
GLOG 有四个错误级别,枚举如下:
![]()
enum SeverityLevel
{
google::INFO = 0,
google::WARNING = 1,
google::ERROR = 2,
google::FATAL = 3,
};![]()
2、Flags 设置:
在上面的简单 Demo 中,只能将日志输出到 stderr ,如果想将日志重定向到文件,需要:
google::InitGoogleLogging(argv[0]);
/*
GLOG代码
*/
google::ShutdownGoogleLogging(); 则默认运行会将日志输出到 /tmp 目录下(格式为 "
另外,glog 使用了 gflags 库,如果已经安装好了 gflags 库(./configure && make && make install 然后再配置编译GLOG库)还可以通过 ./your_application --logtostderr=1 来指定运行参数,但需要在使用时加上如下代码:(详见 http://www.cnblogs.com/tianyajuanke/p/3467572.html)
google::ParseCommandLineFlags(&argc, &argv, true);
/*
GLOG代码
*/
google::ShutDownCommandLineFlags();但此方法会使 valgrind 检测有内存泄漏(截止 valgrind 3.9.0 依然如此),这是由于使用 gflags 库造成的。(即使不使用此方法,但只要在编译 glog 库之前安装好了 gflags 库,就会使 libglog.so 有内存泄漏,介意者可进入 gflags 目录 make uninstall 之后,再对 glog 进行 ./configure && make )。
常用的运行参数如下:
![]()
logtostderr (bool, default=false) //是否将所有日志输出到 stderr,而非文件
alsologtostderr(bool,default=false) //是否同时将日志输出到文件和stderr
minloglevel (int, default=google::INFO) //限制输出到 stderr 的部分信息,包括此错误级别和更高错误级别的日志信息
stderrthreshold (int, default=google::ERROR) //除了将日志输出到文件之外,还将此错误级别和更高错误级别的日志同时输出到 stderr,这个只能使用 -stderrthreshold=1 或代码中设置,而不能使用环境变量的形式。(这个参数可以替代上面两个参数)
colorlogtostderr(bool, default=false) //将输出到 stderr 上的错误日志显示相应的颜色
v (int, default=0) //只记录此错误级别和更高错误级别的 VLOG 日志信息
log_dir (string, default="") //设置日志文件输出目录
v (int, default=0) //只有当自定义日志(VLOG)级别值小于此值时,才进行输出,默认为0(注:自定义日志的优先级与GLOG内置日志优级相反,值越小优先级越高!!!)。
vmodule (string, default="") //分文件(不包括文件名后缀,支持通配符)设置自定义日志的可输出级别,如:GLOG_vmodule=server=2,client=3 表示文件名为server.* 的只输出小于 2 的日志,文件名为 client.* 的只输出小于 3 的日志。如果同时使用 GLOG_v 选项,将覆盖 GLOG_v 选项。![]()
更多运行参数见 logging.cc 中的 DEFINE_ 开头的定义。
运行参数设置的第三种方法是,可以在代码里通过加上 FLAGS_ 前缀来设置,如:
FLAGS_stderrthreshold=google::INFO;
FLAGS_colorlogtostderr=true;
3、条件输出:
LOG_IF(INFO, num_cookies > 10) << "Got lots of cookies"; //当条件满足时输出日志
LOG_EVERY_N(INFO, 10) << "Got the " << google::COUNTER << "th cookie"; //google::COUNTER 记录该语句被执行次数,从1开始,在第一次运行输出日志之后,每隔 10 次再输出一次日志信息
LOG_IF_EVERY_N(INFO, (size > 1024), 10) << "Got the " << google::COUNTER << "th big cookie"; //上述两者的结合,不过要注意,是先每隔 10 次去判断条件是否满足,如果滞则输出日志;而不是当满足某条件的情况下,每隔 10 次输出一次日志信息。
LOG_FIRST_N(INFO, 20) << "Got the " << google::COUNTER << "th cookie"; //当此语句执行的前 20 次都输出日志,然后不再输出演示代码如下:
![]()
#include
int main(int argc,char* argv[])
{
google::InitGoogleLogging(argv[0]);
FLAGS_stderrthreshold=google::INFO;
FLAGS_colorlogtostderr=true;
for(int i = 1; i <= 100;i++)
{
LOG_IF(INFO,i==100)<<"LOG_IF(INFO,i==100) google::COUNTER="<50),10) google::COUNTER="<
输出结果如下:

I1210 13:23:20.059790 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=1 i=1
E1210 13:23:20.060670 6322 test01.cpp:13] LOG_FIRST_N(INFO,5) google::COUNTER=1 i=1
E1210 13:23:20.061272 6322 test01.cpp:13] LOG_FIRST_N(INFO,5) google::COUNTER=2 i=2
E1210 13:23:20.061337 6322 test01.cpp:13] LOG_FIRST_N(INFO,5) google::COUNTER=3 i=3
E1210 13:23:20.061393 6322 test01.cpp:13] LOG_FIRST_N(INFO,5) google::COUNTER=4 i=4
E1210 13:23:20.061450 6322 test01.cpp:13] LOG_FIRST_N(INFO,5) google::COUNTER=5 i=5
I1210 13:23:20.061506 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=11 i=11
I1210 13:23:20.061529 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=21 i=21
I1210 13:23:20.061553 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=31 i=31
I1210 13:23:20.061575 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=41 i=41
I1210 13:23:20.061599 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=51 i=51
W1210 13:23:20.061621 6322 test01.cpp:12] LOG_IF_EVERY_N(INFO,(i>50),10) google::COUNTER=51 i=51
I1210 13:23:20.061667 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=61 i=61
W1210 13:23:20.061691 6322 test01.cpp:12] LOG_IF_EVERY_N(INFO,(i>50),10) google::COUNTER=61 i=61
I1210 13:23:20.061738 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=71 i=71
W1210 13:23:20.061761 6322 test01.cpp:12] LOG_IF_EVERY_N(INFO,(i>50),10) google::COUNTER=71 i=71
I1210 13:23:20.061807 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=81 i=81
W1210 13:23:20.061831 6322 test01.cpp:12] LOG_IF_EVERY_N(INFO,(i>50),10) google::COUNTER=81 i=81
I1210 13:23:20.061877 6322 test01.cpp:11] LOG_EVERY_N(INFO,10) google::COUNTER=91 i=91
W1210 13:23:20.061902 6322 test01.cpp:12] LOG_IF_EVERY_N(INFO,(i>50),10) google::COUNTER=91 i=91
I1210 13:23:20.062140 6322 test01.cpp:10] LOG_IF(INFO,i==100) google::COUNTER=0 i=100
4、日志类型
LOG //内置日志
VLOG //自定义日志
DLOG //DEBUG模式可输出的日志
DVLOG //DEBUG模式可输出的自定义日志
SYSLOG //系统日志,同时通过 syslog() 函数写入到 /var/log/message 文件
PLOG //perror风格日志,设置errno状态并输出到日志中
RAW_LOG //线程安全的日志,需要#include
前六种的日志使用方法完全相同(包括条件日志输出),而 RAW_LOG 使用方法比较特殊,且不支持条件日志输出,另外不接受 colorlogtostderr 的颜色设置。自定义日志也不接受 colorlogtostderr 的颜色设置,另外其日志严重级别也为自定义数字,且与默认日志严重级别相反,数字越小严重级别越高。如:
1 #include
2 #include
3
4 class GLogHelper
5 {
6 public:
7 GLogHelper(char* program)
8 {
9 google::InitGoogleLogging(program);
10 FLAGS_stderrthreshold=google::INFO;
11 FLAGS_colorlogtostderr=true;
12 FLAGS_v = 3;
13 }
14 ~GLogHelper()
15 {
16 google::ShutdownGoogleLogging();
17 }
18 };
19
20 int main(int argc,char* argv[])
21 {
22 GLogHelper gh(argv[0]);
23 LOG(ERROR)<<"LOG";
24 VLOG(3)<<"VLOG";
25 DLOG(ERROR)<<"DLOG";
26 DVLOG(3)<<"DVLOG";
27 SYSLOG(ERROR)<<"SYSLOG";
28 PLOG(ERROR)<<"PLOG";
29 RAW_LOG(ERROR,"RAW_LOG");
30 }
输出结果如下:
E1211 03:04:22.718116 13083 test01.cpp:23] LOG
I1211 03:04:22.719225 13083 test01.cpp:24] VLOG
E1211 03:04:22.719297 13083 test01.cpp:25] DLOG
I1211 03:04:22.719365 13083 test01.cpp:26] DVLOG
E1211 03:04:22.719391 13083 test01.cpp:27] SYSLOG
E1211 03:04:22.719650 13083 test01.cpp:28] PLOG: Success [0]
E1211 03:04:22.719650 13083 test01.cpp:29] RAW: RAW_LOG
5、CHECK 宏
当通过该宏指定的条件不成立的时候,程序会中止,并且记录对应的日志信息。功能类似于ASSERT,区别是 CHECK 宏不受 NDEBUG 约束,在 release 版中同样有效。
目前这个功能我暂时不需要,就不实践了,简单介绍下,如:
CHECK(port == 80)<<"HTTP port 80 is not exit.";
其它还有:CHECK_EQ、 CHECK_NOTNULL、CHECK_STREQ、CHECK_DOUBLE_EQ 等判断数字、空指针,字符串,浮点数的 CHECK 宏,需要使用时可以搜索 glog/logging.h 文件中以 CHECK_ 开头的宏定义。
此外,类似的,还有 PCHECK 和 RAW_CHECK 版本,使用方法类似,只是 RAW_CHECK 使用方法特殊,形如 RAW_CHECK(i<3,"RAW_CHECK");
6、core dumped
通过 google::InstallFailureSignalHandler(); 即可注册,将 core dumped 信息输出到 stderr,如:
#include
#include
#include
//将信息输出到单独的文件和 LOG(ERROR)
void SignalHandle(const char* data, int size)
{
std::ofstream fs("glog_dump.log",std::ios::app);
std::string str = std::string(data,size);
fs<
输出的错误报告如下,可定位错误于 fun() 函数内:
E1211 06:07:04.787719 15444 test01.cpp:11] *** Aborted at 1386742024 (unix time) try "date -d @1386742024" if you are using GNU date ***
E1211 06:07:04.789120 15444 test01.cpp:11] PC: @ 0x401227 fun()
E1211 06:07:04.789481 15444 test01.cpp:11] *** SIGSEGV (@0x0) received by PID 15444 (TID 0x7f03ce478720) from PID 0; stack trace: ***
E1211 06:07:04.791168 15444 test01.cpp:11] @ 0x7f03cd505960 (unknown)
E1211 06:07:04.791453 15444 test01.cpp:11] @ 0x401227 fun()
E1211 06:07:04.791712 15444 test01.cpp:11] @ 0x40125b main
E1211 06:07:04.792908 15444 test01.cpp:11] @ 0x7f03cd4f1cdd __libc_start_main
E1211 06:07:04.793227 15444 test01.cpp:11] @ 0x400fc9 (unknown)
段错误 (core dumped)
如果不使用 google::InstallFailureSignalHandler(); 则只会输出 “段错误” 三个字,难于排查。
7、其它常用配置
google::SetLogDestination(google::ERROR,"log/prefix_"); //第一个参数为日志级别,第二个参数表示输出目录及日志文件名前缀。
google::SetStderrLogging(google::INFO); //输出到标准输出的时候大于 INFO 级别的都输出;等同于 FLAGS_stderrthreshold=google::INFO;
FLAGS_logbufsecs =0; //实时输出日志
FLAGS_max_log_size =100; //最大日志大小(MB)
#define GOOGLE_STRIP_LOG 3 // 小于此级别的日志语句将在编译时清除,以减小编译后的文件大小,必须放在 #include 前面才有效。
8、日志文件说明
如果可执行文件名为 "test",则将日志输出到文件后,还会生成 test.ERROR,test.WARNING,test.INFO 三个链接文件,分别链接到对应级别的日志文件。如果日志输出超过 FLAGS_max_log_size 设置的大小,则会分为多个文件存储,链接文件就会指向其中最新的对应级别的日志文件。所以当日志文件较多时,查看链接文件来查看最新日志挺方便的。
三、实用封装
GLogHelper.h 如下:
#include
#include
//将信息输出到单独的文件和 LOG(ERROR)
void SignalHandle(const char* data, int size);
class GLogHelper
{
public:
//GLOG配置:
GLogHelper(char* program);
//GLOG内存清理:
~GLogHelper();
};
GlogHelper.cpp 如下:
#include
#include "GLogHelper.h"
//配置输出日志的目录:
#define LOGDIR "log"
#define MKDIR "mkdir -p "LOGDIR
//将信息输出到单独的文件和 LOG(ERROR)
void SignalHandle(const char* data, int size)
{
std::string str = std::string(data,size);
/*
std::ofstream fs("glog_dump.log",std::ios::app);
fs<以追加模式方可),所以这里发邮件或短信不是很适合,不过倒是可以调用一个 SHELL 或 PYTHON 脚本,而此脚本会先 sleep 3秒左右,然后将错
误信息通过邮件或短信发送出去,这样就不需要监控脚本定时高频率执行,浪费效率了。
}
//GLOG配置:
GLogHelper::GLogHelper(char* program)
{
system(MKDIR);
google::InitGoogleLogging(program);
google::SetStderrLogging(google::INFO); //设置级别高于 google::INFO 的日志同时输出到屏幕
FLAGS_colorlogtostderr=true; //设置输出到屏幕的日志显示相应颜色
//google::SetLogDestination(google::ERROR,"log/error_"); //设置 google::ERROR 级别的日志存储路径和文件名前缀
google::SetLogDestination(google::INFO,LOGDIR"/INFO_"); //设置 google::INFO 级别的日志存储路径和文件名前缀
google::SetLogDestination(google::WARNING,LOGDIR"/WARNING_"); //设置 google::WARNING 级别的日志存储路径和文件名前缀
google::SetLogDestination(google::ERROR,LOGDIR"/ERROR_"); //设置 google::ERROR 级别的日志存储路径和文件名前缀
FLAGS_logbufsecs =0; //缓冲日志输出,默认为30秒,此处改为立即输出
FLAGS_max_log_size =100; //最大日志大小为 100MB
FLAGS_stop_logging_if_full_disk = true; //当磁盘被写满时,停止日志输出
google::SetLogFilenameExtension("91_"); //设置文件名扩展,如平台?或其它需要区分的信息
google::InstallFailureSignalHandler(); //捕捉 core dumped
google::InstallFailureWriter(&SignalHandle); //默认捕捉 SIGSEGV 信号信息输出会输出到 stderr,可以通过下面的方法自定义输出>方式:
}
//GLOG内存清理:
GLogHelper::~GLogHelper()
{
google::ShutdownGoogleLogging();
}
测试文件 test.cpp 如下:
#include "GLogHelper.h"
int main(int argc,char* argv[])
{
//要使用 GLOG ,只需要在 main 函数开始处添加这句即可
GLogHelper gh(argv[0]);
LOG(INFO)<<"INFO";
LOG(ERROR)<<"ERROR";
}
三、自定义修改
参考:http://www.cppfans.org/1566.html
1、增加日志按天输出
glog默认是根据进程ID是否改变和文件大小是否超过预定值来确定是否需要新建日志文件的,此处可以参考glog源码 logging.cc 文件中的 void LogFileObject::Write 函数中
if (static_cast(file_length_ >> 20) >= MaxLogSize() ||
PidHasChanged()) {
我们只需要在此处加一个日期判断就可以了,PidHasChanged() 定义于 utilities.cc 文件中,可以加一个类似的 DayHasChanged() 函数(注意 utilities.h 文件中加上函数声明):
static int32 g_main_day = 0;
bool DayHasChanged()
{
time_t raw_time;
struct tm* tm_info;
time(&raw_time);
tm_info = localtime(&raw_time);
if (tm_info->tm_mday != g_main_day)
{
g_main_day = tm_info->tm_mday;
return true;
}
return false;
}
再修改 void LogFileObject::Write 函数中的判断条件即可:
if (static_cast(file_length_ >> 20) >= MaxLogSize() ||
PidHasChanged() || DayHasChanged()) {
(注:参考 http://www.cppfans.org/1566.html)
【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【【
gflags是什么:
gflags是google的一个开源的处理命令行参数的库,使用c++开发,具备python接口,可以替代getopt。
gflags使用起来比getopt方便,但是不支持参数的简写(例如getopt支持--list缩写成-l,gflags不支持)。
如何安装使用gflags:
安装:请访问地址https://code.google.com/p/gflags/,下载最新版的gflags,编译安装。
使用:
1.首先需要include "gflags.h"
#include
2.将需要的命令行参数使用gflags的宏:DEFINE_xxxxx(变量名,默认值,help-string) 定义在文件当中,注意全局域哦。gflags支持以下类型:

DEFINE_bool: boolean
DEFINE_int32: 32-bit integer
DEFINE_int64: 64-bit integer
DEFINE_uint64: unsigned 64-bit integer
DEFINE_double: double
DEFINE_string: C++ string
3.在main函数中加入:
google::ParseCommandLineFlags(&argc, &argv, true);
argc和argv想必大家都很清楚了,说明以下第三个参数的作用:
如果设为true,则该函数处理完成后,argv中只保留argv[0],argc会被设置为1。
如果为false,则argv和argc会被保留,但是注意函数会调整argv中的顺序。
4.这样,在后续代码中可以使用FLAGS_变量名访问对应的命令行参数了
printf("%s", FLAGS_mystr);
5.最后,编译成可执行文件之后,用户可以使用:executable --参数1=值1 --参数2=值2 ... 来为这些命令行参数赋值。
./mycmd --var1="test" --var2=3.141592654 --var3=32767 --mybool1=true --mybool2 --nomybool3
这里值得注意的是bool类型命令行参数,除了可以使用--xxx=true/false之外,还可以使用--xxx和--noxxx后面不加等号的方式指定true和false
gflags进阶使用:
1.在其他文件中使用定义的flags变量:有些时候需要在main之外的文件使用定义的flags变量,这时候可以使用宏定义DECLARE_xxx(变量名)声明一下(就和c++中全局变量的使用是一样的,extern一下一样)
DECLARE_bool: boolean
DECLARE_int32: 32-bit integer
DECLARE_int64: 64-bit integer
DECLARE_uint64: unsigned 64-bit integer
DECLARE_double: double
DECLARE_string: C++ string
在gflags的doc中,推荐在对应的.h文件中进行DECLARE_xxx声明,需要使用的文件直接include就行了。
2.检验输入参数是否合法:gflags库支持定制自己的输入参数检查的函数,如下:
static bool ValidatePort(const char* flagname, int32 value) {
if (value > 0 && value < 32768) // value is ok
return true;
printf("Invalid value for --%s: %d\n", flagname, (int)value);
return false;
}
DEFINE_int32(port, 0, "What port to listen on");
static const bool port_dummy = RegisterFlagValidator(&FLAGS_port, &ValidatePort);
3.判断flags变量是否被用户使用:在gflags.h中,还定义了一些平常用不到的函数和结构体。这里举一个例子,判断参数port有没有被用户设定过
google::CommandLineFlagInfo info;
if(GetCommandLineFlagInfo("port" ,&info) && info.is_default) {
FLAGS_port = 27015;
}
4.定制你自己的help信息与version信息:(gflags里面已经定义了-h和--version,你可以通过以下方式定制它们的内容)
version信息:使用google::SetVersionString设定,使用google::VersionString访问
help信息:使用google::SetUsageMessage设定,使用google::ProgramUsage访问
注意:google::SetUsageMessage和google::SetVersionString必须在google::ParseCommandLineFlags之前执行
参考:
- https://code.google.com/p/gflags/
- https://gflags.googlecode.com/git-history/master/doc/gflags.html#flagfiles
】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】
{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{{
Linux下getopt()函数的简单使用
最近在弄Linux C编程,本科的时候没好好学啊,希望学弟学妹们引以为鉴。
好了,虽然啰嗦了点,但确实是忠告。步入正题:
我们的主角----getopt()函数。
英雄不问出处,getopt()函数的出处就是unistd.h头文件(哈哈),写代码的时候千万不要忘记把他老人家include上。
再来看一下这家伙的原型(不是六耳猕猴):
int getopt(int argc,char * const argv[ ],const char * optstring);
前两个参数大家不会陌生,没错,就是老大main函数的两个参数!老大传进来的参数自然要有人接着!
第三个参数是个字符串,看名字,我们可以叫他选项字符串(后面会说明)
返回值为int类型,我们都知道char类型是可以转换成int类型的,每个字符都有他所对应的整型值,其实这个返回值返回的就是一个字符,什么字符呢,叫选项字符(姑且这么叫吧,后面会进一步说明)
简单了解了出身和原型,下面我们看看这家伙到底有什么本事吧!
(⊙o⊙)…在此之前还要介绍他的几个兄弟~~~~呃呃呃
小弟1、extern char* optarg;
小弟2、extern int optind;
小弟3、extern int opterr;
小弟4、extern int optopt;
队形排的不错。小弟1是用来保存选项的参数的(先混个脸熟,后面有例子);小弟2用来记录下一个检索位置;小弟3表示的是是否将错误信息输出到stderr,为0时表示不输出,小弟4表示不在选项字符串optstring中的选项(有点乱哈,后面会有例子)
开始逐渐解释上面遗留的问题。
问题1:选项到底是个什么鬼?
在linux下大家都用过这样一条指令吧:gcc helloworld.c -o helloworld.out; 这条指令中的-o就是命令行的选项,而后面的helloworld.out就是-o选项所携带的参数。当然熟悉shell指令的人都知道(虽然我并不熟悉),有些选项是不用带参数的,而这样不带参数的选项可以写在一起(这一点在后面的例子中会用到,希望理解),比如说有两个选项-c和-d,这两个选项都不带参数(而且明显是好基友),那么他们是可以写在一起,写成-cd的。实际的例子:当我们删除一个文件夹时可以使用指令 rm 目录名 -rf,本来-r表示递归删除,就是删除文件夹中所有的东西,-f表示不提示就立刻删除,他们两个都不带参数,这时他们就可以写在一起。
问题2:选项字符串又是何方神圣?
还是看个例子吧
"a:b:cd::e",这就是一个选项字符串。对应到命令行就是-a ,-b ,-c ,-d, -e 。冒号又是什么呢? 冒号表示参数,一个冒号就表示这个选项后面必须带有参数(没有带参数会报错哦),但是这个参数可以和选项连在一起写,也可以用空格隔开,比如-a123 和-a 123(中间有空格) 都表示123是-a的参数;两个冒号的就表示这个选项的参数是可选的,即可以有参数,也可以没有参数,但要注意有参数时,参数与选项之间不能有空格(有空格会报错的哦),这一点和一个冒号时是有区别的。
好了,先给个代码,然后再解释吧。

#include
#include
int main(int argc, char * argv[])
{
int ch;
printf("\n\n");
printf("optind:%d,opterr:%d\n",optind,opterr);
printf("--------------------------\n");
while ((ch = getopt(argc, argv, "ab:c:de::")) != -1)
{
printf("optind: %d\n", optind);
switch (ch)
{
case 'a':
printf("HAVE option: -a\n\n");
break;
case 'b':
printf("HAVE option: -b\n");
printf("The argument of -b is %s\n\n", optarg);
break;
case 'c':
printf("HAVE option: -c\n");
printf("The argument of -c is %s\n\n", optarg);
break;
case 'd':
printf("HAVE option: -d\n");
break;
case 'e':
printf("HAVE option: -e\n");
printf("The argument of -e is %s\n\n", optarg);
break;
case '?':
printf("Unknown option: %c\n",(char)optopt);
break;
}
}
}
编译后命令行执行:# ./main -b "qing er"
输出结果为:
optind:1,opterr:1
--------------------------
optind: 3
HAVE option: -b
The argument of -b is qing er
我们可以看到:optind和opterr的初始值都为1,前面提到过opterr非零表示产生的错误要输出到stderr上。那么optind的初值为什么是1呢?
这就要涉及到main函数的那两个参数了,argc表示参数的个数,argv[]表示每个参数字符串,对于上面的输出argc就为3,argv[]分别为: ./main 和 -b 和"qing er" ,实际上真正的参数是用第二个-b 开始,也就是argv[1],所以optind的初始值为1;
当执行getopt()函数时,会依次扫描每一个命令行参数(从下标1开始),第一个-b,是一个选项,而且这个选项在选项字符串optstring中有,我们看到b后面有冒号,也就是b后面必须带有参数,而"qing er"就是他的参数。所以这个命令行是符合要求的。至于执行后optind为什么是3,这是因为optind是下一次进行选项搜索的开始索引,也是说下一次getopt()函数要从argv[3]开始搜索。当然,这个例子argv[3]已经没有了,此时getopt()函数就会返回-1。
再看一个输入:
./main -b "qing er" -c1234
输出结果为:
optind:1,opterr:1
--------------------------
optind: 3
HAVE option: -b
The argument of -b is qing er
optind: 4
HAVE option: -c
The argument of -c is 1234
对于这个过程会调用三次getopt()函数,和第一个输入一样,是找到选项-b和他的参数"qing er",这时optind的值为3,也就意味着,下一次的getopt()要从argv[3]开始搜索,所以第二次调用getopt()函数,找到选项-c和他的参数1234(选项和参数是连在一起的),由于-c1234写在一起,所以他两占一起占用argv[3],所以下次搜索从argv[4]开始,而argv[4]为空,这样第三次调用getopt()函数就会返回-1,循环随之结束。
接下来我们看一个错误的命令行输入: ./main -z 123
输出为:
optind:1,opterr:1
--------------------------
./main: invalid option -- 'z'
optind: 2
Unknown option: z
其中./main: invalid option -- 'z'就是输出到stderr的错误输出。如果把opterr设置为0那么就不会有这条输出。
在看一个错误的命令行输入: ./main -zheng
optind:1,opterr:1
--------------------------
./main: invalid option -- 'z'
optind: 1
Unknown option: z
./main: invalid option -- 'h'
optind: 1
Unknown option: h
optind: 2
HAVE option: -e
The argument of -e is ng
前面提到过不带参数的选项可以写在一起,所以当getopt()找到-z的时候,发现在optstring 中没有,这时候他就认为h也是一个选项,也就是-h和-z写在一起了,依次类推,直到找到-e,发现optstring中有。
最后要说明一下,getopt()会改变argv[]中参数的顺序。经过多次getopt()后,argv[]中的选项和选项的参数会被放置在数组前面,而optind 会指向第一个非选项和参数的位置。看例子
#include
#include
int main(int argc, char * argv[])
{
int i;
printf("--------------------------\n");
for(i=0;i
命令行:./main zheng -b "qing er" han -c123 qing
输出结果为:
--------------------------
./main
zheng
-b
qing er
han
-c123
qing
--------------------------
optind:1,opterr:1
--------------------------
optind: 4
HAVE option: -b
The argument of -b is qing er
optind: 6
HAVE option: -c
The argument of -c is 123
----------------------------
optind=4,argv[4]=zheng
--------------------------
./main
-b
qing er
-c123
zheng
han
qing
--------------------------
可以看到最开始argv[]内容为:
./main
zheng
-b
qing er
han
-c123
qing
在执行了多次getopt后变成了
./main
-b
qing er
-c123
zheng
han
qing
我们看到,被getopt挑出的选项和对应的参数都按顺序放在了数组的前面,而那些既不是选项又不是参数的会按顺序放在后面。而此时optind为4,即指向第一个非选项也非选项的参数,zheng
花了40多分钟整理,希望能够给需要的人带来帮助。
很多时候我都在寻思,为啥要花时间整理,明明已经非常忙碌了,有这点时间休息一下多好,多惬意?
我总结的原因有一下几个:
1、总结时会注意到之前没有关注的问题,可以加深对问题的理解。
2、方便以后忘记的时候查阅
3、与广大朋友们分享,想想我们从哪些大牛的博客里得到的太多了。我们应当向那些大神学习。把自己学到的分享出来,帮助其他人(虽然我很渣,但是三人行必有我师,应该还是会帮到些人吧)。
共勉!努力!
最后给大家介绍一个写的更加全面的文章:http://blog.csdn.net/huangxiaohu_coder/article/details/7475156
}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}}
===================================================================================================================================================================================================================================================================================================================================================================
Linux下编译clang、libcxx及其相关库——C++11环境搭建
2014年02月11日 10:33:11 vloong 阅读数:4282
一、编译llvm(同时编译compiler-rt和clang)
1、下载llvm代码:
svn co http://llvm.org/svn/llvm-project/llvm/trunk llvm
2、进入llvm/tools目录,下载clang编译器代码:
cd llvm/tools
svn co http://llvm.org/svn/llvm-project/cfe/trunk clang
3、进入llvm/projects目录,下载Compiler-RT代码:
cd ../.. (back to where you started)
cd llvm/projects
svn co http://llvm.org/svn/llvm-project/compiler-rt/trunk compiler-rt
4、在llvm所在目录新建与llvm同一级的目录build,在其中构建llvm和clang:
cd ../.. (back to where you started)
mkdir build (for building without polluting the source dir)
cd build
../llvm/configure
make
【说明】:至此,设置环境变量后,clang及clang++就可以使用了,但如果你还想使用clang++ + libcxx模式,那么请接着下面的步骤接着编译libcxx和libcxxabi。
二、使用clang++编译libcxx和libcxxabi
1、下载libcxx和libcxxabi代码:
svn co http://llvm.org/svn/llvm-project/libcxx/trunk libcxx
svn co http://llvm.org/svn/llvm-project/libcxxabi/trunk libcxxabi
2、进入libcxx/lib目录进行编译:
./buildit
【说明】:如果要用libcxx + libcxxabi的组合替换掉libstdc++,需要将buildit文件中的-lstdc++选项去掉。
3、进入libcxxabi/lib目录进行编译:
./buildit
【说明】:(1)如果要用libcxx + libcxxabi的组合替换掉libstdc++,需要将buildit文件中的-lstdc++选项去掉。
(2)编译过程中可能会报出找不到头文件的错误,是因为在Mac系统下是系统头文件(libcxxabi主要还是用在Mac上,似乎Linux上更多的人推荐用libcxxrt),而在Linux中在/usr/lib/gcc/x86_64-redhat-linux/4.4.4/include/unwind.h目录下(其中目录名称与处理器结构和编译器版本有关)。可以有两种解决方法:
A、如果要使用libcxxabi + libunwind的方式,可以指定-I${libunwind-path}/include选项包含libunwind中的头文件,这样的话可能还需要安装libunwind库;
B、另一种方法就是使用libcxxabi + libgcc_s的方式这就需要使用/usr/lib/gcc/x86_64-redhat-linux/4.4.4/include目录下的,但该目录下还有、之类的头文件,如果你使用-I选项指定了该目录,或许是你的编译器所不愿看到事,而libcxxabi中仅仅是需要中的声明而已,因此可以简单地将/usr/lib/gcc/x86_64-redhat-linux/4.4.4/include/unwind.h拷贝到libcxxabi/include目录下。可是即便是这样,还是有关于__attribute__((__mode__(__unwind_word__)))的错误,对于此错误暂没做深入分析,猜测次编译器扩展中的__unwind_word__只有gcc才认识,你可以简单地将__unwind_word__定义为__word__(#define __unwind_word__ __word__),或将__attribute__((__mode__(__unwind_word__)))注释起来,我就是这么干的,暂没发现错误。
4、手动安装libc++库和libc++abi库及其头文件,如:

cd /usr/lib64
ln -s ${libcxx-path}/lib/libc++.so.1.0 libc++.so.1
ln -s libc++.so.1 libc++.so
ln -s ${libcxxabi-path}/lib/libc++abi.so.1.0 libc++abi.so.1
ln -s libc++abi.so.1 libc++abi.so
cd /usr/include/c++
ln -s ${libcxx-path}/include v1
【说明】:(1)当使用-stdlib=libc++选项后,clang++默认会从/usr/include/c++/v1目录查找libc++头文件;
(2)上面没有列出${libcxxabi-path}/include的安装位置,此项安装因编译器而异,需要替换掉编译器中的相关头文件。
5、使用clang++ + libcxx + libcxxabi编译程序(如:test.cpp):
clang++ -std=c++0x -stdlib=libc++ -lc++abi test.cpp
【说明】:(1)要是最新的clang,上面的-std=c++0x选项可以改为-std=c++11了;
(2)-lc++abi要单独指定显得很累赘,clang-developers论坛中有说将libc++abi静态链接到libc++中就不用显示指定了,本人没测试过,只在此记录一下,以后若有必要再做测试。
三、STL、ABI、UNWIND层次关系
从libcxx和libcxxabi的主页中可以看出:libc++是C++标准库的一份新的实现,支持C++11新标准,而libc++abi是一份新的支撑(support for)C++标准库的底层实现。这里的libcxx就属于STL层,而libcxxabi则属于ABI层,而unwind暂时不了解,只知道ABI层得依赖于它。下图中列出了各个层次中典型的库:

理论上讲,各个层次的组合都可以使用,但是各个库对C++11的支持程度不一样,因此不见得所有组合都能使用,常见的组合有:
(1) libcxx + libcxxabi + libgcc_s
(2) libcxx + libcxxabi + libunwind
(3) libcxx + libcxxrt + libunwind
(4) libstdc++(包括了libsupc++) + libgcc_s
(5) STLport + libsupc++ + libgcc_s
=============================================================================================================================================================================================================================================================================================================================================================================================================================================================
[转]Google gflags使用说明
gflags是什么:
gflags是google的一个开源的处理命令行参数的库,使用c++开发,具备python接口,可以替代getopt。
gflags使用起来比getopt方便,但是不支持参数的简写(例如getopt支持--list缩写成-l,gflags不支持)。
如何安装使用gflags:
安装:请访问地址https://code.google.com/p/gflags/,下载最新版的gflags,编译安装。
使用:
1.首先需要include "gflags.h"
#include
2.将需要的命令行参数使用gflags的宏:DEFINE_xxxxx(变量名,默认值,help-string) 定义在文件当中,注意全局域哦。gflags支持以下类型:

DEFINE_bool: boolean
DEFINE_int32: 32-bit integer
DEFINE_int64: 64-bit integer
DEFINE_uint64: unsigned 64-bit integer
DEFINE_double: double
DEFINE_string: C++ string
3.在main函数中加入:
google::ParseCommandLineFlags(&argc, &argv, true);
argc和argv想必大家都很清楚了,说明以下第三个参数的作用:
如果设为true,则该函数处理完成后,argv中只保留argv[0],argc会被设置为1。
如果为false,则argv和argc会被保留,但是注意函数会调整argv中的顺序。
4.这样,在后续代码中可以使用FLAGS_变量名访问对应的命令行参数了
printf("%s", FLAGS_mystr);
5.最后,编译成可执行文件之后,用户可以使用:executable --参数1=值1 --参数2=值2 ... 来为这些命令行参数赋值。
./mycmd --var1="test" --var2=3.141592654 --var3=32767 --mybool1=true --mybool2 --nomybool3
这里值得注意的是bool类型命令行参数,除了可以使用--xxx=true/false之外,还可以使用--xxx和--noxxx后面不加等号的方式指定true和false
gflags进阶使用:
1.在其他文件中使用定义的flags变量:有些时候需要在main之外的文件使用定义的flags变量,这时候可以使用宏定义DECLARE_xxx(变量名)声明一下(就和c++中全局变量的使用是一样的,extern一下一样)
DECLARE_bool: boolean
DECLARE_int32: 32-bit integer
DECLARE_int64: 64-bit integer
DECLARE_uint64: unsigned 64-bit integer
DECLARE_double: double
DECLARE_string: C++ string
在gflags的doc中,推荐在对应的.h文件中进行DECLARE_xxx声明,需要使用的文件直接include就行了。
2.检验输入参数是否合法:gflags库支持定制自己的输入参数检查的函数,如下:
static bool ValidatePort(const char* flagname, int32 value) {
if (value > 0 && value < 32768) // value is ok
return true;
printf("Invalid value for --%s: %d\n", flagname, (int)value);
return false;
}
DEFINE_int32(port, 0, "What port to listen on");
static const bool port_dummy = RegisterFlagValidator(&FLAGS_port, &ValidatePort);
3.判断flags变量是否被用户使用:在gflags.h中,还定义了一些平常用不到的函数和结构体。这里举一个例子,判断参数port有没有被用户设定过
google::CommandLineFlagInfo info;
if(GetCommandLineFlagInfo("port" ,&info) && info.is_default) {
FLAGS_port = 27015;
}
4.定制你自己的help信息与version信息:(gflags里面已经定义了-h和--version,你可以通过以下方式定制它们的内容)
version信息:使用google::SetVersionString设定,使用google::VersionString访问
help信息:使用google::SetUsageMessage设定,使用google::ProgramUsage访问
注意:google::SetUsageMessage和google::SetVersionString必须在google::ParseCommandLineFlags之前执行
参考:
- https://code.google.com/p/gflags/
- https://gflags.googlecode.com/git-history/master/doc/gflags.html#flagfiles
===========================================================================================================================================================================================================================================================================
jmp_buf的使用,结构定义为数组
2016年03月06日 10:36:17 无风也流 阅读数:3837
转自:jmp_buf的使用,结构定义为数组
今天看《C专家编程》第7章第8节,最后提到用setjmp/longjmp从信号终恢复。顺便敲了代码看看效果,就对其中jmp_buf这个结构感兴趣。查看一下,发现/usr/include/setjmp.h中是这么定义的:

图1
另外__jmp_buf的定义在/usr/include/i386-linux-gnu/bits/setjmp.h:

图2
图1定义方式很奇怪,即将一个结构定义成由一个成员的数组,刚开始不理解为什么,上网搜了一下,发现2005年云风大神已经有博客了。
文章讲得很简略,细细一想,发现了其中的奥秘:
其实这个小的trick主要利用了C语言中数组的性质:我们假设定义jmp_buf buf;
1. 我们用jmp_buf定义一个变量的时候,相当于定义了一个只有一个成员的数组(按照typedef,jmp_buf数据类型就是一个数组类型,因此用它定义的变量也是数组,只不过这个数组比较特殊,数组的成员是一个结构);我们知道定义数组的时候,编译器会分配内存,那么我们定义这个变量大小就是sizeof(jmp_buf)。
2. 我们知道数组名在直接传递的时候会退化成指针,因此可以起到传址的作用。
链接文章中提到在声明的时候可以把数据分配到堆栈(stack)上,我想说,这样就是利用上面提到的。假设我们在一个函数里面声明一个变量,那么变量会被压入stack中,而传递参数或者访问结构的时候传递指针就可以了。
这就是数组的两头都占好的特性吧,定义时候能直接分配好地址,使用的时候还能把数组名当指针用。
再参考:
setjmp 的正确使用