hadoop 3.x大数据集群搭建系列7-安装Hudi
文章目录
- 编译环境准备
- 一. 下载并解压hudi
- 二. maven的下载和配置
-
- 2.1 maven的下载和解压
- 2.2 添加环境变量到/etc/profile中
- 2.3 修改为阿里镜像
- 三. 编译hudi
-
- 3.1 修改pom文件
- 3.2 修改源码兼容hadoop3
- 3.3 手动安装Kafka依赖
- 3.4 解决spark模块依赖冲突
-
- 3.4.1 修改hudi-spark-bundle的pom文件
- 3.4.2 修改hudi-utilities-bundle的pom文件
- 3.5 编译
- 参考:
编译环境准备
| 软件 | 版本 |
|---|---|
| Hadoop | 3.3.2 |
| Hive | 3.1.2 |
| Spark | 3.3.1 |
| Flink | 1.14.5 |
一. 下载并解压hudi
cd /home/software
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hudi/0.12.0/hudi-0.12.0.src.tgz --no-check-certificate
tar -xvf hudi-0.12.0.src.tgz -C /home
二. maven的下载和配置
2.1 maven的下载和解压
cd /home/software
wget https://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-3/3.8.6/binaries/apache-maven-3.8.6-bin.tar.gz --no-check-certificate
tar -xvf apache-maven-3.8.6-bin.tar.gz -C /home
2.2 添加环境变量到/etc/profile中
vi /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/home/apache-maven-3.8.6
export PATH=$PATH:$MAVEN_HOME/bin
2.3 修改为阿里镜像
vi /home/apache-maven-3.8.6/conf/settings.xml
nexus-aliyun
central
Nexus aliyun
http://maven.aliyun.com/nexus/content/groups/public
三. 编译hudi
3.1 修改pom文件
vim /home/hudi-0.12.0/pom.xml
新增repository加速依赖下载
nexus-aliyun
nexus-aliyun
http://maven.aliyun.com/nexus/content/groups/public/
true
false
修改依赖的组件版本
3.3.2
3.1.2
3.2 修改源码兼容hadoop3
Hudi默认依赖的hadoop2,要兼容hadoop3,除了修改版本,还需要修改如下代码:
vim /home/hudi-0.12.0/hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java

3.3 手动安装Kafka依赖
通过网址下载:http://packages.confluent.io/archive/5.3/confluent-5.3.4-2.12.zip
解压后找到以下jar包,上传服务器hp5
common-config-5.3.4.jar
common-utils-5.3.4.jar
kafka-avro-serializer-5.3.4.jar
kafka-schema-registry-client-5.3.4.jar
install到maven本地仓库
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-config -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-config-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-utils -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-utils-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-avro-serializer -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-avro-serializer-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-schema-registry-client-5.3.4.jar
3.4 解决spark模块依赖冲突
修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。
3.4.1 修改hudi-spark-bundle的pom文件
排除低版本jetty,添加hudi指定版本的jetty:
cp /home/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml /home/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml.bak
vim /home/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml
Hive依赖(382行):
guava
com.google.guava
org.eclipse.jetty
*
org.pentaho
*

415行:
javax.servlet
*
javax.servlet.jsp
*
org.eclipse.jetty
*

436行:
javax.servlet
*
org.datanucleus
datanucleus-core
javax.servlet.jsp
*
guava
com.google.guava

461行:
org.eclipse.jetty.orbit
javax.servlet
org.eclipse.jetty
*
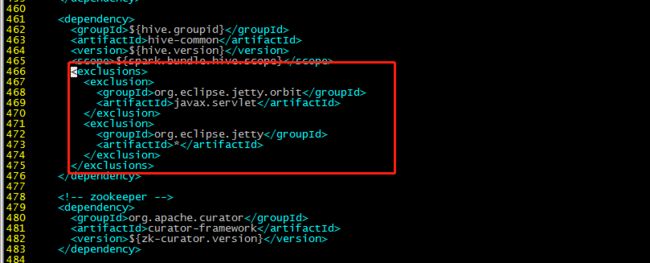
增加hudi配置版本的jetty:
org.eclipse.jetty
jetty-server
${jetty.version}
org.eclipse.jetty
jetty-util
${jetty.version}
org.eclipse.jetty
jetty-webapp
${jetty.version}
org.eclipse.jetty
jetty-http
${jetty.version}
3.4.2 修改hudi-utilities-bundle的pom文件
排除低版本jetty,添加hudi指定版本的jetty:
vim /home/hudi-0.12.0/packaging/hudi-utilities-bundle/pom.xml
345行部分:
org.eclipse.jetty
*
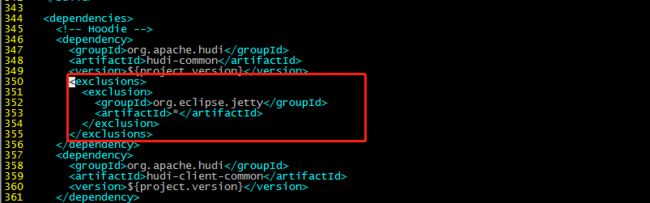
357行:
org.eclipse.jetty
*
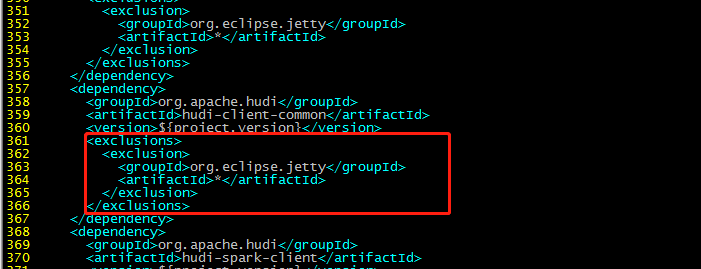
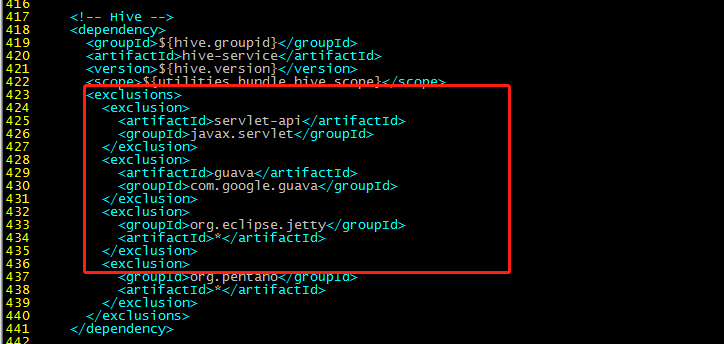
417行部分:
servlet-api
javax.servlet
guava
com.google.guava
org.eclipse.jetty
*
org.pentaho
*
450:
javax.servlet
*
javax.servlet.jsp
*
org.eclipse.jetty
*
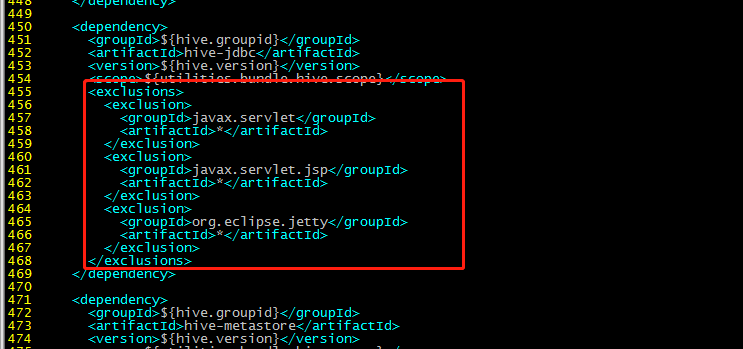
471行:
javax.servlet
*
org.datanucleus
datanucleus-core
javax.servlet.jsp
*
guava
com.google.guava
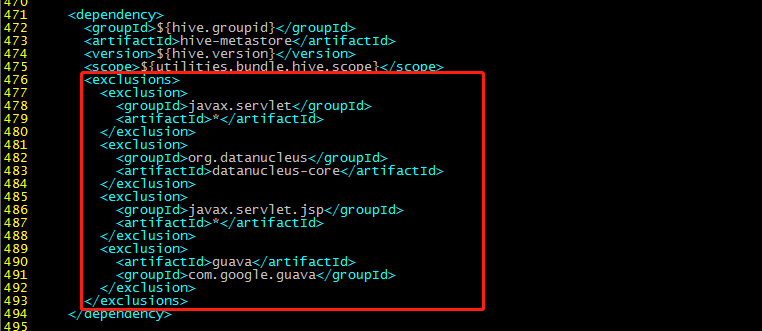
496行:
org.eclipse.jetty.orbit
javax.servlet
org.eclipse.jetty
*
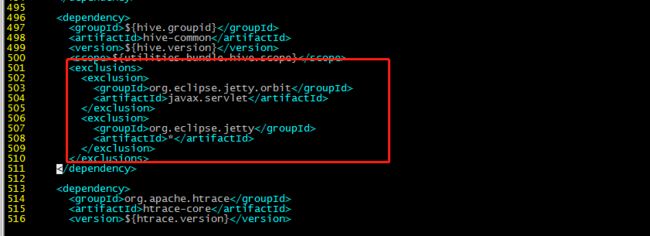
增加:
org.eclipse.jetty
jetty-server
${jetty.version}
org.eclipse.jetty
jetty-util
${jetty.version}
org.eclipse.jetty
jetty-webapp
${jetty.version}
org.eclipse.jetty
jetty-http
${jetty.version}
3.5 编译
cd /home/hudi-0.12.0
mvn clean package -DskipTests -Dspark3.3 -Dflink1.14 -Dscala-2.12 -Dhadoop.version=3.3.2 -Pflink-bundle-shade-hive3
报错:
这个报错在网上找了好久都没找到解决方案,后来想了下,我使用的是open jdk11,换回JDK8版本,此问题解决。
安装apache的各个组件,还是继续使用JDK8版本吧,别使用open jdk了,坑太多了。
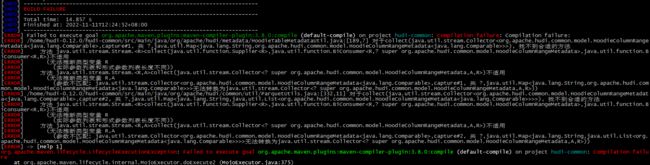
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.8.0:compile (default-compile) on project hudi-common: Compilation failure: Compilation failure:
[ERROR] /home/hudi-0.12.0/hudi-common/src/main/java/org/apache/hudi/metadata/HoodieTableMetadataUtil.java:[189,7] 对于collect(java.util.stream.Collector,capture#1, 共 ?,java.util.Map>>), 找不到合适的方法
[ERROR] 方法 java.util.stream.Stream.collect(java.util.function.Supplier,java.util.function.BiConsumer,java.util.function.BiConsumer)不适用
[ERROR] (无法推断类型变量 R
[ERROR] (实际参数列表和形式参数列表长度不同))
[ERROR] 方法 java.util.stream.Stream.collect(java.util.stream.Collector)不适用
[ERROR] (无法推断类型变量 R,A
[ERROR] (参数不匹配; java.util.stream.Collector,capture#1, 共 ?,java.util.Map>>无法转换为java.util.stream.Collector))
[ERROR] /home/hudi-0.12.0/hudi-common/src/main/java/org/apache/hudi/common/util/ParquetUtils.java:[332,11] 对于collect(java.util.stream.Collector,capture#2, 共 ?,java.util.Map>>>), 找不到合适的方法
[ERROR] 方法 java.util.stream.Stream.collect(java.util.function.Supplier,java.util.function.BiConsumer,java.util.function.BiConsumer)不适用
[ERROR] (无法推断类型变量 R
[ERROR] (实际参数列表和形式参数列表长度不同))
[ERROR] 方法 java.util.stream.Stream.collect(java.util.stream.Collector)不适用
[ERROR] (无法推断类型变量 R,A
[ERROR] (参数不匹配; java.util.stream.Collector,capture#2, 共 ?,java.util.Map>>>无法转换为java.util.stream.Collector))
[ERROR] -> [Help 1]
编译成功:

编译成功后,进入hudi-cli说明成功:
cd /home/hudi-0.12.0/hudi-cli
./hudi-cli.sh
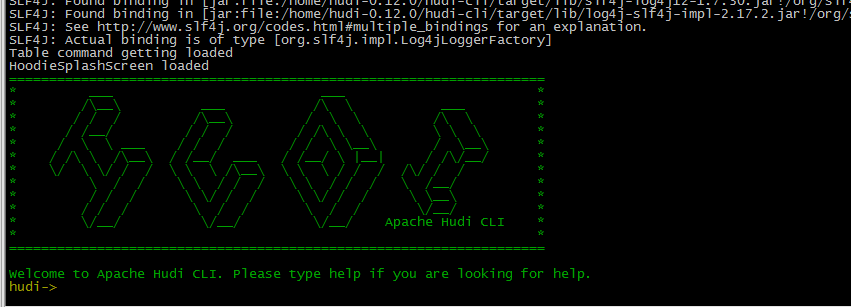
相关的jar包:
编译完成后,相关的包在packaging目录的各个模块中:
比如,flink与hudi的包:
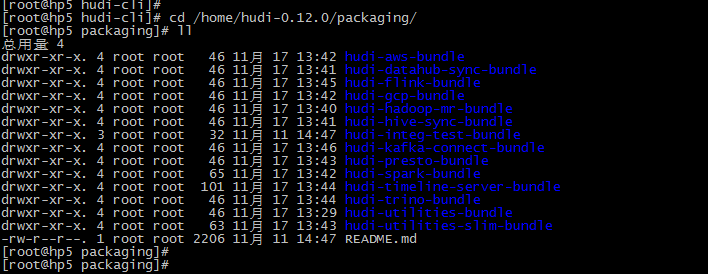
参考:
- https://blog.csdn.net/weixin_36939535/article/details/125595536
- https://blog.csdn.net/weixin_45417821/article/details/127407461