我理解的Volatile三大特性概念详解
文章目录
- 一、volatile是java提供的一种轻量级的同步机制
-
- 1.并发三大特性:原子性,可见性,有序性
- 2.首先理解一个概念 内存屏障(概念)以及它的基本使用
- 3.了解 线程从主内存修改数据 需要进行的步骤(概念):
- 二、volatile三大特性:保证可见性、不保证原子性、禁止指令重排序
-
- 1.保证可见性
- 2.不保证原子性
- 3.禁止指令重排序
- 三、参考链接
一、volatile是java提供的一种轻量级的同步机制
1.并发三大特性:原子性,可见性,有序性
- 原子性指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
- 可见性指当一个线程修改了某一个共享变量的值,其他的线程是否能够立即知道这个修改。显然,对于串行程序来说,可见性问题是不存在的。因为我们在任何一个操作步骤中修改了某个变量,那么在后续的步骤中,读取这个变量一定是修改后的值。
- 有序性指对于一个线程的执行代码,我们习惯性的认为代码的执行是从前往后,依次执行的。但是在并发时,程序的执行可能会出现乱序。给人直观的感觉就是:写在前面的代码,可能会在后面执行。
2.首先理解一个概念 内存屏障(概念)以及它的基本使用
内存屏障(memory barrier)是一个CPU指令。
基本上,它是这样一条指令:
a) 确保一些特定操作执行的顺序;
b) 影响一些数据的可见性(可能是某些指令执行后的结果)。
以上也就是volatile保证可见性与禁止指令重排序的方法
其次理解一下 内存屏障的基本使用(概念):
编译器和CPU可以在保证输出结果一样的情况下对指令重排序,使性能得到优化。
插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。
内存屏障另一个作用是强制更新一次不同CPU的缓存。
例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,
这样任何试图读取该数据的线程将得到最新值,而不用考虑到底是被哪个CPU核心或者哪颗CPU执行的。
内存屏障(memory barrier)和volatile什么关系?
如果你的字段是volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令。
这意味着如果你对一个volatile字段进行写操作,
你必须知道:
1.一旦你完成写入,任何访问这个字段的线程将会得到最新的值。
2.在你写入前,会保证所有之前发生的事已经发生,并且任何更新过的数据值也是可见的,
因为内存屏障会把之前的写入值都刷新到缓存。
3.了解 线程从主内存修改数据 需要进行的步骤(概念):
- read:从主内存中读取数据
- load:加载到某个线程中的私有工作内存中
- use:使用某个或某些数据
- assign:对某个或某些数据进行赋值运算
- store:将结果存储在私有工作内存中
- write:将结果写入主内存中
且线程之间无法直接传入变量
二、volatile三大特性:保证可见性、不保证原子性、禁止指令重排序
1.保证可见性
早期:对共享变量加一把总线锁
现在:MESI缓存一致性协议,CPU总线嗅探机制(监听机制)
①如果线程内的共享变量发生改变,则当前处理器的缓存立即同步到主内存,缓存行锁定
②触发MESI缓存一致性,线程工作内存共享变量失效
首先理解一个概念读写冲突:
当线程 A 获取读锁时,
如果线程 B 正在执行写操作,线程 A 需要等待,否则会引起 read-write conflict(读写冲突)。
如果线程 B 正在执行读操作,线程 A 不需要等待,因为 read-read 不会引起 conflict(冲突)。
当线程 A 要获取写入锁时,
如果线程 B 正在执行写操作,线程 A 需要等待,否则会引起 write-write conflict(写写冲突)。
如果线程 B 正在执行读操作,则线程 A 需要等待,否则会引起 read-write conflict(读写冲突)。
测试代码:
//实体类,观察num值的可见性,此时没有volatile
class Volatile{
int num=0;
public void addTo60(){
this.num=60;
}
}
//测试类
public class MyClass {
public static void main(String[] args) {
seeVolatileOk();//测试可见性
}
//aaa线程修改num值为60后,main线程拿到的num=0,死循环。说明线程之间共享变量不可见。
private static void seeVolatileOk() {
Volatile v = new Volatile();
new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"\t come in ");;
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
v.addTo60();
System.out.println(Thread.currentThread().getName()+"\t updated num value:"+v.num);
},"aaa").start();
while (v.num==0){
}
System.out.println(Thread.currentThread().getName()+"\t mission is over,updated num value:"+v.num);
}
结果:
未定义为volatile:

定义为volatile:

TIPS:那么说明了volatile可以保证线程间的可见性
2.不保证原子性
单个基本数据类型的基本运算可以看作时保证原子性的,但多个基本数据类型运算不能保证。
比如:
int j=1;//可保证
int z=j;//不能保证
z++;//不能保证
基本原理:当多个线程对同一使用volatile定义的共享变量进行num++时:
执行num++需要进行以下步骤:
1、线程读取num 2、temp = num + 1 3、num = temp
首先线程a,b读取到num=0,
线程a开始执行temp=num+1,线程b开始执行temp=num+1,此时线程a,b的私有工作内存中num=0,temp=1,
此时a执行num=temp,由于MESI缓存一致性与cpu总线嗅探机制(监控机制),
此时num的值会立即刷新到主存并通知其他线程保存的 num 值失效,
此时B线程需要重新读取 num 的值那么此时B线程保存的 num 就是1,
同时B线程保存的 temp 还仍然是1, 然后B线程执行 num=temp ,所以导致了计算结果比预期少了1
测试代码:
//注意此时已加上volatile ! ! !
class Volatile{
volatile int num=0;
public void addPlusPlus(){
this.num++;//num++ 不保证原子性
}
}
public class MyClass {
public static void main(String[] args) {
atomicIntegerOk();//测试原子性
}
//20000个线程执行num++,按习惯来说num=20000,然而······
private static void atomicIntegerOk() {
Volatile v = new Volatile();
for (int i = 0; i < 20; i++) {
for (int j = 0; j < 1000; j++) {
new Thread(()->{
v.addPlusPlus();
},String.valueOf(i)).start();
}
}
while (Thread.activeCount()>2){
Thread.yield();
}
System.out.println(Thread.currentThread().getName()+"\t updated int num value:"+v.num);
System.out.println(3*0.1==0.3);//false精度问题
System.out.println(new Integer(30).equals(new Integer(30)));//相等,包装类型缓存
}
}
结果:

多执行几次:


解决方法:
1.在方法体中加上synchronized,不推荐性能损耗太大
2.利用java.util.concurrent.atomic.AtomicInteger类
上代码:
class Volatile{
volatile int num=0;
public void addPlusPlus(){
this.num++;
}
AtomicInteger atomicInteger=new AtomicInteger();
public void addMyTomic(){
atomicInteger.getAndIncrement();//调用自增1方法
}
}
public class MyClass {
public static void main(String[] args) {
// seeVolatileOk();
atomicIntegerOk();
}
private static void atomicIntegerOk() {
Volatile v = new Volatile();
for (int i = 0; i < 20; i++) {
for (int j = 0; j < 1000; j++) {
new Thread(()->{
v.addPlusPlus();
v.addMyTomic();
},String.valueOf(i)).start();
}
}
while (Thread.activeCount()>2){
Thread.yield();
}
System.out.println(Thread.currentThread().getName()+"\t updated int num value:"+v.num);
System.out.println(Thread.currentThread().getName()+"\t updated Atomic Integer num value:"+v.atomicInteger);
}
结果(对比):

多执行几次:


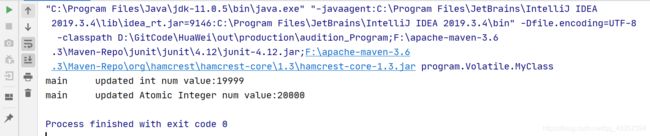
执行了五六遍,总算有等于的结果了
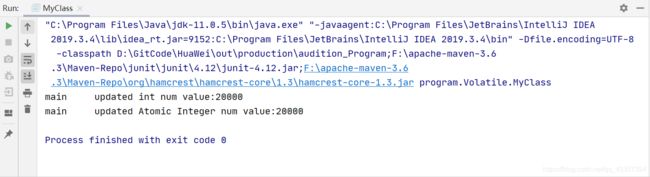
TIPS:说明了不保证原子性,且用volatile修饰的变量num执行自增后结果应该是<=20000 注意这个等号!
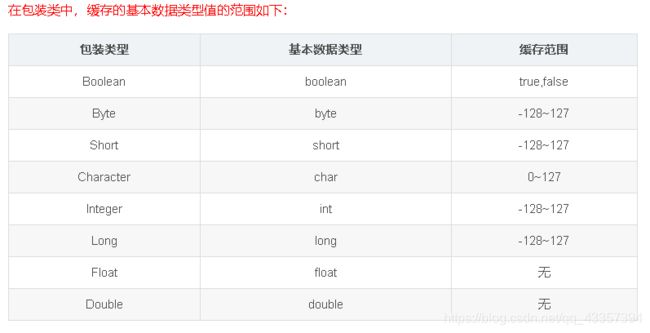
对于代码中最后一个问题,可以参考 Java中的包装类缓存,好文要强推!
3.禁止指令重排序

三、参考链接
Java中的包装类缓存
Java多线程优化都不会,怎么拿Offer?
volatile为什么不能保证原子性
volatile实现禁止指令重排底层操作原理