数据分析4 - 实战篇
数据分析实战4.实战篇
37丨数据采集实战:如何自动化运营微博?
目标
- 掌握 Selenium 自动化测试工具,以及元素定位的方法;
- 学会编写微博自动化功能模块:加关注,写评论,发微博;
- 对微博自动化做自我总结。
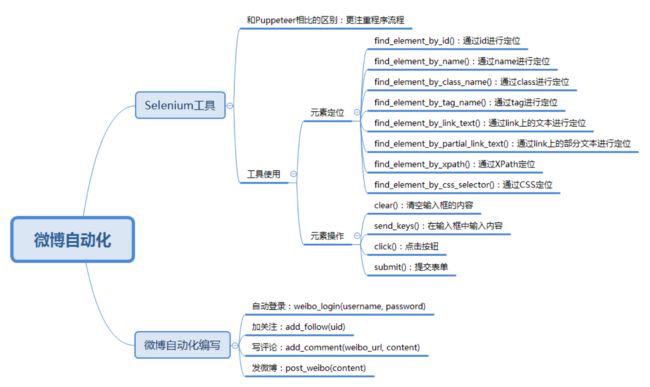
Selenium 自动化测试工具
当我们做 Web 自动化测试的时候,可以选用 Selenium 或者 Puppeteer 工具。我在第 10 篇的时候简单介绍过 Selenium 这个工具,你可以再回顾一下。Puppeteer 通过控制无头 Chrome 来完成浏览器的工作。这两个工具之间的区别在于:Selenium 更关注程序执行的流程本身,比如找到指定的元素,设置相应的值,然后点击操作。而 Puppeteer 是浏览者的视角,比如光标移动到某个元素上,键盘输入某个内容等。
今天我们继续使用 Selenium 工具自动化模拟浏览器,重点是学习对元素的定位。在第 10 篇讲到 Selenium WebDriver 的使用时,重点是对 HTML 进行获取和解析,然后通过 HTML 中的 XPath 进行提取,读取相应的内容。
在今天的实战里,我们需要在微博上自动登录,加关注,发评论,发微博等,这些操作都需要在浏览器上完成,所以我们可以使用 Webdriver 自带的元素定位功能。
如果我们想定位一个元素,可以通过 id、name、class、tag、链接上的全部文本、链接上的部分文本、XPath 或者 CSS 进行定位,在 Selenium Webdriver 中也提供了这 8 种方法方便我们定位元素。
- 通过 id 定位:我们可以使用 find_element_by_id() 函数。比如我们想定位 id=loginName 的元素,就可以使用 browser.find_element_by_id(“loginName”)。
- 通过 name 定位:我们可以使用 find_element_by_name() 函数,比如我们想要对 name=key_word 的元素进行定位,就可以使用 browser.find_element_by_name(“key_word”)。
- 通过 class 定位:可以使用 find_element_by_class_name() 函数。
- 通过 tag 定位:使用 find_element_by_tag_name() 函数。
- 通过 link 上的完整文本定位:使用 find_element_by_link_text() 函数。
- 通过 link 上的部分文本定位:使用 find_element_by_partial_link_text() 函数。有时候超链接上的文本很长,我们通过查找部分文本内容就可以定位。
- 通过 XPath 定位:使用 find_element_by_xpath() 函数。使用 XPath 定位的通用性比较好,因为当 id、name、class 为多个,或者元素没有这些属性值的时候,XPath 定位可以帮我们完成任务。
- 通过 CSS 定位:使用 find_element_by_css_selector() 函数。CSS 定位也是常用的定位方法,相比于 XPath 来说更简洁。
在我们获取某个元素之后,就可以对这个元素进行操作了,对元素进行的操作包括:
- 清空输入框的内容:使用 clear() 函数;
- 在输入框中输入内容:使用 send_keys(content) 函数传入要输入的文本;
- 点击按钮:使用 click() 函数,如果元素是个按钮或者链接的时候,可以点击操作;
- 提交表单:使用 submit() 函数,元素对象为一个表单的时候,可以提交表单;
微博自动化运营:加关注,写评论,发微博

总结
思考
-
对某个指定用户的 UID 做取消关注的操作,请你使用今天讲的元素定位和操作功能,编写相应的代码。
-
通过今天自动化测试工具的学习,你有怎样的收获和总结呢?
38丨数据可视化实战:如何给毛不易的歌曲做词云展示?
目标
- 掌握词云分析工具,并进行可视化呈现;
- 掌握 Python 爬虫,对网页的数据进行爬取;
- 掌握 XPath 工具,分析提取想要的元素 。
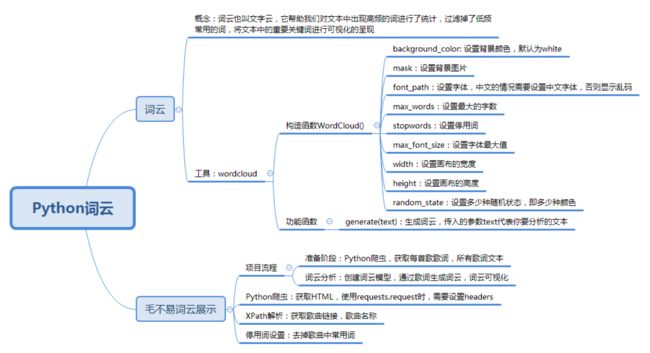
如何制作词云
首先我们需要了解什么是词云。词云也叫文字云,它帮助我们统计文本中高频出现的词,过滤掉某些常用词(比如“作曲”“作词”),将文本中的重要关键词进行可视化,方便分析者更好更快地了解文本的重点,同时还具有一定的美观度。
Python 提供了词云工具 WordCloud,使用 pip install wordcloud 安装后,就可以创建一个词云。
从结果中看出,还是有一些常用词显示出来了,比如“什么”“要求”“这些”等,我们可以把这些词设置为停用词。
给毛不易的歌词制作词云

- 在准备阶段:我们主要使用 Python 爬虫获取 HTML,用 XPath 对歌曲的 ID、名称进行解析,然后通过网易云音乐的 API 接口获取每首歌的歌词,最后将所有的歌词合并得到一个变量。
- 在词云分析阶段,我们需要创建 WordCloud 词云类,分析得到的歌词文本,最后可视化。
总结
思考题
最后给你留一道思考题吧。我抓取了毛不易主页的歌词,是以歌手主页为粒度进行的词云可视化。实际上网易云音乐也有歌单的 API,比如 http://music.163.com/api/playlist/detail?id=753776811 。你能不能编写代码对歌单做个词云展示(比如歌单 ID 为 753776811)呢?
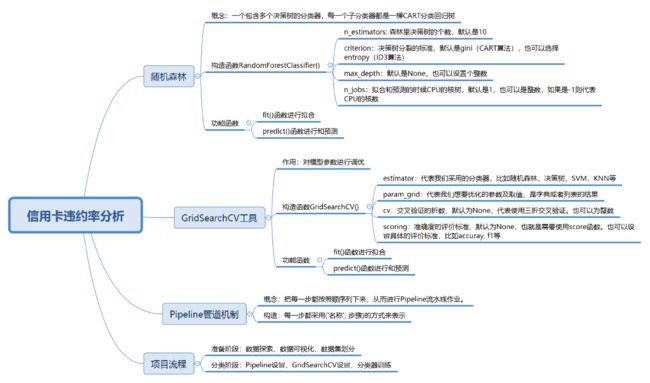
39丨数据挖掘实战(1):信用卡违约率分析
数据挖掘核心的问题
- 如何选择各种分类器,到底选择哪个分类算法,是 SVM,决策树,还是 KNN?
- 如何优化分类器的参数,以便得到更好的分类准确率?
目标
- 创建各种分类器,包括已经掌握的 SVM、决策树、KNN 分类器,以及随机森林分类器;
- 掌握 GridSearchCV 工具,优化算法模型的参数;
- 使用 Pipeline 管道机制进行流水线作业。因为在做分类之前,我们还需要一些准备过程,比如数据规范化,或者数据降维等。
构建随机森林分类器
随机森林的英文是 Random Forest,英文简写是 RF。它实际上是一个包含多个决策树的分类器,每一个子分类器都是一棵 CART 分类回归树。所以随机森林既可以做分类,又可以做回归。当它做分类的时候,输出结果是每个子分类器的分类结果中最多的那个。你可以理解是每个分类器都做投票,取投票最多的那个结果。当它做回归的时候,输出结果是每棵 CART 树的回归结果的平均值。
使用 GridSearchCV 工具对模型参数进行调优
Python 给我们提供了一个很好用的工具 GridSearchCV,它是 Python 的参数自动搜索模块。我们只要告诉它想要调优的参数有哪些以及参数的取值范围,它就会把所有的情况都跑一遍,然后告诉我们哪个参数是最优的,结果如何。
使用 Pipeline 管道机制进行流水线作业
做分类的时候往往都是有步骤的,比如先对数据进行规范化处理,你也可以用 PCA 方法(一种常用的降维方法)对数据降维,最后使用分类器分类。
Python 有一种 Pipeline 管道机制。管道机制就是让我们把每一步都按顺序列下来,从而创建 Pipeline 流水线作业。每一步都采用 (‘名称’, 步骤) 的方式来表示。
我们需要先采用 StandardScaler 方法对数据规范化,即采用数据规范化为均值为 0,方差为 1 的正态分布,然后采用 PCA 方法对数据进行降维,最后采用随机森林进行分类。
对信用卡违约率进行分析
现在我们的目标是要针对这个数据集构建一个分析信用卡违约率的分类器。具体选择哪个分类器,以及分类器的参数如何优化,我们可以用 GridSearchCV 这个工具跑一遍。

- 加载数据;
- 准备阶段:探索数据,采用数据可视化方式可以让我们对数据有更直观的了解,比如我们想要了解信用卡违约率和不违约率的人数。因为数据集没有专门的测试集,我们还需要使用 train_test_split 划分数据集。
- 分类阶段:之所以把数据规范化放到这个阶段,是因为我们可以使用 Pipeline 管道机制,将数据规范化设置为第一步,分类为第二步。因为我们不知道采用哪个分类器效果好,所以我们需要多用几个分类器,比如 SVM、决策树、随机森林和 KNN。然后通过 GridSearchCV 工具,找到每个分类器的最优参数和最优分数,最终找到最适合这个项目的分类器和该分类器的参数。
总结
今天我给你讲了随机森林的概念及工具的使用,另外针对数据挖掘算法中经常采用的参数调优,也介绍了 GridSearchCV 工具这个利器。并将这两者结合起来,在信用卡违约分析这个项目中进行了使用。
很多时候,我们不知道该采用哪种分类算法更适合。即便是对于一种分类算法,也有很多参数可以调优,每个参数都有一定的取值范围。我们可以把想要采用的分类器,以及这些参数的取值范围都设置到数组里,然后使用 GridSearchCV 工具进行调优。
思考
另外针对信用卡违约率分析这个项目,我们使用了 SVM、决策树、随机森林和 KNN 分类器,你能不能编写代码使用 AdaBoost 分类器做分类呢?其中 n_estimators 的取值有 10、50、100 三种可能,你可以使用 GridSearchCV 运行看看最优参数是多少,测试准确率是多少?
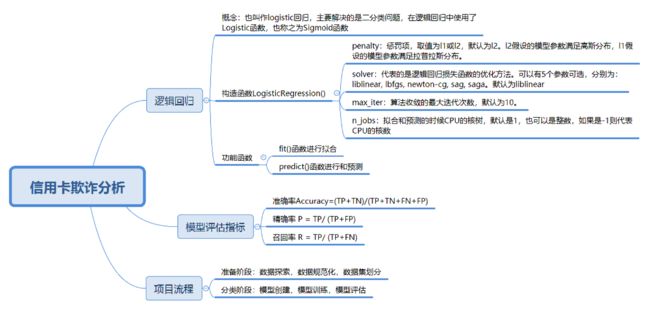
40丨数据挖掘实战(2):信用卡诈骗分析
相比于信用卡违约的比例,信用卡欺诈的比例更小,但是危害极大。如何通过以往的交易数据分析出每笔交易是否正常,是否存在盗刷风险是我们这次项目的目标。
通过今天的学习,你需要掌握以下几个方面:
- 了解逻辑回归分类,以及如何在 sklearn 中使用它;
- 信用卡欺诈属于二分类问题,欺诈交易在所有交易中的比例很小,对于这种数据不平衡的情况,到底采用什么样的模型评估标准会更准确;
- 完成信用卡欺诈分析的实战项目,并通过数据可视化对数据探索和模型结果评估进一步加强了解。
构建逻辑回归分类器
逻辑回归,也叫作 logistic 回归。虽然名字中带有“回归”,但它实际上是分类方法,主要解决的是二分类问题,当然它也可以解决多分类问题,只是二分类更常见一些。
在逻辑回归中使用了 Logistic 函数,也称为 Sigmoid 函数。Sigmoid 函数是在深度学习中经常用到的函数之一,函数公式为:
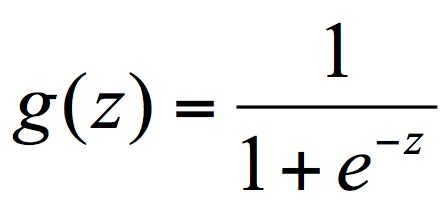
函数的图形如下所示,类似 S 状:

模型评估指标
我们之前对模型做评估时,通常采用的是准确率 (accuracy),它指的是分类器正确分类的样本数与总体样本数之间的比例。这个指标对大部分的分类情况是有效的,不过当分类结果严重不平衡的时候,准确率很难反应模型的好坏。
先介绍下数据预测的四种情况:TP、FP、TN、FN。我们用第二个字母 P 或 N 代表预测为正例还是负例,P 为正,N 为负。第一个字母 T 或 F 代表的是预测结果是否正确,T 为正确,F 为错误。
所以四种情况分别为:
- TP:预测为正,判断正确;
- FP:预测为正,判断错误;
- TN:预测为负,判断正确;
- FN:预测为负,判断错误。
我们知道样本总数 =TP+FP+TN+FN,预测正确的样本数为 TP+TN,因此准确率 Accuracy = (TP+TN)/(TP+TN+FN+FP)。
实际上,对于分类不平衡的情况,有两个指标非常重要,它们分别是精确度和召回率。
精确率 P = TP/ (TP+FP),对应上面恐怖分子这个例子,在所有判断为恐怖分子的人数中,真正是恐怖分子的比例。
召回率 R = TP/ (TP+FN),也称为查全率。代表的是恐怖分子被正确识别出来的个数与恐怖分子总数的比例。
为什么要统计召回率和精确率这两个指标呢?假设我们只统计召回率,当召回率等于 100% 的时候,模型是否真的好呢?
举个例子,假设我们把机场所有的人都认为是恐怖分子,恐怖分子都会被正确识别,这个数字与恐怖分子的总数比例等于 100%,但是这个结果是没有意义的。如果我们认为机场里所有人都是恐怖分子的话,那么非恐怖分子(极高比例)都会认为是恐怖分子,误判率太高了,所以我们还需要统计精确率作为召回率的补充。
实际上有一个指标综合了精确率和召回率,可以更好地评估模型的好坏。这个指标叫做 F1,用公式表示为:
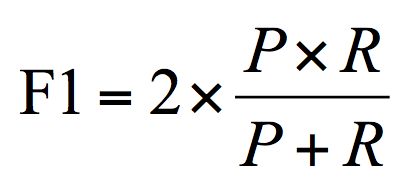
F1 作为精确率 P 和召回率 R 的调和平均,数值越大代表模型的结果越好。
对信用卡违约率进行分析
- 加载数据;
- 准备阶段:我们需要探索数据,用数据可视化的方式查看分类结果的情况,以及随着时间的变化,欺诈交易和正常交易的分布情况。上面已经提到过,V1-V28 的特征值都经过 PCA 的变换,但是其余的两个字段,Time 和 Amount 还需要进行规范化。Time 字段和交易本身是否为欺诈交易无关,因此我们不作为特征选择,只需要对 Amount 做数据规范化就行了。同时数据集没有专门的测试集,使用 train_test_split 对数据集进行划分;
- 分类阶段:我们需要创建逻辑回归分类器,然后传入训练集数据进行训练,并传入测试集预测结果,将预测结果与测试集的结果进行比对。这里的模型评估指标用到了精确率、召回率和 F1 值。同时我们将精确率 - 召回率进行了可视化呈现。
总结
思考题
最后留两道思考题吧,今天我们对信用卡欺诈数据集进行了分析,它是一个不平衡数据集,你知道还有哪些数据属于不平衡数据么?另外,请你使用线性 SVM(对应 sklearn 中的 LinearSVC)对信用卡欺诈数据集进行分类,并计算精确率、召回率和 F1 值。
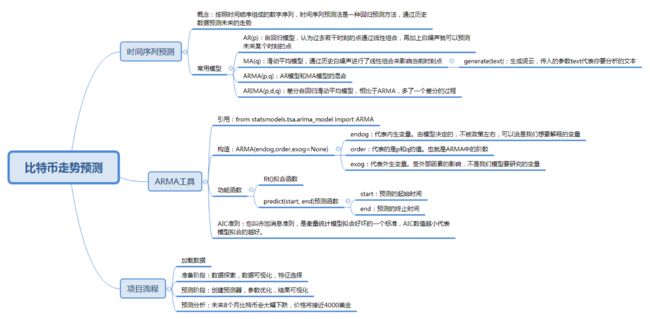
41丨数据挖掘实战(3):如何对比特币走势进行预测?
总结
今天我给你讲了一个比特币趋势预测的实战项目。通过这个项目你应该能体会到,当我们对一个数值进行预测的时候,如果考虑的是多个变量和结果之间的关系,可以采用回归分析,如果考虑单个时间维度与结果的关系,可以使用时间序列分析。
根据比特币的历史数据,我们使用 ARMA 模型对比特币未来 8 个月的走势进行了预测,并对结果进行了可视化显示。你能看到 ARMA 工具还是很好用的,虽然比特币的走势受很多外在因素影响,比如政策环境。不过当我们掌握了这些历史数据,也不妨用时间序列模型来分析预测一下。
思考
最后依然是思考题环节,今天我们讲了 AR、MA、ARMA 和 ARIMA,你能简单说说它们之间的区别么?
另外我在GitHub中上传了沪市指数的历史数据(对应的 shanghai_1990-12-19_to_2019-2-28.csv),请你编写代码使用 ARMA 模型对沪市指数未来 10 个月(截止到 2019 年 12 月 31 日)的变化进行预测(将数据转化为按月统计即可)。