python爬虫(十三)selenium(Selenium入门、chromedriver、Phantomjs)
Selenium介绍
爬虫与反爬虫
使用爬虫程序会给服务器造成一定的压力,维护者会制定一系列的反爬机制,二者进行相互切磋。
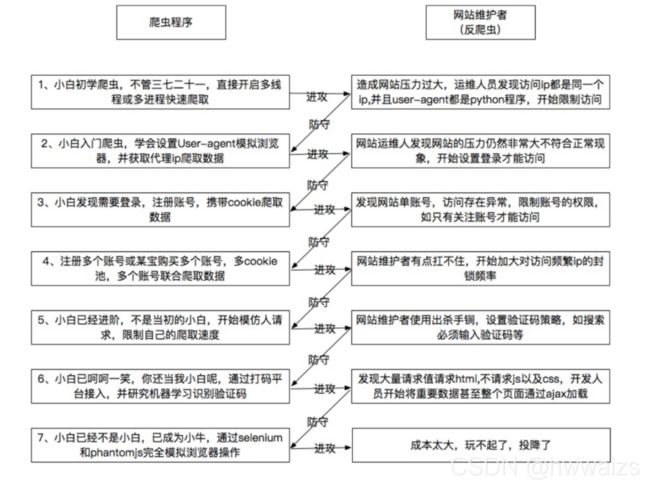
爬虫建议
- 尽量减少请求次数,程序执行速度比较快,会对服务器产生压力,管理者会指定一系列的反爬机制进行制衡,可以将请求到的网页源码保存获取到的HTML,供查错和重复使用
- 关注网站的所有类型的页面
H5页面:html5 = html4 + css3 +JavaScript
APP - 多伪装
代理IP,设置代码格式是固定的,免费的代理IP并不多
随机请求头,进行爬虫的时候可能不是只请求一次,如果多次请求只用一个请求头,会出现问题。
方式一:百度搜索请求头大全
方式二:安装UserAgent模块,可以随机生成请求头
from fake_useragent import UserAgent
ua = UserAgent()
print(ua.random) # 随机生成请求头
print(ua.Chrome) # 指定浏览器,谷歌
print(ua.Firefox) # 指定浏览器,火狐
- 利用多线程分布式
在不被发现的情况下我们尽可能的提高速度。
之前进行的爬取都是从上至下一条一条的爬取,当中间的一条内容出错,下载不了的时候,程序就会卡到那;多线程可以同时进行多个网站多个页面、图片的爬取,但是会导致资源的竞争,加锁之后,代码量增多,出现bug的几率也会增大。scrapy内置了异步网络框架,基于多线程的思想开发的,速度很快。分布式指的是多台计算机同时进行,机器足够多就可以在单位时间内多进行操作。
ajax基本介绍
动态了解HTML技术
JS(了解)
是网络上最常用的脚本语言,它可以收集用户的跟踪数据,不需要重载页面直接提交表单,在页面嵌入多媒体文件,甚至运行网页
jQuery(了解)
jQuery是一个快速、简介的JavaScript框架,封装了JavaScript常用的功能代码
ajax(掌握)
ajax可以使用网页实现异步更新,可以在不重新加载整个网页的情况下,对网页的某部分进行更新,针对的是网页上有,但是网页源码中找不到的数据,可以通过分析数据接口和selenium两种方法
获取ajax数据的方式
1.直接分析ajax调用的接口。然后通过代码请求这个接口。
2.使用Selenium+chromedriver模拟浏览器行为获取数据
selenium的工作原理是让程序去连接浏览器,完成各种各样复杂的操作。本身是自动化测试工具,可以模仿人的行为打开、操作浏览器,程序员可以直接去网页中提取各种各样的信息,在网页上人能看到的内容,对于selenium来说是透明的。
| 方式 | 优点 | 缺点 |
|---|---|---|
| 分析接口 | 直接可以请求到数据。不需要做一些解析工作。代码量少,性能高 | 分析接口比较复杂,特别是一些通过js混淆的接口,要有一定的js功底。容易被发现是爬虫 |
| Selenium | 直接模拟浏览器的行为。浏览器能请求到的,使用selenium也能请求到。爬虫更稳定。 | 代码量多。性能低 |
Selenium+chromedriver
Selenium 介绍
之前爬取的网页大多都是静态的,是在服务器端渲染,然后把网页源码给到浏览器,在浏览器端加载出来网页显示的界面。向对应的url发起请求,在响应对象中获取到网页源码,再对数据进行解析,得到需要的数据。
还有些网页的数据在网页中看不到的,如12306,页面是通过Ajax加载出来的,直接发起请求获取不到想要的数据,我们要找到真正的数据接口,从XHR中找到相关的数据包进行分析。
如果我们想要爬取网页中有 但是源码中找不着的数据
- 分析数据接口(network) XHR的全称是XMLHttpRequest,分析数据接口比较麻烦,数据解析比较简单
- 通过selenium。如12306的车次列表的数据表格,是动态加载出来的,用户可以直接看到,借助selenium工具打开网页也会有这些数据,可以通过selenium去爬取数据。用代码操控selenium工具能代替人去打开网页。
通过分析数据接口爬取案例可以参照python爬虫(十一、十二)爬取贴吧图片和练习爬取好看视频和新发地菜价
selenium是一个web的自动化测试工具,最初是为网站自动化测试而开发的,selenium可以直接运行在浏览器上,它支持所有主流的浏览器,可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏。使用之前先通过 pip install selenium 来安装selenium 。
Phantomjs快速入门(了解)
无头浏览器:一个完整的浏览器内核,包括js解析引擎,渲染引擎,请求处理等,但是不包括显示和用户交互页面的浏览器,没有和用户交互的界面。现在使用的已经不多了,但是之前有程序是用Phantomjs开发出来的,了解了之后可以看懂别人的代码,也可以对比学习webdriver。
使用之前要先下载phantomjs.exe。
使用时webdriver.PhantomJS(executable_path=“phantomjs.exe所在的路径”),括号内以关键字传参的形式传入phantomjs.exe所在的绝对路径,也可以直接把绝对路径传进去;如果phantomjs.exe在python文件夹下,与python.exe在同一目录下,就可以不用传入参数,因为在安装python的时候已经把python文件夹添加到了环境变量里,把phantomjs.exe放到python文件夹中相当于添加到环境变量。
from selenium import webdriver
webdriver.PhantomJS()
会出现如下提示:

这个提示并不是报错,因为程序已经运行完成,红色的警告是告诉我们这个PhantomJS已经被弃用,已经过时不再更新,但是代码可以用。
使用webdriver.PhantomJS()访问浏览器,因为没有交互的界面,程序运行后看起来没有反应,运行时间比较慢,我们需耐心等待;我们可以使用自带的截图功能,对访问的网页进行截取,证明我们来过。
from selenium import webdriver
# 加载驱动
drive = webdriver.PhantomJS()
# 打开网页
drive.get('https://www.baidu.com/') # 使用驱动打开百度,程序运行时看起来没有效果
drive.save_screenshot('baidu.png') # 我们对访问的网页进行截屏,保存为baidu.png
截屏的图片为下图所示,通过图片我们可以看到,确实是打开过网页的,下面我们可以试着对打开的网页再进行操作。

再回到百度网页,我们点一下输入框,把光标定位到输入框后就可以输入内容。如果通过程序往里输入内容,首先也要先找到输入框,在输入框点右键,检查,可以看到光标定位到"input"的标签。可以通过"class",“name”,“id"属性获取输入框,输入内容后要点击“百度一下”按钮,在“百度一下”处点击鼠标右键,检查,它同样是一个"input"标签,我们同样可以通过它的"class”,"id"属性进行操作。

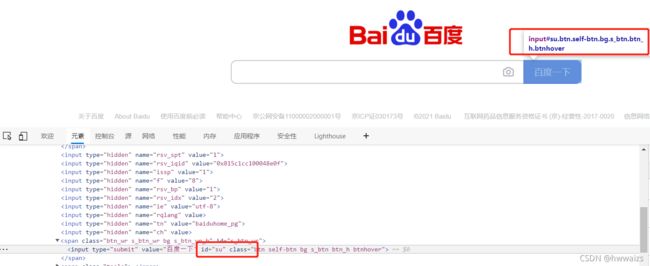
由于程序运行运行相对于打开网页的速度还是比较快的,我们可以用time模块,把时间暂停一下,便于截图看到效果。
from selenium import webdriver
import time
# 加载驱动
drive = webdriver.PhantomJS()
# 打开网页
drive.get('https://www.baidu.com/') # 使用驱动打开百度
# 定位输入框
ipt_tag = drive.find_element_by_id('kw') # 通过id值定位到输入框
# 输入内容
ipt_tag.send_keys('python') # 在输入框中输入内容
# 上面两行代码等价于drive.find_element_by_id('kw').send_keys('python')
time.sleep(1)
# 点击百度一下
# 定位按钮
btn_tag = drive.find_element_by_id('su')
# 点击按钮
btn_tag.click()
time.sleep(2)
# 截图
drive.save_screenshot('baidu.png') # 我们对访问的网页进行截屏,保存为baidu.png
运行的效果如下图所示:

看到的网页内容可能跟自己直接开的稍微有一点点区别,这就涉及到网页的刷新和优化,数据相差不是很多。
chromedriver
chromedriver是一个驱动Chrome浏览器的驱动程序,使用它才可以驱动浏览器。当然针对不同的浏览器有不同的driver。以下列出了不同浏览器及其对应的driver:
Chrome:https://sites.google.com/a/chromium.org/chromedriver/downloads
Firefox:https://github.com/mozilla/geckodriver/releases
Edge:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Safari:https://webkit.org/blog/6900/webdriver-support-in-safari-10/
下载chromedriver
百度搜索:淘宝镜像(https://npm.taobao.org/)
安装总结:https://www.jianshu.com/p/a383e8970135
安装Selenium:pip install selenium
新的chromedriver 第地址 http://chromedriver.storage.googleapis.com/index.html
我用的是edge浏览器,点击浏览器右上角三个点–>点击帮助和反馈–>点击关于Microsoft Edge,看版本号 92.0.902.84,到https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/找92.0.902.xxx就可,找到之后点击–>选择合适的系统下载,然后解压。
下载完msedgedriver之后,要添加到环境变量里,跟phantomjs.exe一样,传入所在路径或者直接放到python文件夹下。把msedgedriver.exe放在python文件夹下,与python.exe在同一目录下因为在安装python的时候已经把python文件夹添加到了环境变量里,把msedgedriver.exe放到python文件夹中相当于添加到环境变量。
在这说一个很坑的事儿,我放到环境变量里,出现下面报错提示需要添加路径,然后我放到浏览器所在的相应位置还是不行,一直在出错。
![]()
最后的解决方法是,把msedgedriver.exe 改为它一直提示的MicrosoftWebDriver.exe,相当于把文件换了个名字,居然成功运行了。
下面对基本用法进行一下讲解,用驱动打开浏览器,并自动关闭浏览器。
打开了之后可以看到在地址栏下方会有提示“Microsoft Edge正在受到自动测试软件的控制”,这句提示用户和百度都能看到,说明selenium 并不能百分之百解决反爬问题,可以解决90%以上的问题吧。
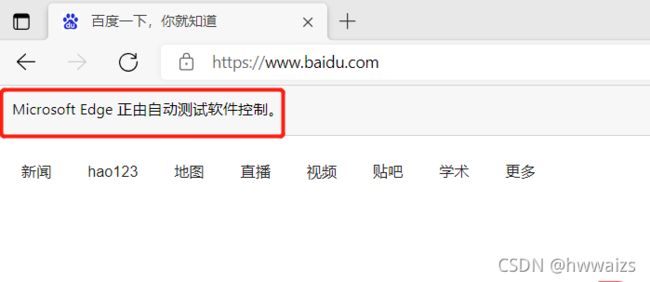
from selenium import webdriver
import time
# 加载驱动
driver = webdriver.Edge()
# 在当前浏览器打开网页
driver.get('https://www.baidu.com/')
time.sleep(2)
# 关闭当前窗口
driver.close()
time.sleep(2)
# 退出驱动
driver.quit()
close关闭的当前网页,如果驱动没有关闭,还可以去操作其他网页,quit关闭的是驱动,关闭所有网页
selenium快速入门(掌握)
定位元素
find_element_by_id:根据id来查找某个元素
find_element_by_class_name:根据类名查找元素
find_element_by_name:根据name属性的值来查找元素
find_element_by_tag_name:根据标签名来查找元素,不常用,重复的标签太多
find_element_by_xpath:根据xpath语法来获取元素,标签没有属性,也不好用标签名来定位的时候用
通过刚才的Phantomjs的例子进行操作。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 加载驱动
driver = webdriver.Edge()
# 在当前浏览器打开网页
driver.get('https://www.baidu.com/')
time.sleep(1)
# 定位元素
# 1. 通过id定位
driver.find_element_by_id('kw').send_keys('python') # 方法一,by
# 利用By来进行访问
ipt_tag = driver.find_element(By.ID, 'kw') # 方法二,By
ipt_tag.send_keys('python')
# 2. 通过类名class定位
driver.find_element_by_class_name('s_ipt').send_keys('python1')
# 利用By来进行访问
driver.find_element(By.CLASS_NAME, 's_ipt').send_keys('python1')
# 3. 通过name定位
ipt_tag = driver.find_element_by_name('wd')
ipt_tag.send_keys('python2')
# 利用By来进行访问
ipt_tag = driver.find_element(By.NAME, 'wd')
ipt_tag.send_keys('python2')
# 4. 通过标签名来定位
ipt_tag = driver.find_element_by_tag_name('head')
print(ipt_tag) # 不常用,因为会有很多重复的标签,没法进行精准定位
ipt_tags = driver.find_elements_by_tag_name('input') # 用elements,在列表中返回多个内容
print(ipt_tags) # 会把符合标签名的所有内容都返回出来,放在了列表中,可以遍历取出
ipt_tag = driver.find_element(By.TAG_NAME, 'head')
# 5. 通过xpath来定位
ipt_tag = driver.find_element_by_xpath('//*[@id="kw"]')
ipt_tag.send_keys('python3')
ipt_tag.find_element(By.XPATH, '//*[@id="kw"]').send_keys('python3')
要注意,find_element是获取第一个满足条件的元素。find_elements是获取所有满足条件的元素
操作表单元素
操作输入框:分为两步。
第一步:找到这个元素。
第二步:使用send_keys(value),将数据填充进去
如果在“百度一下”的input输入框内,用send_keys(value)输入内容,不会进行输入内容的操作。如果在其他div等其他没有input的标签里传入send_keys(value),则会报错。
使用clear方法可以清除输入框中的内容
操作按钮
操作按钮有很多种方式。比如单击、右击、双击等。这里讲一个最常用的。就是点击。直接调用click函数就可以了
from selenium import webdriver
import time
driver = webdriver.Edge()
driver.get('https://www.baidu.com/')
time.sleep(2)
# ipt_tag = driver.find_element_by_id('su')
# ipt_tag.send_keys('python') # 打开网页后没有任何操作
# div_tag = driver.find_element_by_id('head wrapper')
# div_tag.send_keys('python') # 会报错,因为没有input属性
ipt_tag = driver.find_element_by_id('kw') # 定位到输入框
ipt_tag.send_keys('爬虫') # 在输入框里输入内容
time.sleep(2) # 时间停留2秒
btn_tag = driver.find_element_by_id('su') #定位到“百度一下”
btn_tag.click() # 点击“百度一下”
time.sleep(2) # 时间停留2秒
ipt_tag.clear() # 把输入框的内容清空
time.sleep(2) # 时间停留2秒
driver.close() # 关闭 窗口
time.sleep(2) # 时间停留2秒
driver.quit() # 关闭 驱动器