Mysql - 数据库集群方案
数据库集群能解决什么问题?
单节点和集群哪个读写更快?
- 低并发情况下,单节点 MySQL 读写速度快
- 高并发情况下,MySQL 集群的读写速度更快
- 大量并发如果集中在一个 MySQL 节点上,先不说内存撑不撑得住,磁盘 IO 都撑不住。
- 数据库集群的思路:
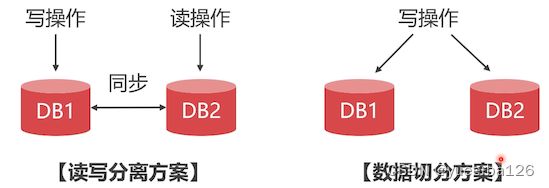
- 读写分离方案
- 数据切分方案
单节点数据库的弊病
- 大型互联网程序用户群庞大,所以架构必须要特殊设计,比如:
- 微信注册用户超 10 亿
- 新浪微博用户超 3.3 亿
- 今日头条用户超 2.4 亿
- 单节点的数据库无法满足性能上的要求:单节点链接数量最大 16000 多,大量用户情况下,根本就应付不过来
- 单节点的数据库没有冗余设计,无法满足高可用:一个节点挂了,这个业务也就瘫痪了。
- 高并发下的数据库压力:2016 年除夕,微信共收发红包 142 亿 个,比上一年增长 75.7%,最高峰值每秒收发红包 76 万 个,支付峰值 20.8 万 次每秒,创下世界纪录。
常见 MySQL 集群方案
-
PXC :同步传输,适合保存少量高价值数据
-
Replication:异步传输,适合保存大量数据
PXC 与 Replication 方案对比
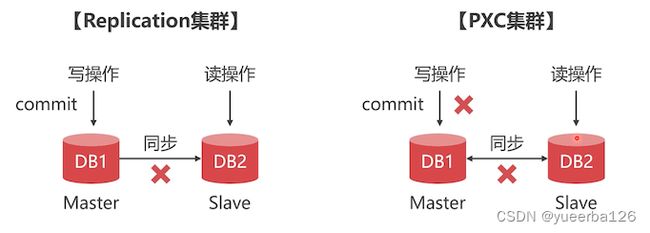
- PXC 方案:事务是同步的
- 执行一个事务,只有当数据同步到 slave 成功后,事务才能提交成功。
- Replication:事务是异步的
- 在 master 上提交成功了,但是异步同步失败了,在 slave 中就无法查询到数据
- 他们不是竞争关系,而是互补关系
如何使用 Docker 虚拟机
Docker 与 vm 虚拟机对比
- Docker 是免费的虚拟机引擎,可以为任何应用创建一个轻量级的可移植的容器
- 总的来说,Docker 在批量集群方面,就是快、方便


可以不安装虚拟机吗?
- Docker 是跨平台的轻量级虚拟机,Win10 和 MacOS 都可以安装 Docker,但是我们需要用到虚拟 IP,这个只有 Linux 才支持。所以还是安装虚拟机吧。

云计算中的 Docker 虚拟机
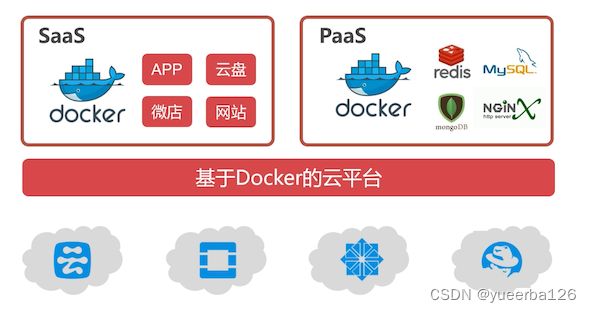
- 因为Docker 是轻量级的虚拟机,一台服务器可以跑几百上千个虚拟的实例,所以有很多厂商就出售这些实例,这就是 云计算的虚拟云主机 ;云又分为:
- Saas
- 为客户提供完整的云端产品(如进销存、财务系统等),用户购买云主机时,挑选需要哪些产品,运营商就立即给你构建这套软件系统,对很多非技术性的中小企业是很有帮助的:不需要自己搭建环境,也不需要找人开发
- PaaS
- 为客户提供服务,客户自己把这些服务整合成产品;
- 比如事先把 redis、mysql、MongoDB 等部署到虚拟的实例上,再开发一套管理系统,如果客户需要使用云端数据库服务,那么就卖给你数据库服务
- PaaS 云适合中小型的技术企业,通过购买运营商提供的基础服务,完成自己的云端引用程序的开发
- 无论是哪一种云,都需要用到 Docker 虚拟机
- Saas
Docker 镜像
- Docker 虚拟机的镜像是一个只读层,不能写入数据。
- 我们可以通过 dockerfile 文件,定义需要安装的程序(如 MySQL),然后创建出镜像文件。
- 在 Docker 仓库中已经存在了一些别人已经制作好的镜像,比如 java 环境。
- 由于镜像是只读的,想要存储一些数据,就需要创建容器。
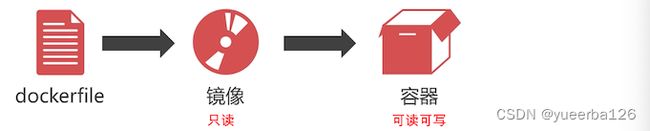
Docker 容器
- Docker 容器是一个 虚拟机的实例,里面的内容可读可写。且容器是 完全隔离 的,我们不用担心部署程序会相互干扰。一个镜像可以创建出多个容器。
安装 Docker 虚拟机
- 首先我们需要多搞几台 vm 的虚拟机出来,这些 vm 虚拟机的硬件配置可以稍微提高一点,因为一台 linux 服务器里面可以跑很多个 docker 虚拟机;
- 在 CentOS 上安装 Docker 虚拟机
yum install -y docker service docker start service docker stop
Docker 虚拟机管理命令
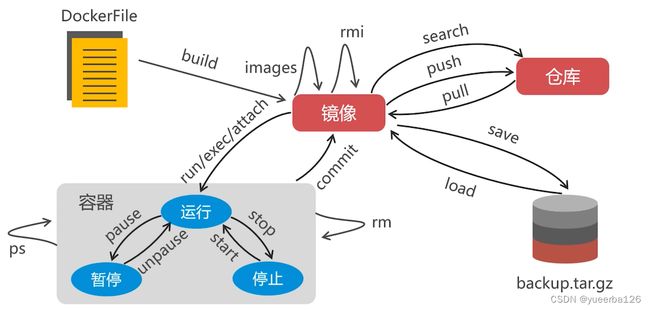
- build:从 DockerFile 构建一个镜像
- search:搜索 Docker 仓库有哪些可用的镜像
- 如果不想自己 build 镜像,就可以查看有哪些别人制作好的
- pull:从远程把镜像,下载到本地
- push:将我们自己创建的镜像发布到仓库
- images:查看本地存放了哪些镜像
- rmi:删除一个镜像
- 前提是,把与该镜像关联的容器都删除
- save:将本地的镜像导出成压缩文件
- load:将压缩文件导入到本地的 Docker 虚拟机
- run:创建容器,创建后就是运行状态的
- 访问容器:可执行 exec/attach 命令
- pause/unpause:暂停或则恢复容器
- stop/start:停止容器或启动容器
- ps:查看 docker 中有多少个容器
- rm:删除容器
- commit:将容器转换成镜像
设置镜像加速器
- Docker 仓库在海外,访问很慢,设置为国内的镜像仓库,加快下载速度;这里使用 dockerCloud 加速器
- 笔者这里使用 dockerCloud 还是有超时现象,这里配置下阿里云的,先进入容器镜像服务;侧边栏有一个镜像中心,找到镜像加速器;会给你一个专属的镜像加速器地址,上面文件中的地址替换掉这个,重启 docker 就可以了
[root@study ~]# curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io
docker version >= 1.12
{"registry-mirrors": ["http://f1361db2.m.daocloud.io"],}
Success.
You need to restart docker to take effect: sudo systemctl restart docker
- 看见上面输出,多了一个逗号,需要手动编辑去掉这个逗号
vim /etc/docker/daemon.json
# 修改为下面这样,就是去掉了后面多余的逗号
{"registry-mirrors": ["http://f1361db2.m.daocloud.io"]}
演示
- 下载一个 java 镜像,创建出一个容器,部署 java 程序
# 搜索远程仓库有哪些可用的 java 镜像
[root@study ~]# docker search java
INDEX NAME DESCRIPTION STARS OFFICIAL AUTOMATED
docker.io docker.io/node Node.js is a JavaScript-based platform for... 8925 [OK]
docker.io docker.io/tomcat Apache Tomcat is an open source implementa... 2751 [OK]
docker.io docker.io/openjdk OpenJDK is an open-source implementation o... 2289 [OK]
# 上面看到了一个 openjdk
# 下载该镜像
[root@study ~]# docker pull docker.io/openjdk
Using default tag: latest
Trying to pull repository docker.io/library/openjdk ...
latest: Pulling from docker.io/library/openjdk
fa926a7d213a: Pull complete
22aed8993d2f: Pull complete
6f92a6635435: Pull complete
Digest: sha256:c56c42fb84c21ebeea1c715f323b78f4160872ac6c28c32292d9cd1d29982aaf
Status: Downloaded newer image for docker.io/openjdk:latest
# 查看 docker 环境里是否有下载下来的镜像
[root@study ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/openjdk latest 4fba8120f640 3 days ago 497 MB
# 创建容器
# -it: 进入容器
# bash:进入容器使用哪一个命令行
[root@study ~]# docker run -it docker.io/openjdk bash
bash-4.2# # 可以看到就进入到容器中来了
# 可以看下当前是哪一个的 java 版本
bash-4.2# java --version
openjdk 14.0.1 2020-04-14
OpenJDK Runtime Environment (build 14.0.1+7)
OpenJDK 64-Bit Server VM (build 14.0.1+7, mixed mode, sharing)
# 部署程序到这个容器中,需要做一个目录映射,才能把文件传到容器中
# 退出容器,在容器中执行 exit
# 查看有哪些容器
[root@study ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
838eefc8ff2c docker.io/openjdk "bash" 3 minutes ago Exited (0) 12 seconds ago adoring_meitner
# 可以看到,刚刚我们退出的容器,status 的确是 exited 了
# 删掉该容器,给的是容器ID
[root@study ~]# docker rm 838eefc8ff2c
# 创建一个有目录容器的映射
# 使用 -v 参数,有两个目录,左边的是宿主机的目录,右边的映射到容器中的目录
# 映射目录,需要该目录先存着,记得先创建它
# 1. 创建并进入该容器
[root@study ~]# docker run -it -v /root/java:/root/java docker.io/openjdk bash
# 2. 在 宿主机的 /root/java 目录下创建一个 Hello.java 文件
# 文件内容就如下一个简单的打印
class Hello{
public static void main(String[] args){
System.out.println("Hello World");
}
}
# 3. 在容器中进入该目录
# 发现提示权限不足,这里还是要听老师的,需要先把 SELinux 关闭; 关闭后需要重新启动机器
bash-4.2# ls /root/java/
ls: cannot open directory /root/java/: Permission denied
# 处理完 SELinux 后,就发现能看到了
bash-4.2# ls /root/java/
Hello.java
bash-4.2# cd /root/java
bash-4.2# javac Hello.java
bash-4.2# java Hello
Hello World
镜像的导入与导出
- 某些电脑无法下载镜像(没有外网)或则下载速度很慢,可以将镜像导出成压缩文件,再导入
# 导出
docker save -o /root/openjdk.tar.gz docker.io/openjdk
# 导入
docker load < /root/openjdk.tar.gz
- 这里测试的话,把本地的 openjdk 镜像删除,前提是 要把用该镜像创建出来的容器删除掉
[root@study ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3f3d27fa951c docker.io/openjdk "bash" 21 hours ago Exited (255) 2 minutes ago trusting_northcutt
# 删除容器
[root@study ~]# docker rm 3f3d27fa951c
3f3d27fa951c
[root@study ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/openjdk latest 4fba8120f640 4 days ago 497 MB
# 删除镜像
[root@study ~]# docker rmi 4fba8120f640
Untagged: docker.io/openjdk:latest
Untagged: docker.io/openjdk@sha256:c56c42fb84c21ebeea1c715f323b78f4160872ac6c28c32292d9cd1d29982aaf
Deleted: sha256:4fba8120f640877c7aedf93c1c862df74ee2d971786a402289099e6c08798598
Deleted: sha256:072f3a083c65224baab5ff73b3913057778d467df1860f67434ef5fbe874e05b
Deleted: sha256:21a066a950d33c4609707b20ac5a7fd4cf71b8526f0f43723b86f306469686bf
Deleted: sha256:351f02e4b003402356cd1295ec4619446767783e503cd455f39a80015538ed7e
- 最后导入刚刚导出的
[root@study ~]# docker load < /root/openjdk.tar.gz
351f02e4b003: Loading layer [==================================================>] 126.2 MB/126.2 MB
41f691265dc2: Loading layer [==================================================>] 42.66 MB/42.66 MB
e0b0ff63abdd: Loading layer [==================================================>] 335.3 MB/335.3 MB
Loaded image: docker.io/openjdk:latest
- 修改镜像名称,看命令 tag 就知道只是增加了一个标签而已, imageID 还是一样的
[root@study ~]# docker tag docker.io/openjdk openjdk
[root@study ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
openjdk latest 4fba8120f640 4 days ago 497 MB
docker.io/openjdk latest 4fba8120f640 4 days ago 497 MB
创建容器命令
- 创建容器时,可以 映射端口和 挂载目录
# --name 给容器启动一个名称,名称可有可无,因为会有容器 id
# 进入容器后,默认运行的是 bash 程序
docker run -it --name java openjdk bash
# -p 做了端口映射,左侧是宿主机端口 : 右侧容器端口
# 可以写多个端口映射
docker run -it --name java -p 9000:8080 -p 9001:8085 openjdk bash
# -v 挂载目录
# --privileged: 容器要读写目录里面的数据,需要分配最高的权限
docker run -it --name java -v /root/project:/sorf --privileged openjdk bash
容器的启动/退出/暂停/恢复
# 创建容器,并以交互模式进入 bash 程序
[root@study ~]# docker run -it docker.io/openjdk bash
bash-4.2# exit # 退出容器,那么容器也停止运行了
exit
[root@study ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
65f855abe6dd docker.io/openjdk "bash" 11 seconds ago Exited (0) 4 seconds ago peaceful_spence
# 让容器再次运行
# -i:是否以交互模式运行,如果不加 -i,那么容器会在后头模式运行
[root@study ~]# docker start -i 65f855abe6dd
bash-4.2# exit
exit
# 后台模式运行
[root@study ~]# docker start 65f855abe6dd
65f855abe6dd
[root@study ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
65f855abe6dd docker.io/openjdk "bash" 4 minutes ago Up 5 seconds peaceful_spence
# 让容器暂停
[root@study ~]# docker pause 65f855abe6dd
65f855abe6dd
[root@study ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
65f855abe6dd docker.io/openjdk "bash" 5 minutes ago Up About a minute (Paused) peaceful_spence
# 可以看到状态变成 pause 了
# 恢复容器的运行
[root@study ~]# docker unpause 65f855abe6dd
65f855abe6dd
[root@study ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
65f855abe6dd docker.io/openjdk "bash" 6 minutes ago Up 2 minutes peaceful_spence
# 停止容器的运行
[root@study ~]# docker stop 65f855abe6dd
分布式 Docker 环境
集中部署的缺点
- 把数据库集群都部署在一个 Docker 上不是一个好办法,如果宿主机宕机了,那么每个 MySQL 节点都不能使用了

分布式部署
- 分布式部署,首先要解决的就是虚拟机组网的问题,Docker Swarm 技术可以 自动把异地的 Docker 虚拟机组成一个局域网
创建多个 VM 实例
- 比如创建 4 个实例,然后使用 Swarm 把这 4 台组成一个区域网
- 可以利用现有的虚拟机,克隆出来,在这之前,我们先删除之前的存在的容器实例后再克隆。
- 笔者使用的是 Oracle VM VirtualBox,克隆很简单了:
- 修改你要复制新的虚拟机名称
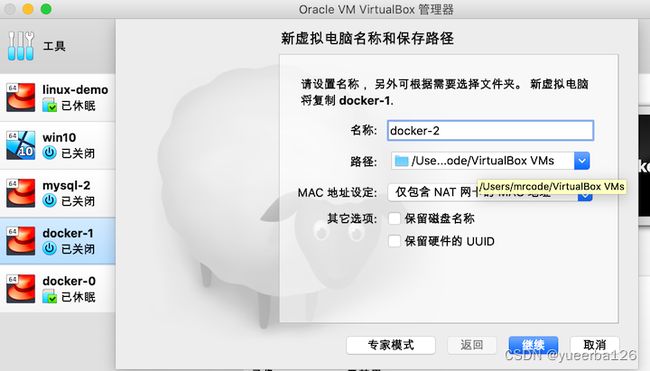

- 等待 2 分钟左右就可以使用了,唯一需要修改就是: 复制后的虚拟机启动后,网络 IP 被设置为了自动模式,需要手动修改成手动模式
创建 Swarm 集群
- 很简单,在某一个 docker 节点上执行 docker swarm init 命令,swarm 集群就创建出来了,并且当前的 docker 节点会自动加入到 swarm 集群,成为集群的管理节点
[root@study ~]# docker swarm init
Error response from daemon: could not choose an IP address to advertise since this system has multiple addresses on different interfaces (10.0.2.105 on enp0s3 and 192.168.56.105 on enp0s8) - specify one with --advertise-addr
# 由于笔者 mac 虚拟机上为了链接外网,使用了两张网卡的方式,这里需要指定网卡
# 这里我选择 enp0s8 这张网卡
[root@study ~]# docker swarm init --advertise-addr enp0s8
Swarm initialized: current node (dsm2a0zz66ckrrc9wkw7437lw) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-1hwraveloheai9kbgrh2r7kwonxze24275ckpa5uxhxt905gbm-ec30fb3zbn4zho8e839bnfbeg \
192.168.56.105:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
-
swarm 集群创建成功,告诉我们当前 105 节点是管理节点,要将其他 docker 虚拟机加入到这个 swarm 集群中,只需要在每台要加入的 docker 虚拟机上,运行那一串 join 指令就可以了;
-
注意的是:还需要放开 2377 这个端口
firewall-cmd --zone=public --add-port=2377/tcp --permanent
firewall-cmd --reload
- 在其他机器上执行加入命令
[root@study ~]# docker swarm join --token SWMTKN-1-1hwraveloheai9kbgrh2r7kwonxze24275ckpa5uxhxt905gbm-ec30fb3zbn4zho8e839bnfbeg 192.168.56.105:2377
This node joined a swarm as a worker.
- 在管理 Swarm 集群的时候,很多命令需要在管理节点上执行,在 worker 节点上执行不支持。
查看 Swarm 集群节点
docker node ls # 查看集群节点
# 删除集群节点,
# -f 是删除 AVAILABILITY 为 active 的节点;表示这台 docker 虚拟机正则运行中
docker node rm -f 节点ID
# 查看集群中有哪些节点
[root@study ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
1468rakoih5r6v6m1gwnn5ap7 study.centos.mrcode Ready Active
dsm2a0zz66ckrrc9wkw7437lw * study.centos.mrcode Ready Active Leader
tcq2sz5ey96yzdzheh5botfg1 study.centos.mrcode Ready Active
- 笔者只创建了三台,删除最后一个节点
# 删除集群节点
[root@study ~]# docker node rm -f tcq2sz5ey96yzdzheh5botfg1
tcq2sz5ey96yzdzheh5botfg1
# 注意:这里删除后,在对应的主机上需要使用 docker swarm leave 指令,让我们脱离之前的集群节点
# 脱离之后才算真正离开了这个集群节点
# 所以:被管理节点移除之后的 docker 虚拟机想要重新加入 swarm 集群,也是需要先离开之前的集群
- 现在要解散 Swarm 节点,需要先删除所有的 work 节点。最后再删除管理节点
# 确认 swarm 集群只剩下管理节点了
[root@study ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
dsm2a0zz66ckrrc9wkw7437lw * study.centos.mrcode Ready Active Leader
# 管理节点不能删除自己,需要离开整个集群节点
[root@study ~]# docker swarm leave -f
Node left the swarm.
查看 Swarm 集群网络
- 前面说到,Swarm 集群会创建虚拟网络完成组网。
[root@study ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
3a2808fe483f bridge bridge local
b5e6c79365f6 docker_gwbridge bridge local
f0d3258b232e host host local
i1g496sh0l2l ingress overlay swarm
6292e2b9fa41 none null local
- 其中 SCOPE 为 swarm 的就是 swarm 创建出来的虚拟网络。该网络我们手动也可以创建
创建共享网络
docker network create -d overlay --attachable swarm_test集群名称
[root@study ~]# docker network create -d overlay --attachable swarm_test
zipwmke4qboj258qxdfpgwqy9
[root@study ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
3a2808fe483f bridge bridge local
b5e6c79365f6 docker_gwbridge bridge local
f0d3258b232e host host local
i1g496sh0l2l ingress overlay swarm
6292e2b9fa41 none null local
zipwmke4qboj swarm_test overlay swarm # 创建出来了
-
虚拟网络的意义:由于每一个 docker 虚拟机上都可以运行成千上万的容器,如果 swarm 集群中的所有容器都运行在同一个网络中,ip 就不够分配的。
-
所以可以创建多个不同的虚拟网络,把容器划分到不同的虚拟网络中。比如,需要搭建 mysql 集群,可以把这些 mysql 容器划分到这一个虚拟网络中
删除虚拟网络
docker network rm 网络名称
[root@study ~]# docker network rm swarm_test
swarm_test
创建分布式容器
- 如何在 swarm 集群中创建分布式容器,我们正常创建的容器还只是本地的容器,并没有加入到虚拟网络中。
docker run -it --net=swarm_test...
-
如上的语法,创建容器时,使用 --net 参数,将容器加入到指定的虚拟网络中;
-
后续讲解 MySQL 集群的时候,再做详细的讲解
搭建 PXC 集群
- PXC 中一般保存高价值的数据,所以很重要
PXC 集群介绍
- Percona XtraDB Cluster 是业界主流的 MySQL 集群方案,在性能上甚至可以比肩 MySQL 企业版。
- 最关键的一个特性:PCX 集群的 数据同步具有强一致性的特点。只支持 InnoDB 引擎
- 连阿里数据库 oceanbase 开发都借鉴了 PXC 的原理。
- 本课程不是深入讲解 PXC 集群的,该讲师有另外一门课程叫《MySQL 数据库集群-PXC 方案》,是专门讲解 PXC 集群的。
- 本章只是讲解怎么把 PXC 集群搭建起来
数据库运行在 Docker 中问题
- 数据库运行在 Docker 里有性能问题吗?
- MySQL 放在容器中运行不会有性能损耗,Docker 虚拟机是轻量级的,没有虚拟硬件,也没有安装操作系统,直接使用宿主机的 linux 内核。
- 数据保存到容器中,如果容器崩溃,如何提取数据?
- 因为容器是可读写的,所以数据可以存放在容器中。宿主机无法访问容器内部的文件,无法从崩溃的容器中吧数据提取出来。
- 但是可以给容器做 目录映射,或则 挂载数据卷
开启防火墙端口
- 在搭建 swarm 集群时,开启了 2377 端口还需要开启,7946 和 4789 端口,他们是 swarm 集群通信的端口,并且还要开放 TPC 和 UDP 协议。
# 管理节点上开启 2377,
# 可以在 swarm 集群中设置多个管理节点,所以下面的端口开放在集群节点上都操作一下
firewall-cmd --zone=public --add-port=2377/tcp --permanent
firewall-cmd --zone=public --add-port=7946/tcp --permanent
firewall-cmd --zone=public --add-port=7946/udp --permanent
firewall-cmd --zone=public --add-port=4789/tcp --permanent
firewall-cmd --zone=public --add-port=4789/udp --permanent
firewall-cmd --reload
注意:修改端口之后,需要重新启动 docker 服务,才会生效
systemctl restart docker
下载 PXC 镜像
- 该镜像中包含了 Percona 数据库,所以不用单独安装数据库了
# 下载下来之后,重命名为 pxc 然后删除原来长名称的
# 下载最新版的 PXC 镜像
docker pull percona/percona-xtradb-cluster
docker tag percona/percona-xtradb-cluster pxc
docker rmi percona/percona-xtradb-cluster
-
该镜像是 percona 官方的一个镜像,详细说明 请阅读镜像说明
-
需要在三个节点上都下载 PXC 镜像
PXC 的主节点容器
第一个启动的 PXC 节点是主节点(临时的),它要初始化 PXC 集群,PXC 启动之后,就没有主节点角色了。
集群中 每一个节点的地位都是相同的,任何节点都可以读写数据
创建主节点容器
- 创建主节点之后,需要等待一会儿,才能连接,它要去做一些初始工作
# -d:不进入交互界面
# -p:端口映射
docker run -d -p 9001:3306
-e MYSQL_ROOT_PASSWORD=123456 # 数据库 root 密码
-e CLUSTEER_NAME=PXC1
-e XTRABACKUP_PASSWORD=123456 # pxc 集群之间数据同步的密码
-v pnv1:/var/lib/mysql --privileged # 数据卷的挂载
--name=pn1 # 给当前容器起名,可以自己随意定义
--net=swarm_mysql # 加入虚拟网络名称
pxc # 容器从哪一个镜像上创建
-
数据卷简单理解:一个虚拟的磁盘,把它挂载到了 /var/lib/mysql 这个目录上
-
下面是实际操作命令,记得需要在三台机器上
[root@study ~]# docker run -d -p 9001:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTEER_NAME=PXC1 -e XTRABACKUP_PASSWORD=123456 -v pnv1:/var/lib/mysql --privileged --name=pn1 --net=swarm_mysql pxc
d86cb7982cbcca2c74e1cd17f5783452caa80f141081b13f570aa55a10040930
- 稍等一会,就可以通过 Navicat 之类的工具连接这台机器的 9001 端口,连接上数据库了
创建从节点容器
- 必须等待主节点可以访问了,才能创建从节点,否则会闪退
# -d:不进入交互界面
# -p:端口映射
docker run -d -p 9001:3306
-e MYSQL_ROOT_PASSWORD=123456 # 数据库 root 密码
-e CLUSTEER_NAME=PXC1
-e XTRABACKUP_PASSWORD=123456 # pxc 集群之间数据同步的密码
-e CLUSTER_JOIN=pn1 # 连接到 pn1 节点
-v pnv2:/var/lib/mysql --privileged # 数据卷的挂载
--name=pn2 # 给当前容器起名,可以自己随意定义
--net=swarm_mysql # 加入虚拟网络名称
pxc # 容器从哪一个镜像上创建
- 参数上和主节点的创建类似。以此类推,把其他剩余的节点加入到 pn1 节点中
[root@study ~]# docker run -d -p 9001:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTEER_NAME=PXC1 -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=pn1 -v pnv2:/var/lib/mysql --privileged --name=pn2 --net=swarm_mysql pxc
-
创建从节点后,可以用 Navicat 去连接下它,检查是否可以连接上;
-
测试 pxc 集群是否生效:前面说过,在 pxc 集群中的所有节点都是对等的,在任意一个节点上创建一个数据库,然后去其他节点查看是否真的能看到
管理 Docker 数据卷
✍什么是数据卷?
-
数据卷相当于 给容器挂载一个虚拟的磁盘,该虚拟机磁盘是 可以在宿主机中访问的,即便容器挂掉了,数据还存在
-
什么不挂载目录?目录不能挂载到多个容器上,但是数据卷可以。而且 PXC 容器只支持挂载数据卷
✍管理数据常用指令
# 数据卷列表
docker volume ls
# 创建数据卷
docker volume create test
# 删除数据卷,如果挂载了容器,则不能删除;先删除容器,再删除数据卷
docker volume rm test
# 清除没有挂载的数据卷
docker volume prune
# 查看数据卷详情
docker volume inspect pnv1
-
创建容器时,如果指定的数据卷没有创建,则会帮我们创建好,再挂载到容器上。
-
下面来看看我们 pxc 集群节点上的数据卷
[root@study ~]# docker volume ls
DRIVER VOLUME NAME
local af0abed08ee3a142ff11f37fb57af53739c3590f45edde4024a987496691e82b
local pnv1
[root@study ~]# docker volume inspect pnv1
[
{
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/pnv1/_data",
"Name": "pnv1",
"Options": {},
"Scope": "local"
}
]
# 然后进入到这个目录
[root@study _data]# cd /var/lib/docker/volumes/pnv1/_data
[root@study _data]# ls
auto.cnf client-cert.pem demo gvwstate.dat ib_logfile0 innobackup.backup.log private_key.pem server-key.pem version_info
ca-key.pem client-key.pem galera.cache ib_buffer_pool ib_logfile1 mysql public_key.pem sst_in_progress xb_doublewrite
ca.pem d86cb7982cbc.pid grastate.dat ibdata1 ibtmp1 performance_schema server-cert.pem sys
# 可以看到存放着数据库的文件,那个 demo 目录,就是我测试 pxc 集群的时候创建的一个逻辑库
PXC 集群注意事项
- 集群搭建起来了,会遇到一些使用上的问题,比如关闭电脑之后,下次再启动 PXC 节点,这些容器就会闪退。
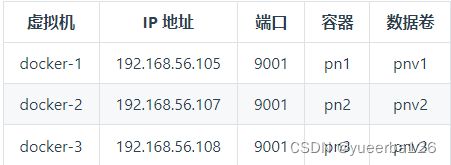
✍PXC 集群结构
- 笔者因为内存不太够用了,只搭建了 3 台虚拟机,视频中是 4 台哈。
✍从节点启动后闪退 1
-
如果主节点没有完全启动成功,从节点就会闪退;
-
这种情况下,只要等待主节点启动成功,使用 Navicat 链接,可以访问的话,就可以了
✍从节点启动后闪退 2
-
这种情况就比较复杂了。先记住这一个结论:PXC 最后退出的节点要最先启动,而且要按照主节点启动
-
PXC 认为最后退出的节点的 数据是最新的,所以需要最先启动,然后启动其他的节点,就会自动的同步数据
-
它的实现大概是:给最后退出的节点打了一个标记,启动时检查这个标记,如果自己没有这个标记,就会 闪退
-
比如下面由 A 、B 两个节点组成的 PXC 集群,先启动的 A 节点,再让 B 节点加入的 A 节点
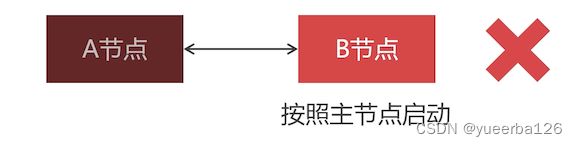
-
模拟故障:A 节点先退出,然后 B 节点也挂掉了。再次启动 B 节点时会闪退,原因是:Docker 不能更换容器启动命令,所以 B 节点无法按照主节点启动
-
解决办法 1: 修改最后退出节点标识到 A 节点上,就不用修改容器启动命令了
-
修改数据卷中的 grastate.dat 文件
# 把该参数修改为 0
safe_to_bootstrap = 0
-
safe_to_bootstrap = 1 代表该节点是最后退出的节点,需要按照主节点启动;但是现在 B 节点无法按照主节点来启动,就把 B 节点修改为 0,A 节点修改为 1,先启动 A 容器,再启动 B 容器
-
解决办法 2: 重新创建容器
- 删除 A、B 容器
- 先启动的容器把原来 B 节点的数据卷挂载上来
- 后启动的容器加入 B 节点的集群,挂载原来 A 节点的数据卷
✍主节点启动后闪退 1
-
要明白的是:PXC 启动之后,所有节点的 ``safe_to_bootstrap` 都是 0;
-
如果所有 PXC 节点同时意外关闭(如停电),所有节点 safe_to_bootstrap 都是 0,所以主节点无法启动
✍主节点启动后闪退 2
-
如果 PXC 集群正在运行,宕机的主节点不能按照主节点启动;
-
解决办法:
- 删除容器,检查 safe_to_bootstrap 是否为 0,如果不为 0 则修改为 0
- 以从节点方式创建容器,加入集群(从存活中的任意节点选一个加入就可以)
✍创建从节点加入 PXC 集群的注意事项
-
因为 PXC 集群的中 每一个节点地位都是平等的,可以使用任何 PXC 节点,然后从节点加入 PXC 集群。

-
比如:创建容器时 A 节点为主节点,B 节点以从节点加入的集群,C 节点可以链接 B 节点进入集群。
-
注意的是: 如果重新启动 C 节点,就必须保证 B 节点可以访问
搭建 PXC 集群分片
-
前面搭建了一个 PXC 集群,由于有多个 MySQL 节点,挂掉其中一个,PXC 集群还是可以使用的,而且多个 MySQL 节点处理读写请求比单节点好很多很多。
-
但是这还不够,下面来了解下
✍PXC 集群的特点
- PXC 节点之间,数据同步是双向的,而且是强一致性的。
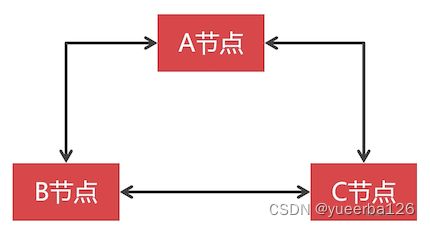
-
比如,三个节点,每个节点都可以写入数据,也都可以读取数据。
-
那么得出一个结论:PXC 集群中的节点不能太多,否则会 影响节点数据写入速度(因为是强一致性同步的),
-
一般不要超过 15 个节点
✍数据同步带来的问题
-
无论在哪个节点写入数据,最终所有节点的数据都是相同的。
-
那么这就失去了数据切分的特性,有 2000 万数据,不能分散存储到某一个节点上。
-
为了 实现数据切分的效果,我们必须新组建一个 PXC 集群,每个 PXC 集群上存储一部分数据

-
这样一来,再在前面增加一层例如 MyCat 之类的数据分片软件,将不同的数据路由到不同的 PXC 集群中去
-
专业术语: 以这个方案来实现的话,上图中的每一个 PXC 集群都是一个分片。
-
需要注意的是: 并不是无休止的增加数据分片,而是可以考虑将数据做冷热分离,将长期不使用的数据归档。如何搭建 TokuDB 归档数据库,可以去转该老师的 PXC 集群专讲课程
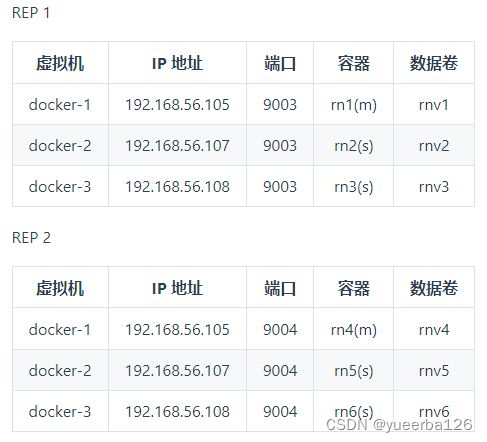
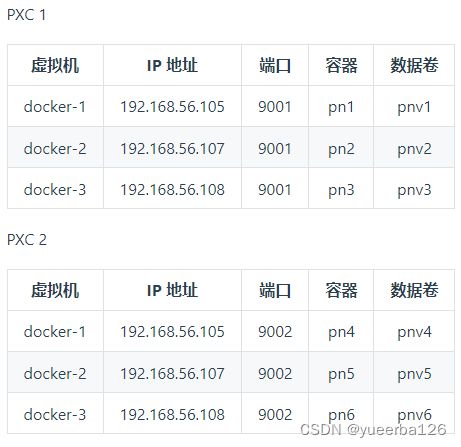
✍PXC 集群结构
- 本机资源有限,搭建两个 PXC 集群,用来主键集分片,分配如下
搭建 Replication 集群
-
PXC 集群适合存放高价值的数据,那么大量低价值的数据就不适合保存在 PCX 集群中;
-
如用户评价信息。
-
Replication 集群是 MySQL 自带的数据同步机制。简单讲解下它的同步原理:
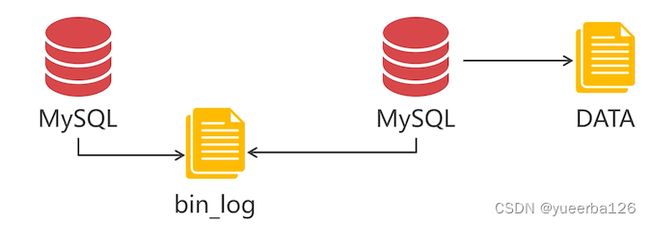
-
第一个 MySQL 开启 bin_log 日志
-
所有使用 MySQL 的操作,都会被记录在该文件中
-
第二个 MySQL 读取第一个 MySQL 的 bin_log 日志
-
就知道第一个 MySQL 执行了哪些操作,并且把这些操作在本地也执行一遍
-
这里可以看出来,数据同步是 单向 的,而 PXC 集群是双向的
主从同步关系
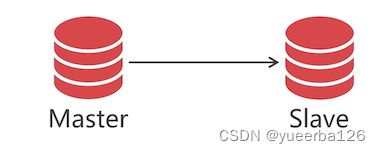
-
Replication 集群中,数据同步是单向的,从主节点(Master)同步到从节点(Slave);
-
如果你的场景是读多写少的,就可以给 master 配置多个 Slave 节点,查询数据的操作都走 Slave,写操作走 Master,就可以实现读写分离的功能。
下载安装 Replication 镜像
-
Oracle 并没有提供官方的 Replication 镜像,所以只能安装第三方封装的镜像文件。
-
Replication 就是 MySQL server,通过配置文件 my.cnf 配置主从的,这里说使用第三方的,应该是封装之后,使用起来更简单?
# 下载镜像后,修改它的名称,把名称修改短一点
docker pull mishamx/mysql
docker tag mishamx/mysql rep
docker rmi mishamx/mysql
Replication 集群的结构
-
为了实现数据分片,Replication 也是要进行数据分片的。所以先来搭建一个 Replication 集群,成功的话,再去搭建第二个。
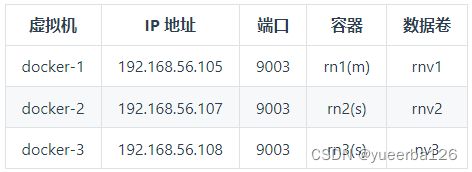
-
rn1作为 master 节点,其余两个作为 Slave 节点。
创建主节点容器
-
主节点用来让其他节点与之同步,而且主节点身份是固定的。
-
使用镜像命令参数,该镜像是封装了 MySQL 官方的 Replication 配置,一定要知道 Replication 最原始的搭建方式。
docker run -d -p 9003:3306 --name rn1
-e MYSQL_MASTER_PORT=3306
-e MYSQL_ROOT_PASSWORD=123456 # 设置数据库 ROOT 账户密码
-e MYSQL_REPLICATION_USER=backup # 创建一个新的 mysql 账户,仅用来做数据同步
-e MYSQL_REPLICATION_PASSWORD=123456 # 设置分配一个密码
-V rnv1:/var/lib/mysql --privileged # 数据卷
--net=swarm_mysql rep
- 下面来实操
[root@study /]# docker run -d -p 9003:3306 --name rn1 -e MYSQL_MASTER_PORT=3306 -e MYSQL_ROOT_PASSWORD=123456 -e MYSQL_REPLICATION_USER=backup -e MYSQL_REPLICATION_PASSWORD=123456 -v rnv1:/var/lib/mysql --privileged --net=swarm_mysql rep
7d9d59aed2af2d766f5413c70530ed6b294601dcb1c4cc3aeab51ca92fac3a7f
- 等一会初始后,通过 Navicat 去连接 9300 端口,看是否能够链接上这个数据库
创建从节点容器
从节点需要与主节点同步数据,没有主节点不能创建从节点,要保证主节点已经创建成功,再来创建从节点
docker run -d -p 9003:3306 --name rn2
-e MySQL_MASTER_HOST=rn1 #### 增加了这一行配置,指向了主节点容器名称
-e MYSQL_MASTER_PORT=3306
-e MYSQL_ROOT_PASSWORD=123456 # 设置数据库 ROOT 账户密码
-e MYSQL_REPLICATION_USER=backup # 创建一个新的 mysql 账户,仅用来做数据同步
-e MYSQL_REPLICATION_PASSWORD=123456 # 设置分配一个密码
-V rnv2:/var/lib/mysql --privileged # 数据卷
--net=swarm_mysql rep
- 从节点创建与主节点类似,只是多了配置主节点的参数。下面只记录了一台机器的从节点创建,需要把你规划的剩余机器也创建上
[root@study ~]# docker run -d -p 9003:3306 --name rn2 -e MYSQL_MASTER_HOST=rn1 -e MYSQL_MASTER_PORT=3306 -e MYSQL_ROOT_PASSWORD=123456 -e MYSQL_REPLICATION_USER=backup -e MYSQL_REPLICATION_PASSWORD=123456 -v rnv2:/var/lib/mysql --privileged --net=swarm_mysql rep
c6f61a470d2b786bbaeb77ab540dc3454e2cbec2f9c39627ccc07280e92f3679
Replication 集群的注意事项
-
这里讨论下 Replication 的使用,是否也会向 PXC 集群那样,关闭之后,再启动会闪退呢?
-
主节点关闭,从节点会发生什么?
-
主节点关闭,从节点依然可以使用,但是 主从同步机制失效
-
不启动主节点,从节点能启动吗?
-
不启动主节点,从节点也能启动,主从同步失效
-
搭建 Replication 集群分片
-
现在可以规划下搭建第二个 Replication 集群了。
-
强一致性与弱一致性:
-
PXC 是强一致性集群
-
Replication 是弱一致性集群
-
这里有一个免费课程,以项目演示为例,讲解 PXC 集群原理、PXC 数据同步与 Replication 同步的区别、PXC 的多节点并发写入、Docker 虚拟机部署 MySQL 集群,并以案例验证 Replication 方案的数据不一致性、PXC 方案数据一致性,等知识点。有兴趣可以去看看
-
数据切分与 PXC 集群一样,搭建两个集群分片,规划如下