Kubernetes 和 Kubeflow 学习笔记
Kubernetes
Kubernetes是一个完备的分布式系统支撑平台,具有完备的集群管理能力,多扩多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和发现机制、內建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制以及多粒度的资源配额管理能力。
Kubernetes优势:
- 原生的资源隔离
- 集群化自动化管理
- 计算资源(CPU/GPU)自动调度
- 对多种分布式存储的支持
- 集成较为成熟的监控和告警
Kubernetes的组件
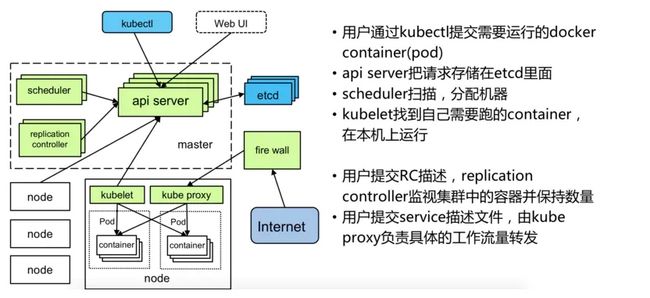

- master 可以简单的理解为控制中心
- etcd:分布式k-v数据库,根据配置选择是cp还是ap, k8s只有api server 和etcd通讯, 其他组件均和api server通讯。
- api server:可以理解为etcd的前置过滤器,换一个视角,它和etcd类似于mysql和文件系统。
- controller manager: 核心,负责将现在的状态调整为etcd上应该的状态,包含了所有的实现逻辑。
- scheduler: 简单点说就是给一个pod找一个node。
- slave 可以简单的理解为worker
- kubelet: 负责和master连接,注册node, listen-watch 本node的任务等。
- kube-proxy: 用于k8s service对象。
- 容器运行时: 除了docker,k8s还支持rkt等容器实现。
k8s集群的运行时的大致结构
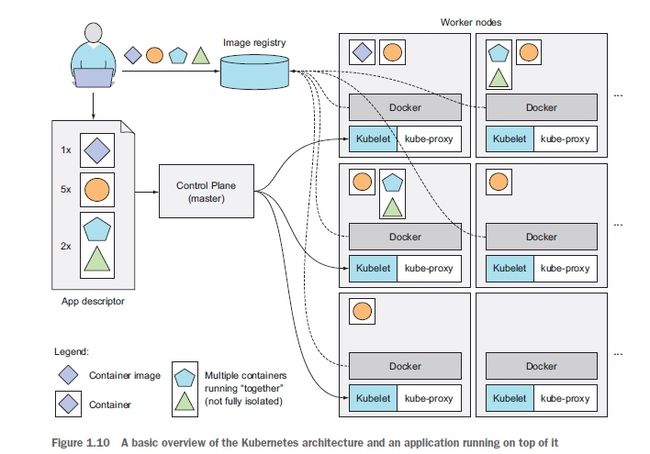
Kubernetes 资源架构图

Kubeflow
Kubeflow简介
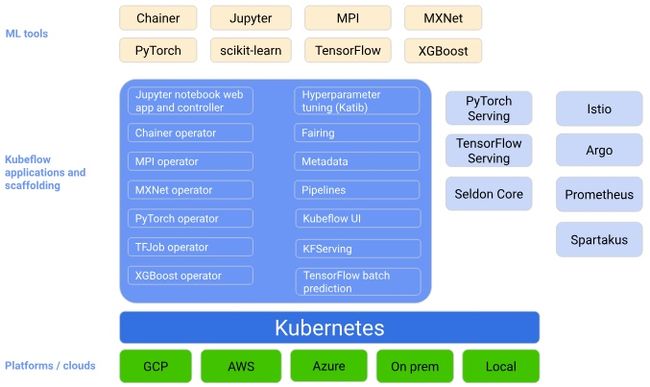
Kubeflow是Kubernetes的机器学习工具包。Kubeflow是运行在K8S之上的一套技术栈,这套技术栈包含了很多组件,组件之间的关系比较松散,我们可以配合起来用,也可以单独用其中的一部分。下图是官网显示Kubeflow作为在Kubernetes上安排ML系统组件的平台:
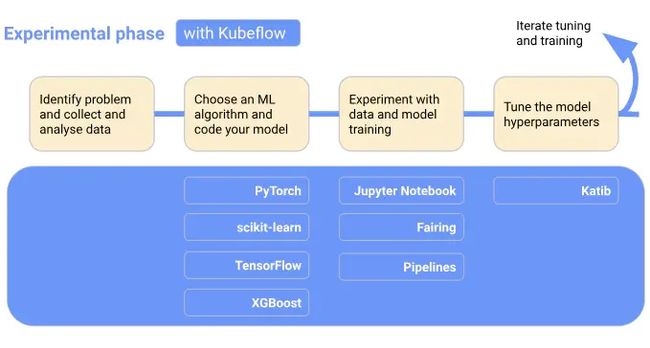
当我们开发和部署ML系统时,ML工作流程通常包括几个阶段。开发ML系统是一个反复的过程。我们需要评估ML工作流各个阶段的输出,并在必要时对模型和参数进行更改,以确保模型不断产生所需的结果。
为了便于理解,下图按顺序显示了工作流程阶段,并将Kubeflow添加到工作流中,显示在每个阶段都有哪些Kubeflow组件有用。工作流末尾的箭头指向流程,以表示流程的迭代性质:
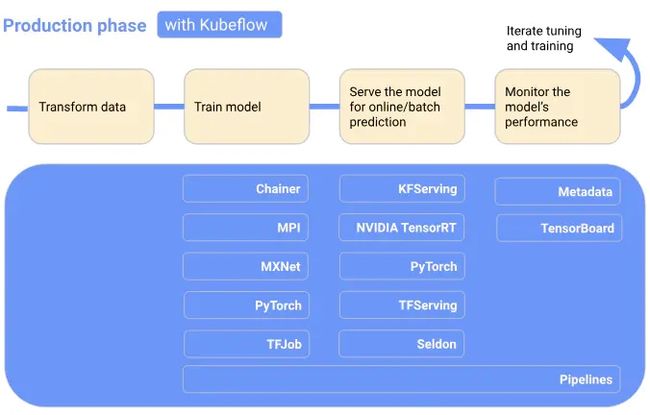
kubeflow特点
- 支持 tensorflow/torch/keras等等主流深度学习库
- 用户界面友好
- 支持分布式训练
- 支持 GPU 训练
- 支持快速产生人工智能产品原型
由此可以看出,Kubeflow的目标是基于K8S,构建一整套统一的机器学习平台,覆盖最主要的机器学习流程(数据->特征->建模->服务->监控),同时兼顾机器学习的实验探索阶段和正式的生产环境。
Kubeflow组件
Kubeflow的主要组件
- Central Dashboard:Kubeflow的dashboard看板页面
- Metadata:用于跟踪各数据集、作业与模型
- Jupyter Notebooks:一个交互式业务IDE编码环境
- Frameworks for Training:支持的ML框架
- Chainer
- MPI
- MXNet
- PyTorch
- TensorFlow
- Hyperparameter Tuning:Katib,超参数服务器
- Pipelines:一个ML的工作流组件,用于定义复杂的ML工作流
- Tools for Serving:提供在Kubernetes上对机器学习模型的部署
- KFServing
- Seldon Core Serving
- TensorFlow Serving(TFJob):提供对Tensorflow模型的在线部署,支持版本控制及无需停止线上服务、切换模型等
- NVIDIA Triton Inference Server(Triton以前叫TensorRT)
- TensorFlow Batch Prediction
- Multi-Tenancy in Kubeflow:Kubeflow中的多租户
- Fairing:一个将code打包构建image的组件,Kubeflow中大多数组件的实现都是通过定义CRD来工作。
- Operator是针对不同的机器学习框架提供资源调度和分布式训练的能力(TF-Operator,PyTorch-Operator,Caffe2-Operator,MPI-Operator,MXNet-Operator)。
- Pipelines是一个基于Argo实现了面向机器学习场景的流水线项目,提供机器学习流程的创建、编排调度和管理,还提供了一个Web UI。
- Katib是基于各个Operator实现的超参数搜索和简单的模型结构搜索的系统,支持并行搜索和分布式训练等。超参优化在实际的工作中还没有被大规模的应用,所以这部分的技术还需要一些时间来成熟。
- Serving支持部署各个框架训练好的模型的服务化部署和离线预测。Kubeflow提供基于TFServing,KFServing,Seldon等好几种方案。由于机器学习框架很多,算法模型也各种各样。工业界一直缺少一种能真正统一的部署框架和方案。这方面Kubeflow也仅仅是把常见的都集成了进来,但是并没有做更多的抽象和统一。
Jupyter Notebooks
Kubeflow将default-editor ServiceAccount分配给Jupyter notebook Pod。该服务帐户绑定到kubeflow-edit ClusterRole,它对许多Kubernetes资源具有命名空间范围的权限,其中包括:
- Pod
- Deployment
- Service
- Job
- TFJob
- PyTorchJob
因此,可以直接从Kubeflow中的Jupyter notebook创建上述Kubernetes资源。 notebook中已预装了Kubernetes kubectl命令行工具,可以说也是非常简单了。
将Jupyter notebook绑定在Kubeflow中时,可以使用Fairing库使用TFJob提交训练作业。训练作业可以运行在单个节点,也可以分布在同一个Kubernetes集群上,但不能在notebook pod内部运行。通过Fairing库提交作业可以使数据科学家清楚地了解Docker容器化和pod分配等流程。
总体而言,Kubeflow-hosted notebooks可以更好地与其他组件集成,同时提供notebook image的可扩展性。
利用Kubeflow,每个用户或团队都将拥有自己的命名空间,在其中轻松运行工作负载。命名空间提供强大的安全保障与资源隔离机制。利用Kubernetes资源配额功能,平台管理员能够轻松限制个人或者团队用户的资源消耗上限,以保证资源调度的公平性。
在Kubeflow部署完成之后,用户可以利用Kubeflow的中央仪表板启动notebook:

Kubeflow的notebook管理UI:用户可以在这里查看并接入现有notebook,或者启动一个新的notebook。
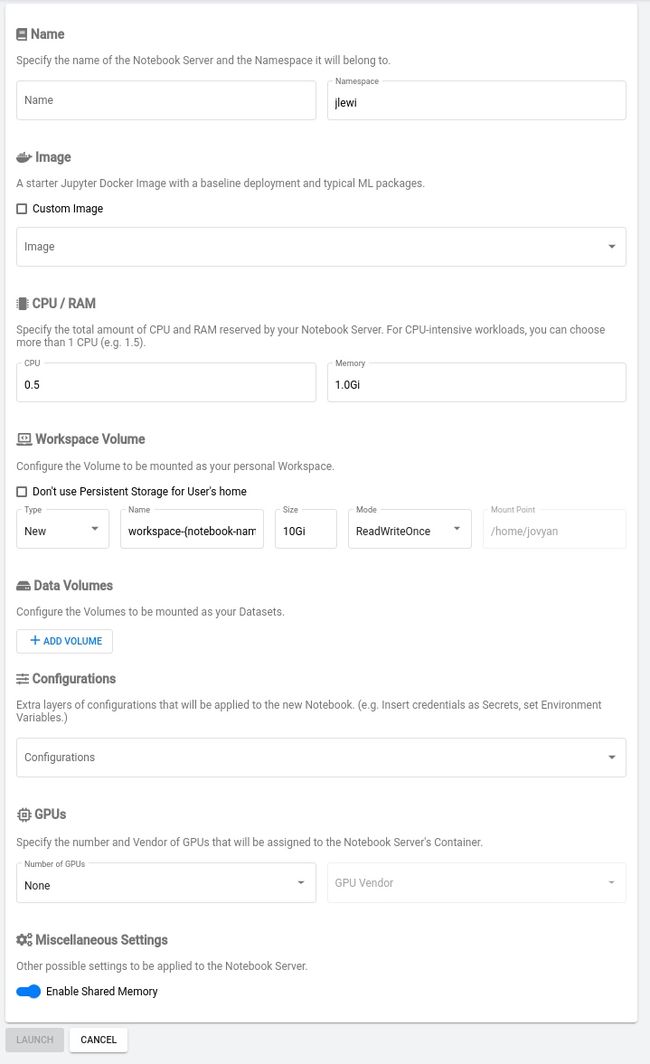
在Kubeflow UI中,用户可以通过选择Jupyter预设的Docker镜像、或者导入自定义镜像的URL来轻松启动新的notebook。接下来,用户需要设置对接该notebook的CPU与GPU数量,并在notebook中添加配置与密码参数以简化对外部库及数据库的访问。
Pipelines
Kubeflow的目的主要是为了简化在Kubernetes上运行机器学习任务的流程,最终希望能够实现一套完整可用的流水线, 来实现机器学习从数据到模型的一整套端到端的过程。 而pipeline是一个工作流平台,能够编译部署机器学习的工作流。
kubeflow/pipelines实现了一个工作流模型。所谓工作流,或者称之为流水线(pipeline),可以将其当做一个有向无环图(DAG)。其中的每一个节点被称作组件(component)。组件处理真正的逻辑,比如预处理,数据清洗,模型训练等。每一个组件负责的功能不同,但有一个共同点,即组件都是以Docker镜像的方式被打包,以容器的方式被运行的。
下图显示了Kubeflow Pipelines UI中管道的运行时执行图:
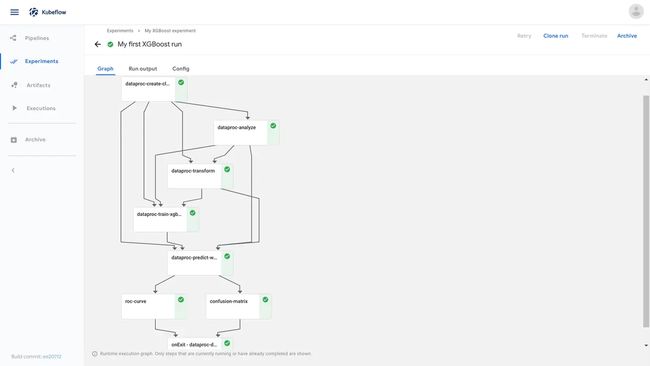
实验(experiment)是一个工作空间,在其中可以针对流水线尝试不同的配置。用户在执行的过程中可以看到每一步的输出文件,以及日志。步(step)是组件的一次运行,输出工件(step output artifacts)是在组件的一次运行结束后输出的,能被系统的前端理解并渲染可视化的文件。
Pipelines架构图
下图是官方提供的Kubeflow Pipelines架构图:
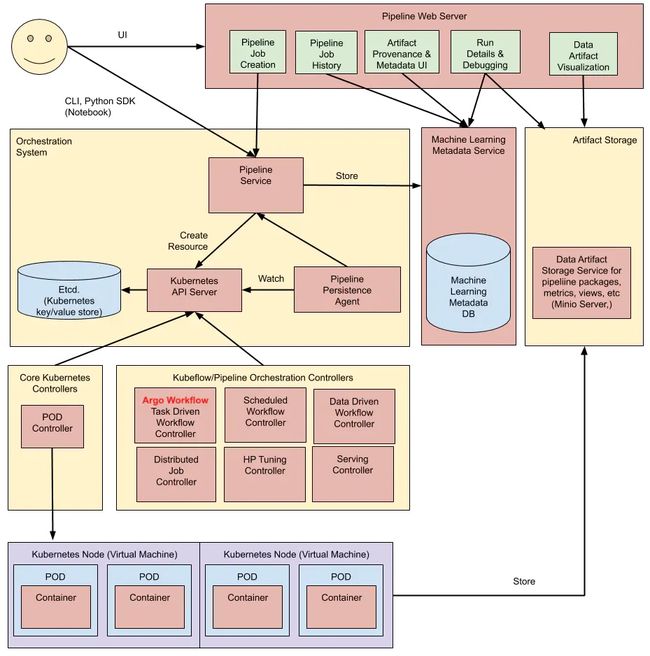
整体可以将pipeline主要划分为八部分:
- Python SDK: 用于创建kubeflow pipelines组件的特定语言(DSL)。
- DSL compiler: 将Python代码转换成YAML静态配置文件(DSL编译器 )。
- Pipeline Web Server: pipeline的前端服务,它收集各种数据以显示相关视图:当前正在运行的pipeline列表,pipeline执行的历史记录,有关各个pipeline运行的调试信息和执行状态等。
- Pipeline Service: pipeline的后端服务,调用K8S服务从YAML创建 pipeline运行。
- Kubernetes Resources: 创建CRDs运行 pipeline。
- Machine Learning Metadata Service: 用于监视由Pipeline Service创建的Kubernetes资源,并将这些资源的状态持久化在ML元数据服务中(存储任务流容器之间的input/output数据交互)。
- Artifact Storage: 用于存储Metadata和Artifact。Kubeflow Pipelines将元数据存储在MySQL数据库中,将Artifact存储在Minio服务器或Cloud Storage等工件存储中。
- Orchestration Controllers:任务编排,比如 Argo Workflow控制器,它可以协调任务驱动的工作流。
Pipelines工作原理
流水线的定义可以分为两步,首先是定义组件,组件可以从镜像开始完全自定义。这里介绍一下自定义的方式:首先需要打包一个Docker镜像,这个镜像是组件的依赖,每一个组件的运行,就是一个Docker容器。其次需要为其定义一个python函数,描述组件的输入输出等信息,这一定义是为了能够让流水线理解组件在流水线中的结构,有几个输入节点,几个输出节点等。接下来组件的使用就与普通的组件并无二致了。实现流水线的第二步,就是根据定义好的组件组成流水线,在流水线中,由输入输出关系会确定图上的边以及方向。在定义好流水线后,可以通过 python中实现好的流水线客户端提交到系统中运行。
虽然kubeflow/pipelines的使用略显复杂,但它的实现其实并不麻烦。整个的架构可以分为五个部分,分别是ScheduledWorkflow CRD以及其operator流水线前端,流水线后端,Python SDK和persistence agent。
- ScheduledWorkflow CRD扩展了argoproj/argo的Workflow定义。这也是流水线项目中的核心部分,它负责真正地在Kubernetes上按照拓扑序创建出对应的容器完成流水线的逻辑。
- Python SDK负责构造出流水线,并且根据流水线构造出 ScheduledWorkflow的YAML定义,随后将其作为参数传递给流水线系统的后端服务。
- 后端服务依赖关系存储数据库(如MySQL)和对象存储(如S3),处理所有流水线中的CRUD请求。
- 前端负责可视化整个流水线的过程,以及获取日志,发起新的运行等。
- Persistence agent负责把数据从Kubernetes Master的etcd中sync到后端服务的关系型数据库中,其实现的方式与CRD operator类似,通过informer来监听 Kubernetes apiserver对应资源实现。
Pipelines提供机器学习流程的创建、编排调度和管理,还提供了一个Web UI。这部分主要基于Argo Workflow。
Fairing
Kubeflow Fairing是一个Python软件包,可轻松在Kubeflow上训练和部署ML模型。Fairing还可以扩展为在其他平台上进行训练或部署。目前,Fairing已扩展为可在Google AI Platform上进行训练。
Fairing简化了在混合云环境中构建,训练和部署机器学习(ML)训练job的过程。通过使用Fairing并添加几行代码,可以直接从Jupyter notebook在本地或在云中使用Python代码运行ML训练作业。训练工作完成后,可以使用Fairing将训练后的模型部署为预测端点。
Katib
Katib结构
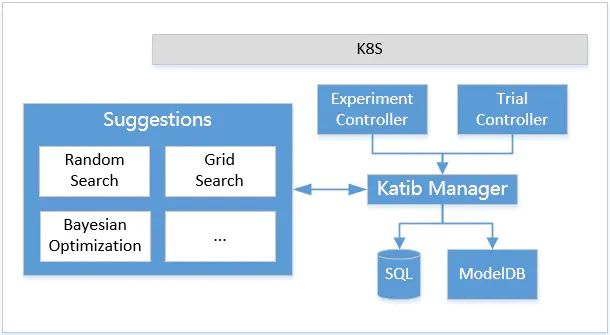
- Experiment Controller:提供对Experiment CRD的生命周期管理。
- Trial Controller:提供对Trial CRD的生命周期管理。
- Suggestions:以Deployment的方式部署,用Service方式暴露服务,提供超参数搜索服务。目前有随机搜索,网格搜索,贝叶斯优化等。
- Katib Manager:一个GRPC server,提供了对Katib DB的操作接口,同时充当Suggestion与 Experiment之间的代理。
- Katib DB:数据库。其中会存储Trial和Experiment,以及Trial的训练指标。目前默认的数据库为 MySQL。
Katib工作原理
当一个Experiment被创建的时候,Experiment Controller会先通过Katib Manager在Katib DB中创建一个Experiment对象,并且打上Finalizer表明这一对象使用了外部资源(数据库)。随后,Experiment Controller会根据自身的状态和关于并行的定义,通过Katib Manager提供的GRPC接口,让Manager通过 Suggestion提供的GRPC接口获取超参数取值,然后再转发给Experiment Controller。在这个过程中,Katib Manager是一个代理的角色,它代理了Experiment Controller对Suggestion的请求。拿到超参数取值后,Experiment Controller会根据Trial Template和超参数的取值,构造出Trial的定义,然后在集群中创建它。
Trial被创建后,与Experiment Controller的行为类似,Trial Controller同样会通过Katib Manager在Katib DB中创建一个Trial对象。随后会构造出期望的Job(如batchv1 Job,TFJob,PyTorchJob等)和Metrics Collector Job,然后在集群上创建出来。这些Job运行结束后,Trial Controller会更新Trial的状态,进而Experiment Controller会更新Experiment的状态。
然后Experiment会继续下一轮的迭代。之前的Trial已经被训练完成,而且训练的指标已经被收集起来了。Experiment会根据配置,判断是否要再创建新的Trial,如果需要则再重复之前的流程。
Katib竞品对比分析图
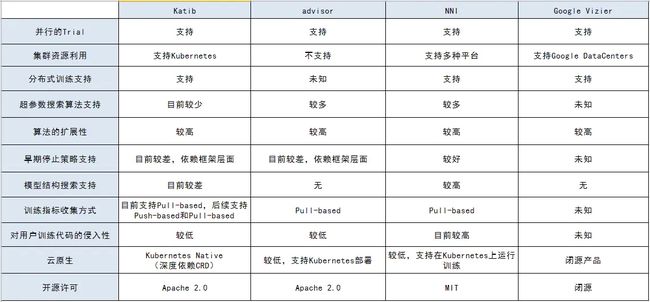
超参优化是一种AutoML的方法。KubeFlow把Katib集成进来作为超参优化的一种方案。
KFServing
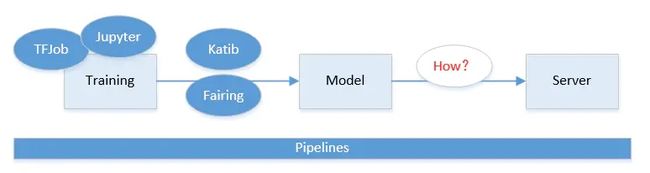
KubeFlow组件中可以看到,它提供基于TF Serving,KFServing,Seldon Core Serving等好几种方案。由于机器学习框架很多,算法模型也各种各样。工业界一直缺少一种能真正统一的部署框架和方案。这方面KubeFlow也仅仅是把常见的都集成了进来,但是并没有做更多的抽象和统一。
Kubeflow提供两个支持多框架的模型服务工具:KFServing和Seldon Core Serving。或者,可以使用独立的模型服务系统,以便可以选择最能满足模型服务要求的框架。
对于TensorFlow模型,可以使用TensorFlow Serving将TFJob导出的模型进行实时预测。但是,如果打算使用多个框架,则应考虑如上所述使用KFServing或Seldon Core Serving。KFServing是Kubeflow项目生态系统的一部分,Seldon Core Serving是Kubeflow支持的外部项目。
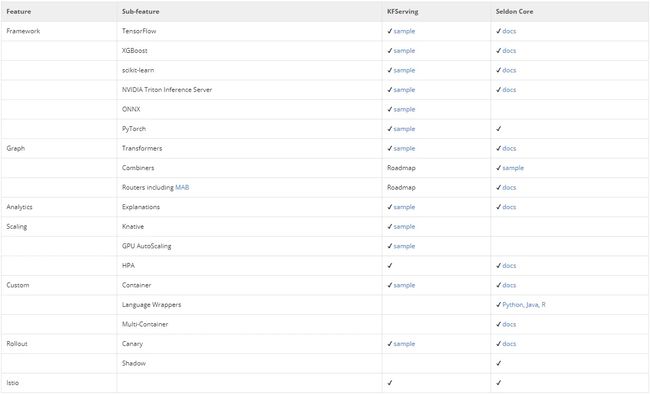
KFServing提供了Kubernetes CRD,用于在任意框架上服务机器学习(ML)模型。它旨在通过为常见ML框架(Tensorflow,XGBoost,ScikitLearn,PyTorch和ONNX等)提供高性能,高抽象的接口来解决模型服务用例。
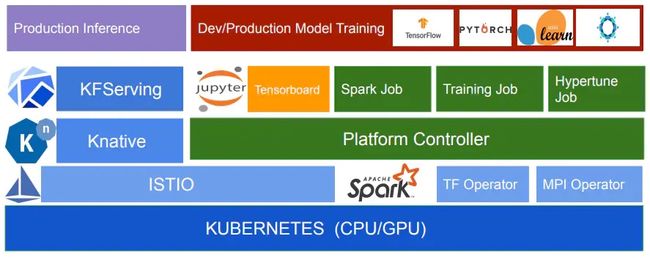
NVIDIA Triton Inference Server是一项REST和GRPC服务,用于对TensorRT,TensorFlow,Pytorch,ONNX和Caffe2模型进行深度学习推理。该服务器经过优化,可以在GPU和CPU上大规模部署机器学习算法。Triton推理服务器以前称为TensorRT推理服务器。
我们可以将NVIDIA Triton Inference Server用作独立系统,但如上所述,更应该考虑使用KFServing。KFServing也包括对NVIDIA Triton Inference Server的支持。
现在国外的Google、微软、亚马逊、Intel以及国内的阿里云、华为云、小米云、京东云、才云等等公司都在发力Kubeflow,并结合kubernetes对多种机器学习引擎进行多机多卡的大规模训练,这样可以做到对GPU资源的整合,并高效的提高GPU资源利用率,及模型训练的效率。并实现一站式服务,将机器学习服务上线的整个workflow都在Kubernetes平台实现。减轻机器学习算法同学的其它学习成本,专心搞算法。
分布式训练加快训练速度
分布式训练已经成为谷歌内部的基本规范,同时也是TensorFlow与PyTorch等深度学习框架当中最激动人心也最具吸引力的能力之一。
谷歌当初之所以要打造Kubeflow项目,一大核心诉求就是充分利用Kubernetes以简化分布式训练流程。借助Kubernetes的自定义资源,Kubeflow得以显著降低TensorFlow与PyTorch上的分布式训练难度。用户需要首先定义一种TFJob或者PyTorch资源,如下所示。接下来,由定制化控制器负责扩展并管理所有单一进程,并通过配置实现进程之间的通信会话:
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
name: mnist-train
spec:
tfReplicaSpecs:
Chief:
replicas: 1
spec:
containers:
image: gcr.io/alice-dev/fairing-job/mnist
name: tensorflow
Ps:
replicas: 1
template:
spec:
containers:
image: gcr.io/alice-dev/fairing-job/mnist
name: tensorflow
Worker:
replicas: 10
spec:
containers:
image: gcr.io/alice-dev/fairing-job/mnist
name: tensorflow
References
Kubernetes官网
kubeflow官网
掘金