PostgreSQL安装以及和mysql的对比
PostgreSQL 研究安装整理
前言
本期文章中主要说明的内容有:
- PostgreSql的使用有点
- PostgreSql基本查询语法介绍(含测试截图)
- PostgreSql和mysql对比
PostgreSQL 是一个免费的对象-关系数据库服务器(ORDBMS),在灵活的BSD许可证下发行。
PostgreSQL 开发者把它念作 post-gress-Q-L。
PostgreSQL 的 Slogan 是 “世界上最先进的开源关系型数据库”。
PostSQL
- 前言
- 简介
- 安装PostgreSQL
-
- 安装成功但连接失败
- MySQL 与 PostgreSQL 的语法对比(常用语法介绍)
-
- Mysql 与 PostgreSQL 的SQL语法对比
- PostgreSQL动态演示
-
-
- LIMIT和OFFSET
- 第一种
- 第二种
- 总结
-
- PostgreSQL的数据类型
-
-
- 数值数据类型
- 日期/时间数据类型
- 一些其他数据类型
-
- 布尔类型:
- 创建数据库:
- Not
- Between
- 连接:
-
- PostgreSQL 常用函数
- PostgreSQL 模式
-
- 使用模式的优势:
-
- 特别注意:
- MySQL和Postgresql的区别
- 一.PostgreSQL相对于MySQL的优势
- 二、MySQL相对于PG的优势:
- 三、总体上来说
- 本期的文档整理参考部分网上资源和自己实际测试内容,如有不对,多多指教。第一次发表文档记录。
简介
PostgreSQL是一个功能非常强大的、源代码开放的客户/服务器关系型数据库管理系统(RDBMS)。PostgreSQL最初设想于1986年,当时被叫做Berkley Postgres Project。该项目一直到1994年都处于演进和修改中,直到开发人员Andrew Yu和Jolly Chen在Postgres中添加了一个SQL(Structured Query Language,结构化查询语言)翻译程序,该版本叫做Postgres95, 在开放源代码社区发放。
PostgreSQL 的 主要优点如下:
- 维护者是PostgreSQL Global Development Group,首次发布于1989年6月。
- 操作系统支持WINDOWS、Linux、UNIX、MAC OS X、BSD。
- 从基本功能上来看,支持ACID、关联完整性、数据库事务、Unicode多国语言。
- 表和视图方面,PostgreSQL支持临时表,而物化视图,可以使用PL/pgSQL、PL/Perl、PL/Python或其他过程语言的存储过程和触发器模拟。
- 索引方面,全面支持R-/R+tree索引、哈希索引、反向索引、部分索引、Expression 索引、
GiST、GIN(用来加速全文检索),从8.3版本开始支持位图索引。 - 其他对象上,支持数据域,支持存储过程、触发器、函数、外部调用、游标
- 数据表分区方 面,支持4种分区,即范围、哈希、混合、列表。
- 从事务的支持度上看,对事务的支持与MySQL相比,经历了更为彻底的测试。
- My ISAM表处理方式方面,MySQL对于无事务的MyISAM表,采用表锁定,1个长时间运行的查询很可能会阻碍对表的更新,而PostgreSQL不存在这样的问题。
- 从存储过程上看,PostgreSQL支持存储过程。因为存储过程的存在也避免了在网络上大量原 始的SQL语句的传输,这样的优势是显而易见的。
- 用户定义函数的扩展方面,PostgreSQL可以更方便地使用UDF(用户定义函数)进行扩展。PostgreSQL 的 应用劣势如下:
- 最新版本和历史版本不分离存储,导致清理老旧版本时需要做更多的扫描,代价比较大但一般 的数据库都有高峰期,如果合理安排VACUUM,这也不是很大的问题,而且在PostgreSQL9.0中VACUUM进一步被加强了。
- 在PostgreSQL中,由于索引完全没有版本信息,不能实现Coverage index scan,即查询只扫描索引,不能直接从索引中返回所需的属性,还需要访问表,而Oracle与Innodb则可以。
安装PostgreSQL
安装步骤以及操作说明请参考(本文不再):
windows 安装PostgreSQL
安装成功但连接失败
使用navicat连接本地PostgreSQL数据库时报错:
could not connect to server: Connection refused (0x0000274D/10061) Is the server running on host"localhost" (:1) and acceptingTCP/IP connections on port 5433 ?

首先检查一下是不是没有启动PostgreSQL服务,因为没启动服务可能会报这个错误(我就是); 方法如下:

win+R打开输入命令框,输入services.msc打开服务列表。
右键启动

再次尝试连接数据库,看是否成功,如果没成功那就进行以下步骤:
1、在postgresql的安装文件夹\9.5\data\pg_hba.conf里面找到“# IPv4 local connections:”
![]()
然后在这行上面添加“local pgsql all trust”,
在它下面的“host all all 127.0.0.1/32 md5”

下面添加一行,内容为“host all all 192.168.91.1/24 md5”
注:127.0.0.1/32和192.168.91.1/24中的32与24,用32表示该IP被固定,用24表示前3位固定, 后面一位可以由自己设,这样,前3位ip地址与该设定相同的计算机就可以访问postgresql数据库。
2、PostgreSQL\9.5\data\postgresql.conf文件中,找到“#listen_addresses = ‘localhost’”,把它改成“listen_addresses = ‘*’”。这样,postgresql就可以监听所有ip地址的连接。

3、然后重启postgresql服务。如果系统启用了防火墙,请先关闭。如果要使用pgadmin连接远程 的数据库服务器,须在SSL的选项中选择允许。
MySQL 与 PostgreSQL 的语法对比(常用语法介绍)
Mysql 与 PostgreSQL 的SQL语法对比
总结
Mysql 与 PostgreSQL的基本语法相同,只不过PostgreSQL比MySQL多一些语法功能实践(demo)
PostgreSQL动态演示
PostgreSQL两种分页方法查询
LIMIT和OFFSET
LIMIT : 限制取多少条数据。
OFFSET : 跳过多少条数据然后取后续数据。
第一种
SELECT * FROM test_table WHERE i_id>1000 limit 100;
第二种
SELECT * FROM test_table limit 100 OFFSET 1000;
在3000W数据的时候,建议使用第一种.
mysql 的分页就非常简单了
SELECT * FROM test_table limit 100, 10;
mysql里分页一般用limit来实现
1. select* from article LIMIT 1,3
2. select * from article LIMIT 3 OFFSET 1
当limit后面跟两个参数的时候,第一个数表示要跳过的数量,后一位表示要取的数量 上面两种写法都表示取2,3,4三条条数据
总结
mysql 与 postgreSQL的分页最后两个参数正好意思相反
PostgreSQL的数据类型
数值数据类型
| 名称 | 描述 | 存储大小 | 范围 |
|---|---|---|---|
| smallint | 存储整数,小范围 | 2字节 | -32768 至 +32767 |
| integer | 存储整数。使用这个类型可存储典型的整数 | 4字节 | -2147483648 至 +2147483647 |
| bigint | 存储整数,大范围。 | 8字节 | -9223372036854775808 至 9223372036854775807 |
| decimal | 用户指定的精度,精确 | 变量 | 小数点前最多为131072个数字; 小数点后最多为16383个数字。 |
| numeric | 用户指定的精度,精确 | 变量 | 小数点前最多为131072个数字; 小数点后最多为16383个数字。 |
| real | 可变精度,不精确 | 4字节 | 6位数字精度 |
| double | 可变精度,不精确 | 8字节 | 15位数字精度 |
| serial | 自动递增整数 | 4字节 | 1 至 2147483647 |
| bigserial | 大的自动递增整数 | 8字节 | 1 至 9223372036854775807 |
对比Mysql的区别很大,mysql 常用的就tinyint 和 int ,以及bigint
字符串数据类型
String数据类型用于表示字符串类型值。
| 数据类型 | 描述 |
|---|---|
| char(size) | 这里size 是要存储的字符数。固定长度字符串,右边的空格填充到相等大小的字符。 |
| character(size) | 这里size 是要存储的字符数。 固定长度字符串。 右边的空格填充到相等大小的字符。 |
| varchar(size) | 这里size 是要存储的字符数。 可变长度字符串。 |
| character varying(size) | 这里size 是要存储的字符数。 可变长度字符串。 |
| text | 可变长度字符串。 |
比Mysql 拥有更加丰富的字符串类型
日期/时间数据类型
日期/时间数据类型用于表示使用日期和时间值的列。
| 名称 | 描述 | 存储大小 | 最小值 | 最大值 | 解析度 |
|---|---|---|---|---|---|
| timestamp [ § ] [不带时区 ] | 日期和时间(无时区) | 8字节 | 4713 bc | 294276 ad | 1微秒/14 位数 |
| timestamp [ § ]带时区 | 包括日期和时间,带时区 | 8字节 | 4713 bc | 294276 ad | |
| date | 日期(没有时间) | 4字节 | 4713 bc | 5874897 ad |
1微秒/14 位数 |
| time [ § ] [ 不带时区 ] | 时间(无日期) | 8字节 | 00:00:00 | 24:00:00 | 1微秒/14 位数 |
| time [ § ] 带时区 | 仅限时间,带时区 | 12字节 | 00:00:00+1459 | 24:00:00- 1459 |
1微秒/14 位数 |
| interval [ fields ] [ § ] |
时间间隔 | 12字节 | -178000000年 | 178000000 年 |
1微秒/14 位数 |
一些其他数据类型
布尔类型:
| 名称 | 描述 | 存储大小 |
|---|---|---|
| boolean | 它指定true 或false 的状态。 | 1字节 |
货币类型:
| 名称 | 描述 | 存储大小 | 范围 |
|---|---|---|---|
| money | 货币金额 | 8字节 | -92233720368547758.08 至 +92233720368547758.07 |
几何类型:
几何数据类型表示二维空间对象。最根本的类型:点- 形成所有其他类型的基础。
| 名称 | 存储大小 | 表示 | 描述 |
|---|---|---|---|
| point | 16字节 | 在一个平面上的点 | (x,y) |
| line | 32字节 | 无限线(未完全实现) | ((x1,y1),(x2,y2)) |
| lseg | 32字节 | 有限线段 | ((x1,y1),(x2,y2)) |
| box | 32字节 | 矩形框 | ((x1,y1),(x2,y2)) |
| path | 16+16n字节 | 封闭路径(类似于多边形) | ((x1,y1),…) |
| polygon | 40+16n字节 | 多边形(类似于封闭路径) | ((x1,y1),…) |
| circle | 24字节 | 圆 | <(x,y),r> (中心点和半径) |
创建数据库:
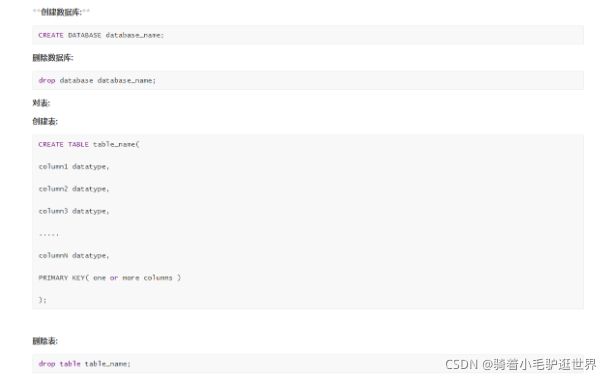

还有 order by / group by / having / and / or / like / in / not in 这些和Mysql 的没啥不同,一样用.
Not
NOT 条件与WHERE子句一起使用以否定查询中的条件。

Between
BETWEEN条件与WHERE子句一起使用,以从两个指定条件之间的表中获取数据。

连接:
内连接(INNER JOIN)

左外连接(LEFT OUTER JOIN)
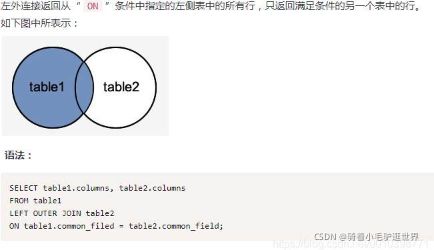
右外连接(RIGHT OUTER JOIN)

全连接(FULL OUTER JOIN)

跨连接(CROSS JOIN)

事务:
BEGIN TRANSACTION :开始事务。
COMMIT :保存更改,或者您可以使用END TRANSACTION 命令。
ROLLBACK :回滚更改。
其实也和mysql 的差不多.语法区别不是很大.
PostgreSQL 常用函数
PostgreSQL 内置函数也称为聚合函数,用于对字符串或数字数据执行处理。下面是所有通用 PostgreSQL 内置函数的列表:
COUNT 函数:用于计算数据库表中的行数。MAX 函数:用于查询某一特定列中最大值。MIN 函数:用于查询某一特定列中最小值。AVG 函数:用于计算某一特定列中平均值。SUM 函数:用于计算数字列所有值的总和。
ARRAY 函数:用于输入值(包括null)添加到数组中。Numeric 函数:完整列出一个 SQL 中所需的操作数的函数。String 函数:完整列出一个 SQL 中所需的操作字符的函数。
总结
与MySQL 的常用函数基本相同
PostgreSQL 模式
ostgreSQL 模式(SCHEMA)可以看着是一个表的集合。
一个模式可以包含视图、索引、数据类型、函数和操作符等。
相同的对象名称可以被用于不同的模式中而不会出现冲突,例如 schema1 和 myschema 都可以包含名为 mytable 的表。
使用模式的优势:
允许多个用户使用一个数据库并且不会互相干扰。
将数据库对象组织成逻辑组以便更容易管理。
第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。
模式类似于操作系统层的目录,但是模式不能嵌套。
特别注意:
在不同模式下使用相同的表时,在查询时需要添加模式的名称以用来进行数据的区分。不添加默认标识查询public下的表数据。
MySQL和Postgresql的区别
一.PostgreSQL相对于MySQL的优势
1、在SQL的标准实现上要比MySQL完善,而且功能实现比较严谨;
2、存储过程的功能支持要比MySQL好,具备本地缓存执行计划的能力;
3、对表连接支持较完整,优化器的功能较完整,支持的索引类型很多,复杂查询能力较强;
4、PG主表采用堆表存放,MySQL采用索引组织表,能够支持比MySQL更大的数据量。
5、PG的主备复制属于物理复制,相对于MySQL基于binlog的逻辑复制,数据的一致性更加可靠,复制 性能更高,对主机性能的影响也更小。
6、MySQL的存储引擎插件化机制,存在锁机制复杂影响并发的问题,而PG不存在。
二、MySQL相对于PG的优势:
1、innodb的基于回滚段实现的MVCC机制,相对PG新老数据一起存放的基于XID的MVCC机制,是占优 的。新老数据一起存放,需要定时触 发VACUUM,会带来多余的IO和数据库对象加锁开销,引起数据库整体的并发能力下降。而且VACUUM清理不及时,还可能会引发数据膨胀;
2、MySQL采用索引组织表,这种存储方式非常适合基于主键匹配的查询、删改操作,但是对表结构设 计存在约束;
3、MySQL的优化器较简单,系统表、运算符、数据类型的实现都很精简,非常适合简单的查询操作;
4、MySQL分区表的实现要优于PG的基于继承表的分区实现,主要体现在分区个数达到上千上万后的处 理性能差异较大。
5、MySQL的存储引擎插件化机制,使得它的应用场景更加广泛,比如除了innodb适合事务处理场景 外,myisam适合静态数据的查询场景。
三、总体上来说
开源数据库都不是很完善,商业数据库oracle在架构和功能方面都还是完善很多的。从应用场景来说, PG更加适合严格的企业应用场景(比如金融、电信、ERP、CRM),而MySQL更加适合业务逻辑相对简单、数据可靠性要求较低的互联网场景(比如google、facebook、alibaba)。
本期的文档整理参考部分网上资源和自己实际测试内容,如有不对,多多指教。第一次发表文档记录。
下一期内容:基于POI封装后的导入导出excel版