Nvidia Tensor Core初探
目录
1 背景
2 硬件单元
3 架构
3.1 Volta Tensor Core
3.2 Turing Tensor Core
3.3 Ampere Tensor Core
3.4 Hopper Tensor Core
4 调用
4.1 WMMA (Warp-level Matrix Multiply Accumulate) API
4.2 WMMA PTX (Parallel Thread Execution)
4.3 MMA (Matrix Multiply Accumulate) PTX
4.4 SASS
1 背景
在基于深度学习卷积网络的图像处理领域,作为计算密集型的卷积算子一直都是工程优化的重点,而卷积计算一般转化为矩阵乘运算,所以优化矩阵乘运算自然成为深度学习框架最为关心的优化方向之一。鉴于此,Nvidia官方给出了一套硬件解决方案,即Tensor Core,可加速矩阵乘运算,实现混合精度计算,在保持准确性的同时提高吞吐量。
2 硬件单元
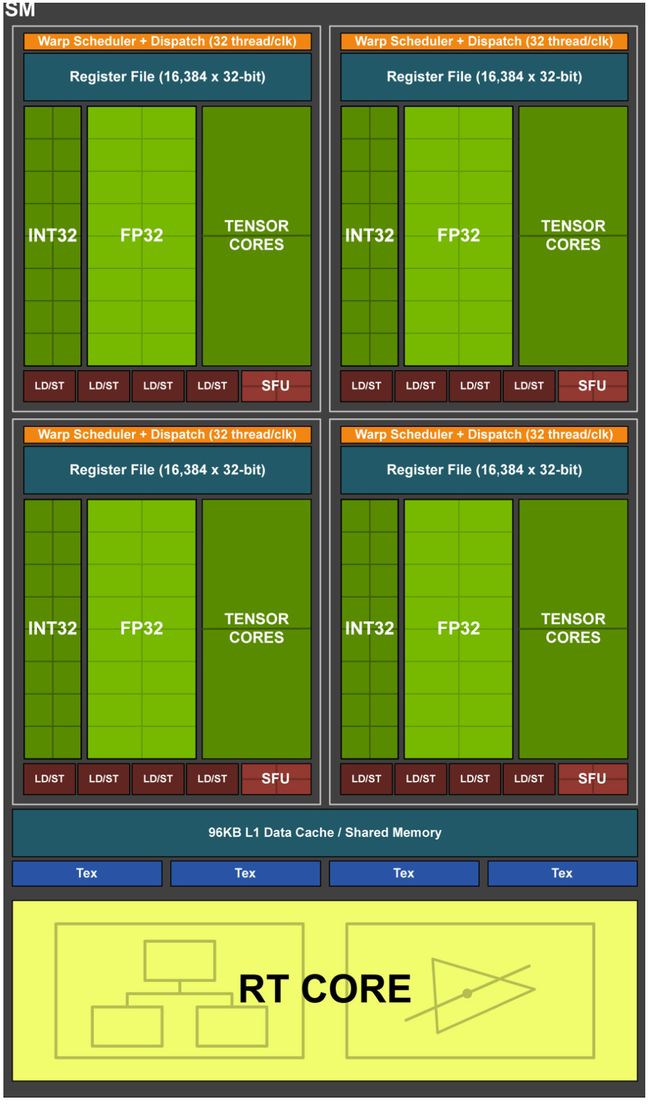
同CUDA Core一样,Tensor Core也是一种运算单元,专门处理矩阵乘运算。如下图为Turing TU102/TU104/TU106的SM内部结构图,分为4个processing blocks,每个processing block包含16个FP32 Cores、16个INT32 Cores、2个Tensor Cores、1个Warp Scheduler和1个Dispatch Unit。
3 架构
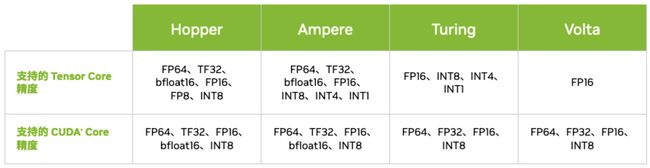
自Volta架构推出第一代Tensor Core以来,后续在每一代的架构升级中,Tensor Core都有比较大的改进,支持的数据类型也逐渐增多。
3.1 Volta Tensor Core
第一代Tensor Core支持FP16和FP32下的混合精度矩阵乘法,可提供每秒超过100万亿次(TFLOPS)的深度学习性能,是Pascal架构的5倍以上。与Pascal相比,用于训练的峰值teraFLOPS(TFLOPS)性能提升了高达12倍,用于推理的峰值TFLOPS性能提升了高达6倍,训练和推理性能提升了3倍。

3.2 Turing Tensor Core
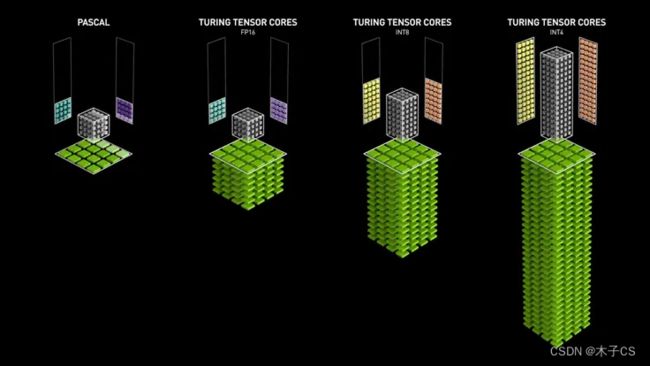
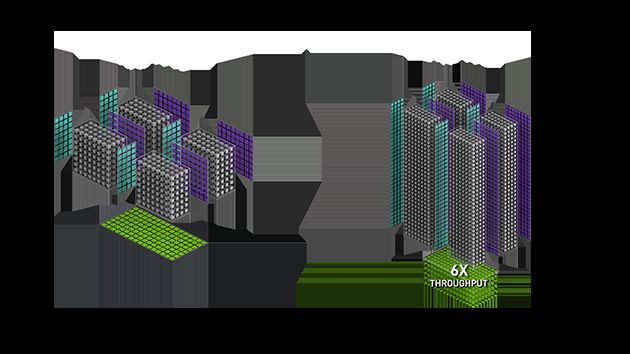
第二代Tensor Core提供了一系列用于深度学习训练和推理的精度(从FP32到FP16再到INT8和INT4),每秒可提供高达500万亿次的张量运算。
3.3 Ampere Tensor Core
第三代Tensor Core采用全新精度标准Tensor Float 32(TF32)与64位浮点(FP64),以加速并简化人工智能应用,可将人工智能速度提升至最高20倍。

3.4 Hopper Tensor Core
第四代Tensor Core使用新的8位浮点精度(FP8),可为万亿参数模型训练提供比FP16高6倍的性能。FP8用于 Transformer引擎,能够应用FP8和FP16的混合精度模式,大幅加速Transformer训练,同时兼顾准确性。FP8还可大幅提升大型语言模型推理的速度,性能较Ampere提升高达30倍。
4 调用
除了使用CUDA生态库里的API调用Tensor Core,如cublas、cudnn等,Nvidia还提供了以下几种方式调用Tensor Core。
4.1 WMMA (Warp-level Matrix Multiply Accumulate) API
对于计算能力在7.0及以上的CUDA设备,可以使用CUDA C++ API调用Tensor Core,支持形如D = AB + C的混合精度的矩阵乘运算。
template class fragment;
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
void fill_fragment(fragment<...> &a, const T& v);
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false); -
fragment:Tensor Core数据存储类,支持matrix_a、matrix_b和accumulator
-
load_matrix_sync:Tensor Core数据加载API,支持将矩阵数据从global memory或shared memory加载到fragment
-
store_matrix_sync:Tensor Core结果存储API,支持将计算结果从fragment存储到global memory或shared memory
-
fill_fragment:fragment填充API,支持常数值填充
-
mma_sync:Tensor Core矩阵乘计算API,支持D = AB + C或者C = AB + C
4.2 WMMA PTX (Parallel Thread Execution)
对于计算能力在7.0及以上的CUDA设备,也可以使用WMMA PTX指令调用Tensor Core,支持形如D = AB + C的混合精度的矩阵乘运算。
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride};
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride};
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride};
wmma.mma.sync.aligned.alayout.blayout.shape.dtype.ctype d, a, b, c;-
wmma.load:Tensor Core数据加载指令,支持将矩阵数据从global memory或shared memory加载到Tensor Core寄存器
-
wmma.store:Tensor Core结果存储指令,支持将计算结果从Tensor Core寄存器存储到global memory或shared memory
-
wmma.mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C
4.3 MMA (Matrix Multiply Accumulate) PTX
对于计算能力在7.0及以上的CUDA设备,还可以使用MMA PTX指令调用Tensor Core,支持形如D = AB + C的混合精度的矩阵乘运算。
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;-
ldmatrix:Tensor Core数据加载指令,支持将矩阵数据从shared memory加载到Tensor Core寄存器
-
mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C
4.4 SASS
根据SASS指令集学习。