机器学习——神经网络(Neural Network)
1、MP模型
Mp模型是最基础,最原始的神经网络模型。MP模型是1943年心理学家W.S.McCulloch和数理逻辑学家W.Pitts建立的。它的主要结构如图1所示。

图1 (来源于浙江大学胡浩基老师的机器学习课程)
![]()
2、感知器算法
感知器算法是在MP模型的基础上发展来的,主要可以解决我们在上一节中提到的线性可分问题。主要的算法流程如下所示:
(1) 随机选取 和
和 ;
;
(2) 选取一个训练样本(X,y), 对于这个训练样本作如下判断:
if ![]() ,
, ![]()
if ![]() ,
, ![]()
(3) 选取下一个训练样本(X,y), 回到步骤(2);
(4) 直至所有的训练样本都不满足步骤(2)中的两个条件,则结束循环。
3、多层神经网络
之前的感知机算法不能解决线性不可分问题,为了更好的解决这一问题,人们提出了多层神经网。

上图证明了多层神经网络中非线性映射函数的重要性,在神经网络中主要使用阶跃函数。


但是在实际应用中,往往模型的结构是未知且参数也是未知的。网络的设计也是在长期的实践中得出来的经验,主要有以下两个准则:
A. 如果问题是简单的,神经网络的层数与每层神经元的个数都可以适当减小;如果问题是复杂的,神经网络需要的层数与每层神经元的个数也可以适当增加;
B. 在训练样本多的情况下,一般需要设置网络层数与每层神经元数目要多一些;在训练样本少的情况下,一般需要设置网络层数与每层神经元数目要少一些。
如果我们假定神经网络层数与各层单元数都已确定,那么如何优化网络中待求的参数?主要是用梯度下降算法(由于 是与的非凸函数,所以使用梯度下降算法来求解局部极小值)与反向传播方法。
是与的非凸函数,所以使用梯度下降算法来求解局部极小值)与反向传播方法。




以上便是后向传播的各个公式的推导过程。之所以称之为后向传播,是因为在上述的推导中我们可以看到,我们先计算了结尾各个值的偏导数而后根据这些偏导数再去求相应的参数的偏导数。是一种由后向前求导的方法。其主要步骤如下所示:
A. 首先对神经网络的每层的各个神经元,随机选取参数与的值;
B. 设置目标函数E(损失函数)例如本文中提到的![]() ,而后利用后向传播算法对于每一个 参数与 ,计算其对应的偏导数。
,而后利用后向传播算法对于每一个 参数与 ,计算其对应的偏导数。
C. 利用如下的迭代公式更新参数与 的值:
![]()
![]()
D. 继续循环B,直至所有的![]() 与
与![]() 很小为止,退出循环。
很小为止,退出循环。
上述后向传播的推导过程是基于一个简单的有固定结构的神经网络,那么如何将神经网络结构一般化呢?




综上所述,通用的神经网络算法的步骤为:
A. 对神经网络的每层的各个神经元,随机选取参数与的值;
B. 前向计算,对于输入的训练数据计算并保留每一项的输出值,直至计算出最后一层的输出;
C. 设置目标函数,而后使用后向传播算法得到每一个参数 与的值;
D. 使用如下公式更新 参数 与的值:
![]()
![]()
E. 回到第二步一直循环,直至所有的![]() 与
与![]() 很小为止,退出循环。
很小为止,退出循环。
上述的神经网络的一般化算法在实际应用中还存在一些问题,针对这些问题我们需要对一般化的神经网络算法进行处理,主要分为以下三个部分:
A. 激活函数
上述神经网络一般化算法中使用的激活函数是阶跃函数。而我们在反向传播过程中需要求解接货函数的导数。但是阶跃函数在0处没有导数,所以我们需要对激活函数进行改进。主要有两种改进方式:sigmoid函数与tanh函数。
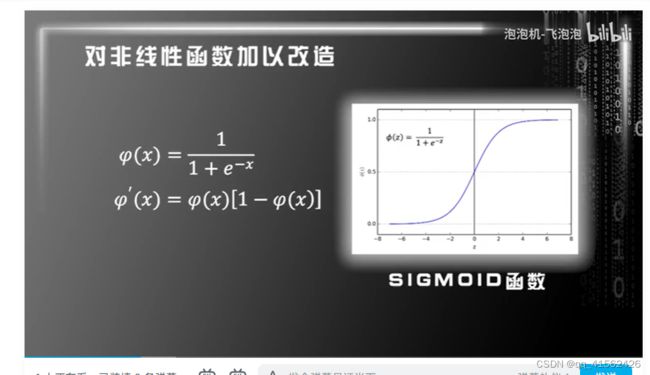


B. 损失函数
前面在神经网络的一般算法中我们使用了![]() 作为损失函数。但是在人工神经网络中,我们通常会使用one-hot表示来表示Y所属的标签,例如第一类可以表示为:
作为损失函数。但是在人工神经网络中,我们通常会使用one-hot表示来表示Y所属的标签,例如第一类可以表示为:![]() 。所以此时我们使用softmax和交叉熵来作为分类问题的损失函数。
。所以此时我们使用softmax和交叉熵来作为分类问题的损失函数。
softmax:![]() , 且有
, 且有![]() ,
, 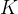 是类别数。
是类别数。
交叉熵(用于衡量两个概率分布之间的相似程度):![]()
softmax+交叉熵的损失函数求导之后对应的向量公式为![]() (推导过程)
(推导过程)
C. min-batch gradient algorithm
在之前的神经网络一般算法中,我们使用的梯度下降算法是这对每一个输入的样本更新一次网络所有的参数。这种更新方式不仅会增大计算成本消耗时间,更容易导致误差增大使得收敛十分困难(例如前一层出现误差之后,会随着前向传播影响后续的环节使得误差增大,难以收敛)。
具体重点如下:
a. 每一次不用输入一个样本就更新一下网络的所有参数而是输入一批数据(成为一个batch)之后,求出对应的平均梯度均值后,根据均值改变参数。(注:在神经网络中batch size大致设置为50-200不等);
b. 按照batch遍历所有的训练样本一次我们称之为一个epoch。而对于每一个epoch需要随机打乱所有的训练样本的次序,以增加batch中训练样本的随机性;
4、几个概念
梯度消失:如下图所示,不论是sigmoid函数还是tanh函数在绝对值很大的地方梯度都很小,所以如果一开始![]() 的绝对值很大,则对应梯度(导数)接近零,则通过后向传播后也趋近于零,所以会使得训练速度缓慢。
的绝对值很大,则对应梯度(导数)接近零,则通过后向传播后也趋近于零,所以会使得训练速度缓慢。
所以一开始需要![]() 一开始初值在0的附近。
一开始初值在0的附近。

batch normalization
基本思想:既然我们希望每一层获得的值都在0附近,从而避免梯度消失,那么直接把每一层的值做基于均值和方差的归一化。
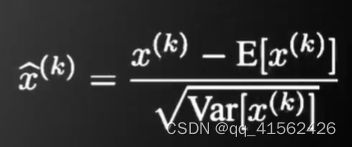
5、总结
支持向量机是寻找一个可以将两类分开的最大化间隔的超平面,而感知机相对随机寻找一个可以将两类分隔开的超平面,所以一般情况下支持向量机得到的超平面要比感知机好一些。由于感知器算法使用部分数据进行训练,而支持向量机使用全部数据训练,所以感知器算法消耗的内存与计算资源要少于支持向量机。此外,感知器算法只能解决线性可分问题,然而现实中大部分数据都是线性不可分的。