java面试--spring
目录
springMVC请求流程详解
BeanFactory 和 FactoryBean
ApplicationContext和beanfactory的区别
Spring常用注解总结
Spring 中用到了那些设计模式
spring 事务的传播机制
spring中bean的作用域有哪些;
spring框架的优点;
Spring AOP 的理解,各个术语,他们是怎么相互工作的
Spring 如何保证 Controller 并发的安全
Spring IOC 的理解
springMVC请求流程详解
springMVC请求流程图:

SpringMVC 的工作流程
【1】用户发送请求至前端控制器 DispatcherServlet;
【2】DispatcherServlet 收到请求调用 HandlerMapping 处理器映射器;
【3】处理器映射器找到具体的处理器(可以根据 xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给 DispatcherServlet;
【5】DispatcherServlet 调用 HandlerAdapter 处理器适配器;
【6】HandlerAdapter 经过适配调用具体的处理器(Controller,也叫后端控制器);
【7】Controller 执行完成返回 ModelAndView;
【8】HandlerAdapter 将 controller 执行结果 ModelAndView 返回给 DispatcherServlet;
【9】DispatcherServlet 将 ModelAndView 传给 ViewReslover 视图解析器;
【10】ViewReslover 解析后返回具体 View;
【11】DispatcherServlet 根据 View进行渲染视图(即将模型数据填充至视图中);
【12】DispatcherServlet 响应用户;
【前端控制器-DispatcherServlet】:接收请求,响应结果,相当于转发器,中央处理器。有了 DispatcherServlet减少了其它组件之间的耦合度。用户请求到达前端控制器,它就相当于 mvc模式中的c,DispatcherServlet 是整个流程控制的中心,由它调用其它组件处理用户的请求,DispatcherServlet 的存在降低了组件之间的耦合性。可以将其看做是 SpringMVC 实现中最为核心的部分;DispatcherServlet 的启动过程就是 SpringMVC 的启动过程。DispatcherServlet 的工作大致分为两个部分:①、初始化部分:由 initServletBean() 启动通过 initApplicationContext() 方法最终调用 DispatcherServlet 的 initStrategies 方法。DispatcherServlet 对 MVC 的其他模块进行初始化。比如:HandlerMapping、ViewResolver 等。②、对 HTTP 请求进行响应:doService() 方法,在这个方法调用中封装了 doDispatch() 这个 doDispatch 是实现 MVC模式的主要部分。不但建立了自己持有的 IOC容器还肩负着请求分发处理的重任。
【处理器映射器-HandlerMapping】:对于不同 Web请求有对应的映射 Spring 提供了不同的 HandlerMapping 作为映射策略。这个策略可以根据需求选择。默认的策略:BeanNameUrlHandlerMapping。根据请求的 url查找 Handler,HandlerMapping 负责根据用户请求找到 Handler即处理器,SpringMVC提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等;
【处理器适配器-HandlerAdapter】:按照特定规则(HandlerAdapter要求的规则)去执行Handler,通过 HandlerAdapter 对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行;
【处理器-Handler】(需要工程师开发):注意:编写 Handler 时按照 HandlerAdapter 的要求去做,这样适配器才可以去正确执行Handler,Handler 是继 DispatcherServlet 前端控制器的后端控制器,在 DispatcherServlet的控制下 Handler对具体的用户请求进行处理。由于Handler涉及到具体的用户业务请求,所以一般情况需要工程师根据业务需求开发 Handler;
【视图解析器View resolver】:进行视图解析,根据逻辑视图名解析成真正的视图(view)。View Resolver 负责将处理结果生成View视图,View Resolver 首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成 View视图对象,最后对 View进行渲染将处理结果通过页面展示给用户。 springmvc 框架提供了很多的View视图类型,包括:jstlView、freemarkerView、pdfView等;
【视图View】(需要工程师开发):View 是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...);
org.springframework.web.context.ContextLoaderListener
contextConfigLocation
/WEB-INF/app-context.xml
app
org.springframework.web.servlet.DispatcherServlet
contextConfigLocation
1
app
/app/*
BeanFactory 和 FactoryBean
【1】BeanFactory:Spring IoC容器设计中,我们可以看到两个主要的容器系列,其中一个就是实现 BeanFactory接口的简单容器系列,这系列容器只实现了容器的基本功能;该接口是 IoC容器的顶级接口,是 IoC容器的最基础实现,也是访问 Spring容器的根接口,负责对 Bean的创建,访问等工作。最典型的容器就是 DefaultListableBeanFactory 。
【2】FactoryBean:是一种工厂 bean,可以返回 bean的实例,可以通过实现该接口对 Bean进行额外的操作,例如根据不同的配置类型返回不同类型的 Bean,简化 xml配置等;其在使用上也有些特殊,大家还记得 BeanFactory 中有一个字符常量String FACTORY_BEAN_PREFIX = "&"; 当我们去获取 BeanFactory类型的 bean时,如果 beanName不加&则获取到对应 bean的实例;如果 beanName 加上 &,则获取到 BeanFactory本身的实例;FactoryBean 接口对应 Spring框架来说占有重要的地位,Spring 本身就提供了70多个 FactoryBean的实现。他们隐藏了实例化一些复杂的细节,给上层应用带来了便利。从Spring3.0 开始,FactoryBean 开始支持泛型。
ApplicationContext和beanfactory的区别
BeanFacotry是spring中比较原始的Factory。
ApplicationContext接口,它由BeanFactory接口派生而来,因而提供BeanFactory所有的功能。并且他还实现了Resource这些是一个更高级的容器。
BeanFactroy只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化,这样,我们就不能发现一些存在的Spring的配置问题。
ApplicationContext则相反,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误。
Spring Bean 的生命周期,如何被管理的
对于普通的 Java对象,当 new的时候创建对象,当它没有任何引用的时候被垃圾回收机制回收。而由Spring IoC容器托管的对象,它们的生命周期完全由容器控制。Spring 中每个 Bean的生命周期如下:加了一些过滤条件(黑色框的平时基本上不会用到)。那分别介绍下面的流程。

【1】实例化 Bean:对于 BeanFactory 容器,当客户向容器请求一个尚未初始化的 bean时,或初始化 bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用 createBean进行实例化。对于 ApplicationContext容器,当容器启动结束后,便实例化所有的单实例 bean。容器通过获取 BeanDefinition对象中的信息进行实例化。并且这一步仅仅是简单的实例化,并未进行依赖注入。实例化对象被包装在 BeanWrapper 对象中,BeanWrapper 提供了设置对象属性的接口,从而避免了使用反射机制设置属性。通过工厂方法或者执行构造器解析执行即可:创建的对象是个空对象。
【2】设置对象属性(依赖注入):实例化后的对象被封装在 BeanWrapper对象中,并且此时对象仍然是一个原生的状态,并没有进行依赖注入。紧接着获取所有的属性信息通过 populateBean(beanName,mbd,bw,pvs),Spring 根据 BeanDefinition 中的信息进行依赖注入。并且通过 BeanWrapper提供的设置属性的接口完成依赖注入。赋值之前获取所有的 InstantiationAwareBeanPostProcessor 后置处理器的 postProcessAfterInstantiation() 第二次获取InstantiationAwareBeanPostProcessor 后置处理器;执行 postProcessPropertyValues()最后为应用 Bean属性赋值:为属性利用 setter 方法进行赋值 applyPropertyValues(beanName,mbd,bw,pvs)。
【3】bean 初始化:initializeBean(beanName,bean,mbd)。
1)执行xxxAware 接口的方法,调用实现了BeanNameAware、BeanClassLoaderAware、BeanFactoryAware接口的方法。
2)执行后置处理器之前的方法:applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName)所有后置处理器的 BeanPostProcessor.postProcessBeforeInitialization()
3)执行初始化方法: InitializingBean 与 init-methodinvoke 当 BeanPostProcessor的前置处理完成后就会进入本阶段。先判断是否实现了 InitializingBean接口的实现;执行接口规定的初始化。其次自定义初始化方法。
InitializingBean 接口只有一个函数:afterPropertiesSet()这一阶段也可以在 bean正式构造完成前增加我们自定义的逻辑,但它与前置处理不同,由于该函数并不会把当前 bean对象传进来,因此在这一步没办法处理对象本身,只能增加一些额外的逻辑。若要使用它,我们需要让 bean实现该接口,并把要增加的逻辑写在该函数中。然后 Spring会在前置处理完成后检测当前 bean是否实现了该接口,并执行 afterPropertiesSet函数。当然,Spring 为了降低对客户代码的侵入性,给 bean的配置提供了 init-method属性,该属性指定了在这一阶段需要执行的函数名。Spring 便会在初始化阶段执行我们设置的函数。init-method 本质上仍然使用了InitializingBean接口。
4)applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);执行初始化之后的后置处理器的方法。BeanPostProcessor.postProcessAfterInitialization(result, beanName);
【4】Bean的销毁:DisposableBean 和 destroy-method:和 init-method 一样,通过给 destroy-method 指定函数,就可以在bean 销毁前执行指定的逻辑。
Bean 的管理就是通过 IOC 容器中的 BeanDefinition 信息进行管理的。
Spring常用注解总结
@Controller
标识一个该类是Spring MVC controller处理器,用来创建处理http请求的对象.
@RestController
@Controller+@ResponseBody
Spring4之后加入的注解,原来在@Controller中返回json需要@ResponseBody来配合,如果直接用@RestController替代@Controller就不需要再配置@ResponseBody,默认返回json格式。
@Service
用于标注业务层组件,说白了就是加入你有一个用注解的方式把这个类注入到spring配置中
@Autowired
用来装配bean,都可以写在字段上,或者方法上。
默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,例如:@Autowired(required=false)
@Resource
@Resource的作用相当于@Autowired
只不过@Autowired按byType自动注入,
而@Resource默认按 byName自动注入罢了。
@Resource有两个属性是比较重要的,分是name和type,Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
@Resource装配顺序:
1、如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
2、如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
3、如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常
4、如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配;
@RequestMapping
类定义处: 提供初步的请求映射信息,相对于 WEB 应用的根目录。
方法处: 提供进一步的细分映射信息,相对于类定义处的 URL。
@RequestParam
用于将请求参数区数据映射到功能处理方法的参数上
例如

这个id就是要接收从接口传递过来的参数id的值的,如果接口传递过来的参数名和你接收的不一致,也可以如下

其中course_id就是接口传递的参数,id就是映射course_id的参数名
@Repository
用于标注数据访问组件,即DAO组件
@Component
泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注
@Scope
用来配置 spring bean 的作用域,它标识 bean 的作用域。
默认值是单例
1、singleton:单例模式,全局有且仅有一个实例
2、prototype:原型模式,每次获取Bean的时候会有一个新的实例
3、request:request表示该针对每一次HTTP请求都会产生一个新的bean,同时该bean仅在当前HTTP request内有效
4、session:session作用域表示该针对每一次HTTP请求都会产生一个新的bean,同时该bean仅在当前HTTP session内有效
5、global session:只在portal应用中有用,给每一个 global http session 新建一个Bean实例。
@Cacheable
用来标记缓存查询。可用用于方法或者类中,当标记在一个方法上时表示该方法是支持缓存的,当标记在一个类上时则表示该类所有的方法都是支持缓存的。
参数列表

比如@Cacheable(value="UserCache") 标识的是当调用了标记了这个注解的方法时,逻辑默认加上从缓存中获取结果的逻辑,如果缓存中没有数据,则执行用户编写查询逻辑,查询成功之后,同时将结果放入缓存中。
但凡说到缓存,都是key-value的形式的,因此key就是方法中的参数(id),value就是查询的结果,而命名空间UserCache是在spring*.xml中定义.

@CacheEvict
用来标记要清空缓存的方法,当这个方法被调用后,即会清空缓存。@CacheEvict(value=”UserCache”)
参数列表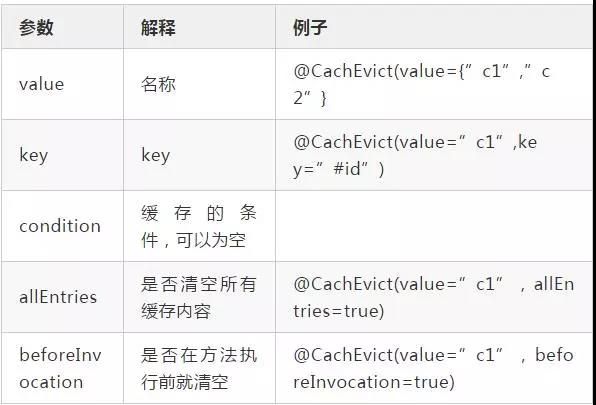
@Required
适用于bean属性setter方法,并表示受影响的bean属性必须在XML配置文件在配置时进行填充。否则,容器会抛出一个BeanInitializationException异常。
@Qualifier
当你创建多个具有相同类型的 bean 时,并且想要用一个属性只为它们其中的一个进行装配,在这种情况下,你可以使用 @Qualifier 注释和 @Autowired 注释通过指定哪一个真正的 bean 将会被装配来消除混乱。
Spring 中用到了那些设计模式
【1】工厂设计模式:Spring 使用工厂模式通过 BeanFactory、ApplicationContext 创建 bean 对象。
【2】代理设计模式:Spring AOP 功能的实现。
【3】单例设计模式:Spring 中的 Bean 默认都是单例的。
【4】模板方法模式:Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
【5】包装器设计模式:我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
【6】观察者模式:Spring 事件驱动模型就是观察者模式很经典的一个应用。
【7】适配器模式:Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配。
【8】职责链模式:Spring AOP 中通过拦截器链将 Advice(通知器) 进行封装,与代理模式配合完成 AOP 功能。
@transactional注解在什么情况下会失效
1、service类标签(一般不建议在接口上)上添加@Transactional,可以将整个类纳入spring事务管理,在每个业务方法执行时都会开启一个事务,不过这些事务采用相同的管理方式。
2、@Transactional 注解只能应用到 public 可见度的方法上。 如果应用在protected、private或者 package可见度的方法上,也不会报错,不过事务设置不会起作用。
3、默认情况下,Spring会对unchecked异常进行事务回滚;如果是checked异常则不回滚。
辣么什么是checked异常,什么是unchecked异常
java里面将派生于Error或者RuntimeException(比如空指针,1/0)的异常称为unchecked异常,其他继承自java.lang.Exception得异常统称为Checked Exception,如IOException、TimeoutException等
辣么再通俗一点:你写代码出现的空指针等异常,会被回滚,文件读写,网络出问题,spring就没法回滚了。然后我教大家怎么记这个,因为很多同学容易弄混,你写代码的时候有些IOException我们的编译器是能够检测到的,说以叫checked异常,你写代码的时候空指针等死检测不到的,所以叫unchecked异常。这样是不是好记一些啦
4、只读事务:
@Transactional(propagation=Propagation.NOT_SUPPORTED,readOnly=true)
只读标志只在事务启动时应用,否则即使配置也会被忽略。
启动事务会增加线程开销,数据库因共享读取而锁定(具体跟数据库类型和事务隔离级别有关)。通常情况下,仅是读取数据时,不必设置只读事务而增加额外的系统开销。
spring 事务的传播机制
spring 对事务的控制,是使用 aop 切面实现的,我们不用关心事务的开始,提交 ,回滚,只需要在方法上加 @Transactional 注解,这时候就有问题了。
- 场景一: serviceA 方法调用了 serviceB 方法,但两个方法都有事务,这个时候如果 serviceB 方法异常,是让 serviceB 方法提交,还是两个一起回滚。
- 场景二:serviceA 方法调用了 serviceB 方法,但是只有 serviceA 方法加了事务,是否把 serviceB 也加入 serviceA 的事务,如果 serviceB 异常,是否回滚 serviceA 。
- 场景三:serviceA 方法调用了 serviceB 方法,两者都有事务,serviceB 已经正常执行完,但 serviceA 异常,是否需要回滚 serviceB 的数据。
因为 spring 是使用 aop 来代理事务控制 ,是针对于接口或类的,所以在同一个 service 类中两个方法的调用,传播机制是不生效的
传播机制类型(七种)
一般用得比较多的是
required :合并成一个事务;
requires_new:新建事务,父级异常,它也是正常提交;
nested:成为父级事务的一个子事务,他异常可以不回滚,父级异常,它必然回滚;
下面的类型都是针对于被调用方法来说的,理解起来要想象成两个 service 方法的调用才可以。
PROPAGATION_REQUIRED (默认)required
-
支持当前事务,如果当前没有事务,则新建事务
-
如果当前存在事务,则加入当前事务,合并成一个事务
REQUIRES_NEW requires_new
-
新建事务,如果当前存在事务,则把当前事务挂起
-
这个方法会独立提交事务,不受调用者的事务影响,父级异常,它也是正常提交
NESTED
-
如果当前存在事务,它将会成为父级事务的一个子事务,方法结束后并没有提交,只有等父事务结束才提交
-
如果当前没有事务,则新建事务
-
如果它异常,父级可以捕获它的异常而不进行回滚,正常提交
-
但如果父级异常,它必然回滚,这就是和
REQUIRES_NEW的区别
SUPPORTS
-
如果当前存在事务,则加入事务
-
如果当前不存在事务,则以非事务方式运行,这个和不写没区别
NOT_SUPPORTED
-
以非事务方式运行
-
如果当前存在事务,则把当前事务挂起
MANDATORY
-
如果当前存在事务,则运行在当前事务中
-
如果当前无事务,则抛出异常,也即父级方法必须有事务
NEVER
-
以非事务方式运行,如果当前存在事务,则抛出异常,即父级方法必须无事务
spring中bean的作用域有哪些;
scope配置项有5个属性,用于描述不同的作用域。
① singleton
使用该属性定义Bean时,IOC容器仅创建一个Bean实例,IOC容器每次返回的是同一个Bean实例。
② prototype
使用该属性定义Bean时,IOC容器可以创建多个Bean实例,每次返回的都是一个新的实例。
③ request
该属性仅对HTTP请求产生作用,使用该属性定义Bean时,每次HTTP请求都会创建一个新的Bean,适用于WebApplicationContext环境。
④ session
该属性仅用于HTTP Session,同一个Session共享一个Bean实例。不同Session使用不同的实例。
⑤ global-session
该属性仅用于HTTP Session,同session作用域不同的是,所有的Session共享一个Bean实例。
其中比较常用的是singleton和prototype两种作用域。对于singleton作用域的Bean,每次请求该Bean都将获得相同的实例。容器负责跟踪Bean实例的状态,负责维护Bean实例的生命周期行为;如果一个Bean被设置成prototype作用域,程序每次请求该id的Bean,Spring都会新建一个Bean实例,然后返回给程序。在这种情况下,Spring容器仅仅使用new 关键字创建Bean实例,一旦创建成功,容器不在跟踪实例,也不会维护Bean实例的状态。
如果不指定Bean的作用域,Spring默认使用singleton作用域。Java在创建Java实例时,需要进行内存申请;销毁实例时,需要完成垃圾回收,这些工作都会导致系统开销的增加。因此,prototype作用域Bean的创建、销毁代价比较大。而singleton作用域的Bean实例一旦创建成功,可以重复使用。因此,除非必要,否则尽量避免将Bean被设置成prototype作用域。
spring框架的优点;
1、非侵入式设计
Spring是一种非侵入式(non-invasive)框架,它可以使应用程序代码对框架的依赖最小化。
2、方便解耦、简化开发
Spring就是一个大工厂,可以将所有对象的创建和依赖关系的维护工作都交给Spring容器的管理,大大的降低了组件之间的耦合性。
3、支持AOP
Spring提供了对AOP的支持,它允许将一些通用任务,如安全、事物、日志等进行集中式处理,从而提高了程序的复用性。
4、支持声明式事务处理
只需要通过配置就可以完成对事物的管理,而无须手动编程。
5、方便程序的测试
Spring提供了对Junit4的支持,可以通过注解方便的测试Spring程序。
6、方便集成各种优秀框架
Spring不排斥各种优秀的开源框架,其内部提供了对各种优秀框架(如Struts、Hibernate、MyBatis、Quartz等)的直接支持。
7、降低Jave EE API的使用难度。
Spring对Java EE开发中非常难用的一些API(如JDBC、JavaMail等),都提供了封装,使这些API应用难度大大降低。
Spring AOP 的理解,各个术语,他们是怎么相互工作的
Spring 用代理类+拦截器链包裹切面,把它们织入到 Spring管理的 Bean中。也就是说代理类伪装成目标类,它会截取对目标类中方法的调用,让调用者对目标类的调用都先变成调用伪装类,伪装类中就先执行了切面,再把调用转发给真正的目标Bean。
【1】通知器(Advice):当我们完成对目标方法的切面增强设计(advice)和关注点的设计(pointcut)以后,需要一个对象把它们结合起来。主要包括:①、@Before:前置通知,方法执行之前执行;②、@After(finally):后置通知,方法执行之后执行,无论成功执行还是抛出异常。③、@AfterReturning:返回通知,方法成功执行之后执行,异常或者错误不执行。可以获取方法返回值。④、@AfterThrowing:异常通知,方法抛出异常之后才执行,成功时不执行。⑤、@Around:环绕通知,包括以上四中注解!能决定目标方法是否执行和执行时间。
@Around("point()")
public void exec(ProceedingJoinPoint point) throws Throwable{
System.out.println("...............Before(此处执行的代码相当于-前置通知)...............");
try{
point.proceed();//有此代码,被切入的方法体才会执行,如果被切入的方法有返回值,则返回值为null,见3
System.out.println("..........AfterReturning(此处执行的代码相当于-返回通知)..........");
}catch(Exception e){
System.out.println("...........AfterThrowing(此处执行的代码相当于-异常通知)..........");
}finally{
System.out.println("...........After1(此处执行的代码相当于-后置通知).............");
}
System.out.println("........After2(此处执行的代码相当于-后置通知).........");
}
【2】连接点(JoinPoint):JoinPoint 对象封装了 SpringAop中切面方法的信息,在切面方法中添加 JoinPoint 参数,就可以获取到封装了该方法信息的 JoinPoint对象。ProceedingJoinPoint 对象:ProceedingJoinPoint 对象是 JoinPoint 的子接口,该对象只用在 @Around 的切面方法中,添加了 Object proceed()执行目标方法,例如上面的例子。作为方法的参数传入:
/**
* 前置方法,在目标方法执行前执行
* @param joinPoint 封装了代理方法信息的对象,若用不到则可以忽略不写
*/
@Before("declareJoinPointerExpression()")
public void beforeMethod(JoinPoint joinPoint){
System.out.println("目标方法名为:" + joinPoint.getSignature().getName());
System.out.println("目标方法所属类的简单类名:" + joinPoint.getSignature().getDeclaringType().getSimpleName());
System.out.println("目标方法所属类的类名:" + joinPoint.getSignature().getDeclaringTypeName());
System.out.println("目标方法声明类型:" + Modifier.toString(joinPoint.getSignature().getModifiers()));
//获取传入目标方法的参数
Object[] args = joinPoint.getArgs();
for (int i = 0; i < args.length; i++) {
System.out.println("第" + (i+1) + "个参数为:" + args[i]);
}
System.out.println("被代理的对象:" + joinPoint.getTarget());
System.out.println("代理对象自己:" + joinPoint.getThis());
}
【3】切入点(Pointcut):上面说的连接点的基础上,来定义切入点,你的一个类里,有15个方法,那就有几十个连接点了对把,但是你并不想在所有方法附近都使用通知(使用叫织入,以后再说),你只想让其中的几个,在调用这几个方法之前,之后或者抛出异常时干点什么,那么就用切点来定义这几个方法,让切入点来筛选连接点,选中那几个你想要的方法。
/**
* 定义一个切入点表达式,用来确定哪些类需要代理
* execution(* aopdemo.*.*(..))代表aopdemo包下所有类的所有方法都会被代理
*/
@Pointcut("execution(* aopdemo.*.*(..))")
public void declareJoinPointerExpression() {}
【4】切面(Aspect):切面是通知和切入点的结合。现在发现了吧,没连接点什么事情,连接点就是为了让你好理解切入点,搞出来的,明白这个概念就行了。通知说明了干什么和什么时候干(什么时候通过方法名中的before、after、around等就能知道),而切入点说明了在哪干(指定到底是哪个方法),这就是一个完整的切面定义。上面的方法都在此类中定义:
@Aspect
@Component
public class aopAspect {【5】引入(introduction):允许我们向现有的类添加新方法属性。这不就是把切面(也就是新方法属性:通知定义的)用到目标类中吗。
【6】目标(target):引入中所提到的目标类,也就是要被通知的对象,也就是真正的业务逻辑,他可以在毫不知情的情况下,被咱们织入切面。而自己专注于业务本身的逻辑。
【7】织入(weaving):织入是将增强添加到目标类具体连接点上的过程,AOP有三种织入方式:①编译时织入:需要特殊的Java编译器(例如AspectJ的ajc);②装载期织入:要求使用特殊的类加载器,在装载类的时候对类进行增强;③运行时织入:在运行时为目标类生成代理实现增强。Spring采用了动态代理的方式实现了运行时织入,而AspectJ采用了编译期织入和装载期织入的方式。
【8】在 SpringAopDemoApplication 中增加注解 @EnableAspectJAutoProxy
@SpringBootApplication
@EnableAspectJAutoProxy
public class SpringAopDemoApplication {
public static void main(String[] args) {
ApplicationContext applicationContext = SpringApplication.run(SpringAopDemoApplication.class, args);
}
}Spring 如何保证 Controller 并发的安全
Controller 默认是单例的,一般情况下,如果用Spring MVC 的 Controller时,尽量不在 Controller中使用实例变量。否则会出现线程不安全性的情况,导致数据逻辑混乱。正因为单例所以不是线程安全的。举个简单例子:
@Controller
public class ScopeTestController {
private int num = 0;
@RequestMapping("/testScope")
public void testScope() {
System.out.println(++num);
}
@RequestMapping("/testScope2")
public void testScope2() {
System.out.println(++num);
}
}【1】首先访问 http://localhost:8080/testScope,得到的答案是1;
【2】然后我们再访问 http://localhost:8080/testScope2,得到的答案是 2。 此时就不是我们想要的答案,num已经被修改。所有 request都访问同一个 Controller时,这里的私有变量就是共用的,也就是说某个 request中如果修改了这个变量,那么在别的请求中也可读到这个修改的内容。
【解决办法】:
【1】不要在 Controller 中定义成员变量;
【2】万一必须要定义一个非静态成员变量时候,则通过注解 @Scope(“prototype”),将其设置为多例模式。
【3】在 Controller 中使用 ThreadLocal 变量;
Spring IOC 的理解
- 谁控制谁:在传统的开发模式下,我们都是采用直接 new 一个对象的方式来创建对象,也就是说你依赖的对象直接由你自己控制,但是有了 IOC 容器后,则直接由 IoC 容器来控制。所以“谁控制谁”,当然是 IoC 容器控制对象。
- 控制什么:控制对象。
- 为何是反转:没有 IoC 的时候我们都是在自己对象中主动去创建被依赖的对象,这是正转。但是有了 IoC 后,所依赖的对象直接由 IoC 容器创建后注入到被注入的对象中,依赖的对象由原来的主动获取变成被动接受,所以是反转。
- 哪些方面反转了:所依赖对象的获取被反转了。