Flink-1.11 新的部署模型 application mode
在 Flink-1.11 版本之前 Flink on yarn 有两种部署的模式, session 模式和 per-job 模式,但是这两种模式都存在一定的问题,所以在最新的 Flink-1.11 版本中引入了新的部署模式即 application 模式,支持 yarn 和 k8s,这篇文章主要来分析一下新旧模式的优缺点以及 application 模式的使用.
session mode
会话模式假定一个已经在运行的集群,并使用该集群的资源来执行任何提交的应用程序。在同一个(会话)集群中执行的应用程序使用相同的资源,并因此竞争相同的资源。你并没有为每一项工作付出全部的开销。但是,如果其中一个作业行为不当或导致TaskManager崩溃,则该TaskManager上运行的所有作业都将受到该故障的影响。除了对导致失败的作业造成负面影响外,这意味着一个潜在的大规模恢复过程,即所有重新启动的作业同时访问文件系统,并使其对其他服务不可用。另外,让一个集群运行多个作业意味着JobManager的负载更大,JobManager负责记录集群中的所有作业。这种模式非常适合于启动延迟非常重要的短作业,例如交互式查询。
per-job mode
在每作业模式下,可用的集群管理器框架(例如YARN或Kubernetes)用于为每个提交的作业启动一个Flink集群,该集群仅对该作业可用。作业完成后,集群将关闭,并清理所有延迟的资源(例如文件)。此模式允许更好的资源隔离,因为行为不端的作业不会影响任何其他作业。此外,由于每个应用程序都有自己的JobManager,因此它将簿记负载分散到多个实体中。考虑到前面提到的会话模式的资源隔离问题,用户通常会选择每个作业模式来处理长时间运行的作业,这些作业愿意接受一些启动延迟的增加,以利于恢复。总而言之,在会话模式下,集群生命周期独立于集群上运行的任何作业,并且集群上运行的所有作业共享其资源。每作业模式选择为每个提交的作业付出启动集群的代价,以提供更好的资源隔离保证,因为资源不会跨作业共享。在这种情况下,集群的生命周期与作业的生命周期相关联.
存在的问题
通过上面的描述可以看出,这两种模式程序的入口 main 方法都是在客户端执行的,在 main 方法开始执行直到 env.execute() 方法之前,客户端也需要做一些工作,即:
获取作业所需的依赖项;
通过执行环境分析并取得逻辑计划,即StreamGraph→JobGraph;
将依赖项和JobGraph上传到集群中。
只有在这些都完成之后,才会通过 env.execute() 方法触发 Flink 运行时真正地开始执行作业。如果所有用户都在客户端上提交作业,较大的依赖会消耗更多的带宽,而较复杂的作业逻辑翻译成 JobGraph 也需要吃掉更多的 CPU 和内存,客户端的资源反而会成为瓶颈——不管 Session 还是 Per-Job 模式都存在此问题。为了解决它,社区在传统部署模式的基础上实现了 Application 模式。
application mode
Application 模式下,用户程序的 main 方法将在集群中而不是客户端运行,用户将程序逻辑和依赖打包进一个可执行的 jar 包里,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法来生成 JobGraph。Application 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止。在这种体系结构中,Application 模式在不同应用之间提供了资源隔离和负载平衡保证。在特定一个应用程序上,JobManager 执行 main() 可以节省所需的 CPU 周期,还可以节省本地下载依赖项所需的带宽。
application mode 使用
./bin/flink run-application -t yarn-application ./MyApplication.jar
使用此命令,所有配置参数(例如用于引导应用程序状态的保存点的路径或所需的JobManager / TaskManager内存大小)都可以通过其配置选项(以开头)来指定-D。有关可用配置选项的目录,请参阅Flink的 配置页面。
例如,用于指定 JobManager 和 TaskManager 的内存大小的命令如下所示:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
./MyApplication.jar
为了进一步节省将Flink发行版运送到群集的带宽,可以把 Flink 的发行版预上传到 YARN 可访问的位置,并使用 yarn.provided.lib.dirs配置选项,如下所示:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \
./MyApplication.jar
最后,为了进一步节省提交应用程序 jar 所需的带宽,还可以将其预上传到 HDFS,并指定指向的远程路径, ./MyApplication.jar如下所示:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \
hdfs://myhdfs/jars/MyApplication.jar
还可以把 yarn.provided.lib.dirs 配置到 conf/flink-conf.yaml 中,这样提交作业就和普通的作业没有什么区别
注意事项
在配置 yarn.provided.lib.dirs 的时候需要注意:
1,需要把 lib 和 plugins 包地址用 ; 分开,如果放在一起的话可能会造成包的冲突.
2, plugins 包的路径必须以 plugins 结尾.
3,hdfs 路径必须指定 nameservice (或者 active namenode 的地址) ,不能简写为 hdfs:///path/lib 这种形式
提交任务
flink run-application -t yarn-application \
-c flink.streaming.FlinkReduceFunctionDemo \
-Denv.hadoop.conf.dir=/home/jason/bigdata/hadoop/hadoop-2.9.0/etc/hadoop \
-Dyarn.application.queue="flink" \
-Djobmanager.memory.process.size=1024m \
-Dtaskmanager.memory.process.size=1024m \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dparallelism.default=4 \
-Dyarn.application-attempts=4 \
-Dyarn.application.name="test" \
-Dyarn.provided.lib.dirs="hdfs://master:9000/flink/lib;hdfs://master:9000/flink/plugins" \
hdfs://master:9000/flink/jar/flink-1.11.1-1.0-SNAPSHOT.jar
需要把 lib plugins 还有自己的 jar 包提前上传到 HDFS上面,然后运行命令提交一个任务
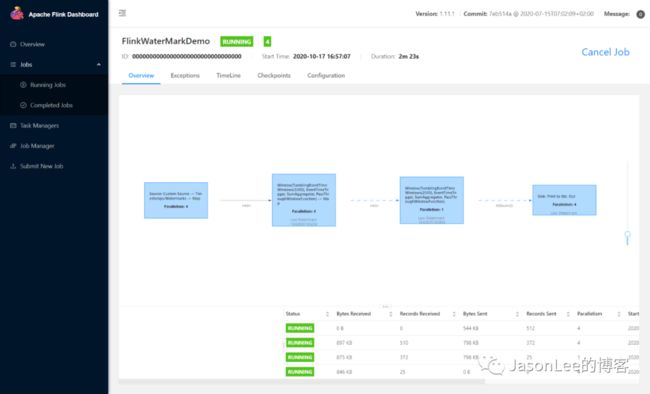
你会发现提交任务的速度确实变快了,因为配置了 yarn.provided.lib.dirs 相当于提前把包上传到了 HDFS 上, Flink 会检测到这个配置,直接从 HDFS 上拉取 Flink运行所需要的依赖包.
提交任务的时候可能会遇到报错,一定要去看日志,比如下面的报错信息.
The program finished with the following exception:
org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn Application Cluster
at org.apache.flink.yarn.YarnClusterDescriptor.deployApplicationCluster(YarnClusterDescriptor.java:414)
at org.apache.flink.client.deployment.application.cli.ApplicationClusterDeployer.run(ApplicationClusterDeployer.java:64)
at org.apache.flink.client.cli.CliFrontend.runApplication(CliFrontend.java:197)
at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:919)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:992)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1836)
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:992)
Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.
Diagnostics from YARN: Application application_1602833854828_0057 failed 2 times due to AM Container for appattempt_1602833854828_0057_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2020-10-17 17:23:49.428]Exception from container-launch.
Container id: container_1602833854828_0057_02_000001
Exit code: 1
[2020-10-17 17:23:49.428]
[2020-10-17 17:23:49.429]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
[2020-10-17 17:23:49.429]
[2020-10-17 17:23:49.429]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
[2020-10-17 17:23:49.429]
For more detailed output, check the application tracking page: http://master:8088/cluster/app/application_1602833854828_0057 Then click on links to logs of each attempt.
. Failing the application.
If log aggregation is enabled on your cluster, use this command to further investigate the issue:
yarn logs -applicationId application_1602833854828_0057
at org.apache.flink.yarn.YarnClusterDescriptor.startAppMaster(YarnClusterDescriptor.java:1021)
at org.apache.flink.yarn.YarnClusterDescriptor.deployInternal(YarnClusterDescriptor.java:524)
at org.apache.flink.yarn.YarnClusterDescriptor.deployApplicationCluster(YarnClusterDescriptor.java:407)
... 9 more
2020-10-17 17:23:49,590 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cancelling deployment from Deployment Failure Hook
2020-10-17 17:23:49,591 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at master/192.168.17.142:8032
2020-10-17 17:23:49,591 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Killing YARN application
2020-10-17 17:23:49,609 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Killed application application_1602833854828_0057
2020-10-17 17:23:49,609 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deleting files in hdfs://master:9000/user/root/.flink/application_1602833854828_0057.
需要用 yarn logs -applicationId application_1602833854828_0057 命令去看下日志,找一下真正报错的原因,快速的定位问题.
注意
1,目前 application 模式在配置了 HA 的集群环境下 jobid 显示的是 00000000000000000000000000000000 而不是一个随机字符(可以看上图显示的就是0),主要是因为目前 HA 的模式下 application 模式任务的 recovery 比较复杂,目前 HA 模式不支持多个 job 所以暂时就把 jobid 设置成 0 了.
2,在官网的提交命令中,并没有指定 main 方法所在的类,但是测试的 demo 却依然可以运行,那 Flink是怎么知道要运行哪个类的呢? 这个是因为 Flink 会自动检测用户提交的 jar 包然后提取到 main 方法,具体的代码是在 PackagedProgram 这个类里面. 核心的代码如下,感兴趣的可以自己去看一下, 不过还是建议自己指定一个比较好.
// load the entry point class
this.mainClass = loadMainClass(
// if no entryPointClassName name was given, we try and look one up through the manifest
entryPointClassName != null ? entryPointClassName : getEntryPointClassNameFromJar(this.jarFile),
userCodeClassLoader);
推荐阅读
Flink on zeppelin第四弹hive streaming writing
JasonLee,公众号:JasonLee的博客Flink on zeppelin第四弹hive streaming writing
Flink on zeppelin第三弹UDF的使用
JasonLee,公众号:JasonLee的博客Flink on zeppelin第三弹UDF的使用
Flink on zeppelin 实时计算pv,uv结果写入mysql
JasonLee,公众号:JasonLee的博客Flink on zeppelin体验第二弹
Flink on zepplien的安装配置
JasonLee,公众号:JasonLee的博客Flink on zepplien的使用体验
更多spark和flink的内容可以关注下面的公众号
