分布式NoSQL数据库HBase实践与原理剖析(一)
title: HBase系列
第一章 HBase基础理论
1.1 HBase简介
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Apache HBase™ 是Hadoop数据库,是一种分布式、可扩展的大数据存储。
HBase 是 BigTable 的开源 java 版本。
建立在 HDFS 之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的 NoSQL 数据库系统。
NoSQL的两种解释,更精确的是后者
NoSQL = NO SQL
NoSQL = Not Only SQL
NoSQL:HBase, Redis, MongoDB
NoSQL数据库基本上都是Key-Value类型存储数据的。
RDBMS:MySQL,Oracle,SQL Server,DB2
RDBMS数据库基本上都可以通过SQL去进行操作
以下几点是 HBase 这个 NoSQL 数据库的要点:
1、它仅能通过主键(row key)和主键的 range 来检索数据;
2、HBase查询数据功能简单,不支持 join 等复杂操作;
3、不支持复杂的事务(行级的事务);
4、HBase 中支持的数据类型:byte[] ;
5、主要用来存储结构化和半结构化的数据。
与 Hadoop 一样,HBase 目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase 中的表一般有这样的特点:
1、大:一个表可以有上十亿行,上百万列;
2、面向列:面向列(簇)的存储和权限控制,列(簇)独立检索;
3、稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
1.2 HBase逻辑存储
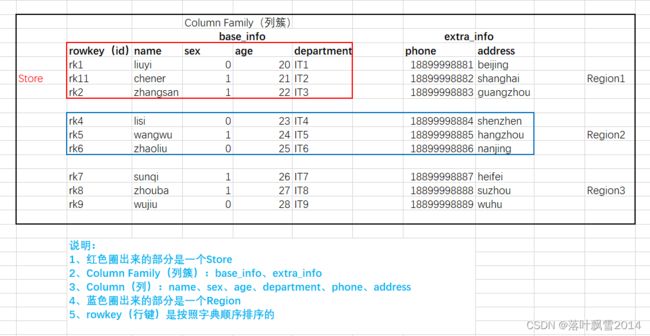

首先,要知道一下,HBase的数据模型其实和关系型数据库类似,数据都是存储在某张表中间,有行也有列的。
从HBase的底层物理存储结构来看,HBase像一个多维的map结构。
高表: 几十亿行
宽表: 几百个列
效率 成本 质量
1.3 HBase物理存储

1.4 HBase中重要的新概念
1.4.1 RowKey(行键)
与 NoSQL 数据库们一样,Rowkey 是用来检索记录的主键。访问 HBase table 中的行,有如下的方式:
1、通过单个 Rowkey 访问
2、通过 Rowkey 的 range
3、全表扫描
Rowkey 行键 (Rowkey)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100byte)。在 HBase 内部,rowkey 保存为字节数组。HBase 会对表中的数据 按照 Rowkey 排序(字典顺序) 。
存储时,数据按照 Rowkey 的字典序(byte order)排序存储。设计 key 时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。
1.4.2 列簇(Column Family)
HBase表中的每个列,都归属与某个列簇。列簇是表的 schema 的一部分(而列限定符不是),必须在使用表之前定义。
列名都以列簇作为前缀。例如 courses:history , courses:math 都属于 courses 这个列簇。
列族越多,在取一行数据时所要参与 IO、搜寻的文件就越多,所以,如果没有必要,不要设置太多的列族。
1.4.3 TimeStamp(时间戳)
HBase 中通过 row 和 columns 确定的为一个存储单元称为 cell。
每个 cell 都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64 位整型。时间戳可以由 HBase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。
时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
每个 cell 中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
1.4.4 Cell
由{rowkey, column( = + ), version} 唯一确定的单元。label其实就是Qualifier
Cell 中的数据是没有类型的,全部是字节码形式存储。 HBase提供了工具类将String、Double、Integer等和字节数据之间来回转换。
1.4.5 NameSpace
命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下可以有多个表。
HBase 有两个自带的命名空间, 分别是 hbase 和 default ,hbase 中存放的是 HBase 内置的表, default 表是用户默认使用的命名空间。
1.4.6 Row
HBase 表中的每行数据都由一个 RowKey 和多个Column(列)组成,数据是按照 RowKey 的字典顺序来进行存储的,并且查询数据时只能根据 RowKey 进行检索,由此可见 RowKey 的设计很重要。
1.4.7 Region
相当于表的切片。类似于关系型数据库的表概念。但是,在HBase中定义表时只需要声明列族即可,不需要声明具体的列。也就是说,往 HBase 写入数据时,字段可以动态的按需指定。与关系型数据库相比,HBase 能够应对字段变更的场景。一个表的数据到10g的数据时候开始切,其实刚开开始的时候就一个Region。
1.4.8 Column
HBase 中的每个列都由Column Family (列簇)和Column Qualifier (列限定符)进行限定,例如 info:name , info:age。建表的时候只需指明列簇,而列限定符不需要提前定义。
1.5 先看一个简易版的架构
简易版架构
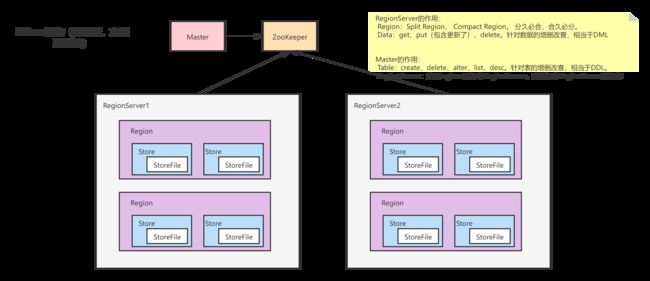
RegionServer的作用:
Region:Split Region, Compact Region。 分久必合,合久必分。
Data:get、put(包含更新了)、delete。针对数据的增删改查,相当于DML
Master的作用:
Table:create、delete、alter、list、desc。针对表的增删改查,相当于DDL。
RegionServer:分配regions到每个RegionServer,监控每个RegionServer的状态
管理Region的Server
第二章 HBase安装部署
2.1 HBase1.3.1集群搭建
注意安装hbase集群之前一定要保证hadoop集群没有问题,安装之前给所有节点上运行的集群先停了。
1 在hadoop0上面上传解压重命名
mv hbase-1.3.1-bin.tar.gz /software
cd /software
tar -zxvf hbase-1.3.1-bin.tar.gz
mv hbase-1.3.1 hbase
2 添加环境变量
修改 vi /etc/profile
export HBASE_HOME=/software/hbase
export PATH=.:$PATH:$HBASE_HOME/bin
配置如下图,也可以在一个PATH后面使劲加上所有的大数据文件的bin:

3 修改配置文件
在目录/software/hbase/conf下面
(1)vi hbase-env.sh
export JAVA_HOME=/software/jdk/
export HBASE_MANAGES_ZK=false #可以在命令模式下通过/进行查找
这里false代表的使用的外置的zookeeper,true代表的使用的是hadoop自带的zookeeper
(2)vi hbase-site.xml
注意hdfs://hadoop0:8020/hbase的端口和hadoop保持一致,hadoop没有配置端口默认是8020,配置了一般配置9000端口。
hbase.rootdir
hdfs://hadoop0:8020/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
hadoop0,hadoop1,hadoop2
hbase.zookeeper.property.dataDir
/software/zk
(3)修改regionservers文件(存放的region server的hostname),内容修改为如下:
hadoop1
hadoop2
(4)复制hadoop0中的hbase文件夹到hadoop1、hadoop2中,在hadoop0中执行如下命令
scp -r /software/hbase hadoop1:/software/
scp -r /software/hbase hadoop2:/software/
(5)复制hadoop0中的/etc/profile到hadoop1、hadoop2中,在hadoop1、hadoop2上执行source /etc/profile
scp /etc/profile hadoop1:/etc/
scp /etc/profile hadoop2:/etc/
或者直接修改 vi /etc/profile
export HBASE_HOME=/software/hbase
export PATH=.:$PATH:$HBASE_HOME/bin
4 启动/停止HBase集群
1、在三台服务器上分别使用zkServer.sh start启动ZooKeeper
2、在hadoop0先启动Hadoop
3、启动HBASE
在主节点hadoop0上面启动,进入/software/hbase/bin目录
配置了环境变量可以在任意目录下使用start-hbase.sh都可以启动。
./start-hbase.sh
4、停止
cd $HBASE_HOME/bin
./stop-hbase.sh
5、shell命令验证
在主服务器上面
hbase shell
然后list
quit 或 exit 退出
6、界面化验证
通过浏览器访问:http://hadoop0:16010
原来0.x版本是60010端口

先停止hbase,再停止hadoop,最后停止zkServer
7、各个节点进程
hadoop0:
[root@hadoop0 bin]# jps
2498 NameNode
3172 HMaster
2311 QuorumPeerMain
2778 ResourceManager
4751 Jps
hadoop1:
[root@hadoop1 bin]# jps
2640 HRegionServer
2259 DataNode
2454 NodeManager
4042 Jps
2157 QuorumPeerMain
2365 SecondaryNameNode
hadoop2:
[root@hadoop2 bin]# jps
2544 HRegionServer
2146 QuorumPeerMain
2242 DataNode
2360 NodeManager
3897 Jps
其中:
ZooKeeper进程为:QuorumPeerMain
Hadoop进程:NameNode、DataNode、ResourceManager、NodeManager、SecondaryNameNode
HBase进程:HMaster、HRegionServer
2.2 HBase2.3.6 集群搭建
2.3.6 是目前的最新稳定版本 ,仅仅到目前讲课时间。
注意安装hbase集群之前一定要保证hadoop集群没有问题,安装之前给所有节点上运行的集群先停了。
1 在hadoop10上面上传解压重命名
mv hbase-2.3.6-bin.tar.gz /software
cd /software
tar -zxvf hbase-2.3.6-bin.tar.gz
mv hbase-2.3.6 hbase
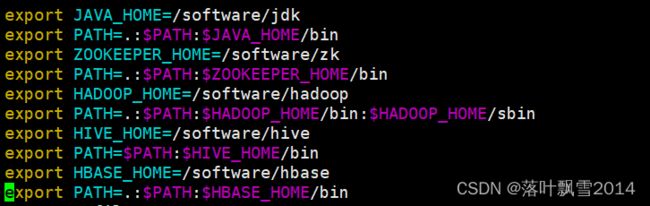
2 添加环境变量
修改 vi /etc/profile
export HBASE_HOME=/software/hbase
export PATH=.:$PATH:$HBASE_HOME/bin
配置如下图,也可以在一个PATH后面使劲加上所有的大数据文件的bin:
3 修改配置文件
在目录/software/hbase/conf下面
(1)vi hbase-env.sh
export JAVA_HOME=/software/jdk/
export HBASE_MANAGES_ZK=false #可以在命令模式下通过/进行查找
这里false代表的使用的外置的zookeeper,true代表的使用的是HBase自带的zookeeper

(2)vi hbase-site.xml
注意hdfs://hadoop10:8020/hbase的端口和hadoop保持一致,hadoop没有配置端口默认是8020,配置了一般配置9000端口。
<property>
<name>hbase.rootdirname>
<value>hdfs://hadoop10:8020/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>hadoop10,hadoop11,hadoop12value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/software/zkvalue>
property>
(3)修改regionservers文件(存放的region server的hostname),内容修改为如下:
hadoop11
hadoop12
(4)复制hadoop10中的hbase文件夹到hadoop11、hadoop12中,在hadoop10中执行如下命令
scp -r /software/hbase hadoop11:/software/
scp -r /software/hbase hadoop12:/software/
(5)修改hadoop11和hadoop12上面的配置文件 vim /etc/profile
export HBASE_HOME=/software/hbase
export PATH=.:$PATH:$HBASE_HOME/bin
最后source /etc/profile
4 启动/停止HBase集群
1、在三台服务器上分别使用zkServer.sh start启动ZooKeeper
2、在hadoop10先启动Hadoop
3、启动HBASE
在主节点hadoop10上面启动,进入/software/hbase/bin目录
配置了环境变量可以在任意目录下使用start-hbase.sh都可以启动。
./start-hbase.sh
4、停止
cd $HBASE_HOME/bin
./stop-hbase.sh
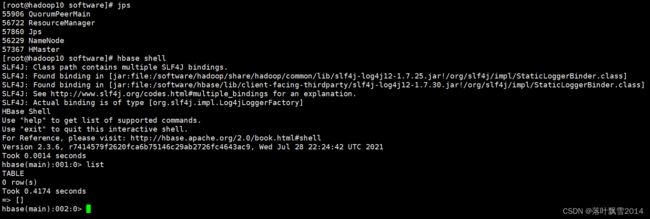
5、shell命令验证
在主服务器上面
hbase shell
然后list
quit 或 exit 退出(不用加分号)
6、界面化验证
通过浏览器访问:http://hadoop10:16010/master-status
原来0.x版本是60010端口
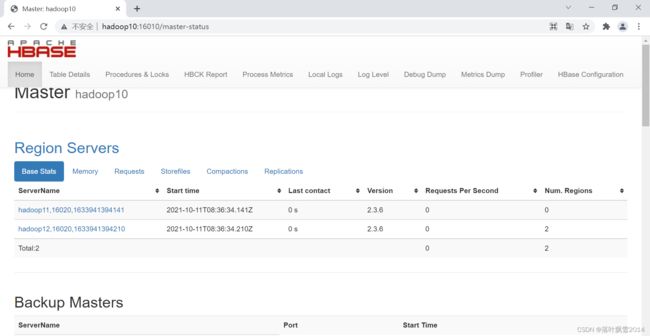
先停止hbase,再停止hadoop,最后停止zkServer
7、各个节点进程
hadoop10:
[root@hadoop10 software]# jps
57681 Jps
55906 QuorumPeerMain
56722 ResourceManager
56229 NameNode
57367 HMaster
hadoop1:
[root@hadoop11 bin]# jps
55587 QuorumPeerMain
56291 HRegionServer
56005 NodeManager
56617 Jps
55758 DataNode
55903 SecondaryNameNode
hadoop2:
[root@hadoop12 bin]# jps
51397 Jps
50471 QuorumPeerMain
50808 NodeManager
50651 DataNode
51087 HRegionServer
其中:
ZooKeeper进程为:QuorumPeerMain
Hadoop进程:NameNode、DataNode、ResourceManager、NodeManager、SecondaryNameNode
HBase进程:HMaster、HRegionServer
第三章 HBase的Shell操作
如果遇到不会的命令,直接使用help查看一下即可。会有案例提示。
hbase(main):080:0> help ‘deleteall’
3.1 小理论
1、进入HBase客户端命令行
bin/hbase shell

2、查看当前数据库中有哪些表
list

3、帮助命令
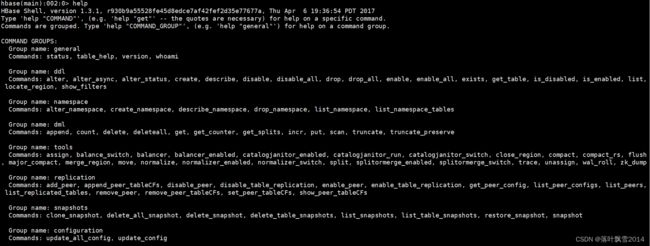
4、创建表
create 'student','info'

5、插入数据到表
put 'student','1001','info:sex','male'
put 'student','1001','info:age','18'
put 'student','1002','info:name','zhangsan'
put 'student','1002','info:sex','female'
put 'student','1002','info:age','20'
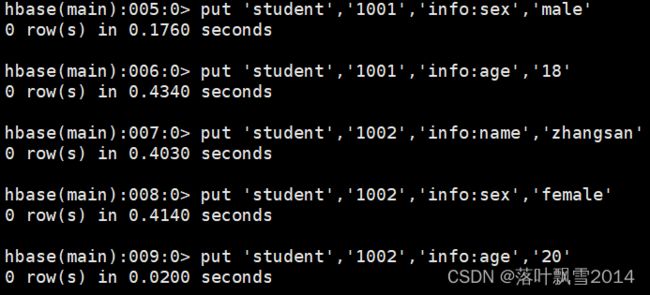
6、查看表数据
scan 'student'

//前闭后开
scan 'student',{STARTROW => '1001', STOPROW => '1002'}

7、查看表结构
describe 'student'
8、修改数据
put 'student','1001','info:name','lisi'
9、删除表
先disable,再drop。
3.2 实际操作(除了put之外的相当于DDL操作)
基本操作
1.进入HBase客户端命令行
bin/hbase shell
2.查看帮助命令
hbase(main):001:0> help
3.查看当前数据库中有哪些表
hbase(main):002:0> list
3.2 表的操作
1.创建表
hbase(main):005:0> create 'student','info'
2.插入数据到表
put 'student3','1001','info:name','zhangsan'
put 'student3','1001','info:sex','male'
put 'student3','1001','info:age','18'
put 'student3','1002','info:name','lisi'
put 'student3','1002','info:sex','female'
put 'student3','1002','info:age','20'
hbase(main):003:0> put 'student','1001','info:sex','male'
hbase(main):004:0> put 'student','1001','info:age','18'
hbase(main):005:0> put 'student','1002','info:name','zhangsan'
hbase(main):006:0> put 'student','1002','info:sex','female'
hbase(main):007:0> put 'student','1002','info:age','20'
3.扫描查看表数据
hbase(main):008:0> scan 'student'
hbase(main):009:0> scan 'student',{STARTROW => '1001', STOPROW => '1002'}
hbase(main):010:0> scan 'student',{STARTROW => '1001'}
4.查看表结构
hbase(main):020:0> describe 'student'
5.更新指定字段的数据
hbase(main):012:0> put 'student','1001','info:name','lisi'
hbase(main):013:0> put 'student','1001','info:age','100'
6.查看“指定行”或“指定列族:列”的数据
hbase(main):014:0> get 'student','1001'
hbase(main):015:0> get 'student','1001','info:name'
7.统计表数据行数
hbase(main):021:0> count 'student'
8.删除数据
删除某rowkey的全部数据:
hbase(main):016:0> deleteall 'student','1001'
删除某rowkey的某一列数据:
hbase(main):017:0> delete 'student','1002','info:sex'
9.清空表数据
hbase(main):018:0> truncate 'student'
提示:清空表的操作顺序为先disable,然后再truncate。
10.删除表
首先需要先让该表为disable状态:
hbase(main):019:0> disable 'student'
然后才能drop这个表:
hbase(main):020:0> drop 'student'
提示:如果直接drop表,会报错:ERROR: Table student is enabled. Disable it first.
11.变更表信息
将info列族中的数据存放3个版本,也就是修改最多保存的版本的个数,注意修改的时候NAME,VERSIONS这些是大小写敏感的:
hbase(main):022:0> alter 'student',{NAME=>'info',VERSIONS=>3}
hbase(main):025:0> describe 'student'
先添加一行,再次测试
hbase(main):005:0> put 'student','1002','info:name','zhangsan'
hbase(main):023:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3}
3.3 关于命名空间NameSpace的操作
hbase(main):035:0> list_namespace
list_namespace list_namespace_tables
hbase(main):035:0> list_namespace
NAMESPACE
default
hbase
2 row(s)
Took 0.0317 seconds
hbase(main):036:0> create_namespace 'ns2'
Took 0.1358 seconds
hbase(main):037:0> list_namespace
NAMESPACE
default
hbase
ns2
3 row(s)
Took 0.0109seconds
hbase(main):038:0> list
TABLE
student
1 row(s)
Took 0.0042 seconds
=> ["student"]
//不能直接切换namespace,想在创建表的时候,直接在前面加上namespace名字即可。
hbase(main):039:0> use 'ns2'
NoMethodError: undefined method `use' for main:Object
hbase(main):040:0> create "ns2:stu","info"
Created table ns2:stu
Took 2.1326 seconds
=> Hbase::Table - ns2:stu
hbase(main):041:0> list
TABLE
student
ns2:stu
2 row(s)
Took 0.0121 seconds
=> ["student", "ns2:stu"]
//删除命名空间,需要先给里面的表disable并删除掉。
hbase(main):042:0> drop_namespace 'ns2'
ERROR: org.apache.hadoop.hbase.constraint.ConstraintException: Only empty namespaces can be removed. Namespace ns2 has 1 tables
at org.apache.hadoop.hbase.master.procedure.DeleteNamespaceProcedure.prepareDelete(DeleteNamespaceProcedure.java:217)
at org.apache.hadoop.hbase.master.procedure.DeleteNamespaceProcedure.executeFromState(DeleteNamespaceProcedure.java:78)
at org.apache.hadoop.hbase.master.procedure.DeleteNamespaceProcedure.executeFromState(DeleteNamespaceProcedure.java:45)
at org.apache.hadoop.hbase.procedure2.StateMachineProcedure.execute(StateMachineProcedure.java:194)
at org.apache.hadoop.hbase.procedure2.Procedure.doExecute(Procedure.java:962)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.execProcedure(ProcedureExecutor.java:1669)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.executeProcedure(ProcedureExecutor.java:1416)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.access$1100(ProcedureExecutor.java:79)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor$WorkerThread.run(ProcedureExecutor.java:1986)
For usage try 'help "drop_namespace"'
Took 0.0439 seconds
hbase(main):043:0> disable 'ns2:stu'
Took 0.3387 seconds
hbase(main):044:0> drop 'ns2:stu'
Took 0.1344 seconds
hbase(main):045:0> drop_namespace 'ns2'
Took 0.1184 seconds
hbase(main):046:0> list_namespace
NAMESPACE
default hbase 2 row(s)
Took 0.0140 seconds
3.4 DML操作
hbase(main):051:0> create 'student','info'
Created table student
Took 2.1402 seconds
=> Hbase::Table - student
hbase(main):052:0> put 'student','1001','info:name','zhangsan'
Took 0.0411 seconds
hbase(main):053:0> scan 'student'
ROW COLUMN+CELL
1001 column=info:name, timestamp=2021-10-12T20:33:17.966, value=zhangsan
1 row(s)
Took 0.0041 seconds
hbase(main):055:0> get 'student','1001'
COLUMN CELL
info:name timestamp=2021-10-12T20:33:17.966, value=zhangsan
1 row(s)
Took 0.0070 seconds
再次多放几条数据进去可以测试使用的。
put 'student','1001','info:sex','male'
put 'student','1001','info:age','18'
put 'student','1002','info:name','zhangsan'
put 'student','1002','info:sex','female'
put 'student','1002','info:age','20'
hbase(main):061:0> scan 'student'
ROW COLUMN+CELL
1001 column=info:age, timestamp=2021-10-12T20:39:38.391, value=18
1001 column=info:name, timestamp=2021-10-12T20:33:17.966, value=zhangsan
1001 column=info:sex, timestamp=2021-10-12T20:39:38.369, value=male
1002 column=info:age, timestamp=2021-10-12T20:39:39.350, value=20
1002 column=info:name, timestamp=2021-10-12T20:39:38.413, value=zhangsan
1002 column=info:sex, timestamp=2021-10-12T20:39:38.443, value=female
2 row(s)
Took 0.0116 seconds
hbase(main):062:0> get 'student','1001'
COLUMN CELL
info:age timestamp=2021-10-12T20:39:38.391, value=18
info:name timestamp=2021-10-12T20:33:17.966, value=zhangsan
info:sex timestamp=2021-10-12T20:39:38.369, value=male
1 row(s)
Took 0.0061 seconds
hbase(main):063:0> get 'student','1001','info:name'
COLUMN CELL
info:name timestamp=2021-10-12T20:33:17.966, value=zhangsan
1 row(s)
Took 0.0065 seconds
hbase(main):064:0> get 'student','1001','info'
COLUMN CELL
info:age timestamp=2021-10-12T20:39:38.391, value=18
info:name timestamp=2021-10-12T20:33:17.966, value=zhangsan
info:sex timestamp=2021-10-12T20:39:38.369, value=male
1 row(s)
Took 0.0067 seconds
hbase(main):065:0>
扫描查看表数据
hbase(main):008:0> scan 'student'
左闭右开
hbase(main):009:0> scan 'student',{STARTROW => '1001', STOPROW => '1002'}
hbase(main):010:0> scan 'student',{STARTROW => '1001'}
下面修改一下数据
put 'student','1002','info:name','zhangsan2'
查看一下修改的最新的数据
hbase(main):067:0> put 'student','1002','info:name','zhangsan2'
Took 0.0068 seconds
hbase(main):068:0> scan 'student'
ROW COLUMN+CELL
1001 column=info:age, timestamp=2021-10-12T20:39:38.391, value=18
1001 column=info:name, timestamp=2021-10-12T20:33:17.966, value=zhangsan
1001 column=info:sex, timestamp=2021-10-12T20:39:38.369, value=male
1002 column=info:age, timestamp=2021-10-12T20:39:39.350, value=20
1002 column=info:name, timestamp=2021-10-12T20:53:40.521, value=zhangsan2
1002
value=female
2 row(s)
Took 0.0075 seconds
除了查看最新的数据,还查看历史的数据
hbase(main):072:0> help "scan"
在 help "scan" 有一个hbase> scan 't1', {RAW => true, VERSIONS => 10} 可以查看最新的10条数据。
操作实践
hbase(main):073:0> scan 'student', {RAW => true, VERSIONS => 10}
ROW COLUMN+CELL
1001 column=info:age, timestamp=2021-10-12T20:39:38.391, value=18
1001 column=info:name, timestamp=2021-10-12T20:33:17.966, value=zhangsan
1001 column=info:sex, timestamp=2021-10-12T20:39:38.369, value=male
1002 column=info:age, timestamp=2021-10-12T20:39:39.350, value=20
1002 column=info:name, timestamp=2021-10-12T20:53:40.521, value=zhangsan2
1002 column=info:name, timestamp=2021-10-12T20:39:38.413, value=zhangsan
1002 column=info:sex, timestamp=2021-10-12T20:39:38.443, value=female
2 row(s)
Took 0.0192 seconds
hbase(main):074:0>
下面删除一下数据
删除某rowkey的全部数据:
hbase(main):016:0> deleteall 'student','1001'
删除某rowkey的某一列数据:
hbase(main):017:0> delete 'student','1002','info:sex'
hbase(main):074:0> delete 'student','1002','info:sex'
Took 0.0095 seconds
hbase(main):075:0> scan 'student', {RAW => true, VERSIONS => 10}
ROW COLUMN+CELL
1001 column=info:age, timestamp=2021-10-12T20:39:38.391, value=18
1001 column=info:name, timestamp=2021-10-12T20:33:17.966, value=zhangsan
1001 column=info:sex, timestamp=2021-10-12T20:39:38.369, value=male
1002 column=info:age, timestamp=2021-10-12T20:39:39.350, value=20
1002 column=info:name, timestamp=2021-10-12T20:53:40.521, value=zhangsan2
1002 column=info:name, timestamp=2021-10-12T20:39:38.413, value=zhangsan
1002 column=info:sex, timestamp=2021-10-12T20:39:38.443, type=Delete
1002 column=info:sex, timestamp=2021-10-12T20:39:38.443, value=female
2 row(s)
Took 0.0115 seconds
你会发现有一个type类型是Delete类型。
hbase(main):076:0> scan 'student'
ROW COLUMN+CELL
1001 column=info:age, timestamp=2021-10-12T20:39:38.391, value=18
1001 column=info:name, timestamp=2021-10-12T20:33:17.966, value=zhangsan
1001 column=info:sex, timestamp=2021-10-12T20:39:38.369, value=male
1002 column=info:age, timestamp=2021-10-12T20:39:39.350, value=20
1002 column=info:name, timestamp=2021-10-12T20:53:40.521, value=zhangsan2
2 row(s)
Took 0.0181 seconds
如果遇到不会的命令,直接使用help查看一下即可。会有案例提示。
hbase(main):080:0> help 'deleteall'
3.5 去Hadoop的页面中去看看hbase的数据
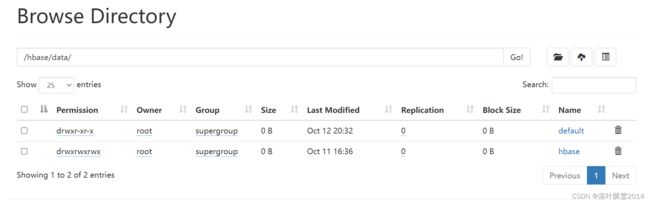
没有指定新的命名空间的情况下,创建的表在default目录下面。
default点击进去之后,可以看到你创建的student表
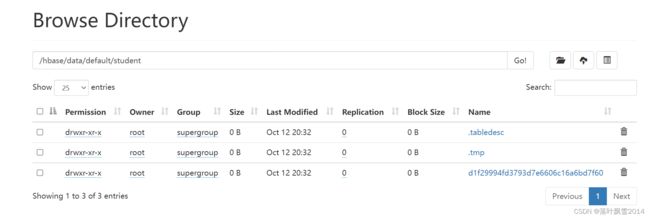
d1f29994fd3793d7e6606c16a6bd7f60其实就是Region的名字。和HBase的页面中显示的是一直的。刚开始就一个Region。

走HDFS页面点击Region的名字进去之后,可以发现info列簇
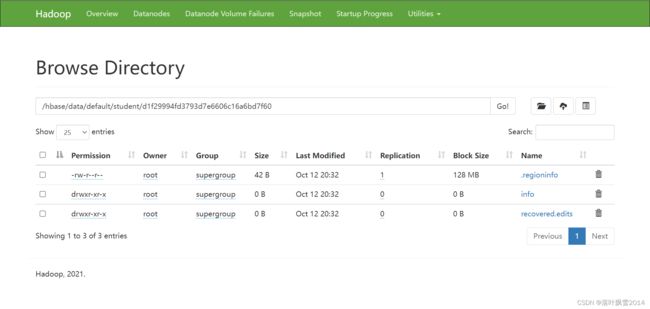
点击Info进去之后,发现空的,这是因为还没有达到刷写到磁盘的条件。这个时候所有的数据还RegionServer的内存中呢。
第四章 HBase的Java API操作
后面放到专门的仓库中
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接