Flink笔记02——单词计数wc和集群部署
前言
在上一篇文章Flink笔记01——入门篇讲述了Flink的一些基础知识后,这篇博客,我们结合日常开发,主要介绍一些Flink的基础编程和框架搭建。
第一个Flink代码
相信学过MR Spark的同学 编写的第一个程序都是单词计数word count,同理 这里南国也是以单词计数作为开始。
开发环境
(由于之前的博客 很多时候忘记描述这个步骤,作为该系列的基础篇,这次尽可能的在每个地方描述细致。)
开发IDE采用的是IDEA,编写代码前 安装好Maven Scala插件,这些准备在IDEA内操作比较简单,不做过多讲述。
这里主要讲述一下配置maven依赖,在pom.xml中配置:
1.7.0
1.8
2.11.0
2.6.0
org.apache.flink
flink-scala_2.11
${flink.version}
org.apache.flink
flink-streaming-scala_2.11
${flink.version}
net.alchim31.maven
scala-maven-plugin
3.4.6
testCompile
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
这里因为我是采用scala编程,因而添加的依赖选择的是相关scala版本的包。如果是选择Java编程,可在Flink官网上查找相关依赖配置。
流计算的demo(也就是上一篇文章 提到的无边界数据)
package com.flink.primary
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* flink 流计算 wc
* @author xjh 2020.4.4
*/
object FlinkStreamingWordCount {
def main(args: Array[String]): Unit = {
//1.初始化flink 流计算的环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.导入隐式转换
import org.apache.flink.streaming.api.scala._
//3.读取数据(这里选择socket数据)
val stream: DataStream[String] = streamEnv.socketTextStream("m1", 8888)
//DataStream类同于sparkStreaming中的DStream
//4.转换和处理数据
val result = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0) //分组算子 0或者1代表前面DataStream的下标,0代表单词 1代表出现的次数
.sum(1) //聚合累加
//5.打印结果
result.print("结果")
//6.启动流计算程序
streamEnv.execute("wordcount")
}
}
代码编写使用的是Scala,注意查看这里的初始化环境是StreamExecutionEnvirment类型,读取数据的类型是DataStream(这个关键词在日后的flink内容会多次看到)
批处理的demo(有边界数据)
package com.flink.primary
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
/**
* Flink 批处理Batch wordcount
*
* @author xjh 2020.4.4
*/
object FlinkBatchWordCount {
def main(args: Array[String]): Unit = {
//1.初始化flink批处理的环境
val environment = ExecutionEnvironment.getExecutionEnvironment
//2.导入隐式转换
import org.apache.flink.streaming.api.scala._
val dataPath = getClass.getResource("/wordcount.txt")
val data: DataSet[String] = environment.readTextFile(dataPath.getPath)
//这里的DataSet类同于Spark中的RDD
//计算并打印结果
data.flatMap(_.split(" ")).map((_, 1))
.groupBy(0)
.sum(1)
.print()
}
}
比较于上一次流计算的demo,这里的初始化环境使用的是ExecutionEnvironment.getExecutionEnvironment,读取数据源的类型是DataSet API,因为是批处理,这里不用启动流处理程序。
需要说明的是,在Flink的应用中 更多的是做流计算,所以我们需要重点关注DataStream API的使用和掌握。
Flink集群的基础架构
Flink 整个系统主要由两个组件组成,分别为JobManager 和TaskManager,Flink 架构也遵循Master-Slave 架构设计原则,JobManager 为Master 节点,TaskManager 为Worker(Slave)节点。所有组件之间的通信都是借助于Akka Framework,包括任务的状态以及Checkpoint 触发等信息。

- Client 客户端
客户端负责将任务提交到集群,与JobManager 构建Akka 连接,然后将任务提交到JobManager,通过和JobManager 之间进行交互获取任务执行状态。客户端提交任务可以采用CLI 方式或者通过使用Flink WebUI 提交,也可以在应用程序中指定JobManager 的RPC网络端口构建ExecutionEnvironment 提交Flink 应用。 - JobManager
JobManager 负责整个Flink 集群任务的调度以及资源的管理,从客户端中获取提交的应用,然后根据集群中TaskManager 上TaskSlot 的使用情况,为提交的应用分配相应的TaskSlots 资源并命令TaskManger 启动从客户端中获取的应用。JobManager 相当于整个集群的Master 节点,且整个集群中有且仅有一个活跃的JobManager,负责整个集群的任务管理和资源管理。JobManager 和TaskManager 之间通过Actor System 进行通信,获取任务执行的情况并通过Actor System 将应用的任务执行情况发送给客户端。同时在任务执行过程
中,Flink JobManager 会触发Checkpoints 操作,每个TaskManager 节点收到Checkpoint触发指令后,完成Checkpoint 操作,所有的Checkpoint 协调过程都是在Flink JobManager中完成。当任务完成后,Flink 会将任务执行的信息反馈给客户端,并且释放掉TaskManager中的资源以供下一次提交任务使用。 - TaskManager
TaskManager 相当于整个集群的Slave 节点,负责具体的任务执行和对应任务在每个节点上的资源申请与管理。客户端通过将编写好的Flink 应用编译打包,提交到JobManager,然后JobManager 会根据已经注册在JobManager 中TaskManager 的资源情况,将任务分配给有资源的TaskManager 节点,然后启动并运行任务。TaskManager 从JobManager 接收需要部署的任务,然后使用Slot 资源启动Task,建立数据接入的网络连接,接收数据并开始数据处理。同时TaskManager 之间的数据交互都是通过数据流的方式进行的。
可以看出,Flink 的任务运行其实是采用多线程的方式,这和MapReduce 多JVM 进程的方式有很大的区别。Fink 能够极大提高CPU 使用效率,在多个任务和Task 之间通过TaskSlot方式共享系统资源,每个TaskManager 中通过管理多个TaskSlot 资源池进行对资源进行有效管理。
Flink的安装部署模式
类似于Spark,Flink的安装部署主要分为本地模式和集群模式。常见的部署模式如下:
- local模式
- Standalone模式
- Flink on Yarn模式
这里有一点说明的是,现在的运用中还有Docker Kubernetes(K8s),不过在日常开发中运用的最多的是Yarn模式,因而关于Docker K8s的部署 暂时不做过多叙述。
local模式
local模式简单,一般用于开发时对代码的测试。部署时只需在主节点上解压安装包就代表成功安装了,在flink安装目录下使用./bin/start-cluster.sh命令,就可以通过master:8081监控集群状态,关闭集群命令:./bin/stop-cluster.sh。
开发者一般使用这种模式的场景 南国觉得大概就是Flink代码在本地IDEA写完之后 直接运行。
Standalone模式
- 进入conf目录下,编辑flink-conf.yaml
jobmanager.rpc.address: m1
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
jobmanager.heap.size: 1024m
# The heap size for the TaskManager JVM
taskmanager.heap.size: 1024m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 3
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
其中,jobmanager.rpc.address: m1表示指定Flink集群的jobmanager的地址是m1;taskmanager.numberOfTaskSlots: 3表示每一个Taskmanager上有3个Slot.
-
编辑master文件
m1:8081 -
编辑slaves文件
m1
m2
m3 -
将修改好的配置分发到另外的服务器节点上
scp -r /home/xjh/bigData/flink-1.7.0 xjh@m2:/home/xjh/bigData/
scp -r /home/xjh/bigData/flink-1.7.0 xjh@m3:/home/xjh/bigData/ -
启动flink集群服务
[xjh@m1 flink-1.7.0]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host m1.
Starting taskexecutor daemon on host m1.
Starting taskexecutor daemon on host m2.
Starting taskexecutor daemon on host m3.
[xjh@m1 flink-1.7.0]$ jps
4728 StandaloneSessionClusterEntrypoint
5274 Jps
5212 TaskManagerRunner
- 访问Flink 的WebUI

网址m1:8081 表示当前flink 集群的jobmanager(master)的主机名和端口号,在这里我们配置的是3个Taskamanager,每个Taskmanager上有3个Slot,即可以运行3个task,所以一共是9个Task Slot. - 提交job到集群上运行
在flink中,提交作业有两种方式:
- Jar包指令上传
首先,打包:

依次对maven项目点击clean complile package,则会在项目的Target中查看到打包后的Jar包:

将Jar包上传到linux中指定的文件路径。
然后,在linux中输入指令:
bin/flink run -d -c com.flink.primary.StreamWordCount /home/xjh/flink-code/Flink-project-1.0-SNAPSHOT.jar
需要说明的是,如果Stream的流数据源是socket,则在在提交Jar包到Flink之前时打开程序中指定的主机和端口号
最后在WebUI上查看job的执行结果


- Jar通过WebUI直接提交
这种方式简单便捷,也是Spark所没有的。

查看job的执行过程和结果同上一种方法类似。
Flink on Yarn模式
这种模式的原理是依靠Yarn来调度Flink任务。这种模式的好处是可以充分利用集群资源,提高集群机器的利用率,并且只需要1 套Hadoop 集群,就可以执行MapReduce 和Spark 任务,还可以执行Flink 任务等,操作非常方便,不
需要维护多套集群,运维方面也很轻松。
Flink on Yarn的内部原理如下图:

- 当启动一个新的Flink YARN Client 会话时,客户端首先会检查所请求的资源(容器和内存)是否可用。之后,它会上传Flink 配置和JAR 文件到HDFS。
- 客户端的下一步是请求一个YARN 容器启动ApplicationMaster 。JobManager 和ApplicationMaster(AM)运行在同一个容器中,一旦它们成功地启动了,AM 就能够知道JobManager 的地址,它会为TaskManager 生成一个新的Flink 配置文件(这样它才能连上JobManager),该文件也同样会被上传到HDFS。另外,AM 容器还提供了Flink 的Web 界面服务。Flink 用来提供服务的端口是由用户和应用程序ID 作为偏移配置的,这使得用户能够并行执行多个YARN 会话。
- 之后,AM 开始为Flink 的TaskManager 分配容器(Container),从HDFS 下载JAR 文件和修改过的配置文件。一旦这些步骤完成了,Flink 就安装完成并准备接受任务了。
这里值得注意的是启动Flink on Yarn模式有两个基础条件:
- 配置Hadoop集群,并成功启动
- Flink的版本必须能和Hadoop兼容。官方的Flink版本从1.7.2之后的安装包都没有明确的指定兼容Hadoop版本号,因而需要下载Flink提交到Hadoop的连接器(Jar包) 如下图所示,并将其拷贝到Flink的lib目录下:

1.7.2及之前的版本在下载时可根据集群上原有的scala版本和hadoop版本下载对应的安装包,下图所示:

Flink在Yarn上使用分为两种模式:
Yarn-Session模式
在Yarn中提前初始化一个Flink集群并开辟指定的资源,之后的Flink任务会提交到这里执行。这个Flink集群会常驻在Yarn集群中,除非开发者手动停止。
缺点:这种模式创建的Flink集群会独占资源,不管是否有Flink任务在执行,Yarn上面的其他任务都无法使用这些资源。

有的资料中会将这种模式称之为内存集中管理模式,大致意思也就是都有启动的Flink Job都在在Flink yarn-session中管理并执行。yarn-session模式的执行概括起来分为两个步骤:yarn-session.sh(开辟资源)+flink run(提交任务)
- 首先启动集群上的Hadoop集群,然后启动一个Flink的yarn-session集群。例如:bin/yarn-session.sh -n 3 -s 3 -nm Fink-project -d
其中yarn-session.sh 后面支持多个参数。下面针对一些常见的参数进行讲解:
-n,--container 表示分配容器的数量(也就是TaskManager 的数量)。
-D 动态属性。
-d,--detached 在后台独立运行。
-jm,--jobManagerMemory :设置JobManager 的内存,单位是MB。
-nm,--name:在YARN 上为一个自定义的应用设置一个名字。
-q,--query:显示YARN 中可用的资源(内存、cpu 核数)。
-qu,--queue :指定YARN 队列。
-s,--slots :每个TaskManager 使用的Slot 数量。
-tm,--taskManagerMemory :每个TaskManager 的内存,单位是MB。
-z,--zookeeperNamespace :针对HA 模式在ZooKeeper 上创建NameSpace。
-id,--applicationId :指定YARN 集群上的任务ID,附着到一个后台独
立运行的yarn session 中。
运行成功后,我们可以在yarn管理的主页查看到该任务成功运行。

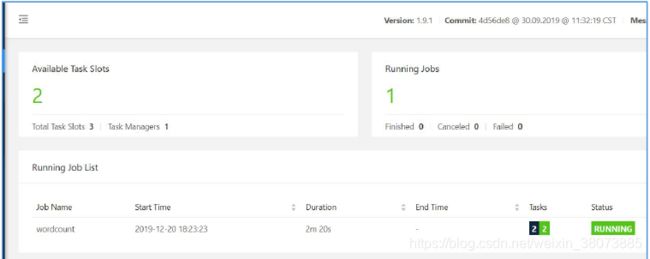
2. 查看Flink的WebUI

因为没有真实提交过Flink job,因而这里的Task slots为0。
3. 提交job到Flink yarn-session,因为有了之前的操作,这里提交Flink 作业时会自动提交到yarn中。
执行命令:bin/flink run -d -c com.flink.primary.StreamWordCount /home/xjh/flink-code/Flink-project-1.0-SNAPSHOT.jar
日志运行中我们可以查看到提供的application id
查看Flink WebUI:
Yarn-Cluster模式
每次提交Flink任务都会创建一个新的Flink集群,每个Flink任务之间相互独立,互不影响。任务执行完成之后创建的Flink集群也会消失。
优点:不会额外占用资源,按需使用Yarn集群的资源,这种方式下资源利用率远高于yarn-session模式,推荐使用这种模式。

yarn-cluster模式也可称为内存job管理模式。这种模式下不需要先启动yarn-session。所以我们可以把前面启动的yarn-session 集群先停止,停止的命令是:
yarn application -kill application_1576832892572_0002
//其中application_1576832892572_0002 是ID
确保Hadoop 集群是健康的情况下直接提交Job 命令:
bin/flink run -m yarn-cluster -yn 3 -ys 3 -ynm bjsxt02 -c
com.bjsxt.flink.StreamWordCount /home/Flink-Demo-1.0-SNAPSHOT.jar
任务提交参数讲解:指定运行模式为yarn-cluster。对比Yarn-Session 参数而言,只是前面加了y。
-yn,--container 表示分配容器的数量,也就是TaskManager 的数量。
-d,--detached:设置在后台运行。
-yjm,--jobManagerMemory:设置JobManager 的内存,单位是MB。
-ytm,--taskManagerMemory:设置每个TaskManager 的内存,单位是MB。
-ynm,--name:给当前Flink application 在Yarn 上指定名称。
-yq,--query:显示yarn 中可用的资源(内存、cpu 核数)
-yqu,--queue :指定yarn 资源队列
-ys,--slots :每个TaskManager 使用的Slot 数量。
-yz,--zookeeperNamespace:针对HA 模式在Zookeeper 上创建NameSpace
-yid,--applicationID : 指定Yarn 集群上的任务ID,附着到一个后台独
立运行的Yarn Session 中。
再次看到yarn的webUI:

Flink的HA
默认情况下,每个Flink 集群只有一个JobManager,这将导致单点故障(SPOF),如
果这个JobManager 挂了,则不能提交新的任务,并且运行中的程序也会失败。使用
JobManager HA,集群可以从JobManager 故障中恢复,从而避免单点故障。用户可以在
Standalone 或Flink on Yarn 集群模式下配置Flink 集群HA(高可用性)。
Standalone 模式下,JobManager 的高可用性的基本思想是,任何时候都有一个Alive
JobManager 和多个Standby JobManager。Standby JobManager 可以在Alive JobManager
挂掉的情况下接管集群成为Alive JobManager,这样避免了单点故障,一旦某一个Standby
JobManager 接管集群,程序就可以继续运行。Standby JobManagers 和Alive JobManager
实例之间没有明确区别,每个JobManager 都可以成为Alive 或Standby。
Flink集群的HA配置
实现HA 还需要依赖ZooKeeper 和HDFS,因此要有一个ZooKeeper 集群和Hadoop 集群,

- 修改配置文件conf/masters
前面的博客,masters我们只指定了m1,这里我们要将所有的节点添加进来。
m1:8081
m2:8081
m3:8081
- 修改conf/flink-conf.yaml
#要启用高可用,设置修改为zookeeper
high-availability: zookeeper
#Zookeeper的主机名和端口信息,多个参数之间用逗号隔开
high-availability.zookeeper.quorum:
m1:2181,m2:2181,m3:2181
# 建议指定HDFS的全路径。如果某个Flink节点没有配置HDFS的话,不指定HDFS的全路径
则无法识到,storageDir存储了恢复一个JobManager所需的所有元数据。
high-availability.storageDir: hdfs://m1:9000/flink/ha
- scp把修改好的配置文件拷贝到其他服务器上
- 启动集群 bin/start-cluster.sh
Flink On Yarn配置
正常基于Yarn 提交Flink 程序,无论是使用yarn-session 模式还是yarn-cluster 模
式, 基于yarn 运行后的application 只要kill 掉对应的Flink 集群进程
“YarnSessionClusterEntrypoint”后,基于Yarn 的Flink 任务就失败了,不会自动进行
重试,所以基于Yarn 运行Flink 任务,也有必要搭建HA,这里同样还是需要借助zookeeper
来完成,步骤如下:
- 修改所有Hadoop节点的yarn-site.xml,将所有Hadoop节点的yarn-site.xml中的提交应用程序的最大尝试次数调大
#在每台hadoop节点yarn-site.xml中设置提交应用程序的最大尝试次数,建议不低于4,这里
重试指的是ApplicationMaster
yarn.resourcemanager.am.max-attempts
4
- 启动Hadoop集群和Zookeeper集群
- 修改Flink对应的flink-conf.yaml配置
#配置依赖zookeeper模式进行HA搭建
high-availability: zookeeper
#配置JobManager原数据存储路径
high-availability.storageDir: hdfs://m1:9000/flink/yarnha/
#配置zookeeper集群节点
high-availability.zookeeper.quorum:
m1:2181,m2:2181,m3:2181
#yarn停止一个application重试的次数
yarn.application-attempts: 10
- 启动yarn-session.sh测试HA:yarn-session.sh -n 2,当然也可以直接提交Job启动之后,可以登录yarn中对应的flink WebUI.
在Flink WebUI中查看JobManager在哪台节点上启动,然后在对应的linux节点上,kill掉对应的“YarnSessionClusterEntrypoint”进程。
最后进入到Yarn中观察应用程序的job信息。点击Job 会发现有对应的重试信息。
Flink并行度和Slot
Flink 中每一个worker(TaskManager)都是一个JVM 进程,它可能会在独立的线程(Solt)
上执行一个或多个subtask。Flink 的每个TaskManager 为集群提供Solt。Solt 的数量通常
与每个TaskManager 节点的可用CPU 内核数成比例,一般情况下Slot 的数量就是每个节点
的CPU 的核数。
Slot 的数量由集群中flink-conf.yaml 配置文件中设置
taskmanager.numberOfTaskSlots 的值为3,这个值的大小建议和节点CPU 的数量保持一致。

关于Slot 和parallelism 的区别,概括如下:
- Slot 是静态的概念,是指TaskManager 具有的并发执行能力。
- parallelism 是动态的概念,是指程序运行时实际使用的并发能力。
- 设置合适的parallelism 能提高运算效率。
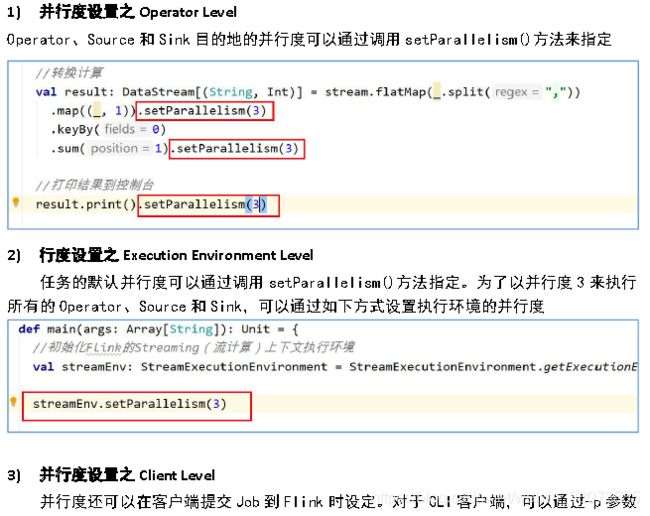
一个任务的并行度设置可以从4 个层面指定:
- Operator Level(算子层面)。
- Execution Environment Level(执行环境层面)。
- Client Level(客户端层面)。
- System Level(系统层面)。
这些并行度的优先级为Operator Level>Execution Environment Level>Client
Level>System Level。



参考资料:
- Flink官网
- 尚学堂Flink教案
- Flink on Yarn的两种模式及HA