Flink之DataStream API(执行环境、数据源、读取kafka)
介绍
Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体,DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。本章主要介绍基本的DataStream API 用法。
DataStream(数据流)本身是 Flink 中一个用来表示数据集合的类(Class),我们编写的Flink 代码其实就是基于这种数据类型的处理,所以这套核心 API 就以 DataStream 命名。对于批处理和流处理,我们都可以用这同一套 API 来实现。
DataStream 在用法上有些类似于常规的 Java 集合,但又有所不同。我们在代码中往往并不关心集合中具体的数据,而只是用 API 定义出一连串的操作来处理它们;这就叫作数据流的“转换”(transformations)。
一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几部分构成
- 获取执行环境(execution environment)
- 读取数据源(source)
- 定义基于数据的转换操作(transformations)
- 定义计算结果的输出位置(sink)
- 触发程序执行(execute)

执行环境
Flink 程序可以在各种上下文环境中运行:我们可以在本地 JVM 中执行程序,也可以提交到远程集群上运行。
不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前 Flink 的运行环境,从而建立起与 Flink 框架之间的联系。只有获取了环境上下文信息,才能将具体的任务调度到不同的 TaskManager 执行。
创建执行环境
- getExecutionEnvironment(推荐使用)
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
这种“智能”的方式不需要我们额外做判断,用起来简单高效,是最常用的一种创建执行环境的方式。 - createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果
不传入,则默认并行度就是本地的 CPU 核心数。 - createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定
要在集群中运行的 Jar 包。
执行模式
- 流处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
这是 DataStream API 最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是 STREAMING 执行模式。
- 批处理
ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();
专门用于批处理的执行模式, 这种模式下,Flink 处理作业的方式类似于 MapReduce 框架。对于不会持续计算的有界数据,我们用这种模式处理会更方便。
什么时候选择 BATCH 模式?
我们知道,Flink 本身持有的就是流处理的世界观,即使是批量数据,也可以看作“有界流”来进行处理。所以 STREAMING 执行模式对于有界数据和无界数据都是有效的;而 BATCH模式仅能用于有界数据。
看起来 BATCH 模式似乎被 STREAMING 模式全覆盖了,那还有必要存在吗?我们能不能所有情况下都用流处理模式呢?
当然是可以的,但是这样有时不够高效。
我们可以仔细回忆一下 word count 程序中,批处理和流处理输出的不同:在 STREAMING模式下,每来一条数据,就会输出一次结果(即使输入数据是有界的);而 BATCH 模式下,只有数据全部处理完之后,才会一次性输出结果。最终的结果两者是一致的,但是流处理模式会将更多的中间结果输出。在本来输入有界、只希望通过批处理得到最终的结果的场景下,STREAMING 模式的逐个输出结果就没有必要了。
所以总结起来,一个简单的原则就是:用 BATCH 模式处理批量数据,用 STREAMING模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候, 我们没得选择——只有 STREAMING 模式才能处理持续的数据流。
当然,在后面的示例代码中,即使是有界的数据源,我们也会统一用 STREAMING 模式处理。这是因为我们的主要目标还是构建实时处理流数据的程序,有界数据源也只是我们用来测试的手段。
触发程序执行
有了执行环境,我们就可以构建程序的处理流程了:基于环境读取数据源,进而进行各种转换操作,最后输出结果到外部系统。
需要注意的是,写完输出(sink)操作并不代表程序已经结束。因为当 main()方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据——因为数据可能还没来。Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”(lazy execution)。
所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
env.execute();
数据源算子
Flink 可以从各种来源获取数据,然后构建 DataStream 进行转换处理。一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。所以,source就是我们整个处理程序的输入端。
Flink 代码中通用的添加 source 的方式,是调用执行环境的 addSource()方法:
DataStream<String> stream = env.addSource(...);
方法传入一个对象参数,需要实现 SourceFunction 接口;返回 DataStreamSource。这里的DataStreamSource 类继承自 SingleOutputStreamOperator 类,又进一步继承自 DataStream。所以很明显,读取数据的 source 操作是一个算子,得到的是一个数据流(DataStream)。
准备工作
创建maven项目,导入依赖
<properties>
<flink.version>1.13.0flink.version>
<java.version>1.8java.version>
<scala.binary.version>2.12scala.binary.version>
<slf4j.version>1.7.30slf4j.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>${slf4j.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>${slf4j.version}version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-to-slf4jartifactId>
<version>2.14.0version>
dependency>
dependencies>
为了更好地理解,我们先构建一个实际应用场景。比如网站的访问操作,可以抽象成一个三元组(用户名,用户访问的 urrl,用户访问 url 的时间戳),所以在这里,我们可以创建一个类 Event,将用户行为包装成它的一个对象。
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "Event{" +
"user='" + user + '\'' +
", url='" + url + '\'' +
", timestamp=" + new Timestamp(timestamp) +
'}';
}
}
这里需要注意,我们定义的 Event,有这样几个特点:
- 类是公有(public)的
- 有一个无参的构造方法
- 所有属性都是公有(public)的
- 所有属性的类型都是可以序列化的
从集合读取数据
最简单的读取数据的方式,就是在代码中直接创建一个 Java 集合,然后调用执行环境的fromCollection 方法进行读取。这相当于将数据临时存储到内存中,形成特殊的数据结构后,作为数据源使用,一般用于测试。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//方式1
ArrayList<Event> clicks = new ArrayList<Event>();
clicks.add(new Event("Mary", "./home", 1000L));
clicks.add(new Event("Bob", "./cart", 2000L));
DataStream<Event> stream = env.fromCollection(clicks);
//方式2
// DataStreamSource stream2 = env.fromElements(
// new Event("Mary", "./home", 1000L),
// new Event("Bob", "./cart", 2000L)
// );
stream.print();
env.execute();
}
从文件读取数据
真正的实际应用中,自然不会直接将数据写在代码中。通常情况下,我们会从存储介质中获取数据,一个比较常见的方式就是读取日志文件。这也是批处理中最常见的读取方式。
DataStream<String> stream = env.readTextFile("clicks.csv");
说明:
- 参数可以是目录,也可以是文件;
- 路径可以是相对路径,也可以是绝对路径;
- 相对路径是从系统属性 user.dir 获取路径: idea 下是 project 的根目录, standalone 模式下是集群节点根目录;
- 也可以从 hdfs 目录下读取, 使用路径 hdfs://…, 由于 Flink 没有提供 hadoop 相关依赖, 需要 pom 中添加相关依赖:
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.5version>
<scope>providedscope>
dependency>
从Socket读取数据
不论从集合还是文件,我们读取的其实都是有界数据。在流处理的场景中,数据往往是无界的。这时又从哪里读取呢?
一个简单的方式,就是我们之前用到的读取 socket 文本流。这种方式由于吞吐量小、稳定性较差,一般也是用于测试。
nc -lk 7777
DataStream<String> stream = env.socketTextStream("localhost", 7777);
从Kafka读取数据(重点)
kafka安装部署,以及测试命令详情请见:https://blog.csdn.net/weixin_47491957/article/details/124319297
那对于真正的流数据,实际项目应该怎样读取呢?
Kafka 作为分布式消息传输队列,是一个高吞吐、易于扩展的消息系统。而消息队列的传输方式,恰恰和流处理是完全一致的。所以可以说 Kafka 和 Flink 天生一对,是当前处理流式数据的双子星。在如今的实时流处理应用中,由 Kafka 进行数据的收集和传输,Flink 进行分析计算,这样的架构已经成为众多企业的首选
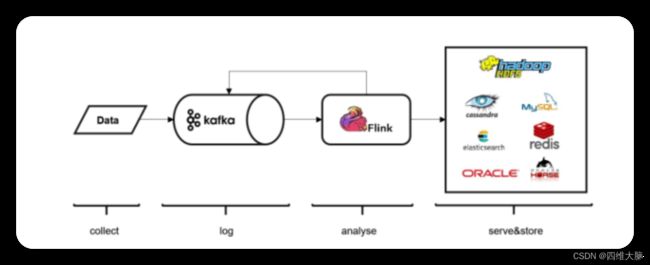
略微遗憾的是,与 Kafka 的连接比较复杂,Flink 内部并没有提供预实现的方法。所以我们只能采用通用的 addSource 方式、实现一个 SourceFunction 了。
好在Kafka与Flink确实是非常契合,所以Flink官方提供了连接工具flink-connector-kafka,直接帮我们实现了一个消费者FlinkKafkaConsumer,它就是用来读取 Kafka 数据的SourceFunction。
所以想要以 Kafka 作为数据源获取数据,我们只需要引入 Kafka 连接器的依赖。Flink 官方提供的是一个通用的 Kafka 连接器,它会自动跟踪最新版本的 Kafka 客户端。目前最新版本只支持 0.10.0 版本以上的 Kafka,读者使用时可以根据自己安装的 Kafka 版本选定连接器的依赖版本。这里我们需要导入的依赖如下。
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class SourceKafkaTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "master:9092"); //kafka地址
properties.setProperty("group.id", "consumer-group"); //消费组
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //key反序列化
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //value反序列化
properties.setProperty("auto.offset.reset", "latest"); //消费偏移从最新开始
DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>("test", new SimpleStringSchema(), properties));
stream.print("Kafka");
env.execute();
}
}
创建 FlinkKafkaConsumer 时需要传入三个参数:
- 第一个参数 topic,定义了从哪些主题中读取数据。可以是一个 topic,也可以是 topic列表,还可以是匹配所有想要读取的 topic 的正则表达式。当从多个 topic 中读取数据时,Kafka 连接器将会处理所有 topic 的分区,将这些分区的数据放到一条流中去。
- 第二个参数是一个 DeserializationSchema 或者 KeyedDeserializationSchema。Kafka 消息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。上面代码中使用的 SimpleStringSchema,是一个内置的 DeserializationSchema,它只是将字节数组简单地反序列化成字符串。DeserializationSchema 和 KeyedDeserializationSchema 是公共接口,所以我们也可以自定义反序列化逻辑。
- 第三个参数是一个 Properties 对象,设置了 Kafka 客户端的一些属性。
启动项目,在启动一个生产者,便可以看到处理结果。
自定义数据源
大多数情况下,前面的数据源已经能够满足需要。但是凡事总有例外,如果遇到特殊情况,我们想要读取的数据源来自某个外部系统,而 flink 既没有预实现的方法、也没有提供连接器,又该怎么办呢?
那就只好自定义实现 SourceFunction 了。
接下来我们创建一个自定义的数据源,实现 SourceFunction 接口。主要重写两个关键方法:run()和 cancel()。
- run()方法:使用运行时上下文对象(SourceContext)向下游发送数据;
- cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Calendar;
import java.util.Random;
public class ClickSource implements SourceFunction<Event> {
// 声明一个布尔变量,作为控制数据生成的标识位
private Boolean running = true;
public void run(SourceContext<Event> sourceContext) throws Exception {
Random random = new Random(); // 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1",
"./prod?id=2"};
while (running) {
sourceContext.collect(new Event(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar.getInstance().getTimeInMillis()
));
// 隔 1 秒生成一个点击事件,方便观测
Thread.sleep(1000);
}
}
public void cancel() {
running = false;
}
}
这个数据源,我们后面会频繁使用,所以在后面的代码中涉及到 ClickSource()数据源,使用上面的代码就可以了。
下面的代码我们来读取一下自定义的数据源。有了自定义的 source function,接下来只要调用 addSource()就可以了:
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SourceCustom {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//有了自定义的 source function,调用 addSource 方法
DataStreamSource<Event> stream = env.addSource(new ClickSource());
stream.print("SourceCustom");
env.execute();
}
}
但是SourceFunction 接口定义的数据源,并行度只能设置为 1,如果数据源设置为大于 1 的并行度,则会抛出异常。
所以如果我们想要自定义并行的数据源的话,需要使用 ParallelSourceFunction
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import java.util.Random;
public class ParallelSourceExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new CustomSource()).setParallelism(2).print();
env.execute();
}
public static class CustomSource implements ParallelSourceFunction<Integer> {
private boolean running = true;
private Random random = new Random();
public void run(SourceContext<Integer> sourceContext) throws Exception {
while (running) {
sourceContext.collect(random.nextInt());
Thread.sleep(1000);
}
}
public void cancel() {
running = false;
}
}
}
尚硅谷yyds
学习资料来自于尚硅谷:https://www.bilibili.com/video/BV133411s7Sa?p=1