Zookeeper【Curator客户端Java版】从0到1——万字学习笔记
目录
初识Zookeeper
Zookeeper作用
维护配置信息
分布式锁服务
集群管理
生产分布式唯一ID
Zookeeper的设计目标
Zookeeper 工作机制
数据模型
ZooKeeper 命令操作
服务端常用命令
客户端常用命令
ZooKeeper JavaAPI操作
Curator 介绍
Curator API 常用操作
导入依赖
建立连接
创建节点
查询节点
修改节点
删除节点
Watch事件监听
概念
API演示
分布式锁实现
分布式锁概述
ZooKeeper分布式锁原理
编辑
Curator实现分布式锁
API
1. 配置
2. 可重入锁InterProcessMutex
3. 不可重入锁InterProcessSemaphoreMutex
4. 可重入读写锁InterProcessReadWriteLock
5. 联锁InterProcessMultiLock
6. 信号量InterProcessSemaphoreV2
7. 共享计数器
ZooKeeper 集群搭建
选举机制
选举过程
异常情况处理
集群中的角色定位
初识Zookeeper
Zookeeper是一个经典的分布式数据一致性解决方案,致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调存储服务。
-
维护配置信息
-
分布式锁服务
-
集群管理
-
生成分布式唯一ID
Zookeeper作用
维护配置信息
java编程经常会遇到配置项,比如数据库的url、 schema、user和 password等。通常这些配置项我们会放置在配置文件中,再将配置文件放置在服务器上当需要更改配置项时,需要去服务器上修改对应的配置文件。
但是随着分布式系统的兴起,由于许多服务都需要使用到该配置文件,因此有必须保证该配置服务的高可用性(highavailability)和各台服务器上配置数据的一致性。
通常会将配置文件部署在一个集群上,然而一个集群动辄上千台服务器,此时如果再一台台服务器逐个修改配置文件那将是非常繁琐且危险的的操作,因此就需要一种服务,能够高效快速且可靠地完成配置项的更改等操作,并能够保证各配置项在每台服务器上的数据一致性。
zookeeper就可以提供这样一种服务,其使用Zab这种一致性协议来保证一致性。现在有很多开源项目使用zookeeper来维护配置,如在 hbase中,客户端就是连接一个 zookeeper,获得必要的 hbase集群的配置信息,然后才可以进一步操作。还有在开源的消息队列 kafka中,也便用zookeeper来维护 brokers的信息。在 alibaba开源的soa框架dubbo中也广泛的使用zookeeper管理一些配置来实现服务治理。
分布式锁服务
一个集群是一个分布式系统,由多台服务器组成。为了提高并发度和可靠性,多台服务器上运行着同一种服务。当多个服务在运行时就需要协调各服务的进度,有时候需要保证当某个服务在进行某个操作时,其他的服务都不能进行该操作,即对该操作进行加锁,如果当前机器挂掉后,释放锁并 fail over到其他的机器继续执行该服务
集群管理
一个集群有时会因为各种软硬件故障或者网络故障,出现棊些服务器挂掉而被移除集群,而某些服务器加入到集群中的情况,zookeeper会将这些服务器加入/移出的情况通知给集群中的其他正常工作的服务器,以及时调整存储和计算等任务的分配和执行等。此外zookeeper还会对故障的服务器做出诊断并尝试修复。
生产分布式唯一ID
在过去的单库单表型系统中,通常可以使用数据库字段自带的auto_ increment属性来自动为每条记录生成一个唯一的ID。但是分库分表后,就无法在依靠数据库的auto_ Increment属性来唯一标识一条记录了。此时我们就可以用zookeeper在分布式环境下生成全局唯一ID。
Zookeeper的设计目标
zooKeeper致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调服务
高性能
zookeeper将全量数据存储在内存中,并直接服务于客户端的所有非事务请求,尤其用于以读为主的应用场景
高可用
-
zookeeper一般以集群的方式对外提供服务,一般3~5台机器就可以组成一个可用的Zookeeper集群了,每台机器都会在内存中维护当前的服务器状态,井且每台机器之间都相互保持着通信。只要集群中超过一半的机器都能够正常工作,那么整个集群就能够正常对外服务
严格顺序访问
-
对于来自客户端的每个更新请求,
Zookeeper都会分配一个全局唯一的递增编号,这个编号反应了所有事务操作的先后顺序
Zookeeper 工作机制
- Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。也就是说 Zookeeper = 文件系统 + 通知机制。

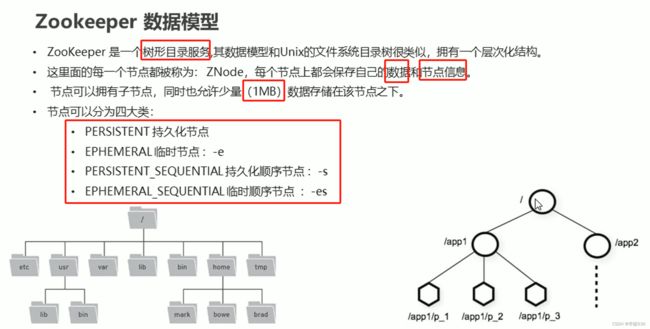
数据模型
ZooKeeper 命令操作
本节主要基于命令行操作Zookeeper
服务端常用命令

客户端常用命令


ZooKeeper JavaAPI操作
Curator 介绍

Curator API 常用操作
注意:如果你采用的是Zookeeper3.5及以上的版本,需要采用的是Curator4.0版本来作为其客户端,对于Zookeeper3.5以下的版本,Curator4.0也兼容,所以无脑4.0
导入依赖
org.apache.curator
curator-framework
4.0.0
org.apache.curator
curator-recipes
4.0.0
建立连接
/**
* 建立连接
*/
@Before
public void testConnect() {
/*
*
* @param connectString 连接字符串。zk server 地址和端口 "192.168.149.135:2181,192.168.149.136:2181"
* @param sessionTimeoutMs 会话超时时间 单位ms
* @param connectionTimeoutMs 连接超时时间 单位ms
* @param retryPolicy 重试策略
*/
/* //重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,10);
//1.第一种方式
CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.149.135:2181",
60 * 1000, 15 * 1000, retryPolicy);*/
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
————————————————————————————————————————————————————————————————————————————————
//2.第二种方式
//CuratorFrameworkFactory.builder();
client = CuratorFrameworkFactory.builder()
.connectString("192.168.149.135:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("itheima") // 设置命名空间,后续创建的节点默认以此为根节点
.build();
//开启连接
client.start();
}
创建节点
题外小知识点:如果我们在Junit单元测试的时候,一个测试方法的需要调用到其他@Test方法来进行初始化 or 资源释放操作,可以通过@Before 和 @After 注解来标注执行该@Test方法前先执行什么方法,后执行什么方法
@Before public void connect(){ 建立连接的逻辑 } @Test public void consum(){ 建立连接后执行的逻辑 } @After public void release(){ 释放连接逻辑 }上述代码,运行consum方法后,他的加载顺序是 connect() ——> consum() ——> release()
/**
* 创建节点:create 持久 临时 顺序 数据
* 1. 基本创建 :create().forPath("")
* 2. 创建节点 带有数据:create().forPath("",data)
* 3. 设置节点的类型:create().withMode().forPath("",data)
* 4. 创建多级节点 /app1/p1 :create().creatingParentsIfNeeded().forPath("",data)
*/
@Test
public void testCreate2() throws Exception {
//1. 基本创建
//如果创建节点,没有指定数据,则默认将当前客户端的ip作为数据存储
String path = client.create().forPath("/app1"); // 这里是在根节点后的节点路径
System.out.println(path);
}
@Test
public void testCreate() throws Exception {
//2. 创建节点 带有数据
//如果创建节点,没有指定数据,则默认将当前客户端的ip作为数据存储
String path = client.create().forPath("/app2", "hehe".getBytes());
System.out.println(path);
}
@Test
public void testCreate3() throws Exception {
//3. 设置节点的类型
//默认类型:持久化
String path = client.create().withMode(CreateMode.EPHEMERAL).forPath("/app3");
System.out.println(path);
}
@Test
public void testCreate4() throws Exception {
//4. 创建多级节点 /app1/p1
//creatingParentsIfNeeded():如果父节点不存在,则创建父节点
String path = client.create().creatingParentsIfNeeded().forPath("/app4/p1");
System.out.println(path);
}
查询节点
/**
* 查询节点:
* 1. 查询数据:get: getData().forPath()
* 2. 查询子节点: ls: getChildren().forPath()
* 3. 查询节点状态信息:ls -s:getData().storingStatIn(状态对象).forPath()
*/
@Test
public void testGet1() throws Exception {
//1. 查询数据:get
byte[] data = client.getData().forPath("/app1");
System.out.println(new String(data));
}
@Test
public void testGet2() throws Exception {
// 2. 查询子节点: ls
List path = client.getChildren().forPath("/"); // 查询整棵树
System.out.println(path);
}
@Test
public void testGet3() throws Exception {
Stat status = new Stat();
System.out.println(status);
//3. 查询节点状态信息:ls -s
client.getData().storingStatIn(status).forPath("/app1");
System.out.println(status);
} 修改节点
/**
* 修改数据
* 1. 基本修改数据:setData().forPath()
* 2. 根据版本修改: setData().withVersion().forPath()
* * version 是通过查询出来的。目的就是为了让其他客户端或者线程不干扰我。
*
* @throws Exception
*/
@Test
public void testSet() throws Exception {
client.setData().forPath("/app1", "itcast".getBytes());
}
@Test
public void testSetForVersion() throws Exception {
Stat status = new Stat();
//3. 查询节点状态信息:ls -s
client.getData().storingStatIn(status).forPath("/app1");
int version = status.getVersion();//查询出来的 3
System.out.println(version);
client.setData().withVersion(version).forPath("/app1", "hehe".getBytes());
}
删除节点
/**
* 删除节点: delete deleteall
* 1. 删除单个节点:delete().forPath("/app1");
* 2. 删除带有子节点的节点:delete().deletingChildrenIfNeeded().forPath("/app1");
* 3. 必须成功的删除:为了防止网络抖动。本质就是重试。 client.delete().guaranteed().forPath("/app2");
* 4. 回调:inBackground
* @throws Exception
*/
@Test
public void testDelete() throws Exception {
// 1. 删除单个节点
client.delete().forPath("/app1");
}
@Test
public void testDelete2() throws Exception {
//2. 删除带有子节点的节点
client.delete().deletingChildrenIfNeeded().forPath("/app4");
}
@Test
public void testDelete3() throws Exception {
//3. 必须成功的删除
client.delete().guaranteed().forPath("/app2");
}
@Test
public void testDelete4() throws Exception {
//4. 回调
client.delete().guaranteed().inBackground(new BackgroundCallback(){
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("我被删除了~");
System.out.println(event);
}
}).forPath("/app1");
}
@After
public void close() {
if (client != null) {
client.close();
}
}
Watch事件监听
概念
Zookeeper的Watch事件监听是一种机制,用于在Zookeeper集群中监视和观察节点状态的变化。当某个节点发生变化时(例如数据内容的更改、节点的创建或删除等),Zookeeper会通知与该节点相关联的应用程序,以便应用程序能够及时作出相应的处理。 Watch事件监听可以帮助应用程序实时感知和处理节点状态的变化,并在节点状态发生变化时触发相应的回调函数或事件处理机制。这种机制使得应用程序能够根据事件的发生而采取适当的行动,从而实现分布式系统中各个节点之间的协调和同步。
Watch事件监听可以类比一下 volatile 关键字修饰的变量的保证多线程可见性的操作
API演示
/**
* 建立连接
*/
@Before
public void testConnect() {
/*
*
* @param connectString 连接字符串。zk server 地址和端口 "192.168.149.135:2181,192.168.149.136:2181"
* @param sessionTimeoutMs 会话超时时间 单位ms
* @param connectionTimeoutMs 连接超时时间 单位ms
* @param retryPolicy 重试策略
*/
/* //重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,10);
//1.第一种方式
CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.149.135:2181",
60 * 1000, 15 * 1000, retryPolicy);*/
//重试策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
//2.第二种方式
//CuratorFrameworkFactory.builder();
client = CuratorFrameworkFactory.builder()
.connectString("192.168.149.135:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("itheima")
.build();
//开启连接
client.start();
}
@After
public void close() {
if (client != null) {
client.close();
}
}
/**
* 演示 NodeCache:给指定一个节点注册监听器
*/
@Test
public void testNodeCache() throws Exception {
//1. 创建NodeCache对象
final NodeCache nodeCache = new NodeCache(client,"/app1");
//2. 注册监听
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("节点变化了~");
//获取修改节点后的数据
byte[] data = nodeCache.getCurrentData().getData();
System.out.println(new String(data));
}
});
//3. 开启监听.如果设置为true,则开启监听是,加载缓冲数据
nodeCache.start(true);
}
/**
* 演示 PathChildrenCache:监听某个节点的所有子节点们
*/
@Test
public void testPathChildrenCache() throws Exception {
//1.创建监听对象
PathChildrenCache pathChildrenCache = new PathChildrenCache(client,"/app2",true);
//2. 绑定监听器
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("子节点变化了~");
System.out.println(event);
//监听子节点的数据变更,并且拿到变更后的数据
//1.获取类型
PathChildrenCacheEvent.Type type = event.getType();
//2.判断类型是否是update
if(type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)){
System.out.println("数据变了!!!");
byte[] data = event.getData().getData();
System.out.println(new String(data));
}
}
});
//3. 开启
pathChildrenCache.start();
}
/**
* 演示 TreeCache:监听某个节点自己和所有子节点们
*/
@Test
public void testTreeCache() throws Exception {
//1. 创建监听器
TreeCache treeCache = new TreeCache(client,"/app2");
//2. 注册监听
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
System.out.println("节点变化了");
System.out.println(event);
}
});
//3. 开启
treeCache.start();
}
分布式锁实现
分布式锁概述
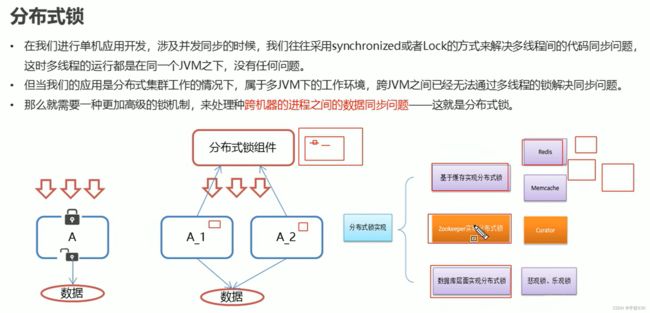

ZooKeeper分布式锁原理
基于节点顺序依次获取锁可见,Zookeeper实现的锁是公平锁
Curator实现分布式锁
API
在Curator中有五种锁方案:
- InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
- InterProcessMutex:分布式可重入排它锁
- InterProcessReadWriteLock:分布式读写锁
- InterProcessMultiLock:将多个锁作为单个实体管理的容器
- InterProcessSemaphoreV2:共享信号量
1. 配置
添加curator客户端配置:
@Configuration
public class CuratorConfig {
@Bean
public CuratorFramework curatorFramework(){
// 重试策略,这里使用的是指数补偿重试策略,重试3次,初始重试间隔1000ms,每次重试之后重试间隔递增。
RetryPolicy retry = new ExponentialBackoffRetry(1000, 3);
// 初始化Curator客户端:指定链接信息 及 重试策略
CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.1.111:2181", retry);
client.start(); // 开始链接,如果不调用该方法,很多方法无法工作
return client;
}
}
2. 可重入锁InterProcessMutex
Reentrant和JDK的ReentrantLock类似, 意味着同一个客户端在拥有锁的同时,可以多次获取,不会被阻塞。它是由类InterProcessMutex来实现。
// 常用构造方法
public InterProcessMutex(CuratorFramework client, String path)
// 获取锁
public void acquire();
// 带超时时间的可重入锁
public boolean acquire(long time, TimeUnit unit);
// 释放锁
public void release();
注意:如想重入,则需要使用同一个InterProcessMutex对象。
3. 不可重入锁InterProcessSemaphoreMutex
具体实现:InterProcessSemaphoreMutex与InterProcessMutex调用方法类似,区别在于该锁是不可重入的,在同一个线程中不可重入。
public InterProcessSemaphoreMutex(CuratorFramework client, String path);
public void acquire();
public boolean acquire(long time, TimeUnit unit);
public void release();
4. 可重入读写锁InterProcessReadWriteLock
类似JDK的ReentrantReadWriteLock。一个拥有写锁的线程可重入读锁,但是读锁却不能进入写锁。这也意味着写锁可以降级成读锁。从读锁升级成写锁是不成的。主要实现类InterProcessReadWriteLock:
// 构造方法
public InterProcessReadWriteLock(CuratorFramework client, String basePath);
// 获取读锁对象
InterProcessMutex readLock();
// 获取写锁对象
InterProcessMutex writeLock();
注意:写锁在释放之前会一直阻塞请求线程,而读锁不会
5. 联锁InterProcessMultiLock
Multi Shared Lock是一个锁的容器。当调用acquire, 所有的锁都会被acquire,如果请求失败,所有的锁都会被release。同样调用release时所有的锁都被release(失败被忽略)。基本上,它就是组锁的代表,在它上面的请求释放操作都会传递给它包含的所有的锁。实现类InterProcessMultiLock:
// 构造函数需要包含的锁的集合,或者一组ZooKeeper的path
public InterProcessMultiLock(List locks);
public InterProcessMultiLock(CuratorFramework client, List paths);
// 获取锁
public void acquire();
public boolean acquire(long time, TimeUnit unit);
// 释放锁
public synchronized void release();
6. 信号量InterProcessSemaphoreV2
一个计数的信号量类似JDK的Semaphore。JDK中Semaphore维护的一组许可(permits),而Cubator中称之为租约(Lease)。注意,所有的实例必须使用相同的numberOfLeases值。调用acquire会返回一个租约对象。客户端必须在finally中close这些租约对象,否则这些租约会丢失掉。但是,如果客户端session由于某种原因比如crash丢掉, 那么这些客户端持有的租约会自动close, 这样其它客户端可以继续使用这些租约。主要实现类InterProcessSemaphoreV2:
// 构造方法
public InterProcessSemaphoreV2(CuratorFramework client, String path, int maxLeases);
// 注意一次你可以请求多个租约,如果Semaphore当前的租约不够,则请求线程会被阻塞。
// 同时还提供了超时的重载方法
public Lease acquire();
public Collection acquire(int qty);
public Lease acquire(long time, TimeUnit unit);
public Collection acquire(int qty, long time, TimeUnit unit)
// 租约还可以通过下面的方式返还
public void returnAll(Collection leases);
public void returnLease(Lease lease);
7. 共享计数器
利用ZooKeeper可以实现一个集群共享的计数器。只要使用相同的path就可以得到最新的计数器值, 这是由ZooKeeper的一致性保证的。Curator有两个计数器, 一个是用int来计数,一个用long来计数。
7.1. SharedCount
共享计数器SharedCount相关方法如下:
// 构造方法
public SharedCount(CuratorFramework client, String path, int seedValue);
// 获取共享计数的值
public int getCount();
// 设置共享计数的值
public void setCount(int newCount) throws Exception;
// 当版本号没有变化时,才会更新共享变量的值
public boolean trySetCount(VersionedValue previous, int newCount);
// 通过监听器监听共享计数的变化
public void addListener(SharedCountListener listener);
public void addListener(final SharedCountListener listener, Executor executor);
// 共享计数在使用之前必须开启
public void start() throws Exception;
// 关闭共享计数
public void close() throws IOException;
ZooKeeper 集群搭建
选举机制
ZooKeeper的选举机制是指在ZooKeeper集群中选择一个节点作为Leader节点的过程。选举机制确保在集群中只有一个节点充当Leader,而其他节点作为Followers来同步数据。
全局唯一标识:每个节点在加入ZooKeeper集群时,会被分配一个全局唯一标识(Zxid),用于标识节点的唯一性和顺序性。这个标识由Leader节点负责分配。

- Server,选举状态
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步leader状态,参与投票。
- LEADING,领导者状态。
选举过程
数据同步
服务器1
服务器1启动,发起投票,投票格式为(Zxid,ServerID),投出的票为(0,1),此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING。
服务器2
服务器2启动,发起投票,投出的票为(0,2),服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ServerID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING。
服务器3
服务器3启动,发起投票,投出的票为(0,3),此时服务器1和服务器2发现服务器3的ServerID比自己目前投票推举的(服务器2)大,更改选票为推举服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING。
服务器4
服务器4启动,发起投票。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING。
服务器5
服务器5启动,同4一样当小弟。
注:Zookeeper集群的中每个服务器的数据都是一致的,除非网络波动极大,才会导致Zxid不一致,故而每个服务器的Zxid一致。如果真的遇到Zxid不一致,那么最大的Zxid的服务器会自动当选leader,如果相当则按照上述规则进行选举。
四、总结
本文介绍了Zookeeper的选举机制,需要注意一下几点:
-
同一集群中Zxid是一致的,除非网络很差。
-
Zookeeper选举成功遵循半数机制,即选票成功超过50%就行。
-
leader故障后会重新按照规则进行选举,优先选择Zxid大的。
异常情况处理
在选举过程中,可能会发生以下异常情况:
- Leader节点失去连接或崩溃:当Leader节点失去连接或崩溃时,其他节点无法接收到Leader的心跳消息,会开始新一轮的选举,选举出新的Leader。
- 拥有最新数据的节点脱离集群:如果一个拥有最新数据的节点脱离了集群,其他节点会将其标记为不可达,并继续选举新的Leader。
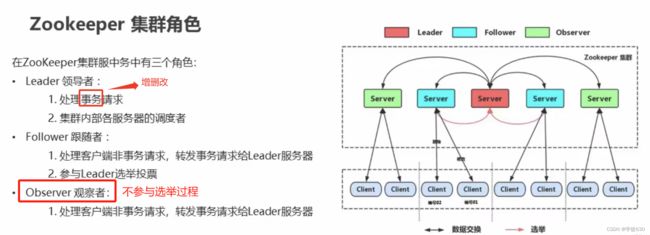
集群中的角色定位