ceph-deploy部署ceph集群
ceph-deploy安装集群
官方文档:
https://ceph.readthedocs.io/en/latest/install/ceph-deploy/quick-start-preflight/
ceph版本列表:
https://ceph.readthedocs.io/en/latest/releases/
节点规划:
| 主机名 | public-ip | cluster-ip | 磁盘 | 角色 |
|---|---|---|---|---|
| ceph-deploy | 192.168.93.60 | 系统盘: sda | ceph-deploy | |
| node01 | 192.168.93.61 | 192.168.94.61 | 系统盘: sda osd盘: sdb、sdc |
monitor,mgr,rgw,mds,osd |
| node02 | 192.168.93.62 | 192.168.94.62 | 系统盘: sda osd盘: sdb、sdc |
monitor,mgr,rgw,mds,osd |
| node03 | 192.168.93.63 | 192.168.94.63 | 系统盘: sda osd盘: sdb、sdc |
monitor,mgr,rgw,mds,osd |
| node04 | 192.168.93.64 | 192.168.94.64 | 系统盘: sda osd盘: sdb、sdc |
osd |
节点角色:
- ceph-deploy:ceph集群部署节点,负责集群整体部署,也可以复用cpeh集群中的节点作为部署节点。
- monitor:Ceph监视管理节点,承担Ceph集群重要的管理任务,一般需要3或5个节点。
- mgr: Ceph 集群管理节点(manager),为外界提供统一的入口。
- rgw: Ceph对象网关,是一种服务,使客户端能够利用标准对象存储API来访问Ceph集群
- mds:Ceph元数据服务器,MetaData Server,主要保存的文件系统服务的元数据,使用文件存储时才需要该组件
- osd:Ceph存储节点Object Storage Daemon,实际负责数据存储的节点。
安装版本:
- ceph版本:nautilus 14.2.9
- deploy版本:ceph-deploy 2.0.1
- Ceph网络:Ceph Cluster网络均采用192.168.93.0/24,Ceph Public网络采用192.168.94.0/24
ceph网络示意图:
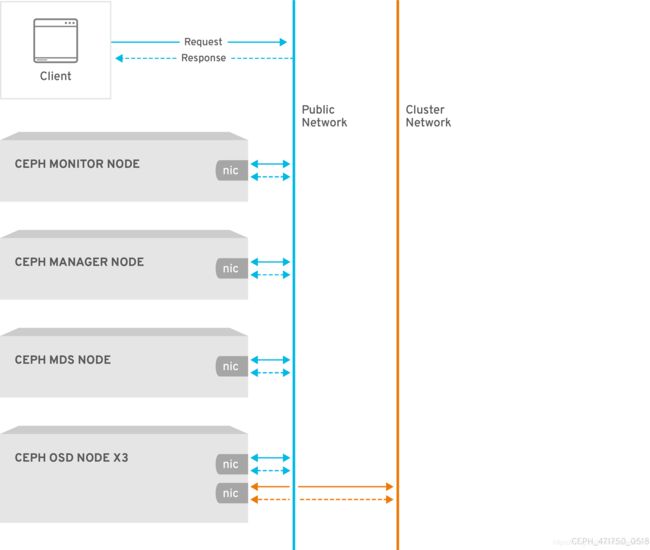
注意:monitor节点也运行osd,因此所有节点2块网卡。
环境初始化
注:如果没有特殊说明,以下所有操作在所有节点上执行。
所有节点配置主机名
hostnamectl set-hostname ceph-deploy
hostnamectl set-hostname node01
hostnamectl set-hostname node02
hostnamectl set-hostname node03
hostnamectl set-hostname node04
配置hosts解析
cat >> /etc/hosts <<EOF
#ceph deploy
192.168.93.60 ceph-deploy
# Ceph Cluster Network
192.168.93.61 node01
192.168.93.62 node02
192.168.93.63 node03
192.168.93.64 node04
# Ceph Public Network
192.168.94.61 node01
192.168.94.62 node02
192.168.94.63 node03
192.168.94.64 node04
EOF
基础配置
#关闭防火墙和selinux
systemctl disable --now firewalld
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
#配置时间同步
yum install -y chrony
systemctl enable --now chronyd
配置yum源
#centos基础源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
#epel源
yum install -y epel-release
#阿里云ceph源,该源指定了ceph安装版本
cat >/etc/yum.repos.d/ceph.repo <<EOF
[Ceph]
name=Ceph packages for \$basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/\$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
EOF
添加节点SSH互信
ssh-keygen -t rsa
ssh-copy-id root@node01
ssh-copy-id root@node02
ssh-copy-id root@node03
ssh-copy-id root@node04
安装ceph-deploy
在ceph-deploy节点执行。默认EPEL源提供的ceph-deploy版本是1.5,务必确保安装版本为2.0.1或之上版本。
yum update -y
yum install -y python-setuptools
yum install -y ceph-deploy
#校验版本
# ceph-deploy --version
2.0.1
初始化Ceph集群
初次运行先使用一个Ceph Monitor和三个Ceph OSD守护进程创建一个Ceph存储集群。集群达到 active + clean状态后,通过添加第四个Ceph OSD守护程序和另外两个Ceph Monitors对其进行扩展。
在管理点上创建一个目录,以维护为集群生成的配置文件和密钥。
mkdir my-cluster
cd my-cluster
ceph-deploy部署程序会将文件输出到当前目录。执行ceph-deploy部署时请确保位于ceph-deploy目录中。
如果想要重新部署,请执行以下操作清除Ceph软件包,并清除其所有数据和配置:
ceph-deploy purge {ceph-node} [{ceph-node}]
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys
rm ceph.*
如果执行purge,则必须重新安装Ceph。最后一个rm命令删除在先前安装过程中由ceph-deploy在本地写出的所有文件。
使用ceph-deploy创建集群
执行下面的命令创建一个Ceph Cluster集群,指定initial-monitor-node为node01:
ceph-deploy new --public-network 192.168.93.0/24 --cluster-network 192.168.94.0/24 node01
这里直接指定cluster-network(集群内部通讯)和public-network(外部访问Ceph集群),也可以在执行命令后修改配置文件方式指定。
检查当前目录中的输出。应该看到一个Ceph配置文件(ceph.conf),一个monitor secret keyring (ceph.mon.keyring)和新集群的日志文件。有关更多详细信息,请参见ceph-deploy new -h。
[root@ceph-deploy my-cluster]# ll
total 12
-rw-r--r-- 1 root root 264 Jun 19 10:54 ceph.conf
-rw-r--r-- 1 root root 3204 Jun 19 10:54 ceph-deploy-ceph.log
-rw------- 1 root root 73 Jun 19 10:54 ceph.mon.keyring
查看ceph配置文件
[root@ceph-deploy my-cluster]# cat ceph.conf
[global]
fsid = 8a23025d-3299-4320-abb9-3de4da949a62
public_network = 192.168.93.0/24
cluster_network = 192.168.94.0/24
mon_initial_members = node01
mon_host = 192.168.93.61
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
安装Ceph包到指定节点,参数–no-adjust-repos是直接使用本地源,不生成官方源。
ceph-deploy install --no-adjust-repos node01 node02 node03 node04
创建第一个monitor
创建监视器,初始化monitor,并收集所有密钥,官方介绍:为了获得高可用性,您应该运行带有至少三个监视器的生产Ceph集群。
ceph-deploy mon create-initial
初始化完毕后会自动生成以下几个文件,这些文件用于后续和Ceph认证交互使用:
[root@ceph-deploy my-cluster]# ll *.keyring
-rw------- 1 root root 113 Jun 19 11:13 ceph.bootstrap-mds.keyring
-rw------- 1 root root 113 Jun 19 11:13 ceph.bootstrap-mgr.keyring
-rw------- 1 root root 113 Jun 19 11:13 ceph.bootstrap-osd.keyring
-rw------- 1 root root 113 Jun 19 11:13 ceph.bootstrap-rgw.keyring
-rw------- 1 root root 151 Jun 19 11:13 ceph.client.admin.keyring
-rw------- 1 root root 73 Jun 19 10:54 ceph.mon.keyring
使用ceph-deploy命令将配置文件和 admin key复制到管理节点和Ceph节点,以便每次执行ceph CLI命令无需指定monitor地址和 ceph.client.admin.keyring。
ceph-deploy admin node01 node02 node03 node04
查看复制的包
[root@ceph-deploy my-cluster]# ssh node01 ls /etc/ceph
ceph.client.admin.keyring
ceph.conf
rbdmap
创建第一个manager
ceph-deploy mgr create node01
添加3个OSD盘
添加3个osd,假设每个节点中都有一个未使用的磁盘/dev/vdb。 确保该设备当前未使用并且不包含任何重要数据。
ceph-deploy osd create --data /dev/sdb node01
ceph-deploy osd create --data /dev/sdb node02
ceph-deploy osd create --data /dev/sdb node03
可以看到ceph将磁盘创建为lvm格式然后加入ceph集群
[root@node01 ceph]# pvs |grep ceph
/dev/sdb ceph-bf950639-fe82-48bd-b1a4-f052d4e36d33 lvm2 a-- <20.00g 0
[root@node01 ceph]# vgs |grep ceph
ceph-bf950639-fe82-48bd-b1a4-f052d4e36d33 1 1 0 wz--n- <20.00g 0
[root@node01 ceph]# lvs | grep ceph
osd-block-b770fa12-8898-49aa-804b-7f4b9da38622 ceph-bf950639-fe82-48bd-b1a4-f052d4e36d33 -wi-ao---- <20.00g
如果直接使用lvm创建OSD,其中–data参数必须为volume_group/lv_name格式,而不是块设备的路径。
检查集群健康状态
[root@node01 ~]# ceph health
HEALTH_OK
[root@node01 ~]# ceph health detail
集群正常应该显示HEALTH_OK,查看集群状态详细信息:
[root@node01 ~]# ceph -s
cluster:
id: 8a23025d-3299-4320-abb9-3de4da949a62
health: HEALTH_OK
services:
mon: 1 daemons, quorum node01 (age 20m)
mgr: node01(active, since 6m)
osd: 3 osds: 3 up (since 4m), 3 in (since 4m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
扩展群集
基本集群启动并运行后,下一步就是扩展集群。然后将Ceph Monitor和Ceph Manager添加到node2,node3以提高可靠性和可用性。
添加Monitors
一个Ceph存储集群至少需要一个Ceph Monitor和Ceph Manager才能运行。为了获得高可用性,Ceph存储群集通常运行多个Ceph Monitor,这样单个Ceph Monitor的故障不会使Ceph存储群集停机。Ceph使用Paxos算法,该算法需要大多数Monitor(即,大于N / 2,其中N是Monitor的数量)才能形成仲裁。Monitor的奇数往往会更好,尽管这不是必需的。
将两个Ceph Monitor添加到集群中:
ceph-deploy mon add node02
ceph-deploy mon add node03
一旦添加了新的Ceph Monitor,Ceph将开始同步Monitor并形成仲裁。可以通过执行以下命令检查仲裁状态:
ceph quorum_status --format json-pretty
说明:当使用多台Monitor运行Ceph时,应在每台Monitor主机上安装和配置NTP。确保Monitor之间时间同步。
添加Managers
Ceph Manager守护程序以 active/standby模式运行。部署其他manager daemons可确保如果一个守护程序或主机发生故障,另一守护程序或主机可以接管而不会中断服务。
执行以下命令添加要部署其他Manager守护程序:
ceph-deploy mgr create node02 node03
在以下输出中可以看到standby Manager:
[root@node01 ~]# ceph -s
cluster:
id: 8a23025d-3299-4320-abb9-3de4da949a62
health: HEALTH_WARN
1 daemons have recently crashed
services:
mon: 3 daemons, quorum node01,node02,node03 (age 6m)
mgr: node01(active, since 6m), standbys: node02, node03
osd: 3 osds: 3 up (since 19m), 3 in (since 19m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
创建rgw实例
要使用 Ceph Object Gateway对象网关组件,必须部署RGW的实例。执行以下操作以创建RGW的新实例:
ceph-deploy rgw create node01 node02 node03
默认情况下,RGW实例将侦听7480端口。可以通过在运行RGW的节点上编辑ceph.conf来更改此端口,如下所示:
[client]
rgw frontends = civetweb port=80
验证rgb,浏览器访问http://192.168.93.61:7480/,输出以下内容
This XML file does not appear to have any style information associated with it. The document tree is shown below.
<ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<Owner>
<ID>anonymous</ID>
<DisplayName/>
</Owner>
<Buckets/>
</ListAllMyBucketsResult>
创建mds实例
在ceph节点执行。
ceph-deploy mds create noe01 node02 node03
查看
[root@node01 ~]# ceph -s
cluster:
id: 8a23025d-3299-4320-abb9-3de4da949a62
health: HEALTH_OK
services:
mon: 3 daemons, quorum node01,node02,node03 (age 26m)
mgr: node01(active, since 47m), standbys: node02, node03
mds: 3 up:standby
osd: 8 osds: 8 up (since 80m), 8 in (since 80m)
rgw: 3 daemons active (node01, node02, node03)
data:
pools: 4 pools, 128 pgs
objects: 190 objects, 1.9 KiB
usage: 8.1 GiB used, 192 GiB / 200 GiB avail
pgs: 128 active+clean
io:
client: 12 KiB/s rd, 0 B/s wr, 11 op/s rd, 7 op/s wr
mds状态
[root@node01 ~]# ceph mds stat
3 up:standby
添加其他osd盘
继续添加节点上剩余的osd磁盘
ceph-deploy osd create --data /dev/sdc node01
ceph-deploy osd create --data /dev/sdc node02
ceph-deploy osd create --data /dev/sdc node03
ceph-deploy osd create --data /dev/sdb node04
ceph-deploy osd create --data /dev/sdc node04
通过ceph osd tree查看osd的列表情况,可以清晰看到osd在对应node节点,以及当前状态:
[root@node01 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.19513 root default
-3 0.04878 host node01
0 hdd 0.01949 osd.0 up 1.00000 1.00000
3 hdd 0.02930 osd.3 up 1.00000 1.00000
-5 0.04878 host node02
1 hdd 0.01949 osd.1 up 1.00000 1.00000
4 hdd 0.02930 osd.4 up 1.00000 1.00000
-7 0.04878 host node03
2 hdd 0.01949 osd.2 up 1.00000 1.00000
5 hdd 0.02930 osd.5 up 1.00000 1.00000
-9 0.04878 host node04
6 hdd 0.01949 osd.6 up 1.00000 1.00000
7 hdd 0.02930 osd.7 up 1.00000 1.00000
配置删除pool权限
默认创建pool无法执行删除操作,需要执行以下配置
[root@ceph-deploy my-cluster]# cat ceph.conf
...
[mon]
mon_allow_pool_delete = true
更新配置到所有节点
cd /etc/ceph
ceph-deploy --overwrite-conf config push node01 node02 node03 node04
各个节点重启monitor服务
systemctl restart ceph-mon.target