flink 自定义多并发度 elasticsearch source连接器
前言
目前flink 是没有es source flink 通过sql方式读取es中的数据需要自定义es source

参考
1.官网:User-defined Sources & Sinks | Apache Flink
2.博客:Flink自定义实现ElasticSearch Table Source_不会心跳的博客-CSDN博客
flink1.13 elasticsearch 7.5.1
步骤
1.自定义Dynamic Table Factories ESSqlFactory 继承DynamicTableSourceFactory类
自定义source 名字为:elasticsearch-source factoryIdentifier 方法中定义
package com.tang.elasticsearch.source;
/**
* @Description: 工厂类
* @author tang
* @date 2021/11/14 22:05
*/
public class ESSqlFactory implements DynamicTableSourceFactory {
public static final ConfigOption HOSTS= ConfigOptions.key("hosts").stringType().noDefaultValue();
public static final ConfigOption USERNAME = ConfigOptions.key("username").stringType().noDefaultValue();
public static final ConfigOption PASSWORD = ConfigOptions.key("password").stringType().noDefaultValue();
public static final ConfigOption INDEX = ConfigOptions.key("index").stringType().noDefaultValue();
public static final ConfigOption DOCUMENT_TYPE = ConfigOptions.key("document-type").stringType().noDefaultValue();
public static final ConfigOption FORMAT = ConfigOptions.key("format").stringType().noDefaultValue();
public static final ConfigOption FETCH_SIZE = ConfigOptions.key("fetch_size").intType().noDefaultValue();
/**
* @Description: 连接器名称
* @author tang
* @date 2021/11/1 23:15
*/
@Override
public String factoryIdentifier() {
return "elasticsearch-source";
}
/**
* @Description: 必须参数
* @author tang
* @date 2021/11/14 22:05
*/
@Override
public Set> requiredOptions() {
final Set> options = new HashSet<>();
options.add(HOSTS);
options.add(INDEX);
options.add(USERNAME);
options.add(PASSWORD);
options.add(FactoryUtil.FORMAT);
// use pre-defined option for format
return options;
}
/**
* @Description: 可选参数
* @author tang
* @date 2021/11/14 22:04
*/
@Override
public Set> optionalOptions() {
final Set> options = new HashSet<>();
options.add(FORMAT);
options.add(FETCH_SIZE);
options.add(DOCUMENT_TYPE);
return options;
}
public DynamicTableSource createDynamicTableSource(Context context) {
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// 获取解码器
final DecodingFormat> valueFormat =
(DecodingFormat)helper.discoverOptionalDecodingFormat(
DeserializationFormatFactory.class, FactoryUtil.FORMAT).orElseGet(() -> {
return helper.discoverDecodingFormat(DeserializationFormatFactory.class, KafkaOptions.VALUE_FORMAT);
});
final DecodingFormat> decodingFormat = helper.discoverDecodingFormat(
DeserializationFormatFactory.class, FactoryUtil.FORMAT);
helper.validate();
final ReadableConfig options = helper.getOptions();
final String hosts = options.get(HOSTS);
final String username = options.get(USERNAME);
final String password = options.get(PASSWORD);
final String index = options.get(INDEX);
final String document_type = options.get(DOCUMENT_TYPE);
Integer fetch_size = options.get(FETCH_SIZE);
//...
final DataType producedDataType = context.getCatalogTable().getSchema().toPersistedRowDataType();
return new ESDynamicTableSource(hosts, username, password,index,document_type,fetch_size,valueFormat, producedDataType);
}
}
2.自定义Dynamic Table Source ESDynamicTableSource 继承 ScanTableSource类
根据Scan Table Source 和 Lookup Table Source 特点选择需要继承的类

代码:
package com.tang.elasticsearch.source;
/**
* @Description: 动态table source
* @author tang
* @date 2021/11/14 22:06
*/
public class ESDynamicTableSource implements ScanTableSource {
private final String hosts;
private final String username;
private final String password;
private final String index;
private final String document_type;
private Integer fetch_size;
//...
private final DecodingFormat> decodingFormat;
private final DataType producedDataType;
public ESDynamicTableSource(String hosts,
String username,
String password,
String index,
String document_type,
Integer fetch_size,
DecodingFormat> decodingFormat,
DataType producedDataType) {
this.hosts = hosts;
this.username = username;
this.password = password;
this.index = index;
this.document_type = document_type;
//...
this.decodingFormat = decodingFormat;
this.producedDataType = producedDataType;
this.fetch_size = fetch_size;
}
@Override
public ChangelogMode getChangelogMode() {
return decodingFormat.getChangelogMode();
}
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
final DeserializationSchema deserializer = decodingFormat.createRuntimeDecoder(
runtimeProviderContext,
producedDataType);
final SourceFunction sourceFunction = new ESSourceFunction(
hosts, username, password,index,document_type,fetch_size,deserializer);
return SourceFunctionProvider.of(sourceFunction, false);
}
@Override
public DynamicTableSource copy() {
return new ESDynamicTableSource(hosts, username, password,index,document_type,fetch_size,decodingFormat,producedDataType);
}
@Override
public String asSummaryString() {
return "elastic Table Source";
}
} 3.自定义SourceFunction 继承 RichSourceFunction 或RichParallelSourceFunction 函数
注意 RichSourceFunction 函数是单并行度的,RichParallelSourceFunction 是多并行度的
这里选择继承 RichParallelSourceFunction 并实现 run open close 方法


实现多并行度的原理是 获取当前任务的 并行度和 当前subTask的编号,如并行度为18 则subTaskIndex 为 0-17
RuntimeContext runtimeContext = getRuntimeContext();
subTaskIndex = runtimeContext.getIndexOfThisSubtask();
parallelNum = runtimeContext.getNumberOfParallelSubtasks();page % parallelNum != subTaskIndex 遍历每页 每个subTask 只读取除以并行度 余数等于自身subTaskIndex 的页数 需要查询时无数据写入
我的需求是查询60天前某个索引的数据,故满足需求,更好多并行度下切分数据可以参考cdc连接器
完整代码如下:
package com.tang.elasticsearch.source;
/**
* @Description: 查询函数
* @author tang
* @date 2021/11/14 22:11
*/
public class ESSourceFunction extends RichParallelSourceFunction implements ResultTypeQueryable {
Logger logger = LoggerFactory.getLogger(ESSourceFunction.class);
private final String hosts;
private final String username;
private final String password;
private final String index;
private final String document_type;
private Integer fetch_size;
//...
private final DeserializationSchema deserializer;
private volatile boolean isRunning = true;
private RestClient client;
private int subTaskIndex = 0;
private int parallelNum = 0;
private Long total;
private Long totalPage;
private int retryTime = 3;
public ESSourceFunction(String hosts, String username, String password, String index, String document_type, Integer fetch_size, DeserializationSchema deserializer) {
this.hosts = hosts;
this.username = username;
this.password = password;
this.index = index;
this.document_type = document_type;
this.fetch_size = fetch_size;
//...
this.deserializer = deserializer;
}
/**
* @Description: 支持多并行度,多并行度的核心是
* @author tang
* @date 2021/11/1 23:16
*/
@Override
public TypeInformation getProducedType() {
return deserializer.getProducedType();
}
@Override
public void run(SourceContext ctx) throws Exception {
if (fetch_size == null) {
fetch_size = 1000;
}
logger.info("subTask:{} es source function current task index:{} parallelNum:{}", subTaskIndex, subTaskIndex, parallelNum);
// 数据源获取
try {
logger.info("subTask:{} step1:es source function start execute hosts:{} index:{} document_type:{} fetch_size:{}",
subTaskIndex, hosts, index, document_type, fetch_size);
// 修改索引配置 可以查询超10000
Request settingRequest = new Request("PUT", "/" + index + "/_settings");
String json = "{\"max_result_window\":\"2147483647\"}";
settingRequest.setJsonEntity(json);
client.performRequest(settingRequest);
logger.info("subTask:{} step2:es source function put settings set max_result_window success ", subTaskIndex);
// 初始化分页
initPage();
logger.info("subTask:{} step3:es source function get total:{} totalPage:{}", subTaskIndex, total, totalPage);
int from = 0;
int size = fetch_size;
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String startTime = format.format(new Date());
logger.info("subTask:{} step4:es source function execute query start from:{} size:{} ", subTaskIndex, from, size);
SearchHit[] searchHits = null;
Request request = new Request("GET", "/" + index + "/_search");
for (int page = 0; page < totalPage; page++) {
from = (page + 1) * size;
if (!isRunning) {
logger.info("subTask:{} es source function query now is not running break while", subTaskIndex);
cancel();
break;
}
if (page % parallelNum != subTaskIndex) {
continue;
}
logger.info("subTask:{} es source function query current page:{} from:{} size:{}", subTaskIndex, page,from, size);
String queryJson = "{\n" +
" \"query\": {\n" +
" \"match_all\": {}\n" +
" },\n" +
" \"from\":" + from + ",\n" +
" \"size\":" + size + ",\n" +
" \"track_total_hits\":true\n" +
"}";
request.setJsonEntity(queryJson);
Response response = null;
try{
response = client.performRequest(request);
}catch (Exception e){
// 请求报错 间隔3秒重试
logger.error("subTask:{} es source function query request param:{} have error:{}",subTaskIndex,queryJson,e);
Thread.sleep(3000);
logger.error("subTask:{} es source function query sleep 3 s again request param:{}",subTaskIndex,queryJson);
response = client.performRequest(request);
}
String responseBody = EntityUtils.toString(response.getEntity());
Map map = JSONObject.parseObject(responseBody, Map.class);
JSONObject jsonObject = map.get("hits");
if (null == jsonObject) {
continue;
}
JSONArray array = jsonObject.getJSONArray("hits");
List searchList = array.toJavaList(String.class);
if(searchList.size()<=0){
logger.info("subTask:{} es source function query result size less than 0 exit query current from:{} page:{}", subTaskIndex,from,page);
}
searchList.stream().forEach(sourceAsString -> {
if (StringUtils.isBlank(sourceAsString)) {
logger.info("subTask:{} es source function query row is empty:{}", subTaskIndex);
}
Map resultMap = JSONObject.parseObject(sourceAsString, Map.class);
String source = JSONObject.toJSONString(resultMap.get("_source"));
try {
ctx.collect(deserializer.deserialize(source.getBytes()));
} catch (IOException e) {
logger.error("subTask:{} error s source function query ctx collect data:{} have error:{}", subTaskIndex, sourceAsString, ExceptionUtils.getStackTrace(e));
throw new RuntimeException(ExceptionUtils.getStackTrace(e));
}
});
}
String endTime = format.format(new Date());
logger.info("subTask:{} step5:es source function execute query end startTime:{} endTime:{}", subTaskIndex, startTime, endTime);
} catch (Exception e) {
logger.error("subTask:{} error es source function query have error:{}", subTaskIndex, ExceptionUtils.getStackTrace(e));
throw new RuntimeException(ExceptionUtils.getStackTrace(e));
} finally {
logger.info("subTask:{} step6:es source function query end read cancel client:{}..... ", subTaskIndex, client);
cancel();
logger.info("subTask:{} step6:es source function query cancel client success.", subTaskIndex);
}
}
@Override
public void cancel() {
isRunning = false;
try {
logger.info("subTask:{} step6:es source function query end read cancel client:{}..... ", subTaskIndex, client);
if (client != null) {
client.close();
} else {
logger.info("subTask:{} es source function query cancel client but client is null.", subTaskIndex);
}
logger.info("subTask:{} step6:es source function query cancel client success.", subTaskIndex);
} catch (Throwable t) {
logger.error("subTask:{} error es source function cancel client have error:{}", ExceptionUtils.getStackTrace(t), subTaskIndex);
}
}
/**
* @Description: 获取总数
* @author tang
* @date 2021/10/31 16:09
*/
public void initPage() throws IOException {
Request request = new Request("GET", "/" + index + "/_search");
String queryJson = "{\n" +
" \"query\": {\n" +
" \"match_all\": {}\n" +
" },\n" +
" \"track_total_hits\":true\n" +
"}";
request.setJsonEntity(queryJson);
Response response = client.performRequest(request);
String responseBody = EntityUtils.toString(response.getEntity());
Map map = JSONObject.parseObject(responseBody, Map.class);
JSONObject jsonObject = map.get("hits");
if (null == jsonObject) {
total = 0L;
return;
}
total = jsonObject.getJSONObject("total").getLong("value");
totalPage = total % fetch_size == 0 ? total / fetch_size : (total / fetch_size) + 1;
}
/**
* @Description: 初始化客户端
* @author tang
* @date 2021/10/31 16:08
*/
public void initClient() throws Exception {
String[] split = hosts.split(";");
HttpHost[] hosts = new HttpHost[split.length];
for (int i = 0; i < split.length; i++) {
String url = split[i];
String[] s = url.split(":");
String host = s[1].replaceAll("/", "");
int port = Integer.parseInt(s[2]);
String scheme = s[0];
HttpHost httpHost = new HttpHost(host, port, scheme);
hosts[i] = httpHost;
}
//设置密码
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
//设置超时
RestClientBuilder builder = RestClient.builder(hosts).setRequestConfigCallback(new RestClientBuilder.RequestConfigCallback() {
@Override
public RequestConfig.Builder customizeRequestConfig(RequestConfig.Builder requestConfigBuilder) {
requestConfigBuilder.setConnectTimeout(-1);
requestConfigBuilder.setSocketTimeout(-1);
requestConfigBuilder.setConnectionRequestTimeout(-1);
return requestConfigBuilder;
}
}).setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {
httpClientBuilder.disableAuthCaching();
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
});
client = builder.build();
if (client == null) {
logger.error("subTask:{} es source function init client fail");
throw new Exception("subTask:{} es source function init client fail");
}
logger.info("subTask:" + subTaskIndex + " step2:es source function init client success ", subTaskIndex);
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
RuntimeContext runtimeContext = getRuntimeContext();
subTaskIndex = runtimeContext.getIndexOfThisSubtask();
parallelNum = runtimeContext.getNumberOfParallelSubtasks();
// 初始化生成客户端
initClient();
}
@Override
public void close() throws Exception {
logger.info("subTask:{} step6:es source function query close client start.", subTaskIndex);
if (client != null) {
client.close();
}
logger.info("subTask:{} step6:es source function query close client success.", subTaskIndex);
}
}
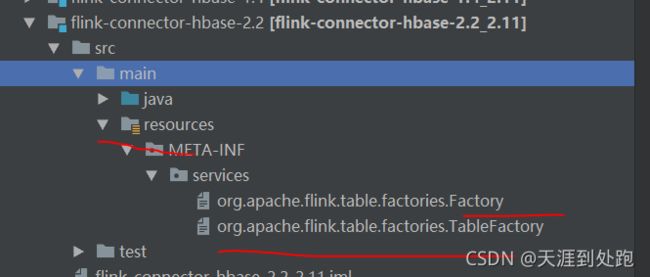
4.配置META-INF 信息
官网中有说要添加META-INF信息

具体怎么加参考源码中hbase的META-INF信息 复制过来修改即可
5.自定义elasticsearch source 使用方式
'connector' = 'elasticsearch-source', elasticsearch-source 为
创建 表 connector 为 elasticsearch-source
CREATE TABLE IF NOT EXISTS flink_es_source_test (
id BIGINT comment 'id',
name STRING comment '',
age BIGINT comment '',
sex STRING comment ''
) WITH (
'connector' = 'elasticsearch-source',
'hosts' = 'http://host1:9200;http://host2:9200;http://host3:9200',
'index' = 'test_20211111',
'username' = 'test',
'password' = '123456',
'format' = 'json'
);
在flink sqlClinet 中执行 select * from flink_es_source_test; 则可以查询es中数据 改变并行度可通过
SET parallelism.default = 18;