Fbank及MFCC学习
Fbank:FilterBank:人耳对声音频谱的响应是非线性的,Fbank就是一种前端处理算法,以类似于人耳的方式对音频进行处理,可以提高语音识别的性能。获得语音信号的fbank特征的一般步骤是:预加重、分帧、加窗、短时傅里叶变换(STFT)、mel滤波、去均值等。对fbank做离散余弦变换(DCT)即可获得mfcc特征。
MFCC(Mel-frequency cepstral coefficients):梅尔频率倒谱系数。梅尔频率是基于人耳听觉特性提出来的, 它与Hz频率成非线性对应关系。梅尔频率倒谱系数(MFCC)则是利用它们之间的这种关系,计算得到的Hz频谱特征。主要用于语音数据特征提取和降低运算维度。例如:对于一帧有512维(采样点)数据,经过MFCC后可以提取出最重要的40维(一般而言)数据同时也达到了降维的目的。
MFCC分析依据的听觉机理有两个:
1. 第一梅尔刻度(Mel scale):人耳感知的声音频率和声音的实际频率并不是线性的,若能将语音信号的频域变换为感知频域中,能更好的模拟听觉过程的处理。
2. 第二临界带(Critical Band):把进入人耳的声音频率用临界带进行划分,将语音在频域上就被划分成一系列的频率群,组成了滤波器组,即Mel滤波器组。
Fbank特征提取流程图

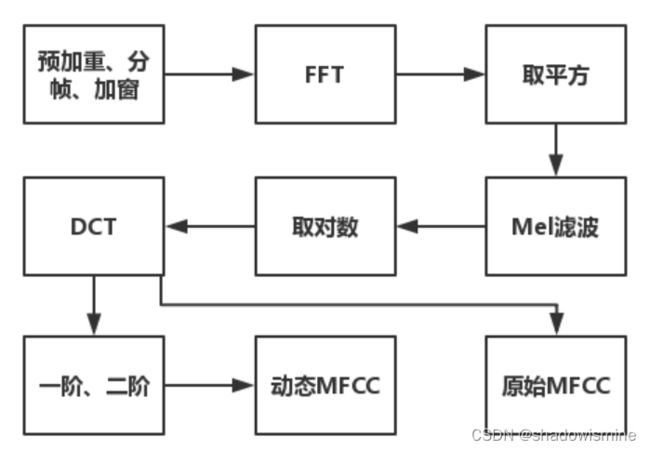
Fbank处理过程
0 读取数据
PCM编码的WAV格式
import numpy as np
from scipy.io import wavfile
from scipy.fftpack import dct
import matplotlib.pyplot as plt
def plot_time(sig, fs):
绘制时域图
time = np.arange(0, len(sig)) * (1.0 / fs)
plt.figure(figsize=(20, 5))
plt.plot(time, sig)
plt.xlabel('Time(s)')
plt.ylabel('Amplitude')#振幅
plt.grid()
def plot_freq(sig, sample_rate, nfft=512):
#绘制频域图
freqs = np.linspace(0, sample_rate/2, nfft//2 + 1)
xf = np.fft.rfft(sig, nfft) / nfft
xfp = 20 * np.log10(np.clip(np.abs(xf), 1e-20, 1e100))#强度
plt.figure(figsize=(20, 5))
plt.plot(freqs, xfp)
plt.xlabel('Freq(hz)')
plt.ylabel('dB')#强度
plt.grid()
def plot_spectrogram(spec, ylabel = 'ylabel'):
#绘制二维数组
fig = plt.figure(figsize=(20, 5))
heatmap = plt.pcolor(spec)
fig.colorbar(mappable=heatmap)
plt.xlabel('Time(s)')
plt.ylabel(ylabel)
plt.tight_layout()
plt.show()
wav_file = 'OSR_us_000_0010_8k.wav'
fs, sig = wavfile.read(wav_file)
#fs是wav文件的采样率,signal是wav文件的内容,filename是要读取的音频文件的路径
sig = sig[0: int(10 * fs)]
保留前10s数据
plot_time(sig, fs)
Time Domain:

Frequency Domain:
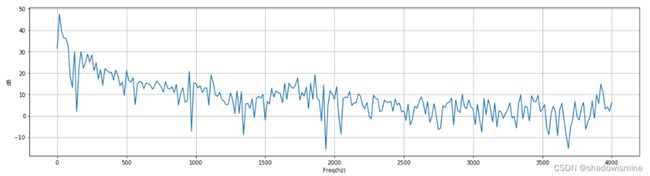
1 预加重
定义:预加重即对语音的高频部分进行加重。
预加重的目的:
- 平衡频谱,因为高频通常与较低频率相比具有较小的幅度,提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的噪声比(SNR)求频谱。
- 也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。
预加重的过程:预加重处理其实是将语音信号通过一个高通滤波器
![]()
其中滤波器系数α的通常为0.95或0.97,这里取pre_emphasis =0.97
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])Time Domain:

Frequency Domain:

2 分帧
目的:
由于语音信号是一个非平稳态过程,不能用处理平稳信号的信号处理技术对其进行分析处理。语音信号是短时平稳信号。因此我们在短时帧上进行傅里叶变换,通过连接相邻帧来获得信号频率轮廓的良好近似。
过程:
为了方便对语音分析,可以将语音分成一个个小段,称之为:帧。先将N个采样点集合成一个观测单位,称为帧。通常情况下N的值为256或512,涵盖的时间约为20~30ms左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3。通常语音识别所采用语音信号的采样频率为8KHz或16KHz,以8KHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000×1000=32ms。简单表述就两点:
- 短时分析将语音流分为一帧来处理,帧长:10~30ms,20ms常见;
- 帧移:STRIDE,0~1/2帧长,帧与帧之间的平滑长度;
def framing(frame_len_s, frame_shift_s, fs, sig):
"""
分帧,主要是计算对应下标
:param frame_len_s: 帧长,s
:param frame_shift_s: 帧移,s
:param fs: 采样率,hz
:param sig: 信号
:return: 二维list,一个元素为一帧信号
"""
sig_n = len(sig)
frame_len_n, frame_shift_n = int(round(fs * frame_len_s)), int(round(fs * frame_shift_s))
num_frame = int(np.ceil(float(sig_n - frame_len_n) / frame_shift_n) + 1)
pad_num = frame_shift_n * (num_frame - 1) + frame_len_n - sig_n # 待补0的个数
pad_zero = np.zeros(int(pad_num)) # 补0
pad_sig = np.append(sig, pad_zero)
#计算下标
#每个帧的内部下标
frame_inner_index = np.arange(0, frame_len_n
分帧后的信号每个帧的起始下标
frame_index = np.arange(0, num_frame) * frame_shift_n
复制每个帧的内部下标,信号有多少帧,就复制多少个,在行方向上进行复制
frame_inner_index_extend = np.tile(frame_inner_index, (num_frame, 1))
各帧起始下标扩展维度,便于后续相加
frame_index_extend = np.expand_dims(frame_index, 1)
分帧后各帧的下标,二维数组,一个元素为一帧的下标
each_frame_index = frame_inner_index_extend + frame_index_extend
each_frame_index = each_frame_index.astype(np.int, copy=False)
frame_sig = pad_sig[each_frame_index]
return frame_sig
frame_len_s = 0.025
frame_shift_s = 0.01
frame_sig = framing(frame_len_s, frame_shift_s, fs, sig)
3 加窗
语音在长范围内是不停变动的,没有固定的特性无法做处理,所以将每一帧代入窗函数,窗外的值设定为0,其目的是消除各个帧两端可能会造成的信号不连续性。
常用的窗函数有方窗、汉明窗和汉宁窗等,根据窗函数的频域特性,常采用汉明窗。
目的:
使全局更加连续,避免出现吉布斯效应;
加窗时,原本没有周期性的语音信号呈现出周期函数的部分特征。
过程:
将信号分割成帧后,我们再对每个帧乘以一个窗函数,如Hamming窗口。以增加帧左端和右端的连续性。抵消FFT假设(数据是无限的),并减少频谱泄漏。汉明窗的形式如下:
![]()
不同的a值会产生不同的汉明窗,一般情况下a取0.46.

#frames *= numpy.hamming(frame_length)
# frames *= 0.54 - 0.46 * numpy.cos((2 * numpy.pi * n) / (frame_length - 1)) # 内部实现
# 加窗
window = np.hamming(int(round(frame_len_s * fs)))
plt.figure(figsize=(20, 5))
plt.plot(window)
plt.grid()
plt.xlim(0, 200)
plt.ylim(0, 1)
plt.xlabel('Samples')
plt.ylabel('Amplitude')
frame_sig *= window
Time Domain:

Frequency Domain:

4 傅里叶变换
目的
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。并对语音信号的频谱取模平方得到语音信号的功率谱。设语音信号的DFT为:
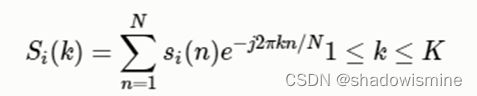
过程:
接我们对分帧加窗后的各帧信号进行做一个N点FFT来计算频谱,也称为短时傅立叶变换(STFT),其中N通常为256或512,NFFT=512;
代码:
mag_frames = numpy.absolute(numpy.fft.rfft(frames, NFFT)) # fft的幅度(magnitude)
5 功率谱(Power Spectrum)
然后我们使用以下公式计算功率谱(周期图periodogram),对语音信号的频谱取模平方(取对数或者去平方,因为频率不可能为负,负值要舍去)得到语音信号的谱线能量。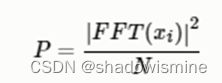
短时傅里叶变换返回的就是功率谱的值
def stft(frame_sig, nfft=512):
"""
:param frame_sig: 分帧后的信号
:param nfft: fft点数
:return: 返回分帧信号的功率谱
np.fft.fft vs np.fft.rfft
fft 返回 nfft
rfft 返回 nfft // 2 + 1,即rfft仅返回有效部分
"""
frame_spec = np.fft.rfft(frame_sig, nfft)
幅度谱
frame_mag = np.abs(frame_spec)
功率谱
frame_pow = (frame_mag ** 2) * 1.0 / nfft
return frame_pow
nfft = 512
frame_pow = stft(frame_sig, nfft)
plt.figure(figsize=(20, 5))
plt.plot(frame_pow[1])
plt.grid()

6 梅尔滤波器组(Filter Banks)
计算Mel滤波器组,将功率谱通过一组Mel刻度(通常取40个滤波器,nfilt=40)的三角滤波器(triangular filters)来提取频带(frequency bands)。
这个Mel滤波器组就像人类的听觉感知系统(耳朵),人耳只关注某些特定的频率分量(人的听觉对频率是有选择性的)。它对不同频率信号的灵敏度是不同的,换言之,它只让某些频率的信号通过,而压根就直接无视它不想感知的某些频率信号。但是这些滤波器在频率坐标轴上却不是统一分布的,在低频区域有很多的滤波器,他们分布比较密集,但在高频区域,滤波器的数目就变得比较少,分布很稀疏。因此Mel刻度的目的是模拟人耳对声音的非线性感知,在较低的频率下更具辨别力,在较高的频率下则不具辨别力。
我们可以使用以下公式在语音频率和Mel频率间转换:

定义一个有M个三角滤波器的滤波器组(滤波器的个数和临界带的个数相近),M通常取22-40,26是标准,本文取nfilt = 40。滤波器组中的每个滤波器都是三角形的,中心频率为f(m) ,中心频率处的响应为1,并向0线性减小,直到达到两个相邻滤波器的中心频率,其中响应为0,各f(m)之间的间隔随着m值的增大而增宽,如图所示:

这可以通过以下等式建模,三角滤波器的频率响应定义为:

三角带通滤波器有两个主要目的:对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。(因此一段语音的音调或音高,是不会呈现在MFCC 参数内,换句话说,以MFCC 为特征的语音辨识系统,并不会受到输入语音的音调不同而有所影响)此外,还可以降低运算量。
计算每个滤波器组输出的对数能量为:

代码和效果:
def mel_filter(frame_pow, fs, n_filter, nfft):
"""
mel 滤波器系数计算
:param frame_pow: 分帧信号功率谱
:param fs: 采样率 hz
:param n_filter: 滤波器个数
:param nfft: fft点数
:return: 分帧信号功率谱mel滤波后的值的对数值
mel = 2595 * log10(1 + f/700) # 频率到mel值映射
f = 700 * (10^(m/2595) - 1 # mel值到频率映射
上述过程本质上是对频率f对数化
"""
mel_min = 0 # 最低mel值
mel_max = 2595 * np.log10(1 + fs / 2.0 / 700) # 最高mel值,最大信号频率为 fs/2
mel_points = np.linspace(mel_min, mel_max, n_filter + 2) # n_filter个mel值均匀分布与最低与最高mel值之间
hz_points = 700 * (10 ** (mel_points / 2595.0) - 1) # mel值对应回频率点,频率间隔指数化
filter_edge = np.floor(hz_points * (nfft + 1) / fs) # 对应到fft的点数比例上
# 求mel滤波器系数
fbank = np.zeros((n_filter, int(nfft / 2 + 1)))
for m in range(1, 1 + n_filter):
f_left = int(filter_edge[m - 1]) # 左边界点
f_center = int(filter_edge[m]) # 中心点
f_right = int(filter_edge[m + 1]) # 右边界点
for k in range(f_left, f_center):
fbank[m - 1, k] = (k - f_left) / (f_center - f_left)
for k in range(f_center, f_right):
fbank[m - 1, k] = (f_right - k) / (f_right - f_center)
# mel 滤波
# [num_frame, nfft/2 + 1] * [nfft/2 + 1, n_filter] = [num_frame, n_filter]
filter_banks = np.dot(frame_pow, fbank.T)
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks)
# 取对数
filter_banks = 20 * np.log10(filter_banks) # dB
return filter_banks
# mel 滤波
n_filter = 40 # mel滤波器个数
filter_banks = mel_filter(frame_pow, fs, n_filter, nfft)
plot_spectrogram(filter_banks.T, ylabel='Filter Banks')
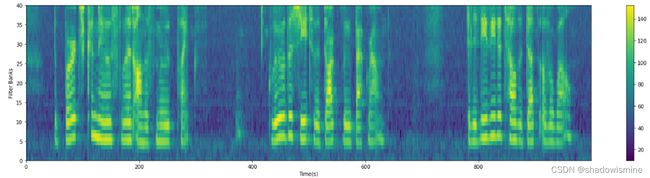
7 梅尔频率倒谱系数(MFCCs)
MFCC实际上就是在Fbank的基础上增加一个离散余弦变换(DCT)。
(a)离散余弦变换(DCT)
离散余弦变换经常用于信号处理和图像处理,用来对信号和图像进行有损数据压缩,这是由于离散余弦变换具有很强的"能量集中"特性:大多数的自然信号(包括声音和图像)的能量都集中在离散余弦变换后的低频部分,实际就是对每帧数据在进行一次降维。
上一步骤中计算的滤波器组系数是高度相关的,这在某些机器学习算法中可能是有问题的。因此,我们可以应用离散余弦变换(DCT)对滤波器组系数去相关处理,并产生滤波器组的压缩表示。通常,对于自动语音识别(ASR),保留所得到的个倒频谱系数2-13,其余部分被丢弃; 我们这里取 num_ceps = 12。丢弃其他的原因是它们代表了滤波器组系数的快速变化,并且这些精细的细节对自动语音识别(ASR)没有贡献。

L阶指MFCC系数阶数,通常取2-13。这里M是三角滤波器个数。
num_ceps = 12
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1:(num_ceps+1)] # 保持在2-13
plot_spectrogram(mfcc.T, 'MFCC Coefficients')
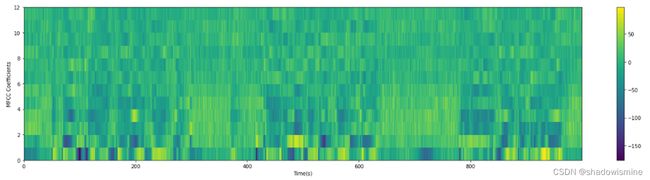
(b)动态差分参数的提取
标准的倒谱参数MFCC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述。实验证明:把动、静态特征结合起来才能有效提高系统的识别性能。
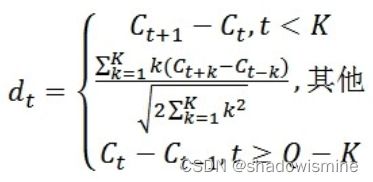
式中,dt表示第t个一阶差分,Ct表示第t个倒谱系数,Q表示倒谱系数的阶数,K表示一阶导数的时间差,可取1或2。将上式的结果再代入就可以得到二阶差分的参数。
MFCC的全部组成其实是由: N维MFCC参数(N/3 MFCC系数+ N/3 一阶差分参数+ N/3 二阶差分参数)+帧能量(此项可根据需求替换)。
这里的帧能量是指一帧的音量(即能量),也是语音的重要特征,而且非常容易计算。因此,通常再加上一帧的对数能量(定义:一帧内信号的平方和,再取以10为底的对数值,再乘以10)使得每一帧基本的语音特征就多了一维,包括一个对数能量和剩下的倒频谱参数。另外,解释下40维是怎么回事,假设离散余弦变换的阶数取13,那么经过一阶二阶差分后就是39维了再加上帧能量总共就是40维,当然这个可以根据实际需要动态调整。
Fbank与mfcc的标准化
其目的是希望减少训练集与测试集之间的不匹配。有三种操作:
1 去均值 (CMN)
为了均衡频谱,提升信噪比,可以做一个去均值的操作
# filter_banks去均值
filter_banks -= (np.mean(filter_banks, axis=0) + 1e-8)
plot_spectrogram(filter_banks.T, ylabel='Filter Banks')
去均值之后的fbank:如下图所示

Fbank与mfcc的比较
Fbank特征更多是希望符合声音信号的本质,拟合人耳的接收特性。
Filter Banks和MFCC对比:
- 计算量:MFCC是在FBank的基础上进行的,所以MFCC的计算量更大
- 特征区分度:FBank特征相关性较高(相邻滤波器组有重叠),MFCC具有更好的判别度,这也是在大多数语音识别论文中用的是MFCC,而不是FBank的原因
- 信息量:FBank特征的提取更多的是希望符合声音信号的本质,拟合人耳接收的特性。MFCC做了DCT去相关处理,因此Filter Banks包含比MFCC更多的信息
- 使用对角协方差矩阵的GMM由于忽略了不同特征维度的相关性,MFCC更适合用来做特征。
- DNN/CNN可以更好的利用Filter Banks特征的相关性,降低损失。
从目前的趋势来看,因为神经网络的逐步发展,FBank特征越来越流行。
上述代码:https://github.com/yifanhunter/audio
参考文献
【1】 https://blog.csdn.net/fengzhonghen/article/details/51722555
【2】MFCC的理解: https://www.cnblogs.com/LXP-Never/p/10918590.html
【3】数据分析图例(代码主要来源于此):https://zhuanlan.zhihu.com/p/130926693
【4】语音: https://zhuanlan.zhihu.com/p/61467187
【5】https://blog.csdn.net/iFlyAI/article/details/108123263