关于Hadoop的杂乱无章(续更)
hadoop
JPS(是jdk的工具):表示查看当前主机有哪些运行的进程
NameNode :表示主节点
DataNode:表示数据节点
SecondaryNameNode :表示次要名称节点
--节点表示:一台机器
进程是运行在机器上的,一个软件可以有多个进程(分布式软件:Hadoop)
HDFS只是Hadoop的一部分,Hadoop还有MR、yarn
HDFS是分布式软件系统:将文件自动分布在三台机器上(副本/备份)
HDFS的特点:
1.可容错:表示你把软件删除了,还可以复原
2,低廉硬件(安装了x86服务器/CPU)
3.高吞吐量(IO):分布多台机器同时处理
4.适用于有超大数据集的应用程序(1G以上大小的表格)
--但是不能满足:update(随机读写),但是可以以流的形式访问文件,提高了性能
---------
POSIX:可移植操作系统接口(是一个规范)
说白就是一个文件系统的接口,ext4、ext3、FAT32、NTFS全部都实现了这个接口,但是功能不一定全部实现
-HDFS框架是有中心的架构
主节点是:NameNode
用于对外(client)通信,通过交换机接收和发送,但是查询到的数据不经过这里直接由DataNode交给client
管理+协调,可以控制其他节点
完成任务(干活节点):DataNode
DataNode之间没有关联,之间的通信也是通过局域网
--实际生产环境中是有多个NameNode
MateData(元数据):元数据就是形容数据的数据
在这里他包含NameSpace:目录结构+blockdata(块数据)
HDFS是分块存储的,块表示一个文件存储在哪台机器上
------------
client(客户端)与NameNode之间是元数据交换
client与DataNode之间是数据交换
在同一个机架上通信快,HDFS会在同一个机架上放两个数据(在两台机器上),在不同的机架上保存一个(备份)
128M是一个block(块)
block就是键值对--映射到内存中就是元数据
key:block的id(哪台机器)-----------value:block的内容地址
--文件越小消耗的内存越大,因为保存相同大小,文件越多分的块越多,映射到内存中的元数据越多
例如:文件1024G,保存1T大小的这样的文件,占用内存8M,磁盘大小是3T
文件1M,保存1pb大小的这样的文件,占用内存1T,磁盘大小是3pb
分块是客户端
客户端将文件分块,串行依次写入,分的块不一定保存在同一台机器上
1.向文件系统(Hadoop集群)中上传文件
hadoop fs -put /abc /
/abc:表示将要上传的文件
/:表示上传到集群中的路径是:/
----------
Fs文件系统----保存file
数据库(DB)----保存表格/table-----存入之后需要经常修改
HDFS---file----crd(没有u不能随机读写,但是能追加),
记住HDFS与数据库无关,HDFS是处理海量数据的,不能经常修改
---
OLTP:在线事务处理(对数据库的写操作)
主要是数据库操作--web网站
特点:实时(立即有效果),处理的数据量小
OLAP:对数据库的读、分析处理
主要是:Hadoop
特点:实时不高,数据量大,HDFS是一次写入多次读取的模式
--元数据:ns(目录结构)+blockMap(文件所在的地址)
Secondary不是NameNode的备份,因为NameNode与Secondary共存亡
他类似于秘书:将内存中的内容持久化
工作:将最近的一个image(存量)与edit—log(增量)合并--生成出最新的image,并将开始的image删除,循环操作
这是因为每写一个文件,都会产生一个edit-log
过程:NameNode将日志+最新的image发送给--Secondary,Secondary将这两个和合并,并删除原来的image,发送给NameNode一个最新的image(这两个是进程之间通信通过Http协议)
--Hadoop中的配置文件
permission权限,false:表示任何人都可以访问,实际生产环境中true
每次格式化,version中的NameSpaceID、clusterID(集群的id)改变了
集群在开启前几分钟会开启安全模式(SafeMode),DataNode向NameNode汇报数据信息,之后自动关闭
50010是集群之间的通信端口号,如果是非知名端口号,防火墙会拦截
hadoop fs -checksum /fileName:校验码,可以查看文件是否被改变(是否成为脏数据)
------mapreduce
hdfs:是分布式存储,可以单独使用
mapreduce是分布式计算,必须按照分布式存储才能分布式计算
map:映射、转化、分
reduce:合并、减少
MR是计算模型:可以并行化处理大量数据(提高效率)
a.并行(事):一件事分成多个快,多个人同时做
b.并发(人):多个人同时做一件事
cdh与hdp是两家最大的hadoop上市公司(在2018年听说要合并)
以后spark(函数式设计语言)会代替mapreduce,因为mapreduce相对于比较慢、难以维护。
-------实际生产中的集群需求:

MapReduce集群搭建
1.yarn环境
在/usr/local/hadoop/etc/hadoop/yarn-env.sh中配置--java安装路径
2.MapReduce配置 IP:8088
将mapred-site.xml.tmplate复制成mapred-site.xml
cp mapred-site.xml.tmplate mapred-site.xml
将mapred-site.xml中添加配置
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
3.yarn配置
在yarn-site.xml中添加配置
yarn.resourcemanager.hostname
master
这里表示yarn存放在master,这里value中的值填什么yarn就在那里
yarn.nodemanager.aux-services
mapreduce_shuffle
--如果不是单机伪分布集群则处理一下操作
4.将etc/hadoop复制到其他节点
5.最终启动
启动
执行start-yarn.sh命令(在这之前确保HDFS已经启动,没有启动的先start-dfs.sh)。
执行成功后,通过JPS检查ResourceManager、NodeManager是否启动。
如果启动成功,通过master:8088可以打开MapReduce“应用”站点:
注意:需要配置本地Windows系统的hosts文件才能在本地使用主机名!

phoenix在测试javaAPI的注意:
(1)插入值如果是字符串要用单引号引起来,切记不能用双引号!!!
(2)表名如果要体现小写效果,必须要用双引号!!!
upsert into "person" values (1, 'test', 100); 正确
upsert into "person" values (1, "test", 100); 错误
HBase的协处理器
过程:
Java写协处理器代码-------打jar包-------上传到hbase/lib目录下-----重启hbase(为了加载jar包)-------在hbase上创建表----为表添加自定义的协处理器(alter ‘tableName’,’coprocessor’ => ‘|classPath|‘)------测试:put数据。
类:将索引放在另一张表中,表也不放在hbase上,放在sole上。
- EndPoint:数据存储过程(hbase的协处理器—现在已经不常用)
存储在mysql中的多条sql语句的集合,执行多条语句,提高性能
但是最致命的缺点是:迁移性差(写的越多,迁移的时候要写的sql语句越多)
b. Observer(触发器):就是在写入数据之前,为表创建二级索引
DML:观察表数据的变化—CURD(增删改查)-----在Observer中RegionObserver
DDL:观察表的元数据变化---创表删表之类-------在Observer中MasterObserver
WAL:写之前记录日志
索引:排序之后的文件---有索引,先读取索引文件,再查询数据内容。(不用全表扫描)
覆盖索引(非主键的索引):增大索引文件,但是读取数据快,也会稍微降低写入数据的速度(以空间换时间)
Hbase本身只有rowKey一个索引。
可以利用phoenix插件可以随意创建二级索引,提高hbase的查询速度;
也可以在写入数据之前对表添加协处理器。
Hbase RowKey设计:
- rowKey的大小:不是很大
长度不宜过长:<=256字节
- rowKey与业务整合:
因为hbase只有rowKey一个索引,创建的时候尽量与业务逻辑整合(就是查询的条件放在rowKey中);为了命中索引,提高查询速度。
- rowKey散列:为了避免写热点
写热点:数据倾斜(数据分布不均匀)
- 加随机前缀(不建议使用)--因为需要另保存前缀用来查询数据
- 加hash前缀(建议使用)--由hash算法就可以取前缀值,用来查询
- 倒叙写入(偷懒式)
比如:1-2018-start--------------àtrats-8102-1
先构造rowKey,再倒序。
正序可能(数据)递增,而导致写热点。
----------libreoffice
下载:
Linux centos
https://donate.libreoffice.org/zh-CN/dl/rpm-x86_64/6.0.6/zh-CN/LibreOffice_6.0.6_Linux_x86-64_rpm.tar.gz
安装:
1.解压文件
2.进入到的RPMS目录
3.yum localinstall *.rpm
文档转换:
word→pdf
libreoffice6.0 --invisible --convert-to pdf some.doc
word→html
libreoffice6.0 --invisible --convert-to html some.doc
或者
soffice --convert-to pdf somedoc
转换(word-->pdf)出现下面错误,请下载插件
yum -y install ibus
[root@master209 local]# libreoffice --invisible --convert-to pdf 1.doc
-bash: libreoffice: command not found
[root@master209 local]# libreoffice6.0 --invisible --convert-to pdf 1.doc
/opt/libreoffice6.0/program/soffice.bin: error while loading shared libraries: libcairo.so.2: cannot open shared object file: No such file or directory
异常处理:
word->pdf时中文乱码
1.打开c盘下的Windows/Fonts目录

2.在这之前我们还需要新建目录,首先在/usr/shared/fonts目录下新建一个目录chinese:
3.然后就是将上面的两个字体上传至/usr/share/fonts/chinese目录下即可
chmod -R 755 /usr/share/fonts/chinese
4.刷新内存中的字体缓存,这样就不用reboot重启了,输入:fc-cache
5.最后再次通过fc-list看一下字体列表:(ps可能我添加的比较多)

卸载libreoffice
yum erase libreoffice\*
--------------kafka
Kafka 消息队列、消息系统、消息中间件、消息的推送口
生产者-----à(中介)ß-------消费者
中间通过TCP通信
中间件的演化:
类---à软件
线程-à进程
Flum中agent表示一个节点(进程)
Kafka中broker表示一个节点(进程)
--特性:分布、可分区、可复制(备份)、顺序读写-速度高
Offset:消费者的(每个分区的)偏移量
Offset是有消费者来维护
Topic:话题—默认是hash分区
每个topic的领导者是相对的
一条数据(一个分区)可以由不同组的多个消费者来消费
有两种模式:排队、订阅
消息队列的种类:
1.ActiceMQ java
2.zero MQ
3.Rabbit MQ
4. Rocket MQ 阿里云开元
5.kafka
以上都是消息队列,都可以相互替换,一般2,3不常用—使用消息队列就是为了解耦
一个分区,一个组 能保证有序性
在0.11之前kafka将元数据保存在zookeeper中
以日志的形式将数据持久化
分区个数 按照kafka集群个数的10倍关系
Kafka中的相关配置
- acks
设置为all:安全,可能数据重复,先复制,再告诉
à-1 提高性能,但是不安全
à1 数据在leader接收之后,立即回复,如果中介机器宕机,可能丢失
16kb----批量发送的单位
Batch(缓冲区-一次发送的数据)与linger(间隔)满足之一、都会发送
Kafka---à发送的是json字符串
Enable.auto.commit--àtrue 自动提交
消费者取出之后就告诉别人消费过了,消费者还没有消费就告诉,如果中间shutdown了,数据就丢失。
防止数据重复与数据丢失---偏移量问题
幂等(事务控制)+手动
Auto.offset.reset---àearliest(最早) 有--(上次) 无---(从头)
-àbest (最近) 数据丢失
-ànone 测试用
---------------------spark
spark.streaming._ 实时处理数据
localhost:4040
storm与stream的区别:
storm:每次处理一条数据,快,但是处理的数据小(吞吐量小)
stream:每次可以快速处理一批数据,特征:high-throughput(高吞吐)、fault-tolerant(可容错)、scalable(可扩展)
配置信息:
streaming至少两个线程
new SparkConf().setMaster("local[*]").setAppName("streaming")
时间用于分割数据:Seconds(5)---5秒
new StreamingContext(conf,Seconds(5))
数据的来源是通过tcp通信获取Datastream
Datastream:表示一系列的rdd
对Dstream做map,就是对每个rdd做map
模拟从tcp端口读取数据
val ds=ssc.socketTextStream("localhost",999)
//启动streaming context,防止没有数据关闭
//如果没有接受导数据,也不会立刻关闭,会尝试一段时间强制关闭
ssc.start()
ssc.awaitTermination()
--------------------------mobaxterm配置
Settings
Configuration
Terminal
勾选 Paste using right-click(左键选取,松开左键复制,右键粘贴, 可以使用Ctrl+右键来使用右键功能)
SSH
取消勾选 Automatically switch to SSH-browser tab after login(登录后自动切换到SFTP浏览器)
勾选 SSH keepalive(保持心跳连接不断)------
命令 hadoop dfsadmin -safemode get 查看安全模式状态
命令 hadoop dfsadmin -safemode enter 进入安全模式状态
命令 hadoop dfsadmin -safemode leave 离开安全模式
--------------spark中rdd、dataframe、dataset联系与区别
在spark中,RDD、DataFrame、Dataset是最常用的数据类型,本博文给出笔者在使用的过程中体会到的区别和各自的优势
共性:
1、RDD、DataFrame、Dataset全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
2、三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算,极端情况下,如果代码里面有创建、转换,但是后面没有在Action中使用对应的结果,在执行时会被直接跳过,如
| 1 2 3 4 5 6 7 8 |
|
map中的println("运行")并不会运行
3、三者都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
4、三者都有partition的概念,如
| 1 2 3 4 5 6 7 8 |
|
这样对每一个分区进行操作时,就跟在操作数组一样,不但数据量比较小,而且可以方便的将map中的运算结果拿出来,如果直接用map,map中对外面的操作是无效的,如
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
不使用partition时,对map之外的操作无法对map之外的变量造成影响
5、三者有许多共同的函数,如filter,排序等
6、在对DataFrame和Dataset进行操作许多操作都需要这个包进行支持
| 1 2 |
|
7、DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型
DataFrame:
| 1 2 3 4 5 6 7 |
|
为了提高稳健性,最好后面有一个_通配操作,这里提供了DataFrame一个解析字段的方法
Dataset:
| 1 2 3 4 5 6 7 8 |
|
区别:
RDD:
1、RDD一般和spark mlib同时使用
2、RDD不支持sparksql操作
DataFrame:
1、与RDD和Dataset不同,DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值,如
| 1 2 3 4 5 |
|
每一列的值没法直接访问
2、DataFrame与Dataset一般与spark ml同时使用
3、DataFrame与Dataset均支持sparksql的操作,比如select,groupby之类,还能注册临时表/视窗,进行sql语句操作,如
| 1 2 |
|
4、DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
| 1 2 3 4 5 6 |
|
利用这样的保存方式,可以方便的获得字段名和列的对应,而且分隔符(delimiter)可以自由指定
Dataset:
这里主要对比Dataset和DataFrame,因为Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同
DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段
而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
可以看出,Dataset在需要访问列中的某个字段时是非常方便的,然而,如果要写一些适配性很强的函数时,如果使用Dataset,行的类型又不确定,可能是各种case class,无法实现适配,这时候用DataFrame即Dataset[Row]就能比较好的解决问题
转化:
RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换
DataFrame/Dataset转RDD:
这个转换很简单
| 1 2 |
|
RDD转DataFrame:
| 1 2 3 4 |
|
一般用元组把一行的数据写在一起,然后在toDF中指定字段名
RDD转Dataset:
| 1 2 3 4 5 |
|
可以注意到,定义每一行的类型(case class)时,已经给出了字段名和类型,后面只要往case class里面添加值即可
Dataset转DataFrame:
这个也很简单,因为只是把case class封装成Row
| 1 2 |
|
DataFrame转Dataset:
| 1 2 3 |
|
这种方法就是在给出每一列的类型后,使用as方法,转成Dataset,这在数据类型是DataFrame又需要针对各个字段处理时极为方便
特别注意:
在使用一些特殊的操作时,一定要加上 import spark.implicits._ 不然toDF、toDS无法使用
------------hive中的列转行,与行转列
Hive
行转列和列转行
表1:cityInfo

表2:cityInfoSet

表1和表2的结构如上所示。如何在 hive 中使用 Hql 语句对表1和表2进行互相转化呢?
行转列
表1=>表2 可以使用 hive 的内置函数 concat_ws() 和 collect_set()进行转换:
执行代码如下所示:
select cityname,concat_ws(',',collect_set(regionname)) as address_set from cityInfo group by cityname;
1
列转行
表2=>表1 可以使用 hive 的内置函数 explode()进行转化。代码如下:
select cityname, region from cityInfoSet lateral view explode(split(address_set, ',')) aa as region;
------------------spark中的driver与executor
一、看了很多网上的图,大多是dirver和executor之间的图,都不涉及物理机器
如下图,本人觉得这些始终有些抽象

看到这样的图,我很想知道driver program在哪里啊,鬼知道?为此我自己研究了一下,网友大多都说是对的有不同想法的请评论
二、现在我有三台电脑 分别是
-
192.168.10.82 –>bigdata01.hzjs.co -
192.168.10.83 –>bigdata02.hzjs.co -
192.168.10.84 –>bigdata03.hzjs.co
集群的slaves文件配置如下:
-
bigdata01.hzjs.co -
bigdata02.hzjs.co -
bigdata03.hzjs.co
那么这三台机器都是worker节点,本集群是一个完全分布式的集群经过测试,我使用# ./start-all.sh ,那么你在哪台机器上执行的哪台机器就是7071 Master主节点进程的位置,我现在在192.168.10.84使用./start-all.sh
那么就会这样

三、那么我们来看看local模式下

现在假设我在192.168.10.84上执行了 bin]# spark-shell 那么就会在192.168.10.84产生一个SparkContext,此时84就是driver,其他woker节点(三台都是)就是产生executor的机器。如图
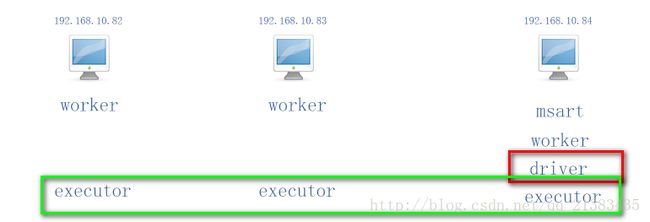
现在假设我在192.168.10.83上执行了 bin]# spark-shell 那么就会在192.168.10.83产生一个SparkContext,此时83就是driver,其他woker节点(三台都是)就是产生executor的机器。如图

总结:在local模式下 驱动程序driver就是执行了一个Spark Application的main函数和创建Spark Context的进程,它包含了这个application的全部代码。(在那台机器运行了应用的全部代码创建了sparkContext就是drive,也可以说是你提交代码运行的那台机器)
四、那么看看cluster模式下

现在假设我在192.168.10.83上执行了 bin]# spark-shell 192.168.10.84:7077 那么就会在192.168.10.84产生一个SparkContext,此时84就是driver,其他woker节点(三台都是)就是产生executor的机器。这里直接指定了主节点driver是哪台机器:如图

五、如果driver有多个,那么按照上面的规则,去判断具体在哪里
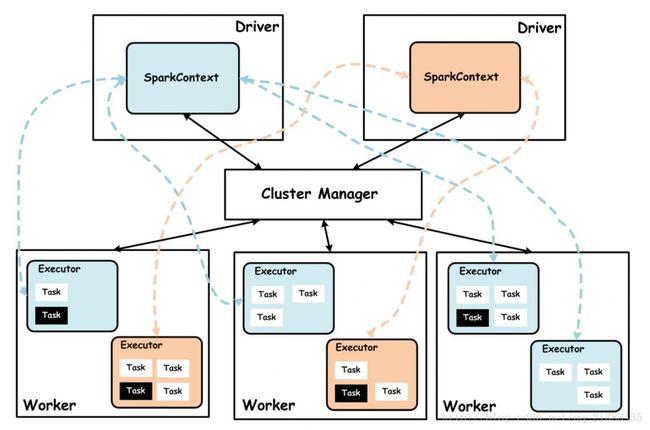
Driver: 使用Driver这一概念的分布式框架有很多,比如hive,Spark中的Driver即运行Application的main()函数,并且创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中由SparkContext负责与ClusterManager通讯,进行资源的申请,任务的分配和监控等。当Executor部分运行完毕后,Driver同时负责将SaprkContext关闭,通常SparkContext代表Driver.
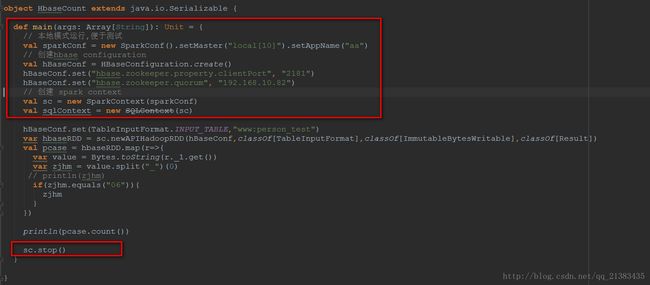
上面红色框框都属于Driver,运行在Driver端,中间没有框住的部分属于Executor,运行的每个ExecutorBackend进程中。println(pcase.count())collect方法是Spark中Action操作,负责job的触发,因为这里有个sc.runJob()方法
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sumhbaseRDD.map()属于Transformation操作。
总结:Spark Application的main方法(于SparkContext相关的代码)运行在Driver上,当用于计算的RDD触发Action动作之后,会提交Job,那么RDD就会向前追溯每一个transformation操作,直到初始的RDD开始,这之间的代码运行在Executor。
---------------------------top K
堆排解法
用堆排来解决Top K的思路很直接。
前面已经说过,堆排利用的大(小)顶堆所有子节点元素都比父节点小(大)的性质来实现的,这里故技重施:既然一个大顶堆的顶是最大的元素,那我们要找最小的K个元素,是不是可以先建立一个包含K个元素的堆,然后遍历集合,如果集合的元素比堆顶元素小(说明它目前应该在K个最小之列),那就用该元素来替换堆顶元素,同时维护该堆的性质,那在遍历结束的时候,堆中包含的K个元素是不是就是我们要找的最小的K个元素?
实现:
在堆排的基础上,稍作了修改,buildHeap和heapify函数都是一样的实现,不难理解。
速记口诀:最小的K个用最大堆,最大的K个用最小堆。
public class TopK {
public static void main(String[] args) {
// TODO Auto-generated method stub
int[] a = { 1, 17, 3, 4, 5, 6, 7, 16, 9, 10, 11, 12, 13, 14, 15, 8 };
int[] b = topK(a, 4);
for (int i = 0; i < b.length; i++) {
System.out.print(b[i] + ", ");
}
}
public static void heapify(int[] array, int index, int length) {
int left = index * 2 + 1;
int right = index * 2 + 2;
int largest = index;
if (left < length && array[left] > array[index]) {
largest = left;
}
if (right < length && array[right] > array[largest]) {
largest = right;
}
if (index != largest) {
swap(array, largest, index);
heapify(array, largest, length);
}
}
public static void swap(int[] array, int a, int b) {
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}
public static void buildHeap(int[] array) {
int length = array.length;
for (int i = length / 2 - 1; i >= 0; i--) {
heapify(array, i, length);
}
}
public static void setTop(int[] array, int top) {
array[0] = top;
heapify(array, 0, array.length);
}
public static int[] topK(int[] array, int k) {
int[] top = new int[k];
for (int i = 0; i < k; i++) {
top[i] = array[i];
}
//先建堆,然后依次比较剩余元素与堆顶元素的大小,比堆顶小的, 说明它应该在堆中出现,则用它来替换掉堆顶元素,然后沉降。
buildHeap(top);
for (int j = k; j < array.length; j++) {
int temp = top[0];
if (array[j] < temp) {
setTop(top, array[j]);
}
}
return top;
}
}
时间复杂度
n*logK
速记:堆排的时间复杂度是n*logn,这里相当于只对前Top K个元素建堆排序,想法不一定对,但一定有助于记忆。
适用场景
实现的过程中,我们先用前K个数建立了一个堆,然后遍历数组来维护这个堆。这种做法带来了三个好处:(1)不会改变数据的输入顺序(按顺序读的);(2)不会占用太多的内存空间(事实上,一次只读入一个数,内存只要求能容纳前K个数即可);(3)由于(2),决定了它特别适合处理海量数据。
这三点,也决定了它最优的适用场景。
快排解法
用快排的思想来解Top K问题,必然要运用到”分治”。
与快排相比,两者唯一的不同是在对”分治”结果的使用上。我们知道,分治函数会返回一个position,在position左边的数都比第position个数小,在position右边的数都比第position大。我们不妨不断调用分治函数,直到它输出的position = K-1,此时position前面的K个数(0到K-1)就是要找的前K个数。
实现:
“分治”还是原来的那个分治,关键是getTopK的逻辑,务必要结合注释理解透彻,自动动手写写。
public class TopK {
public static void main(String[] args) {
// TODO Auto-generated method stub
int[] array = { 9, 3, 1, 10, 5, 7, 6, 2, 8, 0 };
getTopK(array, 4);
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + ", ");
}
}
// 分治
public static int partition(int[] array, int low, int high) {
if (array != null && low < high) {
int flag = array[low];
while (low < high) {
while (low < high && array[high] >= flag) {
high--;
}
array[low] = array[high];
while (low < high && array[low] <= flag) {
low++;
}
array[high] = array[low];
}
array[low] = flag;
return low;
}
return 0;
}
public static void getTopK(int[] array, int k) {
if (array != null && array.length > 0) {
int low = 0;
int high = array.length - 1;
int index = partition(array, low, high);
//不断调整分治的位置,直到position = k-1
while (index != k - 1) {
//大了,往前调整
if (index > k - 1) {
high = index - 1;
index = partition(array, low, high);
}
//小了,往后调整
if (index < k - 1) {
low = index + 1;
index = partition(array, low, high);
}
}
}
}
}
时间复杂度
n
速记:记住就行,基于partition函数的时间复杂度比较难证明,从来没考过。
适用场景
对照着堆排的解法来看,partition函数会不断地交换元素的位置,所以它肯定会改变数据输入的顺序;既然要交换元素的位置,那么所有元素必须要读到内存空间中,所以它会占用比较大的空间,至少能容纳整个数组;数据越多,占用的空间必然越大,海量数据处理起来相对吃力。
但是,它的时间复杂度很低,意味着数据量不大时,效率极高。
好了,两种解法写完了,赶紧实现一下吧。
HIVE
-----------hive自定义函数UDF-------------
工具:IDEA + Maven
定义函数功能:输入xxx,输出Hello xxx
自定义UDF函数的步骤:
以下部分摘自学长博客,略作修改。
创建一个新的项目
填写相关信息:
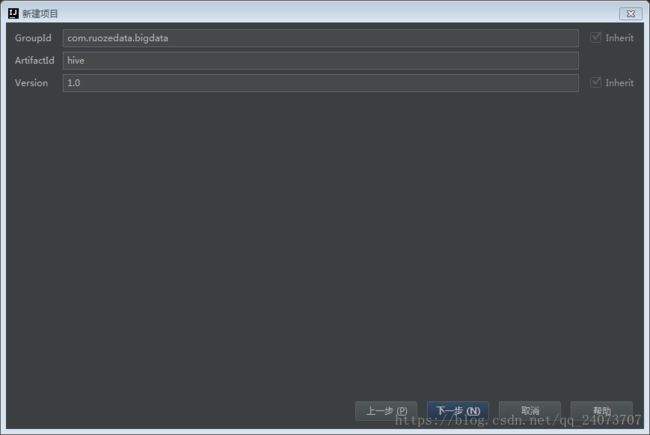
修改参数路径:
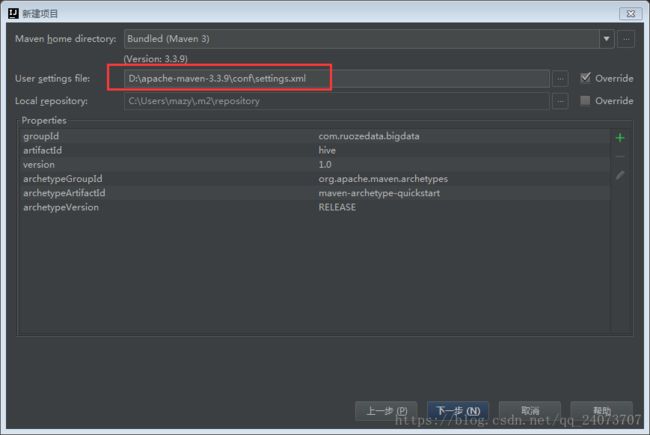
填写项目名称和保存路径:

更新完后删除:

修改:
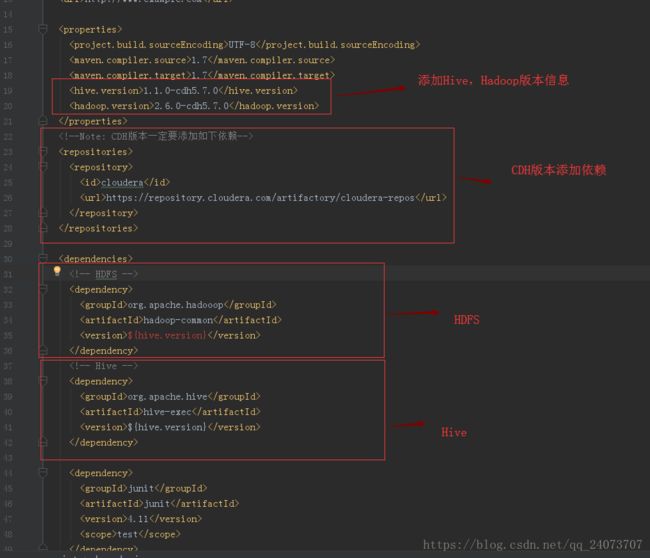
页面可以打开就行:
https://repository.cloudera.com/artifactory/cloudera-repos/

本次环境需要下载:
Index of cloudera-repos/org/apache/hadoop/hadoop-common
新建一个类:

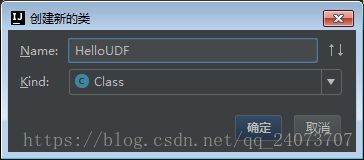
功能:输入XXX,输出Hello xxx -> 输入一个东西,输出的时候前面带Hello
自定义UDF函数的步骤:
1)定义一个类 extends UDF (继承UDF)
导入继承UDF
-- 现在我们输出一个,Hello:若泽:Jepsonpackage com.RUOZEdata.bigdata;
import org.apache.hadoop.hive.ql.exec.UDF;
public class HelloUDF extends UDF {
public String evaluate(String input){
return "Hello:" + input;
}
public String evaluate(String input, String input2) {
return "Hello:" + input + ":" + input2;
}
public static void main(String[] args) {
HelloUDF udf = new HelloUDF();
System.out.println(udf.evaluate("若泽", "Jepson"));
}
}
图结果:

打包:
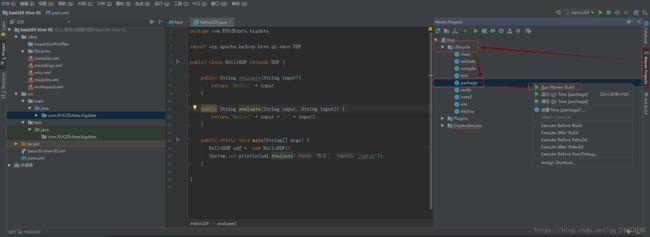
打包成功:

上传jar包到 /home/hadoop/lib目录下:
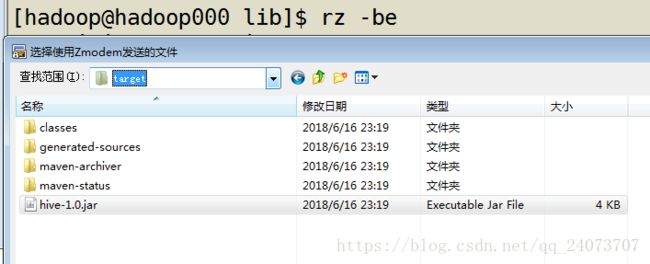
第一种:创建临时函数。如在hive CLI执行下面命令:
-- 以下命令Hive执行,创建 sayHello
add jar /home/hadoop/lib/hive-1.0.jar;
CREATE TEMPORARY FUNCTION sayHello AS 'com.ruozedata.bigdata.HelloUDF';这里的红色字体是从UDF这里 复制 reference,注意红色字体旁边需要有引号

-- 执行语句
add jar /home/hadoop/lib/hive-1.0.jar;
CREATE TEMPORARY FUNCTION sayHello AS 'com.ruozedata.bigdata.HelloUDF';
-- show functions 查找是否存在:
进入另一会话查看,发现没有。
我们使用的是TEMPORARY:仅对当前session(黑窗口)有效,所以在其他窗口打开是没用的
CREATE TEMPORARY FUNCTION sayHello AS 'com.ruozedata.bigdata.HelloUDF';
-- 在第一个窗口使用 list jars可以查看到刚刚添加的jar包

-- 如果从新开一个窗口,会有要去add jar比较麻烦,我们需要在Hive的目录底下创建一个文件,把jar包拷贝过去
然后再创建新的表测试,是否正确,临时的创建,从启后都会失效。

第二种:修改源代码,重编译,注册函数。这种方法可以永久性的保存udf函数,但是风险很大
-- 首先需要把本地文件hive-1.0.jar放到HDFS上,然后在创建永久的函数的时候需要指定HDFS目录
hdfs dfs -put /home/hadoop/lib/hive-1.0.jar /lib/
-- 创建函数,我这里和若泽的端口号可能不同我这里是9000,他这里是8020

不确定端口号的可以使用命令 hive > desc formatted 查看一张表,

-- 如果在location后面看到这一串不认识的东西 511023ea-b9d8-46d3-aff8-c1e3613f61c9 就是HDFS上的
-- show functions 查看是否有sayruozehello
-- 查询是否存在:

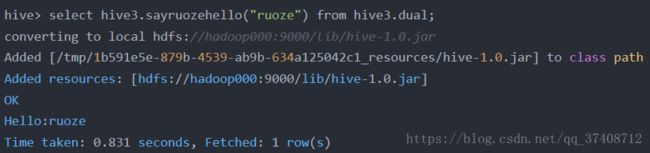
-- 再打开一个窗口,查看是否能查询的到 show functions
-- 再查询,这次查询不连接hive3库,直接查询,查询的时候要在信息前面加hive3的库名,第一次会转换,从HDFS上加载进来
-- 永久注册,会注册到元数据内,我们进行元数据查询。


-- 我们启动Hive会有很多函数,都是怎么来的呢?进入函数查看源码,了解底层的机制

个人总结:
上述两种方法,第一种方法仅仅是临时函数无法满足生产上的需求,总会有情况需要提供稳定的udf函数。而第二种方法虽然满足了需求,但是存在较大的风险,易造成hive的异常。根据官方的说法,hive0.13版本以后(包过0.13)是支持注册永久函数的,而且提供了注册的方法。但注意创建注册udf函数的时候,要注意环境模式。
--------------HIVE数据加载与计算-------------------------------------
explode: (把一串数据转换成多行的数据)
创建一个文本:
[hadoop@ruozehadoop000 data]$ vi hive-wc.txt
hello,world,welcome
hello,welcome创建一个表,并导入文本内容
create table hive_wc(sentence string);
load data local inpath '/home/hadoop/data/hive-wc.txt' into table hive_wc;
hello,world,welcome
hello,welcome求每个单词出现的个数
1) 获取每个单词 split(sentence,",")
["hello","world","welcome"]
["hello","welcome"]
结果输出:
"hello"
"world"
"welcome"
"hello"
"welcome"
通过聚合语法进行计算:
select word, count(1) as c
from (select explode(split(sentence,",")) as word from hive_wc) t
group by word ;json:工作中常用
创建一张表 rating_json,上传数据,并查看前十行数据信息
create table rating_json(json string);
load data local inpath '/home/hadoop/data/rating.json' into table rating_json;
对json的数据进行处理
jason_tuple 是一个UDTF是 Hive0.7版本引进的
select json_tuple(json,"movie","rate","time","userid") as (movie,rate,time,userid)
from rating_json limit 10;作业:
准备一份数据:
[hadoop@ruozehadoop000 data]$ more hive_row_number.txt
1,18,ruoze,M
2,19,jepson,M
3,22,wangwu,F
4,16,zhaoliu,F
5,30,tianqi,M
6,26,wangba,F创建表并导入数据:
create table hive_rownumber(id int,age int, name string, sex string)
row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/data/hive_row_number.txt' into table hive_rownumber;要求:查询出每种性别中年龄最大的2条数据
order by是全局的排序,做不到分组内的排序
组内进行排序,就要用到窗口函数or分析函数
分析函数
select id,age,name,sex
from
(select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rank
from hive_rownumber) t
where rank<=2;
输出结果:

User-Defined Functions : UDF
UDF: 一进一出 upper lower substring
UDAF:Aggregation 多进一出 count max min sum ...
UDTF: Table-Generation 一进多出
KAFKA
--------------------------KAFKA--------------
1.核心概念
broker: 进程
producer: 生产者
consumer: 消费者
topic: 主题
partitions: 分区 (副本数)
consumergroup:
1.容错性的消费机制
2.一个组内,共享一个公共的ID groupid
3.组内的所有消费者协调在一起,去消费topic的所有的分区
4.每个分区只能由同一个消费组的一个消费者来消费
副本数:每个分区有几个副本,以3为例:
发送123--> 0分区 在2,3机器上面也有个0分区,会备份123.
offset: 每个partition的数据的id
kafka中的offset
segment:
1.分为log和index文件
2.通过配置以下参数设置回滚
log.segment.bytes
log.roll.hours
3.命名规则: 上一个segment分组log文件的最大offset
2.消费语义
at most once: 最多消费一次 消费可能丢失 但是不会重复消费 ?-->适用于不重要的log,丢几条没事
at least once: 至少消费一次 消费不可能丢失 但是会重复消费 ?-->不用担心丢失,但数据会重复,需考虑去重
exactly once: 正好一次 消息不会丢失 也不会重复(这才是我们想要的)
但0.10.0.1 不支持不能实现 0.11官方已支持
数据去重:1.HBase的put操作,MySQL的update insert操作。2.把数据放到redis,在redis中去重
consumer offset:
数据:1,2,3,4,5
传到:1,2,3consumer挂了,offset没有维护
那么重启后从上一次的更新的offset的位置去消费(断点还原)
0.10版本的offset是存在kafka自己本身
topic: test
内嵌一个topic:如
3.Flume-->Kafka-->Spark streaming 经典案例
Pom:
4.0.0
com.ruozedata
DSHS
1.0-SNAPSHOT
2008
scala-tools.org
Scala-Tools Maven2 Repository
http://scala-tools.org/repo-releases
UTF-8
2.11.8
0.10.0.0
2.1.1
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-streaming_2.11
${spark.version}
org.apache.spark
spark-streaming-kafka-0-10_2.11
${spark.version}
org.scala-tools
maven-scala-plugin
2.15.2
compile
testCompile
maven-compiler-plugin
3.6.0
1.8
1.8
org.apache.maven.plugins
maven-surefire-plugin
2.19
true
源码:
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges, KafkaUtils}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* By ruozedata-J 20180826
*/
object DSHS {
def main(args: Array[String]): Unit = {
//定义变量
val timeFormat = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss.SSS")
println("启动时间:" + timeFormat.format(new Date()))
//流间隔 batch的时间
var slide_interval = Seconds(1) //默认 1秒
if (args.length==1){
slide_interval = Seconds(args(0).toLong) //自定义
}
val bootstrap_servers = "***.***.*.**:9092,***.***.*.**:9092,***.***.*.**:9092" //kakfa地址
try {
//1. Create context with 2 second batch interval
val ss = SparkSession.builder()
.appName("DSHS-0.1")
.master("local[2]")
.getOrCreate()
val sc = ss.sparkContext
val scc = new StreamingContext(sc, slide_interval)
//2.设置kafka的map参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> bootstrap_servers
, "key.deserializer" -> classOf[StringDeserializer]
, "value.deserializer" -> classOf[StringDeserializer]
, "group.id" -> "use_a_separate_group_id_for_each_stream"
, "auto.offset.reset" -> "latest"
, "enable.auto.commit" -> (false: java.lang.Boolean)
, "max.partition.fetch.bytes" -> (2621440: java.lang.Integer) //default: 1048576
, "request.timeout.ms" -> (90000: java.lang.Integer) //default: 60000
, "session.timeout.ms" -> (60000: java.lang.Integer) //default: 30000
)
//3.创建要从kafka去读取的topic的集合对象
val topics = Array("onlinelogs")
//4.输入流
val directKafkaStream = KafkaUtils.createDirectStream[String, String](
scc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
//坑 order window
directKafkaStream.foreachRDD(
rdd => {
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //RDD的offset
//rdd-->DF -->sql
rdd.foreachPartition(rows => {
rows.foreach { row =>
println(row.toString) //打印
//TODO 业务处理
}
})
//该RDD异步提交offset
directKafkaStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
)
scc.start()
scc.awaitTermination()
scc.stop()
} catch {
case e: Exception =>
println(e.getMessage)
}
}
}
auto.offset.reset:
latest 断点还原从最新的偏移量开始
earliest 断点还原从头开始=重新执行任务
none
enable.auto.commit: 一般设为false,如果设为true,易引发数据丢失
若设为true:
enable.auto.commit: true
auto.commit.interval.ms:5000 每个5s自动维护偏移量
生产:断批还原 +put 保证数据零丢失
举例:一个批次10000条数据,发送2000条后挂了。于是我们开始断批还原,从头传这个批次。那2000条数据,由于put命令的底层操作不会导致重复,后面的数据无缝对接传完。
4.监控 & 心得
1.Kafka eagle:Kafka 消息监控 - Kafka Eagle
2.CDH
通过以下语句构建图标实时监控:
SELECT total_kafka_bytes_received_rate_across_kafka_broker_topics ,total_kafka_bytes_fetched_rate_across_kafka_broker_topics
WHERE entityName = "kafka:onlinelogs" AND category = KAFKA_TOPIC图:
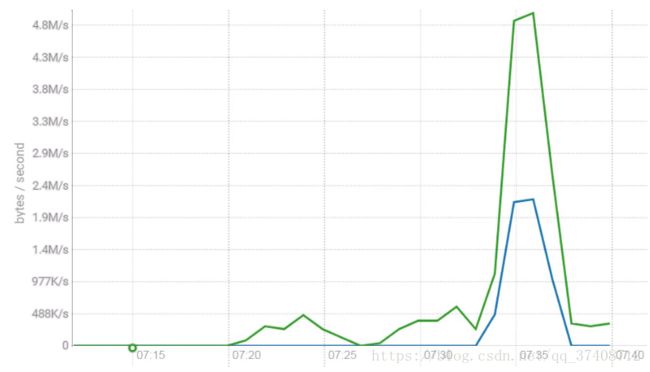
1.生产者和消费者的速度是一样嘛?
由于趋势度吻合,所以速度一样的
2.为什么消费者的曲线和生产者的曲线趋势度吻合?
可以及时消费,消费目前的数据量没有压力
3.为什么消费者的曲线和生产者的曲线要高?
HIVE
压缩:Compression
需要考虑的要素:
一:压缩比
二:解压速度
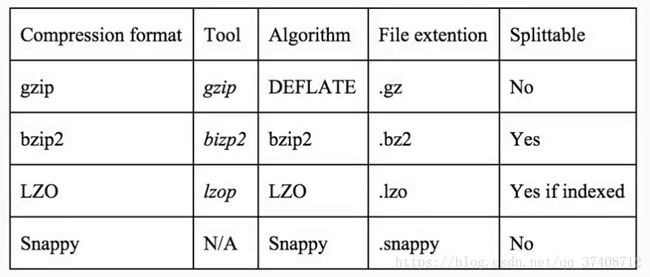
常见压缩格式对比:


压缩在MapReduce里的应用:

hadoop checknative命令查看支持的压缩格式,需要自行编译以支持各种格式
codec:我们只需要配置在hadoop的配置文件中即可
压缩的使用
core-site.xml
//需要哪些格式加什么的代码,这里只加三种
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec, //常用
com.hadoop.compression.lzo.LzopCodec, //常用
org.apache.hadoop.io.compress.Lz4Codec,
org.apache.hadoop.io.compress.Snappycodec,
mapred-site.xml
mapreduce.output.fileoutputformat.compress
true
mapreduce.output.fileoutputformat.compress.codec
org.apache.hadoop.io.compress.BZip2Codec //指定使用BZ2压缩格式
实验:创建第一个表,用于给后续的表插入数据
create table ruoze_page_views(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t';
load data local inpath '/home/hadoop/data/page_views.dat' overwrite into table ruoze_page_views;BZ2示例:Hive的结果以BZ2的格式压缩输出:
开启Hive的压缩输出,并指定为BZ2的格式
SET hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec;
在Hive创建一个Hive的结果以BZ2的格式压缩输出表
create table ruoze_page_views_bzip2
row format delimited fields terminated by '\t'
as select * from ruoze_page_views;
关闭压缩功能
set hive.exec.compress.output=false;
-----------------------
行式存储 vs 列式存储
行式存储的优点:
同一行数据存放在同一个block块里面,select * from table_name;数据能直接获取出来;
INSERT/UPDATE比较方便
行式存储的缺点:
不同类型数据存放在同一个block块里面,压缩性能不好;
select id,name from table_name;这种类型的列查询,所有数据都要读取,而不能跳过。
列式存储的优点:
同类型数据存放在同一个block块里面,压缩性能好;
任何列都能作为索引。
列式存储的缺点:
select * from table_name;这类全表查询,需要数据重组;
INSERT/UPDATE比较麻烦。
Storage Format 介绍:
STORED AS file_format
TextFile示例:
create table ruoze_b(id int) stored as
INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';SequenceFile示例
create table ruoze_page_views_seq(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as SEQUENCEFILE;
insert into table ruoze_page_views_seq select * from ruoze_page_views;RcFile示例:
create table ruoze_page_views_rc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as rcfile;
insert into table ruoze_page_views_rc select * from ruoze_page_views;Orc示例:
create table ruoze_page_views_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc;
insert into table ruoze_page_views_orc select * from ruoze_page_views;不使用orc压缩功能:
create table ruoze_page_views_orc_null(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc tblproperties ("orc.compress"="NONE");
insert into table ruoze_page_views_orc_null select * from ruoze_page_views;
parquet示例:
create table ruoze_page_views_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet;
insert into table ruoze_page_views_parquet select * from ruoze_page_views;GZIP示例:
set parquet.compression=GZIP;
create table ruoze_page_views_parquet_gzip
row format delimited fields terminated by '\t'
stored as parquet
as select * from ruoze_page_views;文件大小对比:

行式储存和列式储存操作时的对比:
行式储存:
select count(1) from ruoze_page_views where session_id='B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';
读取的文件数:19022752
列式储存:
orc:
select count(1) from ruoze_page_views_orc where session_id='B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';
读取的文件数:1257523
parquet:
查一列:
select count(1) from ruoze_page_views_parquet where session_id='B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1';
读取的文件数:2687077
查两列:
select count(1) from ruoze_page_views_parquet where session_id='B58W48U4WKZCJ5D1T3Z9ZY88RU7QA7B1' and ip='1';
读取的文件数:3496487
SCALA
算子=函数=API
Currying(颗粒化):作用是将两个参数的函数,转换成两个函数,第一个函数的参数为两个参数函数的第一个参数,同理,第二个函数的参数为第二个参数。
scala> def sum(x:Int,y:Int) = x + y
sum: (x: Int, y: Int)Int
scala> sum(1,2)
res16: Int = 3
scala> def sum_Currying(x:Int) = (y:Int) => x + y
sum_Currying: (x: Int)Int => Int
scala> sum_Currying(1)(2)
res17: Int = 3
scala> def sum_Currying_Better(x : Int)(y : Int) = x + y
sum_Currying_Better: (x: Int)(y: Int)Int
scala> sum_Currying_Better(1)(2)
res18: Int = 3
隐式转换:(能不用就不用,对于维护极其不友好)偷偷的给你做点什么
def main(args: Array[String]): Unit = {
val one=new tea("奶茶")
//将tea隐式转换为milktea,一般把这条语句抽取出去放到一个专门用于存储
//隐式转换语句的类里,需要用到时导入该类直接引用,方便维护与修改。
//隐式转换的名字格式一般为a2aa,btobb(为了直观形象)
implicit def tea2milkTea(one:tea):milkTea=new milkTea(one.name)
//转换后有了milktea里的speak方法
one.speak()
}
class tea(val name:String)
class milkTea(val name:String) {
def speak() {
println(s"$name:我们不一样")
}
}
抽取出去后导入类引用的代码:
def main(args: Array[String]): Unit = {
val one=new tea("奶茶")
import implicitClass.tea2milkTea
one.speak()
}
class tea(val name:String)
class milkTea(val name:String) {
def speak() {
println(s"$name:我们不一样")
}
}
1.高阶函数介绍:
map:
val list=List(1,2,3,4,5,6,7,8,9)
println(list.map((x:Int)=>x*2))
//自动推断int类型
println(list.map((x)=>x*2))
//一个参数,可去括号
println(list.map(x=>x*2))
//一个参数,简略写法
println(list.map(_*2))filter and take:
//根据条件过滤数据
println(list.map(_ * 2).filter(_>2))
//只查看前3个数据
println(list.take(3))
reduce:
println(list.reduce(_-_))
println(list.reduceLeft(_-_))
//Right的结果不一样,为什么
println(list.reduceRight(_-_))
学会借助代码理解函数的原理:
//让reduceRight打印它的计算流程
list.reduceRight((a,b)=>{
println(a+" "+b)
a+b
})
一目了然
zip:类似于inner join
val list1=List(1,2,3)
val list2=List("a","b","c")
println(list1.zip(list2))
//当list1和list2个数不匹配时
val list1=List(1,2,3,4)
val list2=List("a","b","c")
println(list1.zip(list2))
flatten and foreach:
val list1=List(List(1,2),List(3,4),List(5,6))
//打印出其中的所有内容
println(list1)
//依次查看其中的每个元素
list1.foreach(println)
//查看打扁数据
println(list1.flatten)
flatMap:
val list1=List(List(1,2),List(3,4),List(5,6))
//flatMap后是已经打扁了的数据
println(list1.flatMap(x=>x))
//嵌套个map
println(list1.flatMap(_.map(_*2)))
举个例子,wordCount:
lines.flatMap(_.split(" ")) ==> 拆分成一个个单词
.map(x => (x, 1)) ==> 给每个单词捆绑个值
.reduceByKey(_ + _)按key分组,然后把值两两相加Tuple :tuple是一个集合,里面可以放各种各样类型的元素
val tupletest=(1,2.0,"c")
//打印tupletest的所有数据
println(tupletest)
//取tupletest里的某个值
println(tupletest._1,tupletest._2,tupletest._3)
多行字符串:
val a=
"""
|你好
|我不好
""".stripMargin
另一种输出方法(常用):
val a="Lynn"
println(s"Hello: $a")
//执行结果:
//Hello: Lynn
2.模型匹配:
变量 match {
case 值 => 代码
case 值 => 代码
case _ => 代码 //其他情况就执行这段代码
}
偏函数 PartialFunction
被包在花括号内没有match的一组case语句
PartialFunction[A, B]
A:代表入参类型
B:代表返回类型
举个例子:
def SayChineseName:PartialFunction[String,String]={
case "IT晓白" =>"Lyz"
case "老师" =>"Teacher"
case "学生" =>"Student"
}
println(SayChineseName("IT晓白"))
//执行结果:
//Lyz
HUE
https://blog.csdn.net/qq_37408712/article/details/81283207
通过ScalikeJDBC对MySQL进行增删查改
通过IDEA+Maven+Scala搞定
在pom.xml文件中添加依赖
org.scalikejdbc
scalikejdbc_2.11
${scalikejdbc.version}
org.scalikejdbc
scalikejdbc-config_2.11
${scalikejdbc.version}
mysql
mysql-connector-java
${mysql.java.version}
2.5.2
5.1.38
添加并编辑配置文件:(根据个人情况做相应改动)
# JDBC settings
db.default.driver="org.h2.Driver"
db.default.url="jdbc:h2:file:./db/default"
db.default.user="sa"
db.default.password=""
# Connection Pool settings
db.default.poolInitialSize=10
db.default.poolMaxSize=20
db.default.connectionTimeoutMillis=1000
# Connection Pool settings
db.default.poolInitialSize=5
db.default.poolMaxSize=7
db.default.poolConnectionTimeoutMillis=1000
db.default.poolValidationQuery="select 1 as one"
db.default.poolFactoryName="commons-dbcp2"
db.legacy.driver="org.h2.Driver"
db.legacy.url="jdbc:h2:file:./db/db2"
db.legacy.user="foo"
db.legacy.password="bar"
# MySQL example
db.default.driver="com.mysql.jdbc.Driver"
db.default.url="jdbc:mysql://localhost/scalikejdbc"
# PostgreSQL example
db.default.driver="org.postgresql.Driver"
db.default.url="jdbc:postgresql://localhost:5432/scalikejdbc"
导入相关jar包:
import scalikejdbc._
import scalikejdbc.config._
main函数中解析配置文件:
scalikejdbc.config.DBs.setupAll()
然后即可开始数据库操作
package com.ruozedata
import scalikejdbc._
import scalikejdbc.config._
case class User(id: Int,name: String, age: Int)
object ScalalikeJdbc {
def main(args: Array[String]): Unit = {
scalikejdbc.config.DBs.setupAll()
val userList:List[User] = List(User(1,"Lynn",20),User(2,"zhangsan",19),User(3,"lisi",17))
println("新增数据:"+batchSave(userList))
println("查询数据:")
val users1 = select()
for (user <- users1){
println("id:"+user.id +" name:"+user.name+" age:"+user.age)
}
println("更新id:1的年龄:"+update(10,1))
val users2 = select()
for (user <- users2){
println("id:"+user.id +" name:"+user.name+" age:"+user.age)
}
println("删除id:1:"+deleteByID(1))
println("删除id:2:"+deleteByID(2))
println("删除id:3:"+deleteByID(3))
DBs.closeAll()
}
def deleteByID(id:Int) = {
DB.autoCommit { implicit session =>
SQL("delete from user where id = ?").bind(id).update().apply()
}
}
def update(setage:Int,pid:Int) {
DB.autoCommit { implicit session =>
SQL("update user set age = ? where id = ?").bind(setage, pid).update().apply()
}
}
def select():List[User] = {
DB.readOnly { implicit session =>
SQL("select * from user").map(rs => User(rs.int("id"), rs.string("name"), rs.int("age"))).list().apply()
}
}
def batchSave(users:List[User]) :Unit= {
DB.localTx { implicit session =>
for (user<- users){
SQL("insert into user(name,age,id) values(?,?,?)").bind(user.name, user.age, user.id).update().apply()
}
}
}
}
以下是我的操作结果:

具体事项建议查看官网:scalikejdbc.org/documentation/configuration.html
累计报表
具体需求:
用户 日期 流量
熊猫tv 2018-01-02 5T
快手 2018-01-02 3T
YY 2018-01-02 2T
抖音 2018-01-02 15T
熊猫tv 2018-01-03 4T
快手 2018-01-03 3T
YY 2018-01-03 1T
抖音 2018-01-03 16T
输出:USER_TRAFFIC_STAT
用户 月份 月访问 总访问
熊猫tv 2018-01 100T 100T
熊猫tv 2018-02 200T 300T
熊猫tv 2018-03 200T 500T
抖音 2018-01 500T 500T
抖音 2018-02 600T 1100T
......
源数据:

建个表导入数据:
create table domain_date_flow(domain string,date string,flow int)
row format delimited fields terminated by '\t'
load data local inpath '/home/hadoop/data/hive_user_date_flow.txt' overwrite into table domain_date_flow;
求每月的总访问量,存储到新表:
create table totalbyMonth as
select domain,date,sum(a.flow) mCountflow
from (select domain,(from_unixtime(unix_timestamp(date,'yyyy-mm-dd'),'yyyy-mm'))as date,flow from domain_date_flow)as a
group by a.domain,a.date
sort by a.domain,a.date;
通过自连接,求月累计流量,存储到新表:
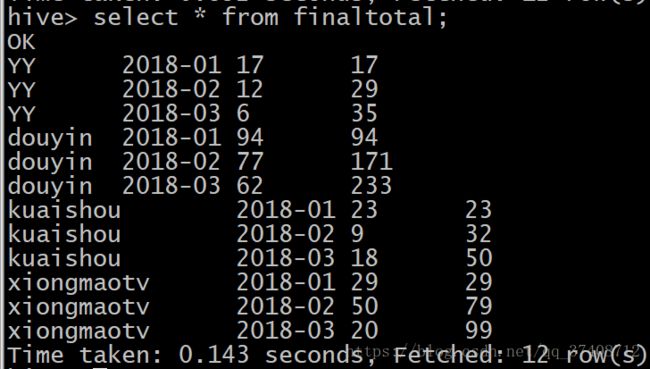
create table finaltotal as
select t1.domain domain,t1.date date,max(t1.mCountflow) mCountflow,sum(t2.mCountflow) totalflow
from totalbyMonth as t1 inner join totalbyMonth as t2 on (t1.domain=t2.domain)
where t2.date <= t1.date
group by t1.domain,t1.date;
运行结果:
原理分析:
totalbyMonth数据:

自连接后的数据:

在经历where t2.date <= t1.date group by t1.domain,t1.date之后,数据成下列形式

然后经过聚合函数的计算,就得到了最后的结果
参考链接:
https://blog.csdn.net/freefish_yzx/article/details/77504587
https://blog.csdn.net/bitcarmanlee/article/details/51926530
Permission
提示
Permission denied解决的办法:
$ sudo chmod -R 777 某一目录其中
-R 是指级联应用到目录里的所有子目录和文件
777 是所有用户都拥有最高权限
DATAX
https://blog.csdn.net/dr_guo/article/details/82222151
FREE
free -h
sync
cat /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
<未完>