机器学习实验——使用决策树和随机森林对数据分类
实验要求:
使用决策树算法和随机森林算法对income_classification.csv的收入水平进行分类。训练集和测试集的比例是7:3,选取适当的特征列,使得针对测试样本的分类准确率在80%以上,比较2种分类方法的准确率。
数据说明:
特征列:
age:年龄,整数
workclass:工作性质,字符串
education:教育程度,字符串
education_num:受教育年限,整数
maritial_status:婚姻状况,字符串
occupation:职业,字符串
relationship:亲戚关系,字符串
race:种族,字符串
sex:性别,字符串
capital_gain:资本收益,浮点数
capital_loss:资本损失,浮点数
hours_per_week:每周工作小时数,浮点数
native_country:原籍,字符串
分类标签列:income
imcome > 50K
Imcome ≤ 50K
1、读入数据并显示数据的维度和前5行数据
2、对连续变量年龄进行离散化,并显示前5行数据离散化后的结果
age_bins = [20, 30,40, 50, 60, 70]
3、对属性是字符串的任意特征进行数字编号处理,显示前5行编号后的结果,每个特定的字符串用一个整数来表示,整数序列从0开始增长。
4、对预处理后的数据用决策树算法和随机森林算法分类
实验步骤
-
选择合适的若干特征字段
-
按7:3划分训练集和样本集
-
使用训练集训练一个决策树分类器
-
使用测试集计算决策树分类器的分类准确率
-
使用训练集训练一个随机森林分类器
-
使用测试集计算随机森林分类器的分类准确率
5、分析实验结果
实验内容:
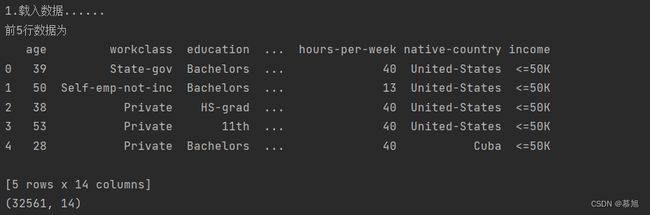
一、实验数据均存放在income_classification.csv,读出数据使用pandas库的read_csv方法,显示前5行数据可以使用DataFrame.head(n),n是指返回行数的整数值,这个方法的作用是返回对象的前n行。
代码:
import pandas
print("1.载入数据......")
data_original = pandas.read_csv('income_classificatio.csv', header = 0, names = column_names)
print("前5行数据为")
print(data_original.head(5)) # 返回前5行数据
print(data_original.shape) # 显示数据维度
结果:
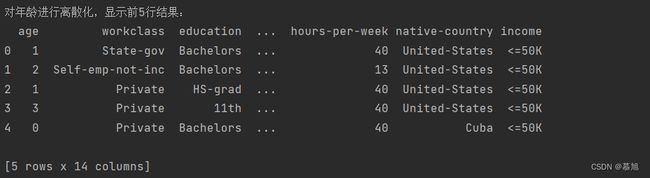
二、对数据进行分箱处理可以使用cut方法进行处理,cut方法可以指定分箱的边界,每个箱体里面的样本量不一定相等,比较适合对年龄进行离散化处理,首先将分组依据的标准输入,即age_bins,放入参数为bins的参数中,参数x为分箱时输入的数据,labels为要返回的标签,但必须和bins的区间相对应。
代码:
age_bins = [20, 30, 40, 50, 60, 70]
data_original['age'] = pandas.cut(x = data_original['age'], bins = age_bins, labels = range(0, 5))
print("对年龄进行离散化,显示前5行结果:")
print(data_original.head(5))
结果:
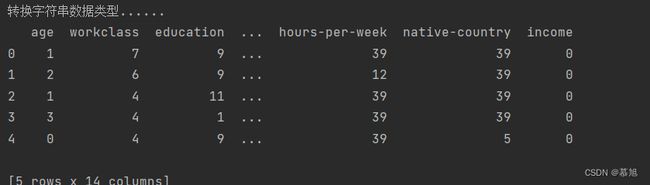
三、转换字符串数据类型使用LabelEncoder().fit_transform方法,由于此次实验的特征较多,全部列出来会造成重复代码太多,造成冗余,所以便创建列表column_names来储存特征,遍历列表对各个特征进行数据类型转换。
代码:
from sklearn.preprocessing import LabelEncoder
column_names = ['age', 'workclass', 'education', 'education-num', 'marital-status', 'occupation', \
'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week','native-country', 'income']
print("转换字符串数据类型......")
for name in column_names:
data_original[name] = LabelEncoder().fit_transform(data_original[name])
print(data_original.head(5))
结果:
四、这一问是这个实验最最最重要的地方,由于这个实验数据集有14个特征,有的特征对实验模型的影响较小,如果未经处理直接对所有的特征直接进行训练模型,会造成计算成本增加,降低速度。所以使用方差滤波法将方差小,对样本区分价值不高的特征筛选出来并进行淘汰,将剩下方差较大的特征存储到新的列表中,进行模型训练。
代码:
print("选择合适的若干特征字段")
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
labels = column_names.copy()
for i in range(len(column_names)):
if numpy.var(data_original[column_names[i]]) < 2:
labels.remove(column_names[i])
index.remove(i)
print(labels)
x = pandas.DataFrame(data_original, columns = labels)
print(x.head(5))
y = data_original[data_original.columns[-1]]
print(y.head(5))
在这里我新建index列表,进行存储特征的索引,如果判断出某个特征的方差少于2便将其移除列表,并且将其索引移除索引列表,最后将剩下的特征使用pandas.DataFrame函数提取出来,columns参数表示列索引,只需要将列输入进去就可以得到整列的数据,这也是为什么我们之前创建index列表,它可以使我们更方便地从data_original中提取出经过方差滤波之后的数据并将其存入到x中,将income作为分类标签存放到y中。
结果: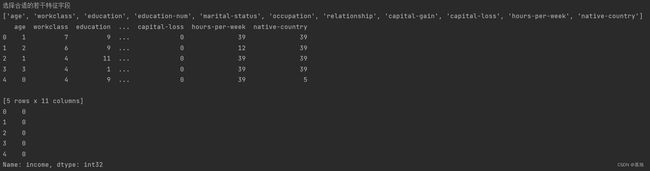
处理完数据之后就需要划分训练集和测试集。我们使用train_test_split方法进行划分,x_train x_test y_train y_test 分别为数据、标签的训练集和测试集,test_size参数表示为样本占比,题干要求比例为7:3,则test_size我们设置为0.3,但是如果test_size是整数的话就是表示样本的数量。
代码:
print('划分训练集测试集...')
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
五、既然我们已经得到了训练集和数据集,那么接下来的工作就比较轻松了,使用决策树以及随机森林分别对训练集处理训练模型,再使用accuracy_score方法计算出准确率。
# 决策树
DT = tree.DecisionTreeClassifier(criterion='gini', max_depth=10, min_samples_split=5)
DT.fit(x_train, y_train)
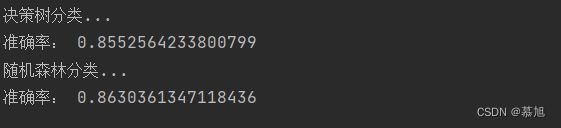
print('决策树分类...')
y_pre = DT.predict(x_test)
print('准确率:', accuracy_score(y_pre, y_test))
# 随机森林
RF = RandomForestClassifier(criterion='gini', max_depth=10, min_samples_split=5, n_estimators=20)
RF.fit(x_train, y_train)
print('随机森林分类...')
y_pre = RF.predict(x_test)
print('准确率:', accuracy_score(y_pre, y_test))
结果:
总代码:
import pandas
import numpy
from sklearn import tree
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
column_names = ['age', 'workclass', 'education', 'education-num', 'marital-status', 'occupation', \
'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week','native-country', 'income']
if __name__ == "__main__":
#第1问
print("1.载入数据......")
data_original = pandas.read_csv('income_classificatio.csv', header=0, names=column_names)
print("前5行数据为")
print(data_original.head(5))
print(data_original.shape)
# 第二问
age_bins = [20, 30, 40, 50, 60, 70]
data_original['age'] = pandas.cut(data_original['age'], age_bins, labels=range(0, 5))
print("对年龄进行离散化,显示前5行结果:")
print(data_original.head(5))
# 第三问
print("转换字符串数据类型......")
for name in column_names:
data_original[name] = LabelEncoder().fit_transform(data_original[name])
print(data_original.head(5))
# 第四问
print("选择合适的若干特征字段")
index = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
labels = column_names.copy()
for i in range(len(column_names)):
if numpy.var(data_original[column_names[i]]) < 2:
labels.remove(column_names[i])
index.remove(i)
print(labels)
x = pandas.DataFrame(data_original, columns = labels)
print(x.head(5))
y = data_original[data_original.columns[-1]]
print(y.head(5))
print('划分训练集测试集...')
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# 决策树
DT = tree.DecisionTreeClassifier(criterion='gini', max_depth=10, min_samples_split=5)
DT.fit(x_train, y_train)
print('决策树分类...')
y_pre = DT.predict(x_test)
print('准确率:', accuracy_score(y_pre, y_test))
# 随机森林
RF = RandomForestClassifier(criterion='gini', max_depth=10, min_samples_split=5, n_estimators=20)
RF.fit(x_train, y_train)
print('随机森林分类...')
y_pre = RF.predict(x_test)
print('准确率:', accuracy_score(y_pre, y_test))
由于版面原因,实验结果就是上面各个结果的汇总。
总结:
此次实验最关键的地方就是对特征的选择,以及决策树以及随机森林的理解。如果有对以上两种分类算法不了解的同学可以自己查询相关资料。好啦,此次实验已经成功完成。创作不易,看完的小伙伴们给个赞呦!