Flink中的CEP(二)
目录
12.4 模式的检测处理
12.4.1 将模式应用到流上
12.4.2 处理匹配事件
12.4.3 处理超时事件
12.4.4 处理迟到数据
12.5 CEP 的状态机实现
12.6 本章总结
12.4 模式的检测处理
Pattern API 是 Flink CEP 的核心,也是最复杂的一部分。不过利用 Pattern API 定义好模式 还只是整个复杂事件处理的第一步,接下来还需要将模式应用到事件流上、检测提取匹配的复杂事件并定义处理转换的方法,最终得到想要的输出信息。
12.4.1 将模式应用到流上
将模式应用到事件流上的代码非常简单,只要调用 CEP 类的静态方法.pattern(),将数据流(DataStream)和模式(Pattern)作为两个参数传入就可以了。最终得到的是一个 PatternStream:
DataStream inputStream = ...
Pattern pattern = ...
PatternStream patternStream = CEP.pattern(inputStream, pattern);
这里的 DataStream,也可以通过 keyBy 进行按键分区得到 KeyedStream,接下来对复杂事件的检测就会针对不同的 key 单独进行了。
模式中定义的复杂事件,发生是有先后顺序的,这里“先后”的判断标准取决于具体的时间语义。默认情况下采用事件时间语义,那么事件会以各自的时间戳进行排序;如果是处理时间语义,那么所谓先后就是数据到达的顺序。对于时间戳相同或是同时到达的事件,我们还可以在 CEP.pattern()中传入一个比较器作为第三个参数,用来进行更精确的排序:
// 可选的事件比较器
EventComparator comparator = ...
PatternStream patternStream = CEP.pattern(input, pattern, comparator); 得到 PatternStream 后,接下来要做的就是对匹配事件的检测处理了。
12.4.2 处理匹配事件
基于PatternStream 可以调用一些转换方法,对匹配的复杂事件进行检测和处理,并最终得到一个正常的 DataStream。这个转换的过程与窗口的处理类似:将模式应用到流上得到PatternStream,就像在流上添加窗口分配器得到 WindowedStream;而之后的转换操作,就像 定义具体处理操作的窗口函数,对收集到的数据进行分析计算,得到结果进行输出,最后回到DataStream 的类型来。 PatternStream 的转换操作主要可以分成两种:简单便捷的选择提取(select)操作,和更 加通用、更加强大的处理(process)操作。与 DataStream 的转换类似,具体实现也是在调用API 时传入一个函数类:选择操作传入的是一个 PatternSelectFunction,处理操作传入的则是一 个 PatternProcessFunction。
1. 匹配事件的选择提取(select)
处理匹配事件最简单的方式,就是从 PatternStream 中直接把匹配的复杂事件提取出来, 包装成想要的信息输出,这个操作就是“选择”(select)。
⚫ PatternSelectFunction
代码中基于 PatternStream 直接调用.select()方法,传入一个 PatternSelectFunction 作为参数。
PatternStream patternStream = CEP.pattern(inputStream, pattern);
DataStream result = patternStream.select(new MyPatternSelectFunction());
这 里 的 MyPatternSelectFunction 是 PatternSelectFunction 的一个具体实现 。
PatternSelectFunction 是 Flink CEP 提供的一个函数类接口,它会将检测到的匹配事件保存在一 个 Map 里,对应的 key 就是这些事件的名称。这里的“事件名称”就对应着在模式中定义的 每个个体模式的名称;而个体模式可以是循环模式,一个名称会对应多个事件,所以最终保存 在 Map 里的 value 就是一个事件的列表(List)。
下面是 MyPatternSelectFunction 的一个具体实现:
class MyPatternSelectFunction implements PatternSelectFunction{
@Override
public String select(Map> pattern) throws Exception {
Event startEvent = pattern.get("start").get(0);
Event middleEvent = pattern.get("middle").get(0);
return startEvent.toString() + " " + middleEvent.toString();
}
}
PatternSelectFunction 里需要实现一个 select()方法,这个方法每当检测到一组匹配的复杂事件时都会调用一次。它以保存了匹配复杂事件的 Map 作为输入,经自定义转换后得到输出信息返回。这里我们假设之前定义的模式序列中,有名为“start”和“middle”的两个个体模式, 于是可以通过这个名称从 Map 中选择提取出对应的事件。注意调用 Map 的.get(key)方法后得 到的是一个事件的 List;如果个体模式是单例的,那么 List 中只有一个元素,直接调用.get(0)就可以把它取出。
当然,如果个体模式是循环的,List 中就有可能有多个元素了。例如我们在 12.3.2 小节中 对连续登录失败检测的改进,我们可以将匹配到的事件包装成 String 类型的报警信息输出,代 码如下:
// 1. 定义 Pattern,登录失败事件,循环检测 3 次
Pattern pattern = Pattern
.begin("fails")
.where(new SimpleCondition() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
}).times(3).consecutive();
// 2. 将 Pattern 应用到流上,检测匹配的复杂事件,得到一个 PatternStream
PatternStream patternStream = CEP.pattern(stream, pattern);
// 3. 将匹配到的复杂事件选择出来,然后包装成报警信息输出
patternStream
.select(new PatternSelectFunction() {
@Override
public String select(Map> map) throws
Exception {
// 只有一个模式,匹配到了 3 个事件,放在 List 中
LoginEvent first = map.get("fails").get(0);
LoginEvent second = map.get("fails").get(1);
LoginEvent third = map.get("fails").get(2);
return first.userId + " 连续三次登录失败!登录时间:" + first.timestamp
+ ", " + second.timestamp + ", " + third.timestamp;
}
})
.print("warning");
我们定义的模式序列中只有一个循环模式 fails,它会将检测到的 3 个登录失败事件保存到 一个列表(List)中。所以第三步处理匹配的复杂事件时,我们从 map 中获取模式名 fails 对应 的事件,拿到的是一个 List,从中按位置索引依次获取元素就可以得到匹配的三个登录失败事 件。
运行程序进行测试,会发现结果与之前完全一样。
⚫ PatternFlatSelectFunction
除此之外,PatternStream 还有一个类似的方法是.flatSelect(),传入的参数是一个PatternFlatSelectFunction。从名字上就能看出,这是 PatternSelectFunction 的“扁平化”版本;内部需要实现一个 flatSelect()方法,它与之前 select()的不同就在于没有返回值,而是多了一个收 集器(Collector)参数 out,通过调用 out.collet()方法就可以实现多次发送输出数据了。
例如上面的代码可以写成:
// 3. 将匹配到的复杂事件选择出来,然后包装成报警信息输出
patternStream.flatSelect(new PatternFlatSelectFunction() {
@Override
public void flatSelect(Map> map,
Collector out) throws Exception {
LoginEvent first = map.get("fails").get(0);
LoginEvent second = map.get("fails").get(1);
LoginEvent third = map.get("fails").get(2);
out.collect(first.userId + " 连续三次登录失败!登录时间:" + first.timestamp +
", " + second.timestamp + ", " + third.timestamp);
}
}).print("warning");
可见 PatternFlatSelectFunction 使用更加灵活,完全能够覆盖 PatternSelectFunction 的功能。 这跟 FlatMapFunction 与 MapFunction 的区别是一样的。
2. 匹配事件的通用处理(process)
自 1.8 版本之后,Flink CEP 引入了对于匹配事件的通用检测处理方式,那就是直接调用PatternStream 的.process()方法,传入一个 PatternProcessFunction。这看起来就像是我们熟悉的 处理函数(process function),它也可以访问一个上下文(Context),进行更多的操作。
所以 PatternProcessFunction 功能更加丰富、调用更加灵活,可以完全覆盖其他接口,也就 成为了目前官方推荐的处理方式。事实上,PatternSelectFunction 和 PatternFlatSelectFunction在 CEP 内部执行时也会被转换成 PatternProcessFunction。
我们可以使用 PatternProcessFunction 将之前的代码重写如下:
package com.atguigu.chapter12;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternSelectFunction;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.functions.PatternProcessFunction;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.time.Duration;
import java.util.List;
import java.util.Map;
public class LoginFailDetectProExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
KeyedStream stream = env.fromElements(
new LoginEvent("user_1", "192.168.0.1", "fail", 2000L),
new LoginEvent("user_1", "192.168.0.2", "fail", 3000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 4000L),
new LoginEvent("user_1", "171.56.23.10", "fail", 5000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 7000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 8000L),
new LoginEvent("user_2", "192.168.1.29", "success", 6000L)
)
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(LoginEvent loginEvent, long l) {
return loginEvent.timestamp;
}
}))
.keyBy(data -> data.userId);
//1.定义一个模式(Pattern):连续三次登录失败
Pattern pattern = Pattern.begin("fail") //开始事件的名字(标签)
.where(new SimpleCondition() {
@Override
public boolean filter(LoginEvent value) throws Exception {
return value.eventType.equals("fail");
}
}).times(3).consecutive();//指定严格近邻的连续三次登录失败
//2.将Pattern应用到DataStream上,检测满足规则的复杂事件,得到一个PatternStream;
PatternStream patternStream = CEP.pattern(stream, pattern);
//3.对 PatternStream 进行转换处理,将检测到的复杂事件提取出来,包装成报警信息输出。
SingleOutputStreamOperator warningStream = patternStream.process(new PatternProcessFunction() {
@Override
public void processMatch(Map> map, Context context, Collector collector) throws Exception {
//提取三次登录失败事件
LoginEvent firstFailEvent =map.get("fail").get(0);
LoginEvent secondFailEvent =map.get("fail").get(1);
LoginEvent thirdFailEvent =map.get("fail").get(2);
collector.collect(firstFailEvent.userId + "连续三次登录失败!登录时间为:" +
firstFailEvent.timestamp + "," +
secondFailEvent.timestamp + "," +
thirdFailEvent.timestamp + ".");
}
});
//打印输出
warningStream.print("warning");
env.execute();
}
}
可以看到,PatternProcessFunction 中必须实现一个 processMatch()方法;这个方法与之前 的 flatSelect()类似,只是多了一个上下文 Context 参数。利用这个上下文可以获取当前的时间 信息,比如事件的时间戳(timestamp)或者处理时间(processing time);还可以调用.output()方法将数据输出到侧输出流。侧输出流的功能是处理函数的一大特性,我们已经非常熟悉;而 在 CEP 中,侧输出流一般被用来处理超时事件。
12.4.3 处理超时事件
复杂事件的检测结果一般只有两种:要么匹配,要么不匹配。检测处理的过程具体如下:
(1)如果当前事件符合模式匹配的条件,就接受该事件,保存到对应的 Map 中;
(2)如果在模式序列定义中,当前事件后面还应该有其他事件,就继续读取事件流进行检测;如果模式序列的定义已经全部满足,那么就成功检测到了一组匹配的复杂事件,调用PatternProcessFunction 的 processMatch()方法进行处理;
(3)如果当前事件不符合模式匹配的条件,就丢弃该事件;
(4)如果当前事件破坏了模式序列中定义的限制条件,比如不满足严格近邻要求,那么 当前已检测的一组部分匹配事件都被丢弃,重新开始检测。
不过在有时间限制的情况下,需要考虑的问题会有一点特别。比如我们用.within()指定了 模式检测的时间间隔,超出这个时间当前这组检测就应该失败了。然而这种“超时失败”跟真 正的“匹配失败”不同,它其实是一种“部分成功匹配”;因为只有在开头能够正常匹配的前提下,没有等到后续的匹配事件才会超时。所以往往不应该直接丢弃,而是要输出一个提示或报警信息。这就要求我们有能力捕获并处理超时事件。
1. 使用 PatternProcessFunction 的侧输出流
在 Flink CEP 中 ,提供了一个专门捕捉超时的部分匹配事件的接口, 叫 作TimedOutPartialMatchHandler。这个接口需要实现一个 processTimedOutMatch()方法,可以将 超时的、已检测到的部分匹配事件放在一个 Map 中,作为方法的第一个参数;方法的第二个参数则是 PatternProcessFunction 的上下文 Context。所以这个接口必须与 PatternProcessFunction结合使用,对处理结果的输出则需要利用侧输出流来进行。
代码中的调用方式如下:
class MyPatternProcessFunction extends PatternProcessFunction
implements TimedOutPartialMatchHandler {
// 正常匹配事件的处理
@Override
public void processMatch(Map> match, Context ctx,
Collector out) throws Exception{
...
}
// 超时部分匹配事件的处理
@Override
public void processTimedOutMatch(Map> match, Context ctx)
throws Exception{
Event startEvent = match.get("start").get(0);
OutputTag outputTag = new OutputTag("time-out"){};
ctx.output(outputTag, startEvent);
}
} 我们在 processTimedOutMatch()方法中定义了一个输出标签(OutputTag)。调用 ctx.output()方法,就可以将超时的部分匹配事件输出到标签所标识的侧输出流了。
2. 使用 PatternTimeoutFunction
上文提到的PatternProcessFunction通过实现TimedOutPartialMatchHandler接口扩展出了处 理超时事件的能力,这是官方推荐的做法。此外,Flink CEP 中也保留了简化版的PatternSelectFunction,它无法直接处理超时事件,不过我们可以通过调用 PatternStream的.select()方法时多传入一个 PatternTimeoutFunction 参数来实现这一点。 PatternTimeoutFunction 是早期版本中用于捕获超时事件的接口。它需要实现一个 timeout()方法,同样会将部分匹配的事件放在一个 Map 中作为参数传入,此外还有一个参数是当前的 时间戳。提取部分匹配事件进行处理转换后,可以将通知或报警信息输出。
由于调用.select()方法后会得到唯一的 DataStream,所以正常匹配事件和超时事件的处理 结果不应该放在同一条流中。正常匹配事件的处理结果会进入转换后得到的 DataStream,而超 时事件的处理结果则会进入侧输出流;这个侧输出流需要另外传入一个侧输出标签(OutputTag) 来指定。
所以最终我们在调用 PatternStream 的.select()方法时需要传入三个参数:侧输出流标签( OutputTag ), 超时事件处理函数 PatternTimeoutFunction ,匹配事件提取函数PatternSelectFunction。下面是一个代码中的调用方式:
// 定义一个侧输出流标签,用于标识超时侧输出流
OutputTag timeoutTag = new OutputTag("timeout"){};
// 将匹配到的,和超时部分匹配的复杂事件提取出来,然后包装成提示信息输出
SingleOutputStreamOperator resultStream = patternStream
.select(timeoutTag,
// 超时部分匹配事件的处理
new PatternTimeoutFunction() {
@Override
public String timeout(Map> pattern, long
timeoutTimestamp) throws Exception {
Event event = pattern.get("start").get(0);
return "超时:" + event.toString();
}
},
// 正常匹配事件的处理
new PatternSelectFunction() {
@Override
public String select(Map> pattern) throws Exception
{
...
}
}
);
// 将正常匹配和超时部分匹配的处理结果流打印输出
resultStream.print("matched");
resultStream.getSideOutput(timeoutTag).print("timeout");
这里需要注意的是,在超时事件处理的过程中,从 Map 里只能取到已经检测到匹配的那 些事件;如果取可能未匹配的事件并调用它的对象方法,则可能会报空指针异常 (NullPointerException)。另外,超时事件处理的结果进入侧输出流,正常匹配事件的处理结果进入主流,两者的数据类型可以不同。
3. 应用实例
接下来我们看一个具体的应用场景。
在电商平台中,最终创造收入和利润的是用户下单购买的环节。用户下单的行为可以表明 用户对商品的需求,但在现实中,并不是每次下单都会被用户立刻支付。当拖延一段时间后, 用户支付的意愿会降低。所以为了让用户更有紧迫感从而提高支付转化率,同时也为了防范订 单支付环节的安全风险,电商网站往往会对订单状态进行监控,设置一个失效时间(比如 15分钟),如果下单后一段时间仍未支付,订单就会被取消。
首先定义出要处理的数据类型。我们面对的是订单事件,主要包括用户对订单的创建(下 单)和支付两种行为。
因此可以定义 POJO 类 OrderEvent 如下,其中属性字段包括用户 ID、 订单 ID、事件类型(操作类型)以及时间戳。
POJO类:
package com.atguigu.chapter12;
public class OrderEvent {
public String userId;
public String orderId;
public String eventType;
public Long timestamp;
public OrderEvent() {
}
public OrderEvent(String userId, String orderId, String eventType, Long
timestamp) {
this.userId = userId;
this.orderId = orderId;
this.eventType = eventType;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "OrderEvent{" +
"userId='" + userId + '\'' +
"orderId='" + orderId + '\'' +
", eventType='" + eventType + '\'' +
", timestamp=" + timestamp + '}';
}
}
当前需求的重点在于对超时未支付的用户进行监控提醒,也就是需要检测有下单行为、但15分钟内没有支付行为的复杂事件。在下单和支付之间,可以有其他操作(比如对订单的修改),所以两者之间是宽松近邻关系。
测试类:
package com.atguigu.chapter12;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.functions.PatternProcessFunction;
import org.apache.flink.cep.functions.TimedOutPartialMatchHandler;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
import java.util.List;
import java.util.Map;
public class OrderTimeOutDetectExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.获取数据源
KeyedStream stream = env.fromElements(
new OrderEvent("user_1", "order_1", "create", 1000L),
new OrderEvent("user_2", "order_2", "create", 2000L),
new OrderEvent("user_1", "order_1", "modify", 10 * 1000L),
new OrderEvent("user_1", "order_1", "pay", 60 * 1000L),
new OrderEvent("user_2", "order_3", "create", 10 * 60 * 1000L),
new OrderEvent("user_2", "order_3", "pay", 20 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(OrderEvent orderEvent, long l) {
return orderEvent.timestamp;
}
}))
.keyBy(data -> data.orderId);
//2.定义模式
Pattern pattern = Pattern.begin("create")
.where(new SimpleCondition() {
@Override
public boolean filter(OrderEvent orderEvent) throws Exception {
return orderEvent.eventType.equals("create");
}
})
.followedBy("pay")
.where(new SimpleCondition() {
@Override
public boolean filter(OrderEvent orderEvent) throws Exception {
return orderEvent.eventType.equals("pay");
}
})
.within(Time.minutes(15));
//3.将当前模式应用到当前数据流中
PatternStream patternStream = CEP.pattern(stream, pattern);
//4.定义一个测输出流标签,用于输出超时事件
OutputTag timeoutTag = new OutputTag("timeout"){};
//5.将完全匹配和超时匹配的复杂事件提取出来,进行处理
SingleOutputStreamOperator result = patternStream.process(new OrderPayMatch());
//6.打印输出
result.print("payed: ");//完全匹配
result.getSideOutput(timeoutTag).print("timeout: ");//超时匹配
env.execute();
}
//自定义PatternProcessFunction
public static class OrderPayMatch extends PatternProcessFunction implements TimedOutPartialMatchHandler {
//提取完全匹配事件,并输出
@Override
public void processMatch(Map> map, Context context, Collector collector) throws Exception {
//获取当前的支付事件
OrderEvent payEvent = map.get("pay").get(0);
collector.collect("用户"+ payEvent.userId+" 订单 "+ payEvent.orderId + " 已支付!");
}
//提取超时匹配事件,并输出
@Override
public void processTimedOutMatch(Map> map, Context context) throws Exception {
//获取当前的下单(create)事件
OrderEvent createEvent = map.get("create").get(0);
OutputTag timeoutTag = new OutputTag("timeout"){};
context.output(timeoutTag,"用户"+ createEvent.userId+" 订单 "+ createEvent.orderId + " 超时未支付!");
}
}
}
12.4.4 处理迟到数据
CEP 主要处理的是先后发生的一组复杂事件,所以事件的顺序非常关键。前面已经说过, 事件先后顺序的具体定义与时间语义有关。如果是处理时间语义,那比较简单,只要按照数据处理的系统时间算就可以了;而如果是事件时间语义,需要按照事件自身的时间戳来排序。这 就有可能出现时间戳大的事件先到、时间戳小的事件后到的现象,也就是所谓的“乱序数据”或“迟到数据”。
在 Flink CEP 中沿用了通过设置水位线(watermark)延迟来处理乱序数据的做法。当一个 事件到来时,并不会立即做检测匹配处理,而是先放入一个缓冲区(buffer)。缓冲区内的数据, 会按照时间戳由小到大排序;当一个水位线到来时,就会将缓冲区中所有时间戳小于水位线的 事件依次取出,进行检测匹配。这样就保证了匹配事件的顺序和事件时间的进展一致,处理的顺序就一定是正确的。这里水位线的延迟时间,也就是事件在缓冲区等待的最大时间。
这样又会带来另一个问题:水位线延迟时间不可能保证将所有乱序数据完美包括进来,总会有一些事件延迟比较大,以至于等它到来的时候水位线早已超过了它的时间戳。这时之前的数据都已处理完毕,这样的“迟到数据”就只能被直接丢弃了——这与窗口对迟到数据的默认处理一致。
我们自然想到,如果不希望迟到数据丢掉,应该也可以借鉴窗口的做法。Flink CEP同样提供了将迟到事件输出到侧输出流的方式 : 我们可以基于 PatternStream 直接调 用.sideOutputLateData()方法,传入一个 OutputTag,将迟到数据放入侧输出流另行处理。代码 中调用方式如下:
PatternStream patternStream = CEP.pattern(input, pattern);
// 定义一个侧输出流的标签
OutputTag lateDataOutputTag = new OutputTag("late-data"){};
SingleOutputStreamOperator result = patternStream
.sideOutputLateData(lateDataOutputTag) // 将迟到数据输出到侧输出流
.select(
// 处理正常匹配数据
new PatternSelectFunction() {...}
);
// 从结果中提取侧输出流
DataStream lateData = result.getSideOutput(lateDataOutputTag);
可以看到,整个处理流程与窗口非常相似。经处理匹配数据得到结果数据流之后,可以调用.getSideOutput()方法来提取侧输出流,捕获迟到数据进行额外处理。
12.5 CEP 的状态机实现
Flink CEP 中对复杂事件的检测,关键在模式的定义。我们会发现 CEP 中模式的定义方式 比较复杂,而且与正则表达式非常相似:正则表达式在字符串上匹配符合模板的字符序列,而Flink CEP 则是在事件流上匹配符合模式定义的复杂事件。
前面我们分析过 CEP 检测处理的流程,可以认为检测匹配事件的过程中会有“初始(没有任何匹配)”“检测中(部分匹配成功)”“匹配成功”“匹配失败”等不同的“状态”。随着每个事件的到来,都会改变当前检测的“状态”;而这种改变跟当前事件的特性有关、也跟当前 所处的状态有关。这样的系统,其实就是一个“状态机”(state machine)。这也正是正则表达式底层引擎的实现原理。
所以 Flink CEP 的底层工作原理其实与正则表达式是一致的,是一个“非确定有限状态自动机”(Nondeterministic Finite Automaton,NFA)。NFA 的原理涉及到较多数学知识,我们这 里不做详细展开,而是用一个具体的例子来说明一下状态机的工作方式,以更好地理解 CEP的原理。
我们回顾一下 12.2.2 小节中的应用案例,检测用户连续三次登录失败的复杂事件。用 Flink CEP 中的 Pattern API 可以很方便地把它定义出来;如果我们现在不用 CEP,而是用 DataStream API 和处理函数来实现,应该怎么做呢?
这需要设置状态,并根据输入的事件不断更新状态。当然因为这个需求不是很复杂,我们 也可以用嵌套的 if-else 条件判断将它实现,不过这样做的代码可读性和扩展性都会很差。更好的方式,就是实现一个状态机。
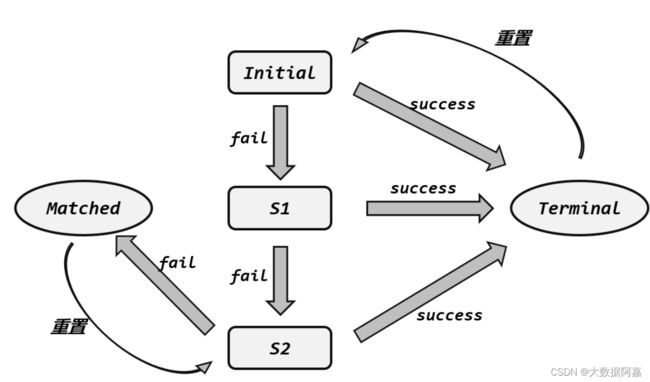
如图所示,即为状态转移的过程,从初始状态(INITIAL)出发,遇到一个类型为fail 的登录失败事件,就开始进入部分匹配的状态;目前只有一个 fail 事件,我们把当前状态 记作 S1。基于 S1 状态,如果继续遇到 fail 事件,那么就有两个 fail 事件,记作 S2。基于 S2状态如果再次遇到 fail 事件,那么就找到了一组匹配的复杂事件,把当前状态记作 Matched, 就可以输出报警信息了。需要注意的是,报警完毕,需要立即重置状态回 S2;因为如果接下来再遇到 fail 事件,就又满足了新的连续三次登录失败,需要再次报警。
而不论是初始状态,还是 S1、S2 状态,只要遇到类型为 success 的登录成功事件,就会 跳转到结束状态,记作 Terminal。此时当前检测完毕,之前的部分匹配应该全部清空,所以需 要立即重置状态到 Initial,重新开始下一轮检测。所以这里我们真正参与状态转移的,其实只 有 Initial、S1、S2 三个状态,Matched 和 Terminal 是为了方便我们做其他操作(比如输出报警、 清空状态)的“临时标记状态”,不等新事件到来马上就会跳转。
完整代码如下:
package com.atguigu.chapter12;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class NFAExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.获取登录数据源,并按用户id进行分组
KeyedStream stream = env.fromElements(
new LoginEvent("user_1", "192.168.0.1", "fail", 2000L),
new LoginEvent("user_1", "192.168.0.2", "fail", 3000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 4000L),
new LoginEvent("user_1", "171.56.23.10", "fail", 5000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 7000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 8000L),
new LoginEvent("user_2", "192.168.1.29", "success", 6000L)
).keyBy(data -> data.userId);
//2.数据按照顺序依次输入,用状态机进行处理,状态跳转
SingleOutputStreamOperator warningStream = stream.flatMap(new StateMachineMapper());
//3.打印输出
warningStream.print();
env.execute();
}
//实现自定义的RichFlatMapFunction
public static class StateMachineMapper extends RichFlatMapFunction{
//声明当前状态机当前的状态
ValueState currentState;
@Override
public void open(Configuration parameters) throws Exception {
currentState=getRuntimeContext().getState(new ValueStateDescriptor("state",State.class));
}
@Override
public void flatMap(LoginEvent value, Collector collector) throws Exception {
//如果状态为空,进行初始化
State state=currentState.value();
if(state==null){
state=state.Initial;
}
//跳转到下一状态
State nextState=state.transition(value.eventType);
//判断当前状态的特殊情况,直接进行跳转
if(nextState==State.Matched){
//检测到了匹配,输出报警信息;不更新状态就是跳转回S2
collector.collect(value.userId + "连续三次登录失败");
}else if (nextState== State.Terminal){
//状态更新,直接状态更新为初始状态,重新开始检测
currentState.update(State.Initial);
}else {
//状态覆盖
currentState.update(nextState);
}
}
}
//状态实现
public enum State{
Terminal, //匹配失败,终止状态
Matched, //匹配成功
//S2状态,传入基于S2状态可以进行的一系列状态转移
S2(new Transition("fail",Matched),new Transition("success",Terminal)),
//S1状态
S1(new Transition("fail",S2),new Transition("success",Terminal)),
//初始状态
Initial(new Transition("fail",S1),new Transition("success",Terminal)),
;
private Transition[] transitions; //当前状态的转移规则
State(Transition... transitions){
this.transitions=transitions;
}
//状态转移方法
public State transition(String eventType){
for(Transition transition:transitions){
if(transition.getEventType().equals(eventType)){
return transition.getTargetState();
}
}
//回到初始状态
return Initial;
}
}
//定义一个状态转移类,包含当前引起状态转移的事件类型,以及转移的目标状态
public static class Transition{
private String eventType;
private State targetState;
public Transition(String eventType, State targetState) {
this.eventType = eventType;
this.targetState = targetState;
}
public String getEventType() {
return eventType;
}
public State getTargetState() {
return targetState;
}
}
}
运行代码,可以看到输出与之前 CEP 的实现是完全一样的。显然,如果所有的复杂事件处理都自己设计状态机来实现是非常繁琐的,而且中间逻辑非常容易出错;所以 Flink CEP 将 底层 NFA 全部实现好并封装起来,这样我们处理复杂事件时只要调上层的 Pattern API 就可以, 无疑大大降低了代码的复杂度,提高了编程的效率。
12.6 本章总结
Flink CEP 是 Flink 对复杂事件处理提供的强大而高效的应用库。本章中我们从一个简单 的应用实例出发,详细讲解了 CEP 的核心内容——Pattern API 和模式的检测处理,并以案例 说明了对超时事件和迟到数据的处理。最后进行了深度扩展,举例讲解了 CEP 的状态机实现, 这部分大家可以只做原理了解,不要求完全实现状态机的代码。 CEP 在实际生产中有非常广泛的应用。对于大数据分析而言,应用场景主要可以分为统 计分析和逻辑分析。企业的报表统计、商业决策都离不开统计分析,这部分需求在目前企业的 分析指标中占了很大的比重,实时的流数据统计可以通过 Flink SQL 方便地实现;而逻辑分析 可以进一步细分为风险控制、数据挖掘、用户画像、精准推荐等各个应用场景,如今对实时性 要求也越来越高,Flink CEP 就可以作为对流数据进行逻辑分析、进行实时风控和推荐的有力工具。
所以 DataStream API 和处理函数是 Flink 应用的基石,而 SQL 和 CEP 就是 Flink 大厦顶层 扩展的两大工具。Flink SQL 也提供了与 CEP 相结合的“模式识别”(Pattern Recognition)语 句——MATCH_RECOGNIZE,可以支持在 SQL 语句中进行复杂事件处理。尽管目前还不完 善,不过相信随着 Flink 的进一步发展,Flink SQL 和 CEP 将对程序员更加友好,功能也将更 加强大,全方位实现大数据实时流处理的各种应用需求。