机器学习sklearn实战
机器学习sklearn实战
今天开始学习机器学习实战,好多年都没有下定决心把这个学好。
文章目录
- 机器学习sklearn实战
- 前言
- 一、感知机
-
- 1.sklearn 实现感知机
- 二、决策树
-
- 1 sklearn.tree.DecisionTreeClassifier 详细说明
- 2 绘制决策树
-
- 2.1 Graphviz形式输出决策树
- 2.2 绘制决策平面
- 2.3 交叉验证
- 2.4 决策树的预剪枝与后剪枝
前言
记录学习sklearn
一、感知机
1.sklearn 实现感知机
sklearn.linear_model import Perceptron的使用方法:
实现:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.linear_model import Perceptron
import matplotlib.pyplot as plt
# 生成二分类的样本
x, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_informative=1, n_clusters_per_class=1)
# print(x)
# 训练数据和测试数据
x_data_train = x[:800, :] #[[1,2],[3,4]]
y_data_train = y[:800] #[1,0]
x_data_test = x[800:, :]
y_data_test = y[800:]
# 构建感知机
clf = Perceptron(fit_intercept=False, max_iter=30, shuffle=False)
#使用训练数据进行训练
clf.fit(x_data_train,y_data_train)
# 得到训练结果,权重矩阵
print(clf.coef_)
# 输出为:[[3.72535338 0.96982592]]
# 超平面的截距,此处输出为:[0.]
print(clf.intercept_)
# 预测
acc = clf.score(x_data_test, y_data_test)
print(acc) #0.98
# 正例和反例
positive_x1 = [x[i, 0] for i in range(1000) if y[i] == 1]
positive_x2 = [x[i, 1] for i in range(1000) if y[i] == 1]
negetive_x1 = [x[i, 0] for i in range(1000) if y[i] == 0]
negetive_x2 = [x[i, 1] for i in range(1000) if y[i] == 0]
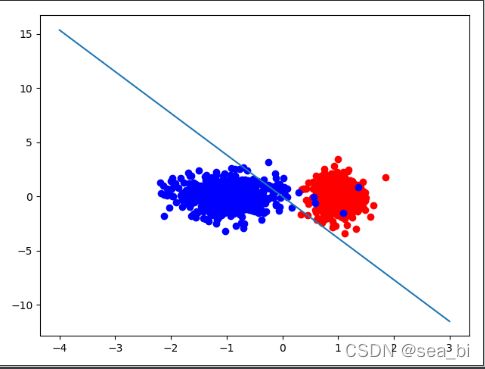
plt.scatter(positive_x1, positive_x2, c='red')
plt.scatter(negetive_x1, negetive_x2, c='blue')
# 画出超平面(在本例中即是一条直线)
line_x = np.arange(-4, 4)
line_y = line_x * (-clf.coef_[0][0] / clf.coef_[0][1]) - clf.intercept_
plt.plot(line_x, line_y)
plt.show()
二、决策树
1 sklearn.tree.DecisionTreeClassifier 详细说明
sklearn.tree.DecisionTreeClassifier()函数用于构建决策树,默认使用CART算法,现对该函数参数进行说明,参考的是scikit-learn 0.20.3版本。
sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
criterion:选择结点划分质量的度量标准,默认使用‘gini’,即基尼系数,基尼系数是CART算法中采用的度量标准,
该参数还可以设置为 “entropy”,表示信息增益,是C4.5算法中采用的度量标准。
splitter:结点划分时的策略,默认使用‘best’。‘best’ 表示依据选用的criterion标准,选用最优划分属性来划分该结点,一般用于训练样本数据量不大的场合,因为选择最优划分属性需要计算每种候选属性下划分的结果;该参数还可以设置为“random”,表示最优的随机划分属性,一般用于训练数据量较大的场合,可以减少计算量,但是具体如何实现最优随机划分暂时不太明白,这需要查看该部分的源码。
max_depth:设置决策树的最大深度,默认为None。None表示不对决策树的最大深度作约束,直到每个叶子结点上的样本均属于同一类,或者少于min_samples_leaf参数指定的叶子结点上的样本个数。也可以指定一个整型数值,设置树的最大深度,在样本数据量较大时,可以通过设置该参数提前结束树的生长,改善过拟合问题,但一般不建议这么做,过拟合问题还是通过剪枝来改善比较有效。
min_samples_split:当对一个内部结点划分时,要求该结点上的最小样本数,默认为2。
min_samples_leaf:设置叶子结点上的最小样本数,默认为1。当尝试划分一个结点时,只有划分后其左右分支上的样本个数不小于该参数指定的值时,才考虑将该结点划分,换句话说,当叶子结点上的样本数小于该参数指定的值时,则该叶子节点及其兄弟节点将被剪枝。在样本数据量较大时,可以考虑增大该值,提前结束树的生长。
min_weight_fraction_leaf :在引入样本权重的情况下,设置每一个叶子节点上样本的权重和的最小值,一旦某个叶子节点上样本的权重和小于该参数指定的值,则该叶子节点会联同其兄弟节点被减去,即其父结点不进行划分。该参数默认为0,表示不考虑权重的问题,若样本中存在较多的缺失值,或样本类别分布偏差很大时,会引入样本权重,此时就要谨慎设置该参数。
max_features:划分结点、寻找最优划分属性时,设置允许搜索的最大属性个数,默认为None。假设训练集中包含的属性个数为n,None表示搜索全部n个的候选属性;‘auto’表示最多搜索sqrt(n)个属性;sqrt表示最多搜索sqrt(n)个属性;‘log2’表示最多搜索log2(n)个属性;用户也可以指定一个整数k,表示最多搜索k个属性。需要说明的是,尽管设置了参数max_features,但是在至少找到一个有效(即在该属性上划分后,criterion指定的度量标准有所提高)的划分属性之前,最优划分属性的搜索不会停止。
random_state :当将参数splitter设置为‘random’时,可以通过该参数设置随机种子号,默认为None,表示使用np.random产生的随机种子号。
max_leaf_nodes : 设置决策树的最大叶子节点个数,该参数与max_depth等参数参数一起,限制决策树的复杂度,默认为None,表示不加限制。
min_impurity_decrease :打算划分一个内部结点时,只有当划分后不纯度(可以用criterion参数指定的度量来描述)减少值不小于该参数指定的值,才会对该结点进行划分,默认值为0。可以通过设置该参数来提前结束树的生长。
min_impurity_split : 打算划分一个内部结点时,只有当该结点上的不纯度不小于该参数指定的值时,才会对该结点进行划分,默认值为1e-7。该参数值0.25版本之后将取消,由min_impurity_decrease代替。
class_weight:设置样本数据中每个类的权重,这里权重是针对整个类的数据设定的,默认为None,即不施加权重。用户可以用字典型或者字典列表型数据指定每个类的权重,假设样本中存在4个类别,可以按照 [{0: 1, 1: 1}, {0: 1, 1: 5}, {0: 1, 1: 1}, {0: 1, 1: 1}] 这样的输入形式设置4个类的权重分别为1、5、1、1,而不是 [{1:1}, {2:5}, {3:1}, {4:1}]的形式。该参数还可以设置为‘balance’,此时系统会按照输入的样本数据自动的计算每个类的权重,计算公式为:n_samples / ( n_classes * np.bincount(y) ),其中n_samples表示输入样本总数,n_classes表示输入样本中类别总数,np.bincount(y) 表示计算属于每个类的样本个数,可以看到,属于某个类的样本个数越多时,该类的权重越小。若用户单独指定了每个样本的权重,且也设置了class_weight参数,则系统会将该样本单独指定的权重乘以class_weight指定的其类的权重作为该样本最终的权重。
presort : 设置对训练数据进行预排序,以提升结点最优划分属性的搜索,默认为False。在训练集较大时,预排序会降低决策树构建的速度,不推荐使用,但训练集较小或者限制树的深度时,使用预排序能提升树的构建速度。
代码:
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine = load_wine()
# 切分数据集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3)
'''
DecisionTreeClassifier() 模型方法中也包含非常多的参数值。例如:
criterion = gini/entropy 可以用来选择用基尼指数或者熵来做损失函数。
splitter = best/random 用来确定每个节点的分裂策略。支持 “最佳” 或者“随机”。
max_depth = int 用来控制决策树的最大深度,防止模型出现过拟合。
min_samples_leaf = int 用来设置叶节点上的最少样本数量,用于对树进行修剪。
'''
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) # 返回预测的准确度accuracy
print(score)
# 根据模型进行预测,模型拟合后,可以用于预测样本的分类
pre = clf.predict([[x for x in range(13)]])
print(pre)
# 可以预测样本属于每个分类(叶节点)的概率,(输出结果:0%,100%)
print(clf.predict_proba([[x for x in range(13)]]))
#拟合完后,可以用plot_tree()方法绘制出决策树来,如下图所示
tree.plot_tree(clf)
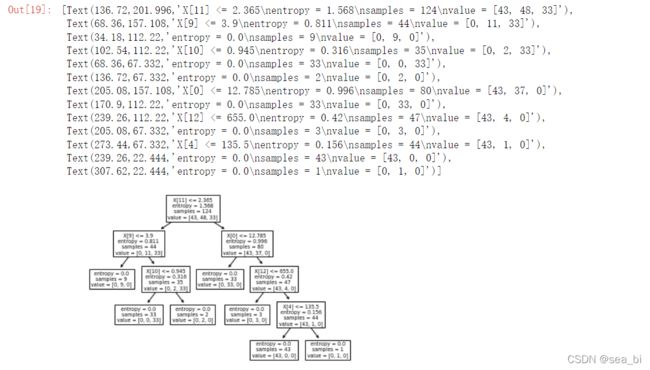
2 绘制决策树
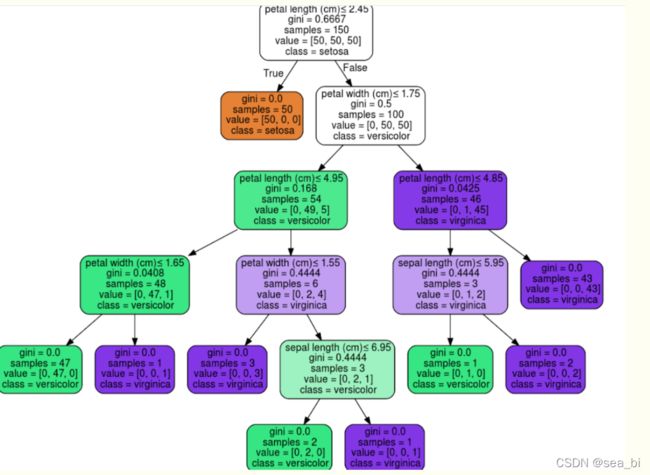
2.1 Graphviz形式输出决策树
export_graphviz 支持使用参数进行视觉优化,包括根据分类或者回归值绘制彩色的结点,也可以使用显式的变量或者类名。
Jupyter Notebook 还可以自动内联呈现这些绘图。
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph
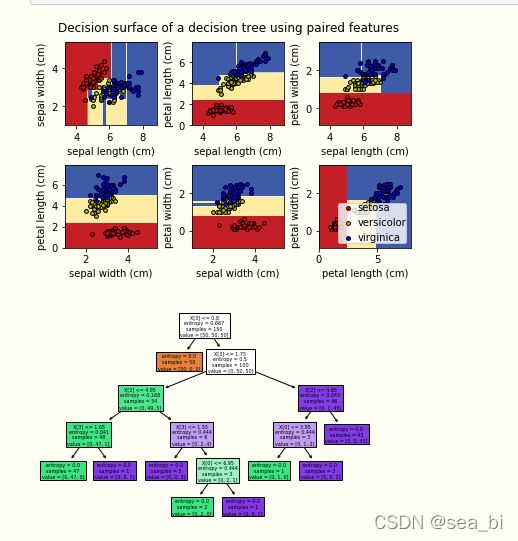
2.2 绘制决策平面
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
# Parameters
n_classes = 3
plot_colors = "ryb"
plot_step = 0.02
# Load data
iris = load_iris()
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3],
[1, 2], [1, 3], [2, 3]]):
# We only take the two corresponding features
X = iris.data[:, pair]
y = iris.target
# Train
clf = DecisionTreeClassifier().fit(X, y)
# Plot the decision boundary
plt.subplot(2, 3, pairidx + 1)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu)
plt.xlabel(iris.feature_names[pair[0]])
plt.ylabel(iris.feature_names[pair[1]])
# Plot the training points
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i],
cmap=plt.cm.RdYlBu, edgecolor='black', s=15)
plt.suptitle("Decision surface of a decision tree using paired features")
plt.legend(loc='lower right', borderpad=0, handletextpad=0)
plt.axis("tight")
plt.figure()
clf = DecisionTreeClassifier().fit(iris.data, iris.target)
plot_tree(clf, filled=True)
plt.show()
2.3 交叉验证
参考官网:https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation
cross_val_score()函数:
sklearn.model_selection.cross_val_score(
estimator,
X,
y=None,
groups=None,
scoring=None,
cv=’warn’,
n_jobs=None,
verbose=0,
fit_params=None,
pre_dispatch=‘2*n_jobs’,
error_score=’raise-deprecating’)
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.model_selection import cross_val_score
x,y=load_iris(return_X_y=True)
clf=tree.DecisionTreeClassifier()
clf.fit(x,y)
score = cross_val_score(clf,X,y,cv=10)
score

2.4 决策树的预剪枝与后剪枝
https://blog.csdn.net/zfan520/article/details/82454814