论文浅尝 | 深度神经网络的模型压缩

笔记整理:闵德海,东南大学硕士,研究方向为知识图谱
链接:https://arxiv.org/abs/1412.6550
动机
提高神经网络的深度通常可以提高网络性能,但它也使基于梯度的训练更加困难,因为更深的网络往往更加强的非线性。最近提出的知识蒸馏方法旨在获得小型和快速执行的模型,它已经表明参数量较小的学生网络可以较好的模仿更大的教师网络或网络集群的Soft Output。
在本文中,我们扩展了这一思想,允许训练一个比教师模型更深更薄的学生模型,不仅使用输出层的信息,还使用教师模型学习到的中间表示作为提示,以改善学生模型的训练过程和最终表现。由于学生模型中间隐含层一般会小于教师模型中间隐含层,因此引入附加参数将学生模型隐含层映射到教师隐含层的预测。
这使得我们可以训练更深的学生模型,他们可以更好地泛化或者运行得更快(这由所选学生模型的能力的权衡控制)。例如,在CIFAR-10上,我们完成了一个参数少近10.4倍的深度学生网络比一个更大、最先进的教师网络表现更好。
主要解决的问题
论文主要针对Hinton提出的知识蒸馏法进行扩展,允许Student网络可以比Teacher网络更深更窄,使用teacher网络的输出和中间层的特征作为提示,改进训练过程和student网络的性能。
贡献
(1)引入了intermediate-level hints来指导学生模型的训练。
(2)使用一个宽而浅的教师模型来训练一个窄而深的学生模型。
(3)在进行hint引导时,提出使用一个层来匹配hint层和guided层的输出shape,这在后人的工作里面常被称为adaptation layer。
方法
1. Hint-Based Training
将教师的hint layer作为监督,学生的guided layer作为被监督的对象,希望guided layer可以尽可能地去预测到hint layer的输出。
HT Loss表示如下:
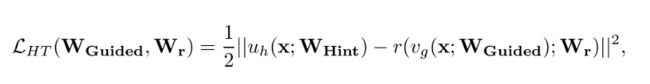
作者使用了一个回归层r(对应下图b中的Wr), 来对齐特征的shape。
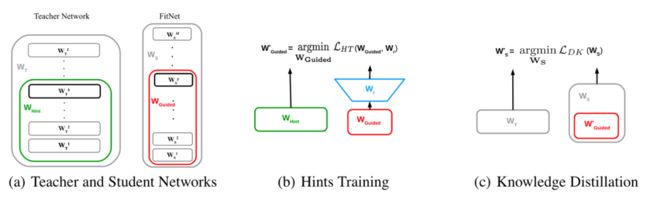
图1 模型的训练框架
此外,本文作者认为使用hint来进行引导是一种正则化手段,学生guided层越深,那么正则化作用就越明显,为了避免过度正则化,需要仔细选择hint和guided。
2. FITNET STAGE-WISE TRAINING
分成两个阶段:
(1)使用训练好的教师模型和随机初始化的学生模型,在第一阶段,用教师的hint来预训练学生的guided layer及之前的层。
(2)第二个阶段,使用经典的KD loss来对整个网络进行训练,KD loss为:

整体的蒸馏算法如下:

图2 蒸馏算法的伪代码
实验
1. 数据集
CIFAR-10:为了验证我们的方法,我们训练了一个最大输出卷积层的教师网络,设计了一个17层最大输出卷积层的FitNet,接着是一个最大输出全连接层和一个顶部的softmax层,大约有1/3的参数。学生网络的第11层被训练成模仿教师网络的第2层。在训练期间,我们使用随机翻转来增强数据。
SVHN: 由GoogleStreet View收集的32×32彩色房屋号码图像组成。训练集中有73,257张图像,测试集中有26,032张图像,还有531,131个较不困难的示例。我们训练了一个由11个最大输出卷积层、一个全连接层和一个softmax层组成的13层FitNet。
2. 结果
CIFAR-10数据集
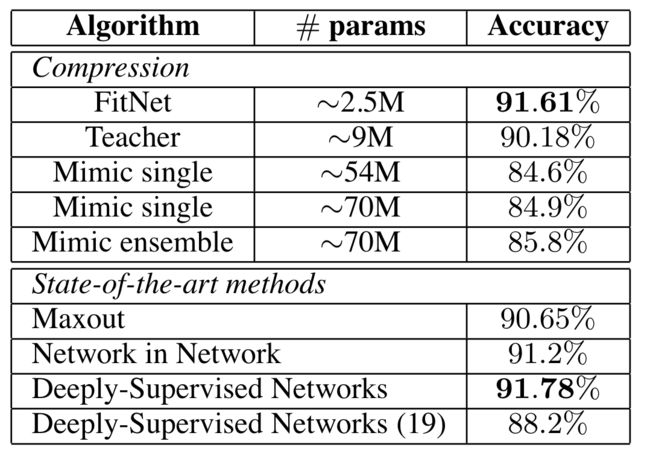
表1 CIFAR-10的准确率表现
表1总结了获得的结果。我们的学生模型胜过教师模型,同时需要明显较少的参数,这表明深度对于实现更好的表示至关重要。与网络压缩方法相比,我们的算法取得了出色的结果。即,学生网络的准确率达到91.61%,比之前的最佳表现者85.8%高得多,同时需要大约28倍的参数。与最先进的方法相比,我们的算法匹配了最佳的表现者。有人可能会质疑使用宽教师网络的隐藏状态来提示内部层的选择。一个直接的替代方案是使用所需的输出来提示它们。这可以通过几种不同的方式解决:(1)阶段性训练,其中第1阶段优化网络的前半部分以实现分类目标,第2阶段优化整个网络以实现分类目标。在这种情况下,第1阶段设置了网络参数的一个良好局部极小值,但此初始化似乎不能充分帮助第2阶段学习,导致它无法学习。
SVHN数据集
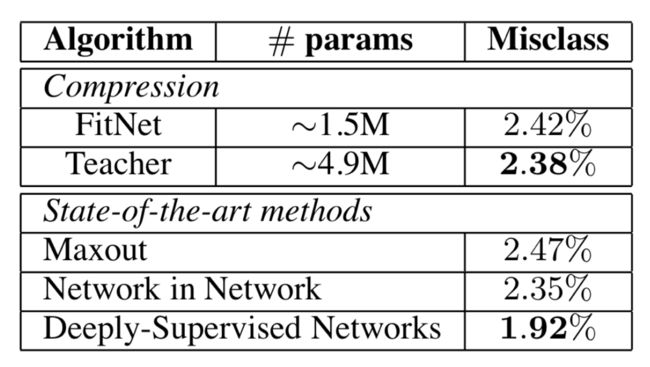
表2 SVHN的错误率
表2的数据表明尽管使用的只有教师网络容量的32%,但我们的FitNet实现了与教师网络相当的准确性。我们的FitNet在性能方面与其他最先进的方法(如Maxout和Network in Network)相当。
总结
本研究提出了一种新的框架,通过引入来自教师隐藏层的中间层提示来压缩宽而深的网络为更薄更深的网络。能够使用这些提示来训练具有更少参数的非常深的学生模型,这些模型可以比其教师模型更好地泛化和/或更快地运行。本研究提供了实证证据,表明使用教师网络的隐藏状态提示薄而深的网络的内部层比使用分类目标提示更好地泛化。在基准数据集上的实验强调,具有低容量的深度网络能够提取与具有多达10倍参数的网络相当甚至更好的特征表示。基于提示的训练表明,应更加努力地探索新的训练策略,以利用深度网络的强大力量。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。