Hadoop框架之MapReduce(一) : MapReduce概述
MapReduce概述
1. 什么是MapReduce呢 ?
MapReduce是一个"基于Hadoop的数据应用分析"核心框架,它是一个分布式运算程序的框架.也就是说,有了MapReduce,我们可以对互联网上的海量数据进行分析并进行运算,将数据整理成我们想要的样子.
2. MapReduce的核心思想
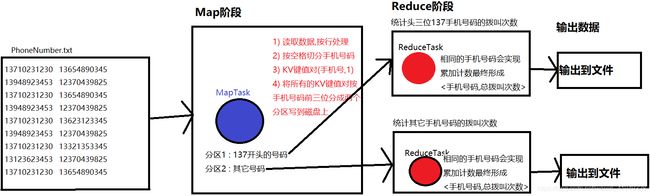
我们以一个实际需求案例来解释 : 假设现在有很多手机号码,需要统计每个手机号码主动拨叫的总次数,每次拨叫都会默认新增一条该手机号码的数据,我们需要将137开头的手机号码分到一个文件,其它手机号码分到另一个文件,那么MapReduce该如何工作呢?
首先我们要知道的是MapReduce是两个单词组合而成,想必你会知道是Map和Reduce
那么它们到底是干什么的呢?
(第一步)Map : 将一个文件中杂乱无章的数据进行分离形成一条一条相互独立的数据.并传递给Reduce(中间涉及分区和排序等知识在这里并不深入研究,若同学已了解过,则可以回忆一遍)
(第二步)Reduce : 将这一条一条数据进行汇总并且存储,组成有序的数据
好了...读到这里,我们应该能够想到首先我们要先把这个文件中的所有手机号码分成一条条相互独立的手机号码,这就是Map要做的工作,然后就把这一条条手机号码传给Reduce进行汇总并输出到两个文件中去(137号码组成的文件和其它号码组成的文件)
好了,让我们来开始理解MapReduce的工作模式吧!!!
假设我们这一个存满手机号码的文件小于128MB(Hadoop集群默认的块大小,若大于128MB的1.1倍则新增一个块,否则只创建一个块,若看不懂,则在这里只需要明白小于128MB就只开启一个块)
Map :
1 : 读取数据,并按行处理
2 : 按空格切分行内单词(这个案例的手机号之间默认不换行,以空格为间隔)
3 : 组成KV键值对 <手机号,1> (注意相同手机号的V值都是1,在Map阶段并不会对数据进行分析操作)
4 : 将所有KV键值对中的手机号(键),按照手机号前三位,分成两个区进行溢写到磁盘中
则此时会创建2个分区 : 分区1 : 137号码 分区2 : 其它号码组成
注意 : 每创建一个块就会有对应一个MapTask进行处理这个块的数据(也就是负责这个块的工作),所以多个块之间是并发执行而没有顺序
Reduce :
1 : 统计137开头的各手机号码的主动拨叫总次数并输出结果到文件中
2 : 统计其它手机号码的主动拨叫总次数并输出结果到文件中
注意 : Reduce的第一点和第二点是并发执行,它们使用的是两个不同的ReduceTask,并无先后执行顺序.
MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂则只能用多个MapReduce程序进行串行执行