高级IO详解——五种IO模型
什么是IO
这里以应用层与传输层的数据交互为例:
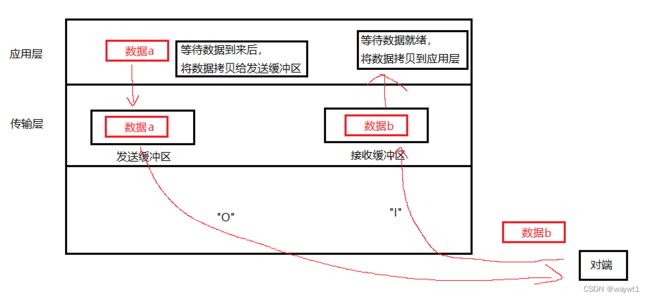 "O"过程:
"O"过程:
● 应用层等待用户层产生数据;
● 数据就绪后,将数据拷贝到发送缓冲区;
"I"过程:
● 接收缓冲区等待数据从对端发来;
● 数据收到后,将数据拷贝给应用层;
本质上,IO = 等 + 拷贝。IO的过程,其实就是等待数据加拷贝数据的过程。
什么是高效的IO
任何的IO过程中,都包含两个步骤,等待数据与拷贝数据。而且在实际的应用场景中,等待消耗的时间往往都远高于拷贝的时间。让IO更高效,最核心的办法就是让等待的时间尽量少。
所以,高效的IO本质就是,减少单位时间内,”等“的比重。
五种IO模型
五种IO模型包括:阻塞IO、非阻塞IO、信号驱动IO、IO多路转接和异步IO。
想象一个钓鱼的场景,有五个人在一起钓鱼。
● 张三:一个一心一意的人,在等待鱼上钩的过程中,什么都不做,专心等待;
● 李四:一个三心二意的人,在开始钓鱼后,就去做别的事了,一会看看书,一会听听音乐;
● 王五:一个聪明人,在鱼钩上挂了一个铃铛,当鱼上钩时,铃铛发出声音通知王五,而王五在等待期间,可以去做别的事;
● 赵六:一个有钱人,周围的人都只是用一根鱼竿在钓鱼,而赵六摆了一百根鱼竿同时钓鱼;
● 田七:一个老板,把钓鱼的事情吩咐给司机,让司机去完成钓鱼的整个过程,完成后,打电话通知田七,田七直接拿走了所有的鱼;
对于上面的场景,鱼竿可以理解为一个文件描述符 fd ,鱼可以理解为我们需要等待的资源。
张三对应的是阻塞等待,当数据还没就绪时,系统调用会一直等待,不做任何事情。所有的套接字,默认都是阻塞方式;
李四对应的是非阻塞等待,当数据还没就绪时,系统调用会直接以错误的形式返回。非阻塞IO往往需要程序员以循环的方式,反复尝试读写文件描述符,这个过程称为轮询。对CPU来说是较大的浪费,一般只有特定的场景下才使用;
王五对应的是信号驱动,内核将数据准备好的时候,使用 SIGIO 信号通知应用程序进行IO操作;
赵六对应的是多路转接,多路转接的等待方式与阻塞等待类似,不过核心区别在于,IO多路转接能同时等待多个资源的就绪状态;
田七对应的是异步IO,由内核将数据拷贝完成时,通知应用程序。与信号驱动不同的是,信号驱动是告诉应用程序何时可以开始拷贝数据;
socket就绪条件
读就绪
● socket 内核中,接收缓冲区中的字节数,大于等于低水位标记 SO_RCVLOWAT 。此时可以无阻塞的读该文件描述符,并且返回值大于0;
● socket TCP通信中,对端关闭连接,此时对该 socket 读,则返回0;
● 监听的 socket 上 有新的请求;
● socket 上有未处理的错误;
写就绪
● socket 内核中,发送缓冲区中的可用字节数(发送缓冲区的空闲位置大小),大于等于低水位标记 SO_SNDLOWAT ,此时可以无阻塞的写,并且返回值大于0;
● socket 的写操作被关闭(close或者shutdown)。对一个写操作被关闭的 socket 进行写操作,会触发 SIGPIPE 信号;
● 非阻塞式的 socket ,connect 连接成功或失败之后;
● socket 上有未读取的错误;
非阻塞IO
一个文件描述符,默认都是阻塞IO。
但我们可以通过设置文件描述符的属性,将其设置成非阻塞。
fcntl
函数原型
#include
#include
int fcntl(int fd, int cmd, .../* arg */ ); 传入的cmd的值不同,后面追加的参数也不相同。
函数功能
● 复制一个现有的文件描述符(cmd=F_DUPFD);
● 获得/设置文件描述符标记(cmd=F_GETFD 或 F_SETFD);
● 获得/设置文件状态标记(cmd=F_GETFL 或 F_SETFL);
● 获得/设置异步I/O所有权(cmd=F_GETOWN 或 F_SETOWN);
● 获得/设置记录锁(cmd=F_GETLK,F_SETLK 或 F_SETLKW) ;
此处用第三种功能,获取/设置文件状态标记,就可以将一个文件描述符设置为非阻塞。
实现函数SetNonBlock
void SetNonBlock(int fd)
{
int fl = fcntl(fd, F_GETFL);
if(fl < 0)
{
perror("fcntl");
return;
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK);
}● 使用 F_GETFL 将当前的文件描述符的属性取出来(这是一个位图);
● 然后再使用 F_SETFL 将文件描述符设置回去。设置回去的同时,加上一个 O_NONBLOCK 参数;
多路复用
在高性能的服务器上,多采用多路复用技术,多路其实就是多个连接,复用就是复用此服务器进程。那么合在一起,多路复用,就是用一个进程进行多个连接的处理。
对于服务器来说,开放端口等待客户端连接,开始多采用多进程或多线程编程的方式。即每个连接采用单独的进程或线程进行处理,但是每台计算机因为内存等资源限制,可以开的进程或线程数有限,而且过多的线程会导致线程切换的成本过大,缓存失效等一系列问题,根本无法做到单机处理十万、百万连接。
如果采用非阻塞,在用户进程里面轮询方式呢?这样会占用很高的cpu资源,所以后来发展出多路复用技术,即采用一个进程处理多个连接。一个进程怎么处理多个连接呢?不可能采用阻塞的方式,一旦阻塞在一个连接的IO上,其他连接有事件过来了也没办法处理,那只能轮询查看各个连接上是否有可读、可写消息,从而达到多路复用的目的,linux内核提供select、poll、epoll三种多路复用机制。