PVIT:利用位置信息增强多模态模型理解用户意图的能力

论文链接: https://arxiv.org/abs/2308.13437
代码链接: https://github.com/PVIT-official/PVIT
Demo: https://huggingface.co/spaces/PVIT/pvit
引言
随着ChatGPT等语言大模型的走红,越来越多人尝试探索为语言大模型赋予视觉能力[1,2],打造多模态大模型。如何让人类与多模态大模型更自然地交互,让模型更好地理解图像和文本指令是重要的研究课题。
引入位置信息是让模型更好地理解图像和用户意图的有效方法。例如在图1中,利用框表示位置信息能有效帮助用户更加简明地表达问题,与多模态大模型更自然地交互。OpenAI近期推出的GPT-4V(ision)[3]也有类似功能。
本文作者尝试以开源模型为基础,引入位置信息进行视觉指令微调。作者发现,引入额外的区域编码器能有效增强模型对用户意图的理解和指令遵循能力。
 图1:利用框给定位置信息有助于模型更好地理解用户意图
图1:利用框给定位置信息有助于模型更好地理解用户意图
一、问题分析
视觉指令微调(Visual Instruction Tuning)通过图像-语言配对数据连接预训练语言模型与视觉编码器,从而得到可以理解图像的多模态大模型(MLLM)。然而,现有模型仅支持文本形式交互,在复杂交互场景中难以有效识别用户意图。
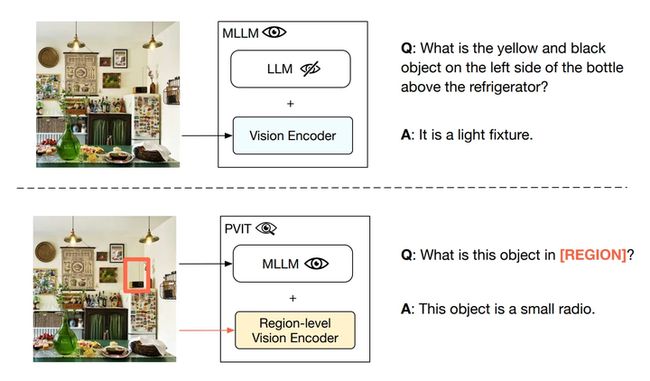 图2:PVIT相较于传统多模态大模型,可以通过边界框理解额外的区域信息
图2:PVIT相较于传统多模态大模型,可以通过边界框理解额外的区域信息
在本文中,作者提出了一种位置信息增强的视觉指令微调方法PVIT(Position-Enhanced Visual Instruction Tuning),在视觉指令微调中引入额外的区域(Region)输入,并利用额外的区域编码器精确理解用户输入的定位区域。通过这种方法,能够实现模型对人类意图的更好理解,从而使模型的回应更加准确。
二、模型结构
如图3所示,模型主要包含三个部分:基于CLIP ViT-L/14的视觉编码器、基于RegionCLIP的区域编码器和大语言模型(LLM),编码器和大语言模型之间采用单一线性层连接。该模型可以理解包含图像、区域信息和自然语言的多模态指令并进行文本生成。
PVIT采用两阶段训练方式。第一阶段只训练连接编码器和大语言模型的线性层,第二阶段微调线性层和大语言模型的参数。
 图3:PVIT模型结构
图3:PVIT模型结构
三、数据生成
如图4所示,作者提出了3种方法生成指令数据,生成的指令包含图像、区域信息和文本描述等。
数据集转换: 使用特定模板为现有的视觉问答数据集生成包含区域信息的指令。
任务特定指令数据生成: 用ChatGPT为5种特定的多模态任务生成指令数据,以解决数据集转换方法生成的数据多样性不足等问题。
通用指令数据生成: ChatGPT生成的详细的图像描述、视觉定位(Visual Grounding)模型生成的物体和图像的对应位置关系和作者编写的数个上下文示例均被用于数据生成。数据多样性和质量得到进一步提高。
 图4:PVIT数据生成方法
图4:PVIT数据生成方法
四、实验结果
效果评估: 作者在MS COCO验证集和GQA验证集上对模型的对象识别和多模态推理能力进行定量评估,结果如表1所示。PVIT模型的对象识别准确率和多模态推理能力高于其他模型。
 表1:模型在COCO和GQA任务上与LLaVA、Shikra和GPT4RoI模型的比较
表1:模型在COCO和GQA任务上与LLaVA、Shikra和GPT4RoI模型的比较
涉及区域信息多模态指令服从能力评估: 为进一步评测模型对涉及区域信息的多模态指令的服从能力,作者提出了FineEval评测集。FineEval包含多种任务,指令中包含图像和区域信息,其样例和统计信息如图5所示。5名评估者对不同模型在FineEval上的输出质量进行相对排名。如图5所示,总体而言PVIT显著优于其他模型。作者在MS COCO验证集和GQA验证集上对模型的对象识别和多模态推理能力进行定量评估,结果如表1所示。PVIT模型的对象识别准确率和多模态推理能力高于其他模型。
 图5:FineEval样例和统计信息
图5:FineEval样例和统计信息
作者还提出了FineEval评测集。由5名评估者对不同模型在FineEval上的输出质量进行相对排名。如图6所示,总体而言PVIT显著优于其他模型,除在物体识别领域略逊于Shikra。
 图6:人工评价中PVIT相较于LLaVA(a)、Shikra(b)和GPT4RoI(c)的胜率
图6:人工评价中PVIT相较于LLaVA(a)、Shikra(b)和GPT4RoI(c)的胜率
五、案例分析
图7展示了几个与PVIT交互的案例。部分问题在没有区域信息帮助的情况下难以清晰表述,这更凸显了区域位置信息的重要性。这些案例展现出PVIT模型的以下四种能力:
对象识别,尤其是小物体识别。 如案例1中正确识别“[REGION-1]”为屏幕,案例5中正确识别“[REGION-2]”为鱼。
属性描述,包括视觉属性和图像中不可见的特征。 如案例5中生成的描述包括了颜色和姿态等视觉属性和从外部知识推断出的其他属性。
基于图像和指令进行推理的能力。 如案例2中识别出游泳者和她的手,并推断手属于游泳者。案例3中准确辨别出鱼的颜色变化,并运用视觉对比知识解释为何红色的鱼显眼。
文本生成能力。 其多数回答均能保持连贯且语法正确,其中案例1和案例4是代表性例子。然而,这些案例不能完全展现模型的文本生成能力,全面的展示和评估有待继续探索。
 图7:与PVIT模型交互的6个案例
图7:与PVIT模型交互的6个案例
六、总结
本文引入额外的区域位置信息进行视觉指令微调,提升了多模态大模型的区域信息理解和视觉指令服从能力。此外,作者还提出了一种新的包含区域信息的指令数据构建方法和一个具有挑战性的人工编写的评测集FineEval。
参考文献
[1] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2023). Visual instruction tuning. arXiv preprint arXiv:2304.08485.
[2] Zhu, D., Chen, J., Shen, X., Li, X., & Elhoseiny, M. (2023). Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592.
[3] GPT-4V(ision): ttps://cdn.openai.com/papers/G
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区