Kotlin 学习笔记(四)—— 协程的基础知识,面试官的最爱了~
又是一个月没见了,坚持永远是世上最难的事情,但,往往难事才会有更大的收获。与君共勉~
前段时间一直在学习 Compose,所以导致 Kotlin 笔记系列搁置了好久。一方面是因为 Compose 的学习在个人来看重要性更高;另一方面就是,发现学完之前的 Kotlin 系列的笔记一到笔记三后,已经基本可以在项目中使用 Kotlin 进行日常的编码了,所以才导致这个 Kotlin 学习笔记系列停更了好久,哈哈!对 Jetpack Compose 感兴趣的同学可以看一下我的另一个笔记系列—— Jetpack Compose 学习笔记。这次咱来看看 Kotlin 协程的基础知识。
1. 协程是什么
协程是一种编程思想。它并不局限于任何语言,不仅 Kotlin 中有对协程的实现,Python、Go 等语言也有。
更实际一点,协程的代码是运行在线程中的,可以在单线程中执行;也可以在多线程中执行,即支持来回切换。并且协程没有直接和操作系统关联,而是跟线程紧密关联,毕竟是要靠线程去执行。它的设计初衷就是为了解决并发问题,可以更方便地处理多线程协作的任务。
在 Kotlin 中,协程就是一个封装好的线程框架。类比于 Java 中的 Executor 或 Android 中的 AsyncTask。只要内存足够,一个线程可以运行任意多个协程,但在某一时刻只能有一个协程在运行,多个协程分享该线程分配到的计算机资源。下面图是进程、线程、协程之间的关系图:
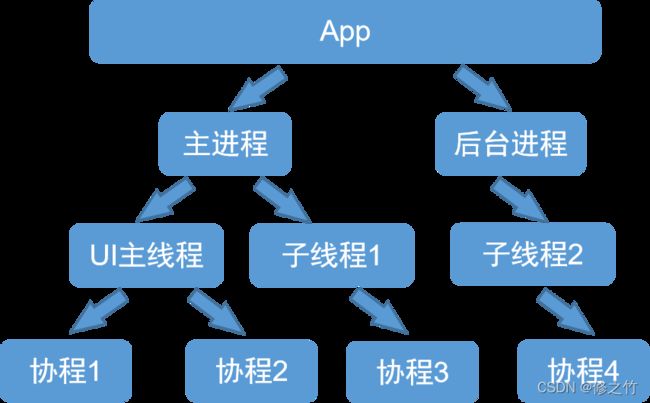
这里是拿 Android 应用来举例的,其实不仅在 Android 中有 UI 主线程的概念,在 Go、Python 等支持协程的语言中,也有主线程的概念。有一点需要注意的是,进程是可以直接通过协程去处理一些事件的,只不过现在的编程语言都约定俗成地采用了图1 的这种层次。
所以,协程就是一套封装好的线程API框架,只不过使用起来非常方便,可以用看起来是同步的代码,去实现异步的操作。
2. suspend 关键字
先来看看 suspend 关键字,好像老是在协程的代码中碰到它。按照它的字面意思,就是“挂起”的意思,确实比较形象,因为被它修饰的方法,是可以被挂起的。这里被挂起的对象是这个方法所在的协程。那么,协程被挂起的真正意思是什么?
协程被挂起的意思是,这个正在线程上运行的协程体代码,将要从当前线程脱离开来,即剩下的协程代码不往下执行了。脱离开后,协程和线程会怎么样呢?线程这边比较好理解,如果有其他的任务需要处理,操作系统肯定会安排线程去执行其他的任务;如果暂时没有什么任务需要处理,可能就会被回收掉,或者放入线程池中;协程这一边,则将会在指定的线程中,继续执行之前被中断的代码。至于被指定的线程具体是哪个,是由 suspend 函数具体实现决定的。常见的可以调用 withContext 方法去指定线程。
suspend 关键字本身没有挂起的作用,需要在方法内部直接或者间接地调用 Kotlin 协程框架中的 suspend 函数才可以。所以,suspend 关键字更多的是给调用者一个提示,提示调用者被它修饰的方法是个耗时方法,需要在协程或者其他 suspend 函数中处理,限制这个方法只能在协程或其他 suspend 函数中被调用。
了解了 suspend 的用法,再来看看实际使用中,协程的几个组成部分。
3. 协程的几个重要组成部分
一般来说,协程的启动使用比较多的有如下的三个方法:
runBlocking: Tlaunch: Jobasync/await: Deferred
通过查看这三个方法,我们可以得知协程的几个重要的属性,或者是参数。拿 launch: Job的源码来说,我们从 GlobalScope.launch的 launch 方法进入,可以看到 launch 的方法声明是:
// code 1 launch 方法声明
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
其中的 CoroutineContext、CoroutineStart 、suspend CoroutineScope.() -> Unit等几个参数都是协程的重要组成部分。
3.1 协程上下文
先看看 launch 方法的第一个参数—— CoroutineContext,协程上下文,跟 Android 里面的 Context 上下文类似,通常用于协程间切换时,传递参数的作用;还可以指定协程在哪个线程中执行,比如 IO 线程、UI Main 线程等;还可以指定当前协程中断后在哪个线程中去恢复它。
默认 CoroutineContext 是设置的 EmptyCoroutineContext —— 一个标准库已经定义好的 object,表示一个空的协程上下文,里面没有任何数据。而 CoroutineContext 的数据结构与集合类似,内部实现是一个单链表,里面的元素是 Element。
Element 中有一个属性 key,这个 key 就是元素 Element 的索引。要说协程上下文在我们的开发中如何使用,我找了下网上的一些资料,提到较多的就是异常的捕获了。如下面 code2 所示:
// code 2 设置协程的异常捕获
val coroutineExceptionHandler = CoroutineExceptionHandler { context, throwable ->
// 出现异常则会执行
throwable.printStackTrace()
}
GlobalScope.launch (Dispatchers.Main + coroutineExceptionHandler) {
// 执行操作
}
这段代码用到了 GlobalScope.launch,代表是个顶级作用域的协程,不推荐在 Android 开发中使用,因为它的生命周期是与Application 应用一致的,所以容易造成内存泄漏。CoroutineExceptionHandler 可以让我们在启动协程时设置一个统一的异常处理器,如果出现异常,就会执行相应的操作。这里的上下文还设置了协程运行的线程为 Main 主线程。此外,CoroutineContext 重载了 plus 方法(public operator fun plus(context: CoroutineContext): CoroutineContext),所以可以直接使用加号 “+” 来添加一个 Element。
还有一个更为复杂的例子,也可以大致看出协程的组成:
// code 3 协程的内部组成
suspend {
// 协程体
Log.d(TAG, "CoroutineStart: +++++ ${coroutineContext[CoroutineName]} ${Thread.currentThread().name}")
// val tmp = 1/0
"suspend 返回值"
}.startCoroutine(object : Continuation<String> {
override val context: CoroutineContext
get() = EmptyCoroutineContext + CoroutineName("修之竹") + CoroutineExceptionHandler { context, throwable ->
Log.d(TAG, "CoroutineExceptionHandler: ++++ ${throwable}")
}
override fun resumeWith(result: Result<String>) {
// 协程执行完会执行 resumeWith 方法
Log.d(TAG, "resumeWith: ++++ CoroutineEnd")
result.onSuccess {
Log.d(TAG, "++++++ resumeWith onSuccess: ${context[CoroutineName]?.name}")
}
result.onFailure {
Log.d(TAG, "++++++ resumeWith onFailure")
context[CoroutineExceptionHandler]?.handleException(context, it)
}
}
})
首先,被 suspend 包裹的代码段就是协程需要去执行的协程体,最后还有一个返回值。其次,startCoroutine 方法中的匿名内部类 Continuation 实际上实现了协程上下文的配置以及协程执行完的回调。
在配置协程上下文中,使用了 CoroutineName 和 CoroutineExceptionHandler 添加了两个元素。CoroutineName 可以为协程绑定一个名字;CoroutineExceptionHandler 前文已有说明。
而 resumeWith 方法就是协程的回调方法,执行失败或完成都会回调,就拿上面的代码,在Activity onCreate 方法中执行,就会输出下面的信息:
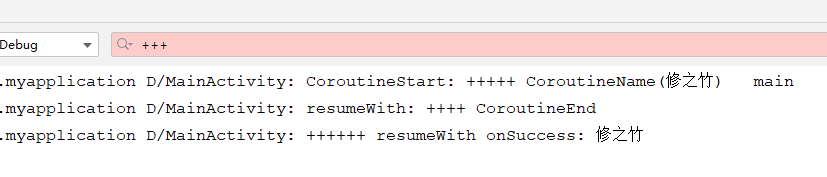
可以看出,通过 CoroutineName 确实可以给协程绑定一个名字,而且在协程体中可通过 coroutineContext 协程上下文对象获取到协程上下文的一些信息;协程执行完成时,回调的是 resumeWith 中 Result 的 onSuccess 方法;协程执行出错时,回调的是 resumeWith 中 Result 的 onFailure 方法。如果把 code 3 中的 val tmp = 1/0去掉注释再运行,则会输出下面的情况:

协程上下文就说到这里。
3.2 协程调度器
在 3.1 中已经出现过调度器的身影,就是当需要指定协程运行的线程时,使用调度器调度即可。在实际的使用中是通过 Dispatchers 对象来访问它们。官方框架预置了4个调度器:
Default:默认调度器,适合处理 CPU 密集型任务,比如涉及大量计算;IO:IO 调度器,适用于执行 IO 相关操作,处理 IO 密集型任务,比如读取文件、访问数据库;Main:UI 调度器,根据平台不同会初始化为对应的 UI 线程调度器,即通常在主线程上执行的任务,比如在 Android 上就是各种更新 UI 的操作;Unconfined:没有约束的调度器,即不会要求协程在哪个线程上执行。当挂起函数结束后程序恢复运行时,这时执行协程的线程就是执行挂起函数的线程。即挂起函数由哪个线程执行,后续协程就在哪个线程执行。
Dispatchers 调度器的基类是 CoroutineDispatchers,后者是所有协程调度器的基类。而 CoroutineDispatchers 继承自 AbstractCoroutineContextElement 并实现了 ContinuationInterceptor 接口;ContinuationInterceptor 又实现了 CoroutineContext.Element 接口,最后,CoroutineContext.Element 接口实现了CoroutineContext。
兜兜转转,原来 CoroutineDispatchers 本身也是一个 CoroutineContext,这也是 code 2 中可以直接与 coroutineExceptionHandler 直接相加的原因:GlobalScope.launch (Dispatchers.Main + coroutineExceptionHandler) ,两者都是 CoroutineContext.Element 的实例当然可以相加了。
使用起来比较简单,常见的设置调度器的方法有两种:launch 方法设置、withContext 方法设置。如下 code 4 所示,在 Android 的 onCreate 方法中调用 launch 方法,并设置在 Main 线程中执行;然后通过 withContext 方法切换到 IO 线程:
// code 4 调度器指定协程运行的线程
GlobalScope.launch(Dispatchers.Main) {
Log.d(TAG, "onCreate: ++++ Dispatchers.Main Thread is ${Thread.currentThread().name}")
withContext(Dispatchers.IO) {
Log.d(TAG, "onCreate: ++++ Dispatchers.IO Thread is ${Thread.currentThread().name}")
}
Log.d(TAG, "onCreate: ++++ Thread here is ${Thread.currentThread().name}")
}
这里用到 GlobalScope 只是为了方便,不推荐在实际开发中使用,输出的结果比较有意思:

注意到,在 withContext 切换到 IO 线程,执行完 IO 线程的逻辑后,居然自己又回到原来的 Main 线程了!太懂事了吧!这也是为什么我们可以在协程中用写同步代码的思想,去写异步的逻辑。比如我把 code 4 中在 IO 线程的操作换成网络请求数据的逻辑,然后把最后的打印的逻辑换成更新 UI 的代码,不就可以实现请求数据更新 UI 的逻辑了吗?再也不用像 RxJava 那样来回切线程了。
3.3 协程启动构建器
再看看 launch 函数的第二个参数—— CoroutineStart,协程的启动模式设置器。在说之前需要弄清 立即调度和立即执行的区别。
立即调度:指的是协程的调度器会立刻接收到调度指令,但具体什么时候调度线程执行,还需要根据调度器的具体情况而定,即立即调度到立即执行之间通常会有时间间隔。
再来看下不同的启动模式,有四种:
DEFAULT:默认值,表示协程创建后,立即开始调度,在执行前如果被取消则直接进入取消响应状态;LAZY:表示该协程只有主动调用了协程的 start 或 join 或 await 方法后才会开始调度,在执行前如果被取消则将直接进入异常结束状态;ATOMIC:表示该协程创建后,立即开始调度,且调度和执行合二为一,是原子操作,协程一定会执行,不会被取消掉,只能忽略协程的执行结果;UNDISPATCHED:表示协程创建后立即在当前函数调用栈中执行,是运行在协程创建时所在的线程。虽然与 ATOMIC 模式一样可保证协程一定执行,但 ATOMIC 会调度到指定调度器所在的线程上执行。
实际开发中,通常使用 DEFAULT 和 LAZY 这两种启动模式就够了。
3.4 协程作用域
launch 函数的第三个参数是一个由外层 CoroutineScope 调用的 lambda 闭包,我们需要在协程中处理的逻辑都在这个闭包中实现。code 2 中的GlobalScope就是一个 CoroutineScope 对象,这个对象代表将要启动的协程的作用域范围,或者说 CoroutineScope 是协程用于管理自身生命周期的对象。
常见的有 GlobalScope 和 MainScope 两种。在 Android 里还有 lifecycleScope、viewModelScope,如果要用的话分别需要在 gradle 中添加如下的库:
// code 4
// 使用 lifecycleScope 需要引用的库
implementation 'androidx.lifecycle:lifecycle-runtime-ktx:2.4.1'
// 使用 viewModelScope 需要引用的库
implementation 'androidx.lifecycle:lifecycle-viewmodel-ktx:2.4.1'
当然,不同的 Scope 有不同的特性。
GlobalScope:通常被用于启动一个顶级协程(顶级协程是顶级作用域,即没有父协程的作用域),这种协程的生命周期是会伴随应用的整个生命周期,不会被取消掉,所以要非常谨慎的使用,容易造成内存泄漏。可以用于数据打点,log 日志记录等,更像是一个守护线程。这个 Scope 是属于标准协程库中的。
MainScope:主要用于在 UI 主线程中运行的协程,这一点可以查看它的源码得知:
// code 5
public fun MainScope(): CoroutineScope = ContextScope(SupervisorJob() + Dispatchers.Main)
Dispatchers.Main 表示最后分发到 Main 主线程上了,包括 Android 在内的许多场景,主线程就代表是 UI 线程。使用 MainScope 需要注意,在当前 UI 页面将要被回收时,需要调用 cancel 方法取消,避免内存泄漏。
3.5 Job 对象
别忘了 launch 函数还有个 Job 类型的返回值,Job 对象是个接口,也是继承自 CoroutineContext.Element 。返回的这个 job 实例可以代表这个协程本身。我们拿到协程的 Job 对象之后,可以获取到协程的状态,用于表明协程状态的 3 个标记位如下:
isActive:true 表示 job 为活跃的状态,已经启动并没有完成,也没有被取消;此外,父 job 在等待子 job 完成时也是处于活跃状态;
isCompleted:true 表示 job 因为某种原因已经完成,值得注意的是,如果 job 被取消或者执行失败,也是已经完成状态;父 job 只有当所有子job 都是完成状态时,它才是完成状态;
isCancelled:true 表示 job 因为某种原因被取消,例如 job 显式地调用 cancel 方法或者执行失败,或者它的子/父 job 被取消。
父子 job 也会相互影响自身的状态。比如,一旦父 job 被取消,其所有子 job 也会被取消;当一个子 job 由于出现异常导致执行失败,其父 job 和其他的子 job 也会立即被取消并抛出 CancellationException。这些“连带影响”可以通过 SupervisorJob 去自定义。
Job 的状态以及 3 个标记位的对应值如下表所示:
| Job 状态 | isActive | isCompleted | isCancelled |
|---|---|---|---|
| New(可选的初始态) | false | false | false |
| Active(默认初始态) | true | false | false |
| Completing(瞬时状态) | true | false | false |
| Cancelling(瞬时状态) | false | false | true |
| Cancelled(最终态) | false | true | true |
| Completed(最终态) | false | true | false |
通常默认情况下,是用 CoroutineStart.DEFAULT 来启动一个协程,这时协程被创建后直接启动,进入 Active 状态;而使用 CoroutineStart.LAZY 创建后的协程则是 New 状态,直到调用 start 或 join 方法后才会进入 Active 状态。
Completing 状态属于 job 内部的状态,对于一个外部观察者来说,一个 Completing 态的 job 仍然处于 Active 态,这个 job 在内部正在等待其子 job 执行完。官方注释有个状态流转图,如下所示:

Job 接口的主要方法有如下几个:
public fun start(): Boolean:启动协程,返回 true 表示启动协程成功;返回 false 表示协程已经被启动或已经执行完成。public fun cancel(cause: CancellationException? = null):取消协程,可选参数用于描述取消协程的理由或错误信息。public suspend fun join():挂起这个协程直到它完成,如果 job 处于 New 状态,此方法也可启动协程;此方法可被取消;当调用此方法的协程被取消或已完成,此方法会抛出 CancellationException。public suspend fun Job.cancelAndJoin():取消协程并挂起它,直到完成取消协程这个操作。public fun attachChild(child: ChildJob): ChildHandle:给当前协程添加一个子协程,返回的 ChildHandle 用于 detach 父协程。public fun invokeOnCompletion(handler: CompletionHandler):DisposableHandle:这个方法用于监听 job 完成或者取消的回调。如果 job 被取消,则会抛出被取消的异常。如果正常完成,则抛出 null。如下代码 code 5,如果 cancel 方法被调用,则会打印出:
MainActivity: ++++++ invokeOnCompletion kotlinx.coroutines.JobCancellationException: StandaloneCoroutine was cancelled; job=StandaloneCoroutine{Cancelled}@302ae10
如果不调用 cancel,则打印为 null.
invokeOnCompletion 方法返回的 DisposableHandle 对象就是用于回收资源的,如果需要,调用它的 dispose 方法即可。
// code 5
val job = GlobalScope.launch(Dispatchers.Main) {
for (i in 1..4) {
delay(1000)
if (i == 2) {
cancel() // 取消
}
Toast.makeText(this@MainActivity, "修之竹~", Toast.LENGTH_SHORT).show()
}
}
job.invokeOnCompletion { throwable ->
Log.d(TAG, "++++++ invokeOnCompletion ${throwable.toString()}")
}
此外,job 接口中所有的方法都是线程安全的。至此,协程的几个重要组成部分就介绍完了,接下来回过头来看看启动协程的常用的几个方法。
4. 协程启动常见的几种方法
启动协程主要的三种方法:
runBlocking: T:用于执行协程任务,通常只用于启动最外层的协程。常用于线程启动或切换到协程的场景
launch: Job:也是用于执行协程任务,会返回一个 Job 对象。
async/await: Deferred:同样用于执行协程任务,成对出现,await 可以得到 async 异步操作后得到的执行结果
launch 方法之前已经介绍的再清楚不过了,这里看看另外的两种。
runBlocking: T:启动一个最外层的协程,即顶级协程,没有父协程。它启动的协程是阻塞的,执行完之后才能继续往下执行,这是它的特点,从它的方法名也可以看出来。而 launch 则是非阻塞的,先来看一下非阻塞的情况:
// code 6 非阻塞协程
GlobalScope.launch {
delay(5000)
Log.d(TAG, " 1)launch Test: +++++ ${Thread.currentThread().name}")
}
Log.d(TAG, "2)After launch Test: +++++ ${Thread.currentThread().name}")
delay 函数也是一个挂起函数,它可以非阻塞性的挂起当前线程,并且在设置的时间间隔之后恢复执行,是可被取消的。这里就是挂起 5s 后再执行打印,下图是输出情况,注意看打印的时间:

在遇到 delay 后,下面的代码是可以继续执行的,没有被阻塞;当 delay 时间到了,再才会执行第一个打印的代码。如果换成 runBlocking 就不一样了:
// code 7 阻塞协程
runBlocking {
delay(5000)
Log.d(TAG, " 1)runBlocking Test: +++++ ${Thread.currentThread().name}")
}
Log.d(TAG, "2)After runBlocking Test: +++++ ${Thread.currentThread().name}")

执行到 delay 后,会将当前线程阻塞,直到时间到了才能继续往下执行。
async/await: Deferred:一般用于 async 内执行请求数据的耗时任务;await 取出 async 返回结果的场景。async 返回的是一个 Deferred 接口对象,继承自 Job,且包含一个返回结果。Deferred 是一个非阻塞的,可被取消的对象。await 是 Deferred 中的方法,可获取返回的结果数据。多个 async 还可以并行处理逻辑,举个栗子:
// code 8 多个 async 并行处理逻辑
GlobalScope.launch(Dispatchers.Main) {
val time1 = System.currentTimeMillis()
val task1 = async(Dispatchers.IO) {
delay(2000)
Log.d("TAG", "task1 Current Thread:${Thread.currentThread().name}")
"task1 返回值"
}
val task2 = async(Dispatchers.IO) {
delay(1000)
Log.d("TAG", "task2 Current Thread:${Thread.currentThread().name}")
"task2 返回值"
}
Log.d("TAG", "task1 返回值:${task1.await()} task2 返回值:${task2.await()}")
Log.d("TAG", "task1 和 task2 总耗时:${System.currentTimeMillis() - time1}")
}

从打印结果可以看出,delay 时间短的 task2 率先完成,总时长为 2s,说明 task1 和 task2 两个任务并行处理了。但是,如果两个 async 方法后面紧接着处理各自的 await 方法,则就是串行处理了,看下面的效果:
// code 9 多个 async 串行处理
GlobalScope.launch(Dispatchers.Main) {
val time1 = System.currentTimeMillis()
val task1 = async(Dispatchers.IO) {
delay(2000)
Log.d("TAG", "task1 Current Thread:${Thread.currentThread().name}")
"task1 返回值"
}.await()
val task2 = async(Dispatchers.IO) {
delay(1000)
Log.d("TAG", "task2 Current Thread:${Thread.currentThread().name}")
"task2 返回值"
}.await()
Log.d("TAG", "task1 和 task2 总耗时:${System.currentTimeMillis() - time1}")
}

看打印结果,task1 执行完才会执行 task2,总耗时是两个任务耗时的总和。Why? 这是因为 await 函数也是一个挂起函数,协程执行到 await 时会被挂起,当 async 执行完返回结果后,才会继续执行。而在 code 8 中两个 await 函数都是在两个 async 之后,所以在两个 async 中的任务就是并行处理的关系了。
协程说到这里,基本的概念应该差不多了,本篇笔记主要归纳总结了协程的主要组成部分以及它们的基本使用,概念的东西比较多,也是重中之重。但协程的知识远不止这些,希望此篇能起到抛砖引玉的作用,希望大家能在项目中使用协程,你会发现,用了就真的回不去了~
参考文献
- 极客时间 Kotlin 系列课程; 张涛
- 《Kotlin 核心编程》; 霍丙乾 水滴技术团队
- Android 上的 Kotlin 协程 官方文档 https://developer.android.google.cn/kotlin/coroutines#groovy
- Kotlin:lifecycleScope与GlobalScope以及MainScope的区别,详细分析为什么在Android中推荐使用lifecycleScope! ;pumpkin的玄学 https://blog.csdn.net/weixin_44235109/article/details/119981210
- Kotlin 的协程用力瞥一眼 - 学不会协程?很可能因为你看过的教程都是错的 https://rengwuxian.com/kotlin-coroutines-1/ ;LewisLuo(罗宇)
- Kotlin 协程的挂起好神奇好难懂?今天我把它的皮给扒了 https://rengwuxian.com/kotlin-coroutines-2/ ;Hugo(谢晨成)
- Kotlin 协程:简单理解 runBlocking, launch ,withContext ,async,doAsync https://blog.csdn.net/Jason_Lee155/article/details/107895920 ;Jason_Lee155
欢迎关注我的个人公众号:修之竹
赞人玫瑰,手留余香!一个点赞、一次转发都是对我最好的鼓励~