浅谈机器学习(第一章基本概念)
机器学习的基本概念
-
- 特征空间与特征变量
- 数据集合
- 假设空间与模型
- 选择模型的策略
- 优化参数的算法
- 机器学习的基本流程
- 机器学习的分类
- 模型的泛化能力
- 参考
特征空间与特征变量
特征变量:一组描述客体性质的变量,变量的个数d称为特征维度,特征变量组成的向量称为特征向量,变量张成的空间称为特征空间(样本空间),变量的取值称为属性值。特征向量和特征向量之间可以度量距离。
数据集合
样本: 特征空间(样本空间)中的一组示例,记为:X。
标记空间: 标签变量或预测变量的取值集合,记为:Y。
样例集合: 特征向量与标签变量对集合,记为:D {(x1,y1),(x2,y2)…(xm,ym)} 样本个数为m个,样本维度d维。
训练集: 在训练过程中使用的数据称为训练数据,每一个样例称为训练样本,全体训练样本的集合称为训练集。
测试集: 用于检测学习得到模型的数据成为检测数据,每一个样例称为检测样本,全体检测样本集合称为测试集。
假设空间与模型
机器学习通过数据集进行训练,构成一个典型的归纳推理过程。学习的结果是得到或逼近样本空间X到标记空间Y的映射 f :X→Y或条件概率分布P(Y|X)。所有可能解的集合称为假设空间,其子集称为一个版本空间。这些假设都会基于一个数学模型来表示,假设近似等于模型。
机器学习的过程又可以理解为:通过算法A,在假设空间H中,根据训练样例集合D,选择最好的假设作为g,使得g无限接近于f。不同模型学习到的g各不相同。
选择模型的策略
策略也称学习准则,是不同模型的比较和选择标准。
经验误差最小化ERM 也叫经验风险最小化,是ML里最常用的标准 ,在已有样本数据上取得最小的经验误差。是模型有效的基础。
经验误差最小化的求解思路:构造一个目标函数或损失函数来描述经验风险,优化参数求解该目标函数或损失函数。
回归问题常用的损失函数:
![]()
分类问题常用的损失函数:
![]()
在样本数据不足的情况下,也可以采用结构风险最小化SRM 作为标准。结构风险在经验风险的基础上增加约束模型复杂度的正则化项,降低模型的复杂度,提升模型的可预测性。
设置对某种假设的偏好称为归纳偏倚,促使学习算法优先考虑具有某些属性的解。
Ein(g),学习的假设在训练样本上的损失,称为经验误差。训练的过程即使得经验误差尽可能的小。
Eout(g),假设g在除了训练样本外的其他所有样本上的损失,称为泛化误差。在测试test过程中希望Eout(g)接近Ein(g)。
机器学习的任务是建立样本空间X到标记空间Y的映射g:X→Y,但是这个映射要能够适应新样本(对没有见过的数据要有效!)。这种能力称为泛化能力,指学习的结果对新样本的适应能力,对样本空间的描述能力。
优化参数的算法
算法:指最优化目标函数(损失函数)中求解参数的方法,即求解最优化问题的算法。

机器学习的三要素:模型+策略+算法
机器学习的基本流程
1.选择数据 2.数据建模 3.验证模型 4.检测模型 5.使用模型 6.调优模型
机器学习的分类
1.是否带有分类标记的样本: 有监督学习、无监督学习、半监督学习、强化学习。
2.能否从导入的数据进行持续动态的学习: 批量学习、在线学习
3.简单的将待分类数据点和已知数据点进行匹配/对训练数据进行模式检测,然后建立一个预测模型: 基于实例的学习、基于模型的学习。
注意:各分类之间并不相互排斥,可以按照合适的方式进行组合。
例如垃圾邮件过滤器:一个在线的、基于模型的监督式学习系统。
(1)有监督学习
也称有导师的学习,常见的分类和回归问题都属于监督学习。目标是从已标记训练样本学习得到样本空间到标记空间的映射,这种映射关系要求与已标记样本情况基本吻合。映射关系和标记在分类问题中分别指分类器和类别,而在回归分析中就是回归函数和实值输出。
(在传统的监督学习中,通常都假设具有足够的已标记样本。如果已标记样本过少,那么从中学习得到的映射会缺乏足够的泛化性,即对新样本进行判别分析的能力不足)
常见算法:K-近邻算法、线性回归、逻辑回归、支持向量机、决策树和随机森林、神经网络
(2)无监督学习
也称无导师学习,常见聚类问题、部分降维问题都属于无监督学习。无监督学习目标是发现输入数据潜藏的结构或者规律。大数据可视化也可以看做是一种无监督学习。
聚类算法:K-均值聚类、层次聚类分析、概率聚类分析
降维算法:主成分分析(PCA)、多维标定降维
关联规则学习算法:Apriori
(3)强化学习
又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标。
(4)增量学习
是指一个学习系统能不断从新样本中学习到新的知识,并能保存大部分以前已经学习到的知识。增量学习非常类似于人类自身的学习模式。
(5)批量学习
无法进行增量学习,系统不能进行持续学习,必须用所有可用数据一次性的进行训练,然后使用已学到的策略来预测新样本,又称为离线学习。
(6)在线学习
能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高预测的准确率。
(7)基于样例的学习
系统先完全记住学习的样例,然后通过某种相似度量方式,将其泛化到新的实例,而不使用模型。
K近邻分类算法:经典的监督学习和基于样例的学习方法:给定某个测试样本,基于某种距离度量在训练集中找出与其最近的k个带有真实标记的训练样本,然后由这k个邻居的标记来进行预测
模型的泛化能力
机器学习是基于数据的科学,模型、数据和训练缺陷都会导致:
欠拟合:是指模型在训练集、验证集和测试集上均表现不佳的情况;
过拟合:是指模型在训练集上表现很好,而在验证和测试阶段表现不行,即模型的泛化能力很差。
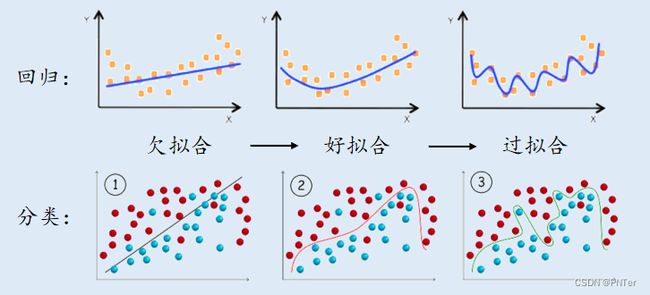
模型选择存在模型复杂度、样本和泛化误差三者之间的平衡问题。
- 训练样本的问题
大部分机器学习算法需要大量的数据才能正常工作。即使是最简单的问题,可能也需要足够多的样例。对于诸如图像识别或语音识别等复杂问题,机器可能需要上千万个样例。对于将要泛化的新实例来说,训练数据一定要有代表性。不论使用的是基于样例的学习还是基于模型的学习,都是如此。

如果训练集充满了错误、异常值和噪声(例如,差质量的测量产生的数据),系统将更难学习到真实情况,更不可能表现良好。所以花时间来清理训练数据是非常值得的投入。
当训练数据中包含较多与目标变量有关的 (Relevant)特征,以及较少的与目标变量无关的 (Irrelevant) 特征,系统才能够有效学习。同时,各特征之间要尽可能减少互相关。
如果训练数据自身的、非全局的特性被学习到了,则易过拟合。
-
模型的复杂度问题
用VC维来度量假设H的学习能力。当固定样本数N时,随着VC维的上升,经验误差会不断降低,同时模型复杂度Ω会不断上升 ,泛化误差会经历从欠拟合到过拟合的一个过程。
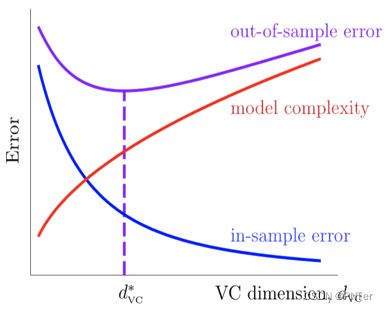
VC维越大模型越复杂。VC维的大小与具体的学习策略和算法无关,与数据集的分布无关,只与模型和假设空间有关。 -
泛化误差的构成
方差-偏差分解:从机器学习的角度看,“误差”从何而来?包含了哪些因素。
eg:对测试样本x,令yD为x在数据集中的标记(这里的yD其实换个角度来说就是目前测量能达到的精度最高值,所有能想到的误差全部已经剔除的结果),y为x的真实标记。可以这么理解yD是目前人类所能测量的精度最高值,而y是三体人测量的精度,属于真值。g(x;D)为训练集D上学得模型g在x上的预测输出,以回归任务为例,学习方法的期望预测为:


偏差(bias):期望输出与真实输出的差别,反映的是模型好不好。
方差(variance):同样规模训练集的变动所导致的性能变化,反映的是模型稳定程度。
噪声(noise):不可避免:包括样本输入的属性不准确,或者标记错误;也可能存在没有考虑到的隐藏属性,是不可预测的随机成分。

参考
武汉大学 郭迟教授 机器学习在导航定位技术中的应用PPT