不良条件视觉感知专栏(一)任务前言
前言 随着深度学习的流行,CNN的强大特征学习能力给计算机视觉领域带来了巨大的提升。2D/3D目标检测、语义分割是常见的视觉感知任务,本专栏我们将围绕着它们展开阐述。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
Transformer、目标检测、语义分割交流群
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
CV各大方向专栏与各个部署框架最全教程整理
(一)任务介绍
检测和分割是场景理解的关键部分,在机器人、无人驾驶、安防等领域有着广泛的应用。现有的大部分方法主要在正常的成像条件下进行,虽然在性能表现上较好,但是并没有考虑到不良条件(恶劣天气、低光照等)下的场景。现实中的场景是复杂多变的,包含着很多不良的条件给视觉算法带来不利的影响。下面我汇总了常见的不良感知场景,大概可以分为天气和光照两部分:
-
雾天(Foggy)
-
雨天(Rainy)
-
雪天(Snowy)
-
黄昏(Dusk)
-
夜晚(Night)
-
黑夜(Dark Night)比普通的夜晚更黑,只包含极少的光照
-
强曝光(Strong exposure)**强曝光是指在环境中光线的突然增强**
-
阴暗(Overcast)
下图为不良感知场景的示例:

强曝光和黑夜

雾天和雨天
一个不能处理巨大场景变化的模型,如果应用在无人驾驶等领域上可能会危及周围的人。在一些基准数据集表现很好的模型,在现实中往往鲁棒性很差。这是因为它们通过正常条件数据集训练得到的,这些模型往往不适用于恶劣的天气条件和夜间出现的低照明。在不良条件下进行稳健鲁棒的视觉感知,是算法落地并融入实际应用的重要先决条件。
(二)研究现状
现阶段针对不良条件的视觉感知,研究的方法分为很多种:
-
域自适应
-
多模态融合(LiDAR 点云和深度图)
-
图像前处理(可微滤波器、GAN)
感觉这个方向热度并没有纯视觉感知(3D目标检测、语义分割等)热度高,可能是因为针对不良条件的视觉感知场景泛化偏向于应用。正因如此,这个方向现在可以填的坑是很多的,有很多的可做性和意义。
域自适应
域自适应的定义:在经典的机器学习中,当 源域 和 目标域 数据分布不同,但是两者的任务相同时,这种特殊 的迁移学习就是域自适应(Domain Adaptation)。
我们一般假设训练集和测试集分布一致,但是在实际中训练集和测试集其实分布会有很大的差异。这时候训练的模型在测试集上效果却不理想迁移学习需要解决的问题。简单举例来说:
-
我们使用白天场景的数据集进行语义分割模型的训练,但是测试集确实夜晚的。这时虽然我们这个模型要解决的任务和标签都是一样的,但是模型缺缺少鲁棒。
域自适应的方法:
-
样本自适应:对源数据的样本进行加权,学习一组权重使分布差异最小化,从而逼近目标域的分布。
-
特征自适应:将源域和目标域投影到公共特征子空间,这样两者的分布相匹配,通过学习公共的特征表示,这样在公共特征空间,源域和目标域的分布就会相同。
多模态(传感器)融合
Camera和LiDAR是现如今主要的传感器,被广泛地用在无人驾驶和机器人等领域。Camera和LiDAR的特征我通过以下表格进行对比:
| 传感器 | 提供信息 | 优点 | 缺点 |
|---|---|---|---|
| Camera(相机) | 纹理信息 | 包含着丰富的纹理,网络学习更容易。 | 相机的图片非常容易受光照和天气影响,无法提供深度信息。 |
| LiDAR(激光雷达) | 深度信息 | 提供3D点云,受光照和天气影响较小。 | 无法捕捉详细纹理,LiDAR的点云是稀疏无序的,利用起来较难。 |
我们通过上表可以发现Camera和LiDAR是几乎互补的,如果结合起来会产生不错的效果。多模态传感器融合意味着信息互补、稳定和安全,长期以来都是自动驾驶感知的重要一环。然而信息利用的不充分、原始数据的噪声及各个传感器间的错位(如时间戳不同步),这些因素都导致融合性能一直受限。

目前多模态融合是自动驾驶中的一个很热门的方向,有着很多的融合方法。但是这些研究方法只是在考虑如何更高效地融合两种模态,并没有完全考虑不良条件与多模态进行结合。研究的重点在于融合的几种方式,如下图。
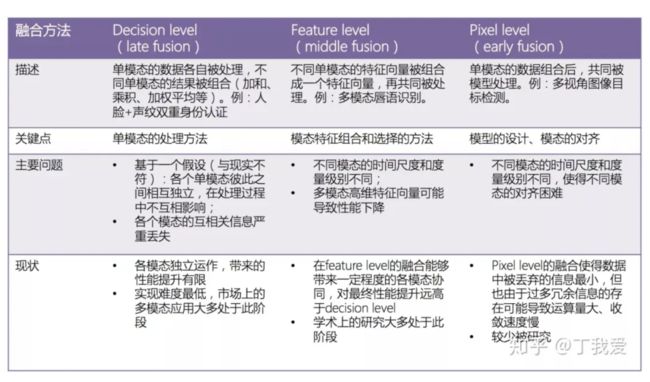
在这之外,还有一些方法将图片和其他传感器(比如说红外相机、热相机)进行融合,如HeatNet(IROS2019)。
图像前处理(可微滤波器、GAN)
这是一种深度学习与传统方法相结合的思路,由此产生了可微滤波器。可微滤波器是指可以通过神经网络进行训练的一种图像算子。可微滤波器用于图像网络的前处理,通过对图像的细节进行恢复。滤波器会进行一些数据的增强,比如说去雾、去噪、对比度和亮度等操作,将图片恢复到正常的条件下。
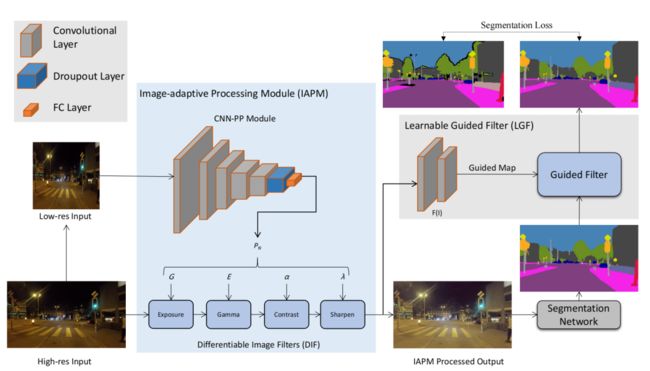
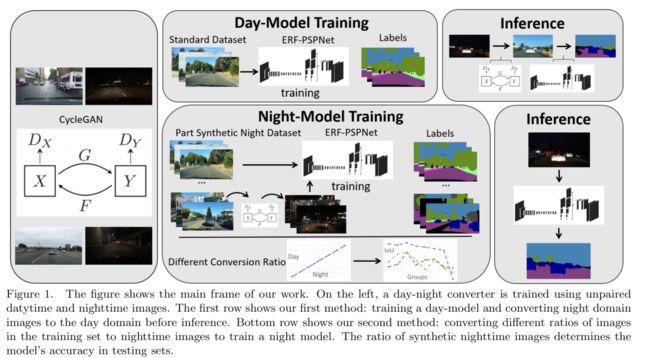
还有一种方法是通过GAN进行网络的前处理,比如说一个黑夜的图片我通过GAN将它变成白天场景。下图的方法通过训练一个CyCle GAN,可以满足图片从白天到黑夜的相互转化:
-
白天->黑夜: 使用生成的数据集进行训练,进行场景的泛化。
-
黑夜->白天:作为网络输入前图片的处理。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章
上线一天,4k star | Facebook:Segment Anything
3090单卡5小时,每个人都能训练专属ChatGPT,港科大开源LMFlow
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
实践教程|GPU 利用率低常见原因分析及优化
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
神经网络的可解释性分析:14种归因算法
无痛涨点:目标检测优化的实用Trick
详解PyTorch编译并调用自定义CUDA算子的三种方式
深度学习训练模型时,GPU显存不够怎么办?
CV各大方向专栏与各个部署框架最全教程整理
计算机视觉入门1v3辅导班
计算机视觉各个方向交流群