学会了工资加5K!运营必学!鸽子学ABTest
文章目录
- 企业ABTest全流程
-
- 1 认识ABTest
-
- 1.1 优点及缺点
- 1.2 企业ABTest业务流程
- 1.3 实际中遇到的问题
- 2 假设检验
-
- 2.1 假设检验逻辑
-
- 2.1.1 普通事件逻辑
- 2.1.2 假设检验逻辑
- 2.2 假设检验步骤
-
- 2.2.1 一对完全对立的假设
- 2.2.2 小概率发生的极端事件
- 2.2.3 给小概率事件一个阈值
- 2.3.4 计算A成立时的分布和样本统计量分布
- 2.3.5 计算更极端事件的发生概率P值
- 2.3.6.对比P值和显著性水平的大小
- 2.3.7 总结
- 2.3.8 补充资料
- 3 ABTest流程实例
-
- 3.1 实验设计
-
- 3.1.1 确定业务目标
- 3.1.2 选择检验指标
- 3.1.3 确定统计量
- 3.1.4 确定原假设与备择假设
- 3.1.5 样本量计算
- 3.1.6 检验策略、分组策略选择
- 3.2 实验结论分析
-
- 3.2.1 统计检验结果
- 3.2.2 业务决策
- 3.2.3 AB测试的条件的时候,如何解决问题
- 4 总结与拓展
-
- 4.1 如何做一个好的ABTest
- 4.2 关于ABTest的思考
- 4 总结与拓展
-
- 4.1 如何做一个好的ABTest
- 4.2 关于ABTest的思考
本文会涉及较多的统计学知识,如果已经遗忘统计学基础的同学,可以去看我之前写的文章复习一下鸽子学统计。
正如之前的文章所说:如果微积分是研究变量的数学,那么概率论与数理统计是研究随机变量的数学。
研究一个随机变量,不只是要看它能取哪些值,更重要的是它取各种值的概率如何!!!
这句就是本文的核心内容,这篇文章里的所有概念都在是描述一件东西,那就是概率!概率!概率!
企业ABTest全流程
1 认识ABTest
1.1 优点及缺点
-
优点:
- 风险控制: 降低开发成本及用户流失风险。
- 科学择优: 用严密的计算逻辑替领导层减少决策成本。
-
缺点:
- 细小改变与重大改版的博弈: 只能做到局部最优,无法做到全局最优。
- 数据驱动与业务灵感的平衡: 数据驱动无法让业务方获得业务灵感,业务灵感需要跳出数据的框架去获得,数据分析师要注意日常工作中有时需跳出数据的桎梏去贴近业务。
1.2 企业ABTest业务流程


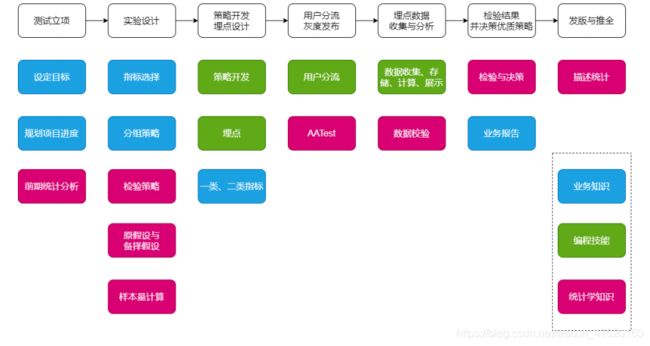
1.3 实际中遇到的问题
-
超多指标之间的选择:
DAU、新用户量、曝光量、点击量、CTR、用户停留时长、留存、用户转化率、GMV、ROI/ROAS
-
过程中会遇到超多问题:
实验方案怎么定?该验哪个指标?数据从哪来?数据准不准?原假设与备择假设是否贴合业务目标?控制变量设置对不对?抽样具不具有代表性?样本数量够不够?灰度发布有没有起效?
2 假设检验
2.1 假设检验逻辑
2.1.1 普通事件逻辑
If A then NOT B ;
则逆反命题为:B then NOT A ;
例如:
如果我有钱(A),我就不会(NOT)买安卓手机(B);
如果我有钱(A),我就不会(NOT)买十万以下的汽车(B);
如果我有钱(A),我就不会(NOT)继续打工(B);
则如果先决条件成立,则逆反命题也同样成立:
如果我买安卓手机(B),则我没钱(NOT A);
如果我买十万以下的汽车(B),则我没钱(NOT A);
如果我继续打工(B),则我没钱(NOT A);
但是如果前面3个先决条件的把握度不高的话,会严重影响我们对B出现后NOT A的推断,导致NOT A无法绝对成立。
2.1.2 假设检验逻辑
由于普通事件无法确定把握度,后面就可以引入我们假设检验的思想:
If A then probably (β) NOT B ;
这个时候,如果我们知道同条件下的各β,我们就能判断各先决条件的可信度。
同理,也有逆反命题:
B then probably(β) NOT A ;
例如:
如果我有钱(A),我就大概率(β)不会(NOT)买安卓手机(B);
如果我有钱(A),我就大概率(β)不会(NOT)买十万以下的汽车(B);
如果我有钱(A),我就大概率(β)不会(NOT)继续打工(B);
则如果先决条件成立,则逆反命题也同样成立:
如果我买安卓手机(B),则我大概率(β)没钱(NOT A);
如果我买十万以下的汽车(B),则我大概率(β)没钱(NOT A);
如果我继续打工(B),则我大概率(β)没钱(NOT A);
到这里,我们就能推导出假设检验的基本逻辑:
- 当你想证明一个事件A 不成立的时候,你可以先找到一件当事件A成立时很大概率不会发生的事件B ;
- 当你发现事件B发生的时候,你就有很大把握证明事件A不成立。
所以我们只需要证明“事件A成立时很大概率不会发生事件B”,我们就能让以上的逻辑成立
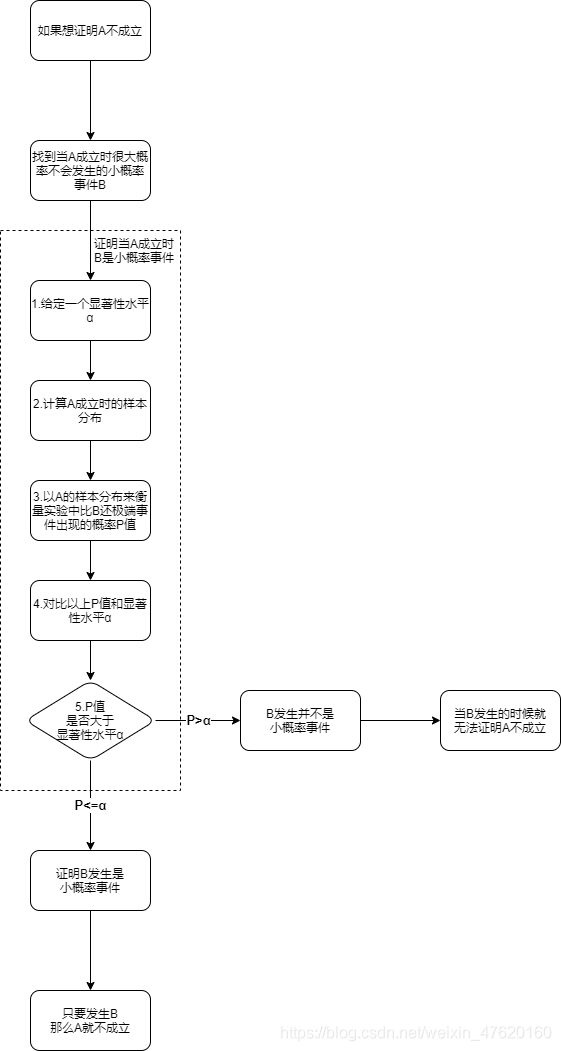
2.2 假设检验步骤
让我们用一组最简单的硬币实验来说明这个流程:
假设我们是一家游戏机中心,我们有一款投币游戏机,如果投进去的硬币足够均匀,那么投的玩家就特别不容易赢。所以我们对硬币生产厂的生产的硬币要求很高。
为了检验硬币是否是均匀的,我们甚至研发了一款投硬币机,可以同时快速地投100枚硬币,并记录投币结果,然后依据一组投递结果,筛选出合格的硬币。但是现在离研发成功还差最后一步,就是给机器设定硬币合格的阈值:
- 出现什么情况我们会判断硬币是不均匀的?
2.2.1 一对完全对立的假设

在假设检验的基本逻辑中,我们把想证明的结论写成备择假设,把想拒绝的结论写成原假设。
在我们的假设检验逻辑中,A成立一般会被我们选为原假设H0;而A不成立,一般会被我们选择为备择假设H1(国外一般使用Ha)。
H0: A事件成立 A
H1: A事件不成立 NOT A
我们主要做的事情:是通过证明B在A条件的前提下是一个小概率事件,只要出现了事件B,就能证明事件A不成立,选择拒绝原假设。
那我们抛硬币实验的假设就可以设置为如下:
H0:硬币是均匀的(A)
H1:硬币是不均匀的(NOT A)
2.2.2 小概率发生的极端事件
比如我们找了几个负责研发投硬币机的同事,让他们给出当硬币是均匀的时候基本不会发生的极端事件:
B1:投100次硬币有90次都是正面
B2:投100次硬币有54次都是正面
B3:投100次硬币有60次都是正面
B4:投100次硬币有58次都是正面
B5:投100次硬币有63次都是正面
2.2.3 给小概率事件一个阈值
这个阈值即平常所说的显著性水平,一般我们设置为0.05(5%),也可以根据具体业务情况设置。
显著性水平代表大概率出错的概率,亦或者说是小概率事件发生的概率。例如我觉得明天大概率(95%)会下雨,则代表了明天大概率会下雨这个事件有5%的可能出错,或者说明天不会下雨这个事件有5%的概率发生。
犯一类错误的后果越严重,那么显著性水平就需要越低。
-
假设检验的结论与实际情况:
实际情况 H0为真 H0为假 拒绝H0 一类错误α(拒真) 正确 不拒绝H0 正确 二类错误β(存伪)
- α+β不一定等于1。
- 在样本容量确定的情况下,α与β不能同时增加或减少。
- 统计检验效力(1-β):当H0为假时,得出拒绝H0的正确结论的概率,被称做检验的效力
- I类错误防范 :
- 小概率α设置小些(避免小概率的触发);
- 增加样本量(使异常数据的影响降低)。
- II类错误防范:
- 调大α(增加小概率的触发) 但是接受I类错误的代价远比II类错误的代价要大,所以不予使用;
- II类错误概率只能在实验结束后才能计算发生二类错误的概率,这是一个事后值。所以在事前
设计我们一般不考虑这个问题。默认二类错误的概率为20%。
2.3.4 计算A成立时的分布和样本统计量分布
比如我们的投硬币实验,假设我们的硬币是均匀的,那我们的总体分布就符合p=0.5的二项分布。
知道总体分布后,我们还需要知道样本符合什么分布。
假设我们做一组10次投币的实验,这时候我们会出现多少种可能的结果?
我们用无顺序的组合数公式可以算出来:
C n + k − 1 k = C 11 10 C^k_{n+k-1}=C^{10}_{11} Cn+k−1k=C1110
(n:每次试验可能出现的结果 k:每组试验重复多少次)
而每种结果,对应的就是我们的样本,每个样本出现概率的分布,就是样本分布。
- 我们可以用EXCEL来计算样本分布情况:
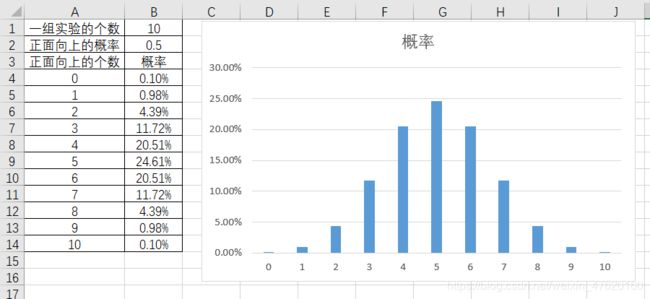
EXCEL二项式样本分布概率计算公式=BINOM.DIST(各个样本结果,一组实验的次数,其中一项的概率,FALSE(概率密度函数))
上述的分布就是事件A(硬币的质量是均匀的) 成立时的样本分布。
对于二项分布的样本分布,我们一般描述为:
X ∼ B ( n , p ) X\sim B(n,p) X∼B(n,p)
其中n为重复次数,p为出现其中一项的概率。在上例中,可以表示为
X ∼ B ( 10 , 0.5 ) X\sim B(10,0.5) X∼B(10,0.5)
对于二项分布:
- 均值为:
E ( x ) = π E(x)=\pi E(x)=π
其中π为实验其中一项的概率,在上例中π=0.5
- 方差为:
D ( x ) = π ( 1 − π ) D(x)=\pi(1-\pi) D(x)=π(1−π)
那回到开始的例子,实验做k次,每次实验投硬币100次,我们直接带入n和p到EXCEL中用原来的算式来计算概率分布。
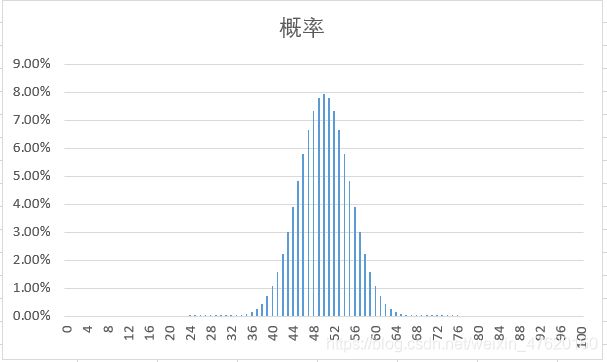
这时,我们的总体期望为:π = 0.5;总体方差为:π (1 - π) = 0.25
除EXCEL外,我们也可以利用中心极限定理来求样本分布概率:从均值为μ、方差为σ2的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值xbar的抽样分布近似服从均值为μ、方差为σ2/n的正态分布。
x ˉ ∼ N ( μ , σ 2 / n ) \bar{x}\sim N(\mu,\sigma^2/n) xˉ∼N(μ,σ2/n)
这时候,我们的样本比例p的分布同样可以适用于中心极限定理,其样本比例的期望π可以直接套用其公式中的均值μ,套用公式可得:
p ∼ N ( π , π ( 1 − π ) / n ) = N ( 0.5 , 0.0025 ) p\sim N(\pi,\pi(1-\pi)/n) =N(0.5,0.0025) p∼N(π,π(1−π)/n)=N(0.5,0.0025)
2.3.5 计算更极端事件的发生概率P值
比“投100次硬币有90次都是正面”(B1事件) 更极端的事件有什么?
比如“91 次正面,9 次反面”、“91 次反面,9 次正面”……
转化为比例则为:“正面比例为0.91”,“正面比例为0.09”……
极端事件的概率P值就是比所得到的样本观察结果**(B1事件,即90次正面)** 更极端的结果出现的概率。由于计算公式复杂,我们一般用EXCEL计算:
= 1 − N O R M . D I S T ( B 发生的概率 , 样本的期望比例 π , 样本比例的标准差 π ( 1 − π ) / n ) , 是否是累计概率 ( 1 ) ) =1-NORM.DIST(B发生的概率,样本的期望比例\pi,样本比例的标准差\sqrt{\pi(1-\pi)/n}),是否是累计概率(1)) =1−NORM.DIST(B发生的概率,样本的期望比例π,样本比例的标准差π(1−π)/n),是否是累计概率(1))
本例中,我们使用Excel函数(由于正面和反面90次都是同一极端事件,是双尾,所以要乘2得到极端事件的概率P值):
P值=(1-NORM.DIST(0.9,0.5,0.05,1))✖2
求得P值为0(实际应为1.2442E-15,但是这个数据过小,Excel计算不出来)。
2.3.6.对比P值和显著性水平的大小
由于上面求出的P值小于显著水平α,这时我们可以说B1事件是极小概率事件。
这时我们就能利用之前的逻辑:B then probably NOT A
所以当B1事件出现时,我们有足够的理由拒绝原假设,接受备择假设。 之后我们将B2~B5的情况都计算一遍:
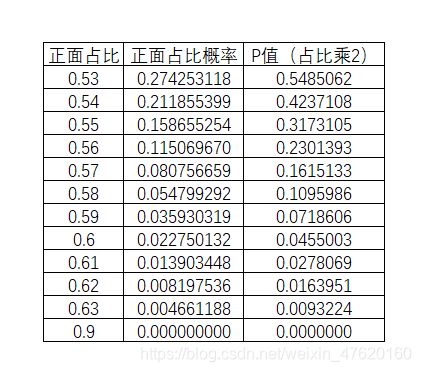
从上表中,我们可以发现,当正面占比为0.6的时候,即“投100次硬币60次都是正面”的时候,P值刚好小于显著性水平,所以我们一般选取60次正面为本例中判断硬币是否均匀的小概率事件,当我们投100次硬币时,观测到样本发生大于60次正面(或者反面),我们就可以拒绝硬币是均匀的假设,即硬币不均匀。
但是在日常工作中,用上面的列表计算起来有些麻烦,所以有的时候,我们直接使用显著性水平计算一个统计量的阈值。
使用Excel的函数NORM.INV(),可以快速求出显著性水平所对应的阈值:
N O R M . I N V ( 阈值对应位置 , 样本比例的期望 π , 样本比例的标准差 π ( 1 − π ) / n ) ) NORM.INV(阈值对应位置,样本比例的期望\pi,样本比例的标准差\sqrt{\pi(1-\pi)/n})) NORM.INV(阈值对应位置,样本比例的期望π,样本比例的标准差π(1−π)/n))
其中 , 阈值对应位置 : { α / 2 双侧检验左侧拒绝域 1 − α / 2 双侧检验右侧拒绝域 α 单侧检验左侧拒绝域 1 − α 单侧检验右侧拒绝域 其中,阈值对应位置:\begin{cases} \alpha/2\qquad 双侧检验左侧拒绝域\\ 1-\alpha/2\ 双侧检验右侧拒绝域\\ \alpha\ \ \ \ \qquad 单侧检验左侧拒绝域\\ 1-\alpha\ \ \ \ \ 单侧检验右侧拒绝域\\ \end{cases} 其中,阈值对应位置:⎩ ⎨ ⎧α/2双侧检验左侧拒绝域1−α/2 双侧检验右侧拒绝域α 单侧检验左侧拒绝域1−α 单侧检验右侧拒绝域
2.3.7 总结
根据上面例子的步骤计算后,这时我们会发现,假设检验逻辑与原来的逻辑相比,变化为:
(变化已标红)
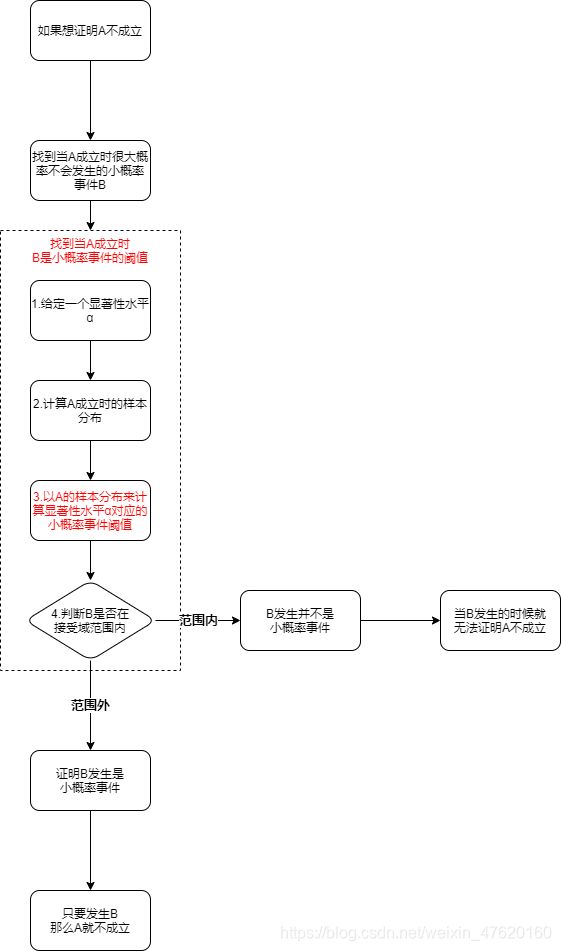
2.3.8 补充资料
- 如何判断一个样本统计量符合什么分布:
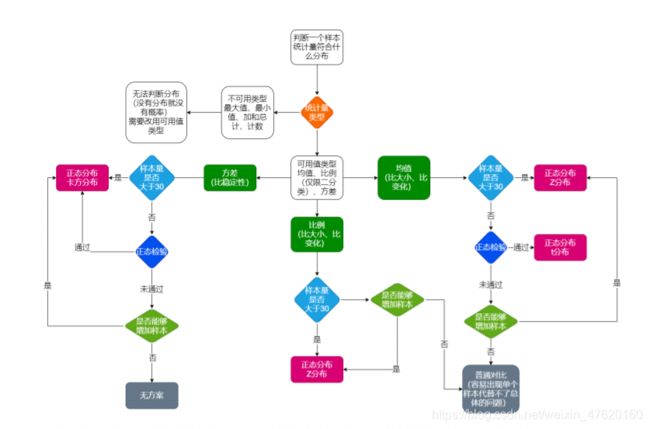
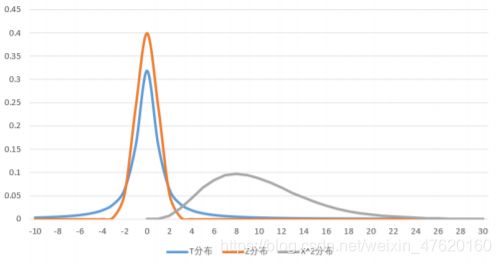
- 统计分布(Z分布,T分布,卡方分布):

-
T分布与标准正态分布(Z分布)都是以0为对称的分布,T分布的方差大所以分布形态更扁平些
-
卡方分布是大于0的右偏分布,随着自由度的增加会趋近于正态分布(注意不是标准正态分布)
- 多个总体:

-
不同分布的拒绝域:
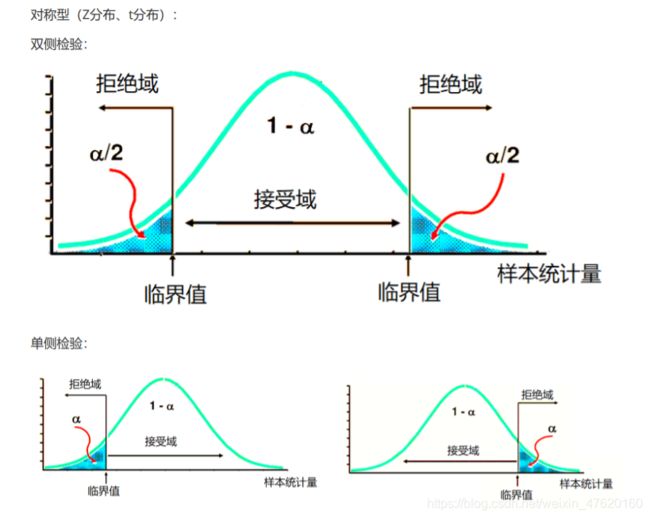

-
卡方分布在左侧的拒绝域特别小,所以拒绝的区间的值也比较少,所以卡方检验的拒绝域一般放在右侧,F分布同理。

-
概率中的PDF\PMF\CDF\PPF\ISF函数:本文内容中出现的所有公式均是基于中心极限定理和正态分布曲线来计算各种概率及标准差等,下面是各种概率函数的解释,看完基本能理解本文公式本后的逻辑。
- pdf:probability density function,概率密度函数,意思是某个连续变量在某个区间内(x轴的区间)的概率密度(x轴的区间对应的y轴曲线面积)有多大;
- pmf:probability mass function,概率质量函数,意思是某个离散变量在某个值(x轴的值)对应的概率(y轴的值)有多大;
- CDF:cumulative distribution function,累积分布函数,表示所有<=x 的值(x轴的值左侧)出现的概率之和(x轴的值左侧对应的y轴曲线面积);(意思就是已知随机变量的值求<=x 值出现的概率和)
- PPF:Percent Point Function,是CDF的逆函数,意思是某分布出现的概率之和(x轴)对应的值为<=y的值(y轴),这个函数的x轴是概率(CDF的Y轴值),y轴是概率之和为x时随机变量的值(CDF的X轴值),作用是找到正态分布中累计分布函数为y时对应x轴的随机变量值;(意思就是已知<=x 值出现的概率和求随机变量的值)
- ISF函数:等于1 - PDF函数,意思是某分布出现的概率之和(x轴)对应的值为>=y的值(y轴),用于求某个分布上的α分位点。
- SF函数:等于1 - CDF函数,意思是所有>x 的值出现的概率之和,用于验证假设检验事件出现的概率。
3 ABTest流程实例
3.1 实验设计
让我们用一个电商中常见的ABTest来说明这个流程:
某电商平台发现,中小店铺面临的流量问题,形成了大店铺流量越来越多,中小店铺流量越来越少的局面。现在需要数据分析师研究一个策略来改变这种业务现状。
经过一番讨论,我们初步决定,在用户支付完成页面的推荐商品页中,固定设置中小店铺展示位置,来增加中小店铺的展示流量。
现在我们需要设计一个AB实验,来对比不同地固定展示位数量,哪个对业务目标地提升最大。
3.1.1 确定业务目标
如何确定业务目标:
- 明确我们要提升的业务指标(如果明确这个部分,实验会变得精简、目标明确);
- 明确我们要改进的产品/策略。
在本例中,我们确定的业务目标为:
在下单推荐页设置固定中小店铺展示位置,通过对比3个固定展示位、6个、9个的区别,探究最优展示位个数。
3.1.2 选择检验指标
我们一般选择一个一类指标和一个二类指标(也可以选择多个),来对比不同实验条件的优劣:
-
一类指标:不能容忍变差的指标;
-
二类指标:业务目标需要提升的指标。
-
如何确定一类指标:从业务出发,去寻找最无法忍受变差的指标,如下图所示
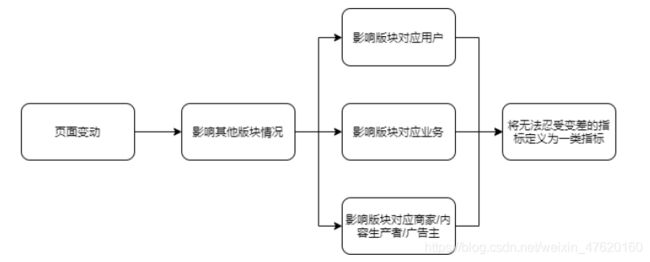
- 如何确定二类指标:筛选第二类指标时,我们一般从用户路径出发去梳理
确定试验目标后,我们会从该试验所改变的用户路径点出发,从变动点后面的路径中选择我们所需的二类指标。第一类则前后都可以选,如下面的电商用户路径图所示:

- 业务场景举例:

在本例中,我们的目标是提升中小店铺在下单推荐页的下单量,那么应该提升多少呢?
这时候我们应该使用科学的方法来计算提升量,不然实验的可信度会大大降低,因为老板并不知道应该提升多少才是好的。
根据正态分布的性质,1个标准差内包含68.2%的数据,2个标准差内是95.5%的数据,3个内是99.7%的数据;数据在3个标准差内波动为正常现象。为观测到显著的提升,所以我们一般设置提升量为实验前的两个标准差。
那么根据公司的实际业务不同,我们计算实验前中小店铺人均下单量的二倍标准差,求得提升量为30%。
此时我们就能确定二类指标:C类店铺人均下单量上升 30%。
由于在下单推荐页将一部分流量固定分配给中小店铺,那大店铺的流量肯定会受到损失。
那么我们的一类指标就可以确定为:A类店铺人均下单量下降在15%以内(实验前大店铺人均下单量两个标准差以内)
在实际业务中,如果实在无法计算提升量,我们也可以不计算,直接使用双侧检验来检验实验组对于对照组是否有显著变化,再根据实验组与对照组的差值或比值来判断变化方向。
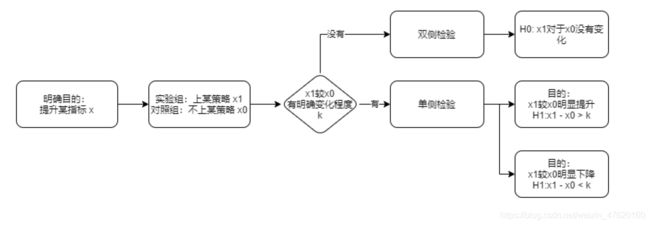
3.1.3 确定统计量
- 确定指标之后,我们就可以接着确定统计量:
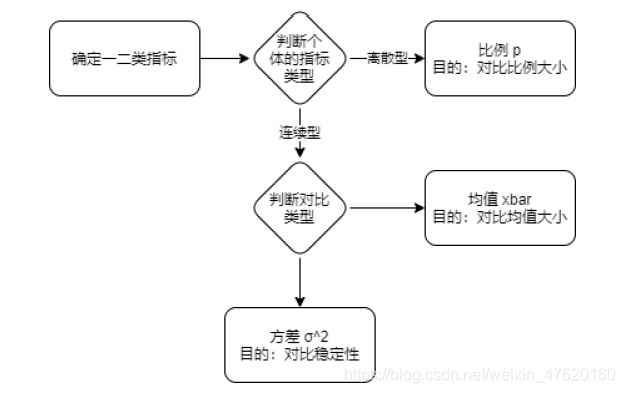
在本例中,我们确定的两类指标都是人均下单量,即均值,所以我们的统计量则为实验组和对照组的均值之差,由此可得到2.3.8补充资料中的均值之差计算公式:
x ˉ 1 − x ˉ 2 ∼ N ( u 1 − u 2 , σ 1 2 n 1 + σ 2 2 n 2 ) \bar{x}_1-\bar{x}_2\sim N(\,u_1-\,u_2,\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}) xˉ1−xˉ2∼N(u1−u2,n1σ12+n2σ22)
3.1.4 确定原假设与备择假设
我们一般设置我们想要验证的结果为备择假设H1,所以本例中,两类指标的假设如下:
-
一类指标
- H0 : 对照组大店铺人均下单量 - 实验组大店铺人均下单量 >= 对照组大店铺人均下单量2倍标准差(等号一般放在H0中)
- H1 : 对照组大店铺人均下单量 - 实验组大店铺人均下单量 < 对照组大店铺人均下单量2倍标准差
-
二类指标
- H0: 实验组中小店铺人均下单量 - 对照组中小店铺人均下单量 <= 30%对照组中小店铺人均下单量
- H1: 实验组中小店铺人均下单量 - 对照组中小店铺人均下单量 > 30%对照组中小店铺人均下单量
3.1.5 样本量计算
在统计学上,我们一般根据统计量抽样分布和边际误差确定样本量。而在业务层面,我们则是以一类错误临界值二类错误临界值计算:
- 估计总体均值时的样本容量
n = ( Z α / 2 ) σ 2 E 2 n=\frac{(Z_{\alpha/2})\sigma^2}{E^2} n=E2(Zα/2)σ2
- 估计总体比例时的样本容量
n = ( Z α / 2 ) ⋅ π ( 1 − π ) E 2 n=\frac{(Z_{\alpha/2})\cdot\pi(1-\pi)}{E^2} n=E2(Zα/2)⋅π(1−π)
- 其中,E2为区间估计算式中的E2
x ˉ ± E 2 , 其中 E 2 = Z α / 2 ∗ σ 2 / n \bar{x}\pm E^2,其中E^2 =Z_{\alpha/2}*\sqrt{\sigma^2/n} xˉ±E2,其中E2=Zα/2∗σ2/n
- Zα/2 为2.2.6中所说的显著性水平阈值计算公式NORM.INV的值,我们可以将其直接代入公式中
但是,在日常工作中,由于各种实验的策略都不一样,导致实验组和对照组可能服从不同的总体分布,所以我们一般选择两个总体的样本量计算公式,如下面四个公式所示,而非上面的公式:
- 估计均值之差时的样本量计算公式(双侧)
A 组样本量 n A = k n B B 组样本量 n B = ( 1 + 1 k ) ( σ z 1 − α / 2 + z 1 − β μ A − μ B ) 2 A组样本量n_A=kn_B\\B组样本量n_B=(1+\frac{1}{k}) (\sigma\frac{z_{1-\alpha/2}+{z_{1-\beta}}}{\mu_A-\mu_B})^2 A组样本量nA=knBB组样本量nB=(1+k1)(σμA−μBz1−α/2+z1−β)2
- 估计比例之差时的样本量计算公式(双侧)
A 组样本量 n A = k n B B 组样本量 n B = ( p A ( 1 − p A ) k + p B ( 1 − p B ) ) ( z 1 − α / 2 + z 1 − β p A − p B ) 2 A组样本量n_A=kn_B\\B组样本量n_B =(\frac{p_A(1-p_A)}{k}+p_B(1-p_B)) (\frac{z_{1-\alpha/2}+{z_{1-\beta}}}{p_A-p_B})^2 A组样本量nA=knBB组样本量nB=(kpA(1−pA)+pB(1−pB))(pA−pBz1−α/2+z1−β)2
- 估计均值之差时的样本量计算公式(单侧)
A 组样本量 n A = k n B B 组样本量 n B = ( σ A 2 + σ B 2 / k ) ( z 1 − α + z 1 − β μ A − μ B ) 2 A组样本量n_A=kn_B\\B组样本量n_B=(\sigma_A^2+\sigma^2_B/k) (\frac{z_{1-\alpha}+{z_{1-\beta}}}{\mu_A-\mu_B})^2 A组样本量nA=knBB组样本量nB=(σA2+σB2/k)(μA−μBz1−α+z1−β)2
- 估计比例之差时的样本量计算公式(单侧)
A 组样本量 n A = k n B B 组样本量 n B = ( p A ( 1 − p A ) k + p B ( 1 − p B ) ) ( z 1 − α + z 1 − β p A − p B ) 2 A组样本量n_A=kn_B\\B组样本量n_B =(\frac{p_A(1-p_A)}{k}+p_B(1-p_B)) (\frac{z_{1-\alpha}+{z_{1-\beta}}}{p_A-p_B})^2 A组样本量nA=knBB组样本量nB=(kpA(1−pA)+pB(1−pB))(pA−pBz1−α+z1−β)2
-
求两个总体的方差σ:
- 均值之差:
σ = σ A n A + σ B n B \sigma=\sqrt{\frac{\sigma_A}{n_A}+\frac{\sigma_B}{n_B}} σ=nAσA+nBσB
- 均值之差:
-
比例之差
σ = p A ( 1 − p A ) n A + p B ( 1 − p B ) n B \sigma=\sqrt{\frac{p_A(1-p_A)}{n_A}+\frac{p_B(1-p_B)}{n_B}} σ=nApA(1−pA)+nBpB(1−pB)
其中:
- A组一般为实验组,B组一般为对照组,反过来也同样可以。
- k为A组与B组的样本量之比,如果计划AB两组有差异,那我们按照计划AB两组的差异来取值,比如我们就要取A组5万人,B
组1万人,那么k=5;如果没有差异,则一律假设为AB两组个数相同,也就是k=1。 - α为显著性水平,一般为0.05,β为二类错误概率,默认为0.2。
- σ为标准差,由于计算样本量时一般不知道实验组的σ,我们在这里假定AB组σ相等,然后求出原有群体总体的标准差即可。
- Z1-α : Python公式:stats.norm.ppf(1-α); EXCEL公式:NORM.INV(1-α,0,1);
- Z1-β: Python公式:stats.norm.ppf(1-β); EXCEL公式:NORM.INV(1-α,0,1);
- μ为均值,p为比例(如果是二项式分布值0,1的话,比例等于均值),μA-μB及PA-PB为统计量,即H1,在本例中为实验组和对照组的均值之差。
- μA和μB:
- 假如我们H1为实验组比对照组显著大a。也就是:μA - μB > a。那么 μA - μB 在这里就可以假设 = a ;
- 假设我们H1为实验组比对照组显著大。也就是:μA - μB > 0,那我们需要给 μA - μB 一个比较小的值,比如0.01或者0.1,因为"实验组比对照组大0"相当于实验组和对照组一样大,所以我们至少要给他一个值,比如0.01或者0.1。那么这里 μA - μB 就可以假设 = 0.01或者0.1。
- pA和pB(也叫πA和πB):
- 首先我们先求出原来总体的比例P1,将对照组πB带入,也就是πB = P1,之后我们按照H1来求实验组πA;
- 假如我们H1为实验组比对照组显著大a。也就是:πA - πB > a。那么 πA 在这里就可以假设 =πB + a;
- 假设我们H1为实验组比对照组显著大。也就是:πA - πB > 0,那我们需要给 πA - πB 一个比较小的值,比如0.001 或者 0.01(因为是比例差,所以需要比均值差要小),因为"实验组比对照组大0"相当于实验组和对照组一样大,所以我们至少要给他一个值,比如0.001 或者0.01。那么这里 πA 就可以假设 = πB + 0.001 或者 0.01。
- 如果无目标提升(或减少)量,一般使用双侧检验,如果有明确的提升(减少)量做对比,一般使用单侧检验。
也可以用以下的网站直接生成样本量,无需手动计算:
- 样本量计算工具:http://powerandsamplesize.com/Calculators/Compare-2-Means/2-Sample-Equality
在本例中,由于我们明确了一类指标的下降阈值和二类指标的上升目标,所以都使用单侧检验。使用均值之差时的样本量计算公式(单侧)计算得到第二类指标的最小样本量为3382.83,第一类指标的最小样本量为1483.21。由于我们平台的日活跃用户为1000万,所以我们给每组分配0.1%的流量,即每组1万人。
3.1.6 检验策略、分组策略选择
在统计学中,检验统计量差异是否显著的方法有T检验、Z检验、卡方检验和F检验。在ABTest中,主要是对样本均值或比例进行检验,所以一般用T检验和Z检验。但是在业务中,一般只使用T检验来检验最终的统计结果与指标的目标是否显著,因为T分布较Z分布多了一个自由度的变量,惩罚小样本,增加其拒绝原假设H0的难度,因而一般采用T检验,优于Z检验。
在本例中,由于我们明确了一类指标的下降阈值和二类指标的上升目标,所以使用单侧独立样本T检验。
我们的分组策略是:
- A组:下单推荐页前12个推荐,9个C类店铺商品
- B组:下单推荐页前12个推荐,6个C类店铺商品
- C组:下单推荐页前12个推荐,3个C类店铺商品
- D组:不干预(对照组)
3.2 实验结论分析
3.2.1 统计检验结果
P值就是我们错误拒绝原假设的概率。例如P值为0.01的时候,也就是说我们错误地拒绝原假设的概率只有0.01,那么我们有理由相信原假设原本就是错误的,而非检验错误导致。简而言之,P值越小,越有理由拒绝原假设。
如果对概率P值计算不太清楚的话,可以看2.3.8中的概率中的PDF\PMF\CDF\PPF\ISF函数部分解释,本文内容中出现的所有公式均是基于中心极限定理和正态分布曲线来计算各种概率及标准差等,下面是各种概率函数的解释,看完基本能理解本文公式本后的逻辑。
- 观测实验结果的第一种方法:
通过统计量及统计量的P值来观测。即我们抽样产生实验组和对照组的统计量(也可以叫统计结果,即μA-μB及PA-PB)在这个用户总体中出现的概率是多少,如果概率P值小于我们的显著性水平α,我们既可以认为这个样本的实验结果对比总体是小概率事件,即不是由于样本随机波动的因素导致的,而是由于实验因素导致的。则可以拒绝原假设,接受我们的备择假设。
不同统计量对应不同的P值计算公式:
-
右侧检验:H1: μA - μB > a 或者 πA - πB > a ,这时候,检验为右侧检验,拒绝域为右侧。
-
均值之差公式:
概率 P 值 = s t a t s . n o r m . s f ( x ˉ A − x ˉ B , μ A − μ B , S A 2 n A + S B 2 n A ) 概率P值 = stats.norm.sf(\bar{x}_A-\bar{x}_B,\mu_A-\mu_B,\sqrt{\frac{S^2_A}{n_A}+\frac{S^2_B}{n_A}}) 概率P值=stats.norm.sf(xˉA−xˉB,μA−μB,nASA2+nASB2)- xbar_A : 抽取的实验组的均值
- xbar_B : 抽取的对照组的均值
- μA - μB:H1: μA - μB > a,即a
- S_A^2:抽取的实验组的方差
- S_B^2:抽取的对照组的方差
-
比例之差公式:
概率 P 值 = s t a t s . n o r m . s f ( p A − p B , π A − π B , p A ( 1 − p A ) n A + p B ( 1 − p B ) n A ) 概率P值 = stats.norm.sf(p_A-p_B,\pi_A-\pi_B,\sqrt{\frac{p_A(1-p_A)}{n_A}+\frac{p_B(1-p_B)}{n_A}}) 概率P值=stats.norm.sf(pA−pB,πA−πB,nApA(1−pA)+nApB(1−pB))-
p_A : 抽取的实验组的比例
-
p_B : 抽取的对照组的比例
-
πA - πB:H1: πA - πB > a,即a
-
n_A :抽取的实验组的样本量
-
n_B :抽取的对照组的样本量
-
-
-
左侧检验:H1: μA - μB < a 或者 πA - πB < a ,这时候,检验为左侧检验,拒绝域为左侧。
-
均值之差公式:
概率 P 值 = s t a t s . n o r m . c d f ( x ˉ A − x ˉ B , μ A − μ B , S A 2 n A + S B 2 n A ) 概率P值 = stats.norm.cdf(\bar{x}_A-\bar{x}_B,\mu_A-\mu_B,\sqrt{\frac{S^2_A}{n_A}+\frac{S^2_B}{n_A}}) 概率P值=stats.norm.cdf(xˉA−xˉB,μA−μB,nASA2+nASB2) -
比例之差公式:
概率 P 值 = s t a t s . n o r m . s f ( p A − p B , π A − π B , p A ( 1 − p A ) n A + p B ( 1 − p B ) n A ) 概率P值 = stats.norm.sf(p_A-p_B,\pi_A-\pi_B,\sqrt{\frac{p_A(1-p_A)}{n_A}+\frac{p_B(1-p_B)}{n_A}}) 概率P值=stats.norm.sf(pA−pB,πA−πB,nApA(1−pA)+nApB(1−pB))
-
-
观测实验结果的第二种方法:
通过样本量分布和显著性水平来确定拒绝域和接受域,从而拒绝或者接受结果。见假设检验部分,100次掷硬币实验的显著性阈值为60次正面或反面,只要超出60次则认为是小概率事件,而接受硬币是不均匀的备择假设。
在本例中,我们最后在测试日结束后,计算的值为:
- 一类指标:(使用观测实验结果的第一种方法)
- A组概率P值为1.0
- B组概率P值为0.0001
- C组测试日样本量未到到最小样本量要求
- 二类指标人均下单量:(观测实验结果的第二种方法)
- A组0.0064
- B组0.4697
- C组测试日样本量未到到最小样本量要求
- D组0.1318
- 对照组中小店铺人均下单量(所有日期,不是只有测试日)的30%为0.031
3.2.2 业务决策
一般我们根据下图的流程来进行决策:
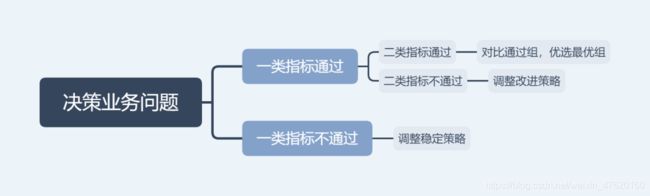
在本例中,我们的决策为:
- 一类指标评估:B策略的一类指标下降幅度在两个标准差内,符合要求;
- 二类指标评估:B策略的二类指标最优,同时上升幅度显著大于30%,符合要求;
- 决策:考虑推全B策略。
- 为了避免我们的取的那天数据是一个异常值,可以多用几天的数据来做检验。
3.2.3 AB测试的条件的时候,如何解决问题
- 没有系统:没有灰度发布系统,无法给不同用户发送不同版本。可以考虑手动进行分组,然后进行线下试验,或者手动给不同用户发送不同的版本;
- 用户量不够:无法达到最小样本量。可以减少实验条件,或者重新设计实验;如果是统计量比例,可以延长实验周期;如果是小众用户,可以考虑配对样本T检验。
- 时间成本高:如果是一个月度以上的实验,时间成本太高。可以研究以日为周期或周为周期对月度的影响,然后进行日实验或周实验。
4 总结与拓展
4.1 如何做一个好的ABTest
- 确定对照组和实验组,最好是做单变量的实验,一次只改变一个变量。
- 分流时尽量排除混杂因素,一般情况下采用随机分流即可。如果随机分流无法保证样本分布于总体分布一致。建议采用手动的分层随机分流。对比样本与总体用户的属性分布是否一致最常用的属性是地域。
- 检查流量是否达到最小样本量要求,达不到要求则没法进行后续的分析,实验结果不可信。如果可以扩展试验周期,可以将试验周期从一天扩展到一周或N周,以保证样本量满足要求。如果是多水平实验达不到要求,可以减少水平数。
- 准确收集用户行为数据,这就要求埋点必须正确。
4.2 关于ABTest的思考
- 产品改进如同玩扫雷游戏,没人知道真正的方向在哪,ABTest的作用只是提示你周围可能有多少雷,有时候成败也看运气。
- 灰度发布+ABTest能够有效规避风险,但是过多地依靠数据决策,是在激励我们更好地创新?还是在让我们为数据打工?
- ABTest适用于循序渐进的改进;ABTest适用于回答是非题;ABTest容易衡量短期效益,ABTest只能做到局部最优而非全局最优。那么,当我们有一些颠覆性想法时,会不会被ABTest桎梏?如何避免这种情况?
够:无法达到最小样本量。可以减少实验条件,或者重新设计实验;如果是统计量比例,可以延长实验周期;如果是小众用户,可以考虑配对样本T检验。
- 时间成本高:如果是一个月度以上的实验,时间成本太高。可以研究以日为周期或周为周期对月度的影响,然后进行日实验或周实验。
4 总结与拓展
4.1 如何做一个好的ABTest
- 确定对照组和实验组,最好是做单变量的实验,一次只改变一个变量。
- 分流时尽量排除混杂因素,一般情况下采用随机分流即可。如果随机分流无法保证样本分布于总体分布一致。建议采用手动的分层随机分流。对比样本与总体用户的属性分布是否一致最常用的属性是地域。
- 检查流量是否达到最小样本量要求,达不到要求则没法进行后续的分析,实验结果不可信。如果可以扩展试验周期,可以将试验周期从一天扩展到一周或N周,以保证样本量满足要求。如果是多水平实验达不到要求,可以减少水平数。
- 准确收集用户行为数据,这就要求埋点必须正确。
4.2 关于ABTest的思考
- 产品改进如同玩扫雷游戏,没人知道真正的方向在哪,ABTest的作用只是提示你周围可能有多少雷,有时候成败也看运气。
- 灰度发布+ABTest能够有效规避风险,但是过多地依靠数据决策,是在激励我们更好地创新?还是在让我们为数据打工?
- ABTest适用于循序渐进的改进;ABTest适用于回答是非题;ABTest容易衡量短期效益,ABTest只能做到局部最优而非全局最优。那么,当我们有一些颠覆性想法时,会不会被ABTest桎梏?如何避免这种情况?