哈希应用之布隆过滤器
文章目录
- 1.介绍
-
- 1.1百度搜索
- 1.2知乎好文
- 1.3自身理解
- 2.模拟实现
-
- 2.1文档阅读
- 2.2代码剖析
- 3.误判率的研究
- 4.布隆过滤器的应用
-
- 4.1如何找到两个分别有100亿个字符串的文件的交集[只有1G内存].分别给出精确算法和近似算法
- 4.2如何扩展BloomFilter使得它支持删除元素的操作
- 5.整体代码

1.介绍
1.1百度搜索

1.2知乎好文
详解布隆过滤器的原理,使用场景和注意事项

1.3自身理解
有了哈希和位图 为什么还要搞一个布隆过滤器?
位图只能处理海量整形的数据 当数据为字符串类型且大量时 目前还没有学习一个可以处理的结构
布隆过滤器的思想
当数据为字符串时 数据是很难处理的 例如当大量字符串需要处理 假定每个字符串的个数都为10 那么这些字符串可能有256^10种可能存在 [ASCII表共有256种字符] 如果用位图的思想 总共能存2的32次方种状态 怎么解决? 我们想到用2个甚至更多的比特位来标识一种字符串 但是这样仍不能避免冲突
布隆过滤器的核心
- 布隆过滤器最大限度减少了冲突 一个数据存在可能是误判的 但一个数据不存在一定是不存在
- 以一个值映射多个位置的这种方法来降低误判率
- 一个值映射多个位置是用哈希函数来映射的 即用3个值来映射就需要3个哈希函数
- 哈希函数越多 误判率越低 但所用空间越大
用一个简单的场景来介绍
在生活中我们经常会遇到这样一个页面
这里输入的就是一个字符串类型 如果我们用之前的算法处理 效率太过低下 因为这个游戏要求昵称单一即不能重复 当用户输入一个昵称[字符串] 游戏要把这个字符串和王者荣耀现有的所有字符串比较一遍查看用户输入的这个字符串是否被允许使用 而王者荣耀现有用户为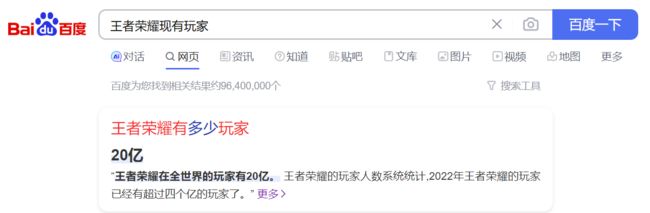
如果仅仅开始注册输入一个昵称就需要这么长时间 我想大多数人骂一句之后直接卸载 
那怎么处理呢? 此时布隆过滤器的作用就大展身手了 布隆过滤器的查询效率是O(1)当用户输入的昵称不可用时 通过布隆过滤器可以明确的得到==[您输入的昵称不可用]==这样一个结果 但是有人问了 布隆过滤器虽然可以肯定的判断数据不存在 但是会误判存在 那怎么办?面对此种情况 大佬这样设计 当输入的数据使用布隆过滤器查询时 得到了false的结果 下一半会再到磁盘上的数据库查询以便得到确切结果 又有人说了 不如直接去数据库 一步到位 我们来回答这个问题:1.昵称查询状态是不存在即可用时 这个结果是确切的 不存在就是不存在 可以用 当昵称判断结果是存在即不可用的 即便这个结果可能误判 一个昵称 用户再输入一个就完了 2.不同的是 用户输入一个身份证号[以下简称id]时 查询不存在即可用 [这样的情况是大多数的 因为用户知道自己的id] 当查询存在时 设计者此时设计了 再去数据库查找这一步骤就可解决[这样的情况是极少见的 因为用户自己知道到底有没有用过这个id去注册 忘记的情况也很少 即便忘记 设计者也有后续解决办法即去数据库再查找 所以整体看 先使用布隆过滤器"过滤"这样的效率无疑是最优的 "布隆过滤器"的名称想必各位也心中有数]
2.模拟实现
2.1文档阅读
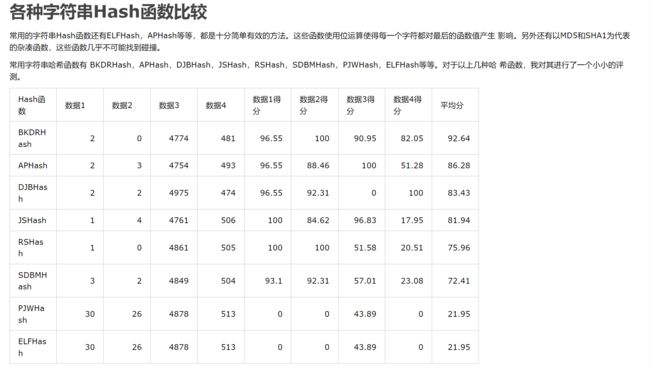
字符串Hash函数对比

2.2代码剖析


3.误判率的研究
//测试误判率
void test_bloomfilter2()
{
srand(time(0));
const size_t N = 10000;
BloomFilter<N> bf; //4w个比特位
v1:url1 url2 url3...url9999///
vector<string> v1;
string url = "https://www.gitee.com/Ape-LHR/apes-warehouse/547993.html";
//v1存储内容:url1 url2 url3....url9999共N个
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + to_string(i));
}
//把v1里面的每个字符串插入到布隆过滤器
for (auto& str : v1)
{
bf.insert_setone(str);
}
/v2:url10000 url10001 url10002...url19999
//v2存储和v1前缀相同 后缀不同的字符串
vector<string> v2;
for (size_t i = N; i < 2 * N; ++i)
{
v2.push_back(url + to_string(i));
}
size_t count1 = 0;
for (auto& str : v2)
{
if (bf.judge(str))
++count1;
}
double rate1 = (double)count1 / (double)N;
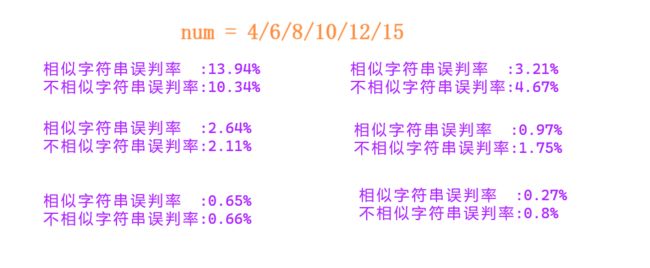
cout << "相似字符串误判率 :" << rate1 * 100 << "%" << endl;
///
//v3存储和v1前缀和后缀均有较大差异
vector<string> v3;
string url2 = "https://www.csdn.net/?spm=1001.2014.3001.4476";
for (size_t i = 0; i < N; ++i)
{
v3.push_back(url2 + to_string(i + rand()));
}
size_t count2 = 0;
for (auto& str : v3)
{
if (bf.judge(str))
++count2;
}
double rate2 = (double)count2 / (double)N;
cout << "不相似字符串误判率:" << rate2 * 100 << "%" << endl;
}
num增加 开的比特位更多 数据分布越分散 误判率越低 也可以通过增加哈希函数的个数[效果不佳]
4.布隆过滤器的应用
4.1如何找到两个分别有100亿个字符串的文件的交集[只有1G内存].分别给出精确算法和近似算法
估算大小
假设一个字符串占50字节 100亿个字符串占5000亿字节 ≈ 500G
思路
将每个文件分成1000份 每份0.5G 此时去查找交集
上述思路的问题
每一个A小文件都要去B小文件查找 共1000 * 1000次查找 效率极低
解决办法
对于A文件中的每一个字符串通过特定的函数计算出Hashi = hashfunc(string) % 1000
1000个文件即1000个小容器 字符串依据函数计算出下标 不同的下标进入不同的文件 假定A的1000个小文件分别是a0 a1 a2 a3…a999[B小文件亦然] 此时只需比较a0和b0 a1和b1…ai和bi
为什么只需比比较ai和bi?
A和B中成为交集的要求是string相同 如果string相同 因为hashfunc相同他们进入的文件编号一定相同 若要查找交集 只需查找比较编号相同的文件即可
存在问题
此时的切分不再是平均切分 通过这样的哈希切分 存在这样一个情况 a50号文件大小50M b50号文件5G
能不能将超出预期大小的文件再次进行哈希切分?
不能.因为存在这样一种情况: b50号文件大小5G 但重复字符串有4G 无论怎么二次切分 都会存在一个超出预期大小的文件
解决办法
利用unordered_set/set不可存储重复值的特点 将超出预期的小文件中的字符串依次读取
如果文件中的字符串都可以成功插入 set所能存储字节数有限 超出预期的文件都能插入成功 说明 该文件存在大量重复string
如果插入工程抛出内存异常 则该超出预期的文件中有大量非重复string 以至于没插完内存就不够了
4.2如何扩展BloomFilter使得它支持删除元素的操作
布隆过滤器不支持删除操作 因为一个位置可能是多个数据的子位
假如 x y 存在 且二者位置有交集 删除x后 y也被认为不在 而y实际存在
若非要支持删除 则可以:原来每个位是0/1 现在我们让每3个位作为一个位置
111最大可以标识7 当不存在置0 每存在一次++ 删除则-- 存在的问题 当数据量过大 7不一定能避免重复
如果继续增大 比如用4个位 1111最大标识15 但是所需空间增大 可能溢出
5.整体代码
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include
#include