深度学习入门 (六):梯度消失与梯度爆炸、权重的初始值、Batch Normalization、Group Normalization
目录
- 梯度消失与梯度爆炸
- 权重的初始值
-
- 权重初始值可以设为 0 吗? (随机生成初始值的重要性)
- 观察权重初始值对隐藏层激活值分布的影响
- Xavier 初始值
- He 初始值
- 归一化输入 (Normalizing inputs)
- Batch Normalization
-
- BN 层的正向传播
- BN 层的反向传播
-
- 基于计算图进行推导
- 不借助计算图,直接推导
- 代码实现
- Group Normalization
- 参考文献
梯度消失与梯度爆炸
- 本节参考:梯度消失、爆炸原因及其解决方法
梯度消失与梯度爆炸
- 层数比较多的神经网络模型在使用梯度下降法对误差进行反向传播时会出现梯度消失和梯度爆炸问题。梯度消失问题和梯度爆炸问题一般会随着网络层数的增加变得越来越明显。当出现梯度消失或梯度下降时,可能会出现网络中靠近输出的层学习的情况很好,但靠近输入的层学习的很慢/参数变化很剧烈
- 梯度消失的原因:假如神经网络所用的激活函数是 s i g m o i d sigmoid sigmoid 函数,即 f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1,则 f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x)=f(x)(1−f(x)) f′(x)=f(x)(1−f(x))。因此两个 0 到 1 之间的数相乘,得到的结果就会变得很小。神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差就因为乘了很多的小于 1 的数而越来越小,最终就会变为 0,从而导致层数比较浅的权重没有更新,这就是梯度消失
- 梯度爆炸的原因也类似,网络层之间的梯度(值大于 1.0)重复相乘导致的指数级增长会产生梯度爆炸。在极端情况下,权重的值变得非常大,以至于溢出,导致 NaN 值
如何确定是否出现梯度爆炸?
- 模型无法从训练数据中获得更新(如低损失)
- 模型不稳定,导致更新过程中的损失出现显著变化
- 训练过程中,模型损失变成 NaN
- …
解决方案
- 减少网络的层数
- 减小学习率
- 使用 ReLU 激活函数:ReLU 函数的导数在正数部分是恒等于 1 的,因此在深层网络中使用 ReLU 激活函数就不会导致梯度消失和爆炸的问题
- 使用梯度截断 (Gradient Clipping): 主要针对梯度爆炸,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。虽然这个方法很简单,但是在许多情况下效果都不错
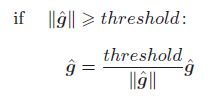 其中, g ^ \hat g g^ 整合了神经网络中用到的所有参数的梯度。比如,当某个模型有 W 1 W_1 W1 和 W 2 W_2 W2 两个参数时, g ^ \hat g g^ 就是这两个参数对应的梯度 d W 1 dW_1 dW1 和 d W 2 dW_2 dW2 的组合
其中, g ^ \hat g g^ 整合了神经网络中用到的所有参数的梯度。比如,当某个模型有 W 1 W_1 W1 和 W 2 W_2 W2 两个参数时, g ^ \hat g g^ 就是这两个参数对应的梯度 d W 1 dW_1 dW1 和 d W 2 dW_2 dW2 的组合
def clip_grads(grads, max_norm):
# grads 为一个记录了所有参数梯度的列表
total_norm = 0
for grad in grads:
total_norm += np.sum(grad ** 2)
total_norm = np.sqrt(total_norm)
rate = max_norm / (total_norm + 1e-6)
if rate < 1:
for grad in grads:
grad *= rate
- 权重正则化 (Weight Regularization): 检查网络权重的大小,并惩罚产生较大权重值的损失函数; 如果发生梯度爆炸,权值的范数就会变的非常大,通过正则化项,可以部分限制梯度爆炸的发生。通常使用的是 L1 惩罚项(权重绝对值)或 L2 惩罚项(权重平方)
- 批量归一化 Batch Normalization: 解决梯度消失和爆炸的问题
- 残差结构 ResNet: 缓解梯度消失
- 权重初始化: Xavier 初始化和 He 初始化
权重的初始值
权重初始值可以设为 0 吗? (随机生成初始值的重要性)
- 在神经网络的学习中,权重的初始值特别重要。实际上,设定什么样的权重初始值,经常关系到神经网络的学习能否成功
- 权值衰减(weight decay)可以抑制过拟合。如果想减小权重的值,一开始就将初始值设为较小的值才是正途。实际上,在这之前的权重初始值都是像
0.01 * np.random.randn(10, 100)这样,使用标准差为0.01的高斯分布 - 然而,如果将权重初始值设为 0 的话,将无法正确进行学习,或者说,将权重初始值设成一样的值,也无法正确进行学习。这是因为在误差反向传播法中,所有的权重值都会进行相同的更新。比如,在 2 层神经网络中,假设第 1 层和第 2 层的权重为 0。这样一来,正向传播时,因为输入层的权重为 0,所以第 2 层的神经元全部会被传递相同的值。第 2 层的神经元中全部输入相同的值,这意味着反向传播时第 2 层的权重全部都会进行相同的更新。因此,权重被更新为相同的值,并拥有了对称的值(重复的值)。这使得神经网络拥有许多不同的权重的意义丧失了
- 权值衰减(weight decay)可以抑制过拟合。如果想减小权重的值,一开始就将初始值设为较小的值才是正途。实际上,在这之前的权重初始值都是像
- 因此,为了防止 “权重均一化”(严格地讲,是为了瓦解权重的对称结构),必须随机生成初始值
观察权重初始值对隐藏层激活值分布的影响
- 下面做一个实验,向一个 5 层神经网络(激活函数使用
sigmoid函数)传入随机生成的输入数据,用直方图绘制各层激活值的数据分布
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(x, 0)
def tanh(x):
return np.tanh(x)
# settings
activator = sigmoid # 选择激活函数
std = 1 # 权重初始化的标准差 改变该值来观察权重初始值对隐藏层激活值分布的影响
input_data = np.random.randn(1000, 100) # 1000 个数据
node_num = 100 # 各隐藏层的节点(神经元)数
hidden_layer_size = 5 # 隐藏层有5层
activations = {} # 激活值的结果保存在这里
x = input_data
for i in range(hidden_layer_size):
if i != 0:
x = activations[i - 1]
w = np.random.randn(node_num, node_num) * std
y = np.dot(x, w)
z = activator(y)
activations[i] = z
# 绘制直方图
fig, axes = plt.subplots(1, len(activations))
for i, z in activations.items():
axes[i].set_title('layer ' + str(i))
if i != 0:
axes[i].set_yticks([], [])
axes[i].hist(z.flatten(), 30, range=(0, 1))
plt.show()
Internal covariate shift: the change in the distribution of network activations due to the change in network parameters during training
- 使用标准差为 1 的高斯分布作为权重初始值时的各层激活值的分布:
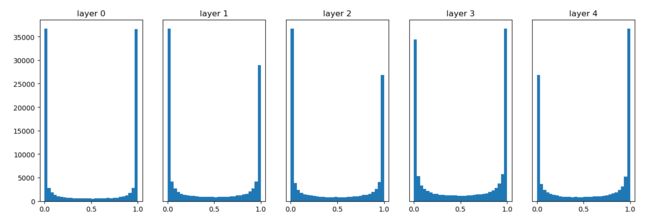 从上图可知,各层的激活值呈偏向 0 和 1 的分布。这里使用的
从上图可知,各层的激活值呈偏向 0 和 1 的分布。这里使用的 sigmoid函数是 S 型函数,随着输出不断地靠近 0(或者靠近 1),它的导数的值逐渐接近 0。因此,偏向 0 和 1 的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失 (gradient vanishing)。层次加深的深度学习中,梯度消失的问题可能会更加严重 - 使用标准差为 0.01 的高斯分布作为权重初始值时的各层激活值的分布:
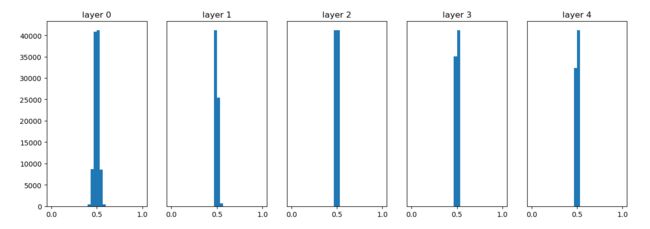 这次呈集中在 0.5 附近的分布。因为不像刚才的例子那样偏向 0 和 1,所以不会发生梯度消失的问题。但是,激活值的分布有所偏向,说明在表现力上会有很大问题。为什么这么说呢?因为如果有多个神经元都输出几乎相同的值,那它们就没有存在的意义了。比如,如果 100 个神经元都输出几乎相同的值,那么也可以由 1 个神经元来表达基本相同的事情。因此,激活值在分布上有所偏向会出现“表现力受限”的问题
这次呈集中在 0.5 附近的分布。因为不像刚才的例子那样偏向 0 和 1,所以不会发生梯度消失的问题。但是,激活值的分布有所偏向,说明在表现力上会有很大问题。为什么这么说呢?因为如果有多个神经元都输出几乎相同的值,那它们就没有存在的意义了。比如,如果 100 个神经元都输出几乎相同的值,那么也可以由 1 个神经元来表达基本相同的事情。因此,激活值在分布上有所偏向会出现“表现力受限”的问题 - 由上述实验可以看出,各层的激活值的分布都要求有适当的广度。如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行
Xavier 初始值
['zʌvɪə]
- Xavier 的论文中,为了使各层的激活值呈现出具有相同广度的分布,推导了合适的权重尺度。推导出的结论是:如果前一层的节点数为 n n n,则初始值使用标准差为 1 n \frac {1}{\sqrt n} n1 的分布;当上层和本层均为卷积层时, n = C i n × F W × F H n=C_{in}\times FW \times FH n=Cin×FW×FH,其中 C i n C_{in} Cin 为输入通道数, F W FW FW、 F H FH FH 为本层滤波器的尺寸

- 使用 Xavier 初始值后,前一层的节点数越多,要设定为目标节点的初始值的权重尺度就越小
- 使用 Xavier 初始值作为权重初始值时的各层激活值的分布:
 可以看出,越是后面的层,图像变得越歪斜,但是呈现了比之前更有广度的分布。因为各层间传递的数据有适当的广度,所以
可以看出,越是后面的层,图像变得越歪斜,但是呈现了比之前更有广度的分布。因为各层间传递的数据有适当的广度,所以 sigmoid函数的表现力不受限制,有望进行高效的学习 - 如果用
tanh函数代替sigmoid函数,这个稍微歪斜的问题就能得到改善。实际上,使用tanh函数后,会呈漂亮的吊钟型分布。tanh函数和sigmoid函数同是 S 型曲线函数,但tanh函数是关于原点 ( 0 , 0 ) (0, 0) (0,0) 对称的 S 型曲线,而sigmoid函数是关于 ( x , y ) = ( 0 , 0.5 ) (x, y)=(0, 0.5) (x,y)=(0,0.5) 对称的 S 型曲线。众所周知,用作激活函数的函数最好具有关于原点对称的性质- 这里有点疑问:为什么用作激活函数的函数最好具有关于原点对称的性质?例如 ReLU 就不是原点对称的;同时在运行了代码之后激活值分布如下图所示,好像不是漂亮吊钟型?

- 这里有点疑问:为什么用作激活函数的函数最好具有关于原点对称的性质?例如 ReLU 就不是原点对称的;同时在运行了代码之后激活值分布如下图所示,好像不是漂亮吊钟型?
He 初始值
- paper: He, Kaiming, et al. “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification.” Proceedings of the IEEE international conference on computer vision. 2015.
- Xavier 初始值是以激活函数是线性函数为前提而推导出来的。因为
sigmoid函数和tanh函数左右对称,且中央附近可以视作线性函数,所以适合使用 Xavier 初始值 - 但当激活函数使用
ReLU时,一般推荐使用ReLU专用的初始值,即 “He 初始值”:- 当前一层的节点数为 n n n 时,He 初始值使用标准差为 2 n \sqrt {\frac {2}{n}} n2 的高斯分布
- (直观上) 可以解释为,因为 ReLU 的负值区域的值为 0,为了使它更有广度,所以需要 2 倍的系数
- 下面将激活函数改为
Relu,并改变权重初始值的标准差,比较隐藏层激活值的分布:- 权重初始值为标准差是 0.01 的高斯分布时,各层的激活值非常小。神经网络上传递的是非常小的值,说明逆向传播时权重的梯度也同样很小。这是很严重的问题,实际上学习基本上没有进展:

- 权重初始值为 Xavier 初始值时,层加深后,激活值的偏向变大,学习时会出现梯度消失的问题

- 权重初始值为 He 初始值时,各层中分布的广度相同。由于即便层加深,数据的广度也能保持不变,因此逆向传播时,也会传递合适的值

- 权重初始值为标准差是 0.01 的高斯分布时,各层的激活值非常小。神经网络上传递的是非常小的值,说明逆向传播时权重的梯度也同样很小。这是很严重的问题,实际上学习基本上没有进展:
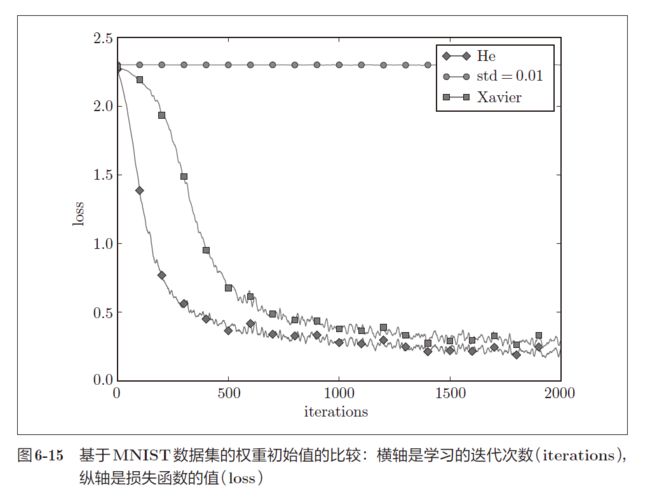
- 在 Mnist 数据集上观察不同的权重初始值的赋值方法会在多大程度上影响神经网络的学习,实验中,神经网络有 5 层,每层有 100 个神经元,激活函数使用的是
ReLU。从下图的结果可知:std = 0.01时完全无法进行学习。这和刚才观察到的激活值的分布一样,是因为正向传播中传递的值很小(集中在 0 附近的数据)。因此,逆向传播时求到的梯度也很小,权重几乎不进行更新- 相反,当权重初始值为 Xavier 初始值和 He 初始值时,学习进行得很顺利。并且,我们发现 He 初始值时的学习进度更快一些
归一化输入 (Normalizing inputs)
归一化过程:
μ ← 1 m ∑ i = 1 m x i \mu \leftarrow \frac {1}{m}\sum_{i=1}^m x_i μ←m1i=1∑mxi σ 2 ← 1 m ∑ i = 1 m ( x i − μ ) 2 \sigma^2 \leftarrow \frac {1}{m}\sum_{i=1}^m {(x_i - \mu)^2} σ2←m1i=1∑m(xi−μ)2 x i ← x i − μ σ 2 + ϵ x_i \leftarrow \frac {x_i - \mu}{\sqrt {\sigma^2 + \epsilon}} xi←σ2+ϵxi−μ
- 如果归一化了训练数据,那么就需要保存参数 μ \mu μ 和 σ \sigma σ,之后用保存的训练集上的 μ \mu μ 和 σ \sigma σ 来归一化测试集,而非分别在训练集和测试集上计算 μ \mu μ 和 σ \sigma σ。这样可以让测试集和训练集都经过相同的 μ \mu μ 和 σ \sigma σ 定义的数据转换
归一化图示:
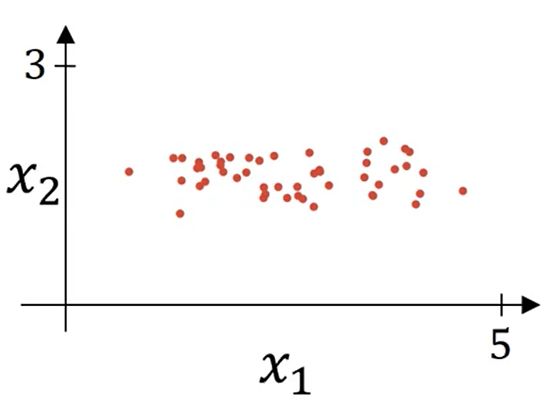


Why normalize inputs?
- 当输入都在相近范围内时,损失函数优化起来更简单更快速,从而加速网络学习
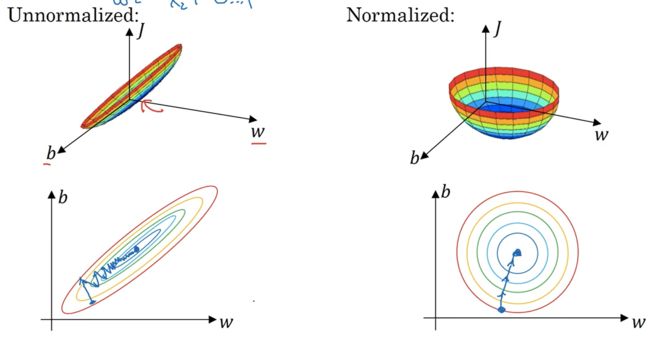
Batch Normalization
- paper: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- 如果设定了合适的权重初始值,则各层的激活值分布会有适当的广度,从而可以顺利地进行学习。那么,为了使各层拥有适当的广度,“强制性”地调整激活值的分布会怎样呢?实际上,Batch Normalization 方法就是基于这个想法而产生的
Batch Norm 的优点:
- 可以使学习快速进行(可以增大学习率)(main purpose)
- 不那么依赖初始值(对于初始值不用那么神经质)(main purpose): 缓解梯度消失或梯度爆炸
- 实际上,在不使用 Batch Norm 的情况下,如果不赋予一个尺度好的初始值,学习将完全无法进行
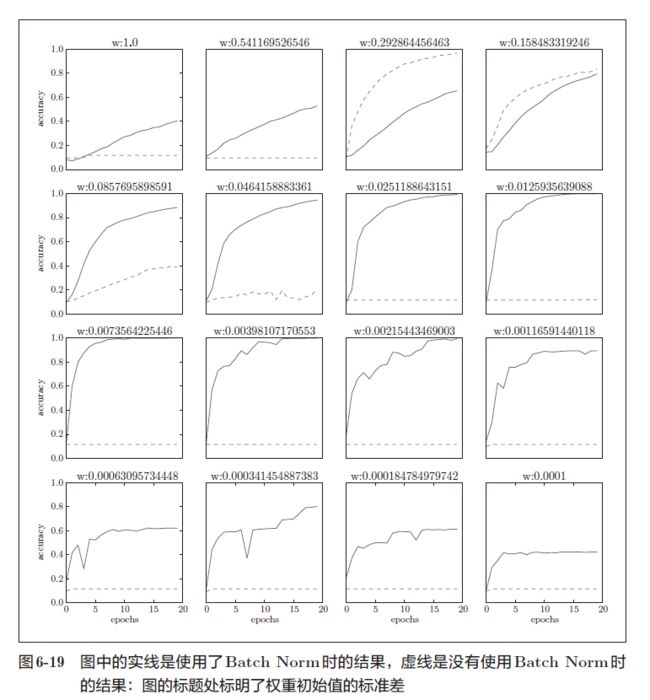
- 实际上,在不使用 Batch Norm 的情况下,如果不赋予一个尺度好的初始值,学习将完全无法进行
- 抑制过拟合(降低 Dropout 等的必要性)(a slight regularization effect): 作归一化时,均值和方差都是由训练集得到的,并不是真实的均值和方差,因此存在一定的噪声
直观地理解 Batch Norm 的优点:
- BN 层强制性地调整各层的激活值分布使其拥有适当的广度,使激活值落在非饱和区从而缓解梯度消失问题,加速网络收敛,同时也避免了表现力不足的问题
- 通过 BN 层可使后面的层对前面层的输出不那么敏感 (没有 BN 层的话,当前面层参数改变时,输出值范围变化,导致后面层的参数也不得不调整),抑制了参数微小变化随网络加深而被放大的问题,减小耦合,使每一层都能独立学习,提升学习速率 (reduce the internal covariate shift,内部协方差偏移是指在深度神经网络的学习过程中,各个层的参数会发生变化,各个层的输出也会随之发生变化。对于其中任意一层,其输入也会不断改变,其结果是这一层及其后面层的学习会产生振荡,学习速度会变缓)
- 如上节所述,归一化所有输入特征可以加速网络学习 (enables higher learning rates)
- μ \mu μ 和 σ \sigma σ 只是由一个 mini-batch 计算得到的,而非是整个数据集上的 μ \mu μ 和 σ \sigma σ,因此相当于加入了一些噪声 (add some noise to each hidden layer’s activations),因此有轻微的正则化效果 (regularization effect) (如果用更大的 mini-batch 就会减小噪声,进而减弱正则化效果)
Batch Norm 的缺点:
- 因为是在 batch 维度归一化,BN 层要有较大的 batch 才能有效工作,而例如物体检测等任务由于占用内存较多,限制了 batch 的大小,进而也限制了 BN 层的归一化功能
- 测试时直接拿训练集的均值与方差对测试集进行归一化,可能会使测试集依赖于训练集
BN 层的正向传播
- Batch Norm 步骤 1:按 mini-batch 进行归一化
μ B ← 1 m ∑ i = 1 m x i \mu_B \leftarrow \frac {1}{m}\sum_{i=1}^m x_i μB←m1i=1∑mxi σ B 2 ← 1 m ∑ i = 1 m ( x i − μ B ) 2 \sigma_B^2 \leftarrow \frac {1}{m}\sum_{i=1}^m {(x_i - \mu_B)^2} σB2←m1i=1∑m(xi−μB)2 x i ← x i − μ B σ B 2 + ϵ x_i \leftarrow \frac {x_i - \mu_B}{\sqrt {\sigma_B^2 + \epsilon}} xi←σB2+ϵxi−μB训练时,用指数加权平均来记录 μ \mu μ 和 σ \sigma σ,从而在推理时用指数加权平均后的 μ \mu μ 和 σ \sigma σ 对测试数据进行归一化- 但是,如果只进行这样的归一化会产生一个问题:这样归一化使 BN 层的下一层网络的输入值方差为 1,但是通过前面权重初始值的实验可以看出,方差为 1 不一定会使激活值具有广度,因此还需要进行下面的步骤对归一化后的数据进行缩放及平移
- Batch Norm 步骤 2:为了保证后面的层还能接受到前面层学习到的特征,需要对归一化后的数据进行缩放和平移来改变正规化后数据的均值与方差
y = γ x + β y = \gamma x + \beta y=γx+β可以看出,当 γ = σ B 2 + ϵ , β = μ B \gamma = \sqrt{\sigma_B^2 + \epsilon}, \beta = \mu_B γ=σB2+ϵ,β=μB 时,该式就变成了归一化的逆变换,这样也允许网络通过学习,将 BN 层变为恒等变换来保持原来网络的能力 (This is what makes BN really powerful)- 一开始设置 γ = 1 , β = 0 \gamma = 1, \beta = 0 γ=1,β=0,然后再通过学习调整到合适的值
- 注意到 BN 层前面 Affine 层的偏置 b b b 实际上可以被忽略 (它会在正则化时被减去),它的偏置作用被步骤 2 中的 β \beta β 所替代
BN 层被用在卷积层之后
- 书上的实现方式: 为了使同一张特征图上的各个元素都能被以相同的方式归一化,需要进行如下操作,对所有样本中同一个通道同一个位置的 N N N 个元素为一组进行归一化:
N, C, H, W = x.shape
x = x.reshape(N, -1)
- Pytorch : 相同样本的相同位置的不同通道上的 C C C 个元素为一组进行归一化,即以通道为单位进行归一化:
N, C, H, W = x.shape
x = x.transpose(1, 0, 2, 3).reshape(C, -1)
之后给出的代码还是基于书上的实现方式
- 通过将 BN 层插入到激活函数前面或者后面,可以减小数据分布的偏向
- 原论文中将 BN 层放在了激活函数之前:We add the BN transform immediately before the nonlinearity such as sigmoid or ReLU.
- 但是我也看到有说 BN 层放在激活函数之后效果更好的
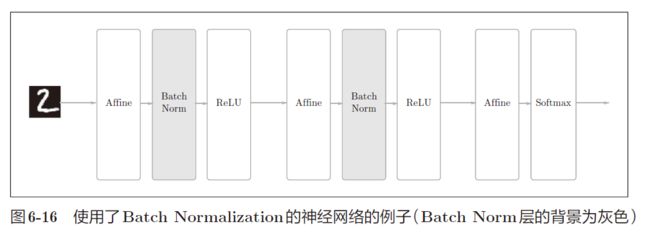
事实上,根据每一组归一化选取元素标准的不同,BN 又衍生出了其他的算法:
- LN (Layer Normalization):以同一个样本上的所有 C × H × W C \times H \times W C×H×W 个元素为一组进行归一化,这样计算的均值与方差与 batch size 无关
S i = { k ∣ k N = i N } S_i = \{k | k_N = i_N\} Si={k∣kN=iN} - IN (Instance Normalization):以同一个样本且同一个通道上的所有 H × W H \times W H×W 个元素为一组进行归一化,这样计算的均值与方差与 batch size 无关
S i = { k ∣ k N = i N , k C = i C } S_i = \{k | k_N = i_N, k_C = i_C\} Si={k∣kN=iN,kC=iC} - GN (Group Normalization):之后介绍
BN 层的反向传播
基于计算图进行推导
本节参考:
Understanding the backward pass through Batch Normalization Layer
- 计算图:
 标注好正向传播对应的步骤,之后按照相反的顺序进行反向传播:
标注好正向传播对应的步骤,之后按照相反的顺序进行反向传播:
 ∂ L ∂ β = ∑ i = 1 N ∂ L ∂ y i ,即 ∂ L ∂ y 在第 0 轴上的累加值 \frac {\partial L}{\partial \beta} = \sum_{i=1}^N \frac {\partial L}{\partial y_i},即\frac {\partial L}{\partial y}在第0轴上的累加值 ∂β∂L=i=1∑N∂yi∂L,即∂y∂L在第0轴上的累加值 ∂ L ∂ γ x ^ = ∂ L ∂ y \frac {\partial L}{\partial \gamma \hat {x}} = \frac {\partial L}{\partial y} ∂γx^∂L=∂y∂L注:设 o u t = y out = y out=y ∂ L ∂ β i = ∑ k = 1 N ( ∂ L ∂ y k i ∂ y k i ∂ β i ) = ∑ k = 1 N ( ∂ L ∂ y k i ∂ ( γ x k i ^ + β i ) ∂ β i ) = ∑ k = 1 N ∂ L ∂ y k i ∂ L ∂ β = ∑ i = 1 N ∂ L ∂ y i \begin{aligned} \frac {\partial L}{\partial \beta_i} &= \sum_{k=1}^N {(\frac {\partial L}{\partial y_{ki}} \frac {\partial y_{ki}}{\partial \beta_i})} \\&= \sum_{k=1}^N {(\frac {\partial L}{\partial y_{ki}} \frac {\partial {(\gamma \hat {x_{ki}} + \beta_i)}}{\partial \beta_i})} \\&= \sum_{k=1}^N {\frac {\partial L}{\partial y_{ki}}} \\\frac {\partial L}{\partial \beta} &= \sum_{i=1}^N \frac {\partial L}{\partial y_i} \end{aligned} ∂βi∂L∂β∂L=k=1∑N(∂yki∂L∂βi∂yki)=k=1∑N(∂yki∂L∂βi∂(γxki^+βi))=k=1∑N∂yki∂L=i=1∑N∂yi∂L
∂ L ∂ β = ∑ i = 1 N ∂ L ∂ y i ,即 ∂ L ∂ y 在第 0 轴上的累加值 \frac {\partial L}{\partial \beta} = \sum_{i=1}^N \frac {\partial L}{\partial y_i},即\frac {\partial L}{\partial y}在第0轴上的累加值 ∂β∂L=i=1∑N∂yi∂L,即∂y∂L在第0轴上的累加值 ∂ L ∂ γ x ^ = ∂ L ∂ y \frac {\partial L}{\partial \gamma \hat {x}} = \frac {\partial L}{\partial y} ∂γx^∂L=∂y∂L注:设 o u t = y out = y out=y ∂ L ∂ β i = ∑ k = 1 N ( ∂ L ∂ y k i ∂ y k i ∂ β i ) = ∑ k = 1 N ( ∂ L ∂ y k i ∂ ( γ x k i ^ + β i ) ∂ β i ) = ∑ k = 1 N ∂ L ∂ y k i ∂ L ∂ β = ∑ i = 1 N ∂ L ∂ y i \begin{aligned} \frac {\partial L}{\partial \beta_i} &= \sum_{k=1}^N {(\frac {\partial L}{\partial y_{ki}} \frac {\partial y_{ki}}{\partial \beta_i})} \\&= \sum_{k=1}^N {(\frac {\partial L}{\partial y_{ki}} \frac {\partial {(\gamma \hat {x_{ki}} + \beta_i)}}{\partial \beta_i})} \\&= \sum_{k=1}^N {\frac {\partial L}{\partial y_{ki}}} \\\frac {\partial L}{\partial \beta} &= \sum_{i=1}^N \frac {\partial L}{\partial y_i} \end{aligned} ∂βi∂L∂β∂L=k=1∑N(∂yki∂L∂βi∂yki)=k=1∑N(∂yki∂L∂βi∂(γxki^+βi))=k=1∑N∂yki∂L=i=1∑N∂yi∂L
 ∂ L ∂ γ = ∑ i = 1 N ∂ L ∂ γ x i ^ ∗ x i ^ = ∑ i = 1 N ∂ L ∂ y i ∗ x i ^ ,即 ∂ L ∂ y ∗ x i ^ 在第 0 轴上的累加值 \frac {\partial L}{\partial \gamma} = \sum_{i=1}^N \frac {\partial L}{\partial \gamma \hat {x_i}} * \hat {x_i} = \sum_{i=1}^N \frac {\partial L}{\partial y_i} * \hat {x_i},即\frac {\partial L}{\partial y} * \hat {x_i} 在第0轴上的累加值 ∂γ∂L=i=1∑N∂γxi^∂L∗xi^=i=1∑N∂yi∂L∗xi^,即∂y∂L∗xi^在第0轴上的累加值 ∂ L ∂ x ^ = ∂ L ∂ γ x i ^ ∗ γ = ∂ L ∂ y ∗ γ \frac {\partial L}{\partial \hat {x}} = \frac {\partial L}{\partial \gamma \hat {x_i}} * \gamma = \frac {\partial L}{\partial y} * \gamma ∂x^∂L=∂γxi^∂L∗γ=∂y∂L∗γ
∂ L ∂ γ = ∑ i = 1 N ∂ L ∂ γ x i ^ ∗ x i ^ = ∑ i = 1 N ∂ L ∂ y i ∗ x i ^ ,即 ∂ L ∂ y ∗ x i ^ 在第 0 轴上的累加值 \frac {\partial L}{\partial \gamma} = \sum_{i=1}^N \frac {\partial L}{\partial \gamma \hat {x_i}} * \hat {x_i} = \sum_{i=1}^N \frac {\partial L}{\partial y_i} * \hat {x_i},即\frac {\partial L}{\partial y} * \hat {x_i} 在第0轴上的累加值 ∂γ∂L=i=1∑N∂γxi^∂L∗xi^=i=1∑N∂yi∂L∗xi^,即∂y∂L∗xi^在第0轴上的累加值 ∂ L ∂ x ^ = ∂ L ∂ γ x i ^ ∗ γ = ∂ L ∂ y ∗ γ \frac {\partial L}{\partial \hat {x}} = \frac {\partial L}{\partial \gamma \hat {x_i}} * \gamma = \frac {\partial L}{\partial y} * \gamma ∂x^∂L=∂γxi^∂L∗γ=∂y∂L∗γ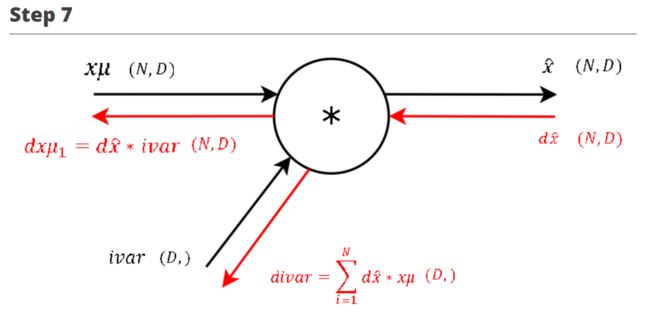 ∂ L ∂ i v a r = ∑ i = 1 N ∂ L ∂ x i ^ ∗ x μ = ∑ i = 1 N ∂ L ∂ y ∗ γ ∗ x μ ,即 ∂ L ∂ y ∗ γ ∗ x μ 在第 0 轴上的累加值 \frac {\partial L}{\partial ivar} = \sum_{i=1}^N \frac {\partial L}{\partial \hat {x_i}} * x\mu = \sum_{i=1}^N \frac {\partial L}{\partial y} * \gamma * x\mu,即 \frac {\partial L}{\partial y} * \gamma * x\mu在第0轴上的累加值 ∂ivar∂L=i=1∑N∂xi^∂L∗xμ=i=1∑N∂y∂L∗γ∗xμ,即∂y∂L∗γ∗xμ在第0轴上的累加值 ∂ L ∂ x μ 1 = ∂ L ∂ x ^ ∗ i v a r = ∂ L ∂ y ∗ γ ∗ i v a r \frac {\partial L}{\partial x\mu_1} = \frac {\partial L}{\partial \hat {x}} * ivar = \frac {\partial L}{\partial y} * \gamma * ivar ∂xμ1∂L=∂x^∂L∗ivar=∂y∂L∗γ∗ivar
∂ L ∂ i v a r = ∑ i = 1 N ∂ L ∂ x i ^ ∗ x μ = ∑ i = 1 N ∂ L ∂ y ∗ γ ∗ x μ ,即 ∂ L ∂ y ∗ γ ∗ x μ 在第 0 轴上的累加值 \frac {\partial L}{\partial ivar} = \sum_{i=1}^N \frac {\partial L}{\partial \hat {x_i}} * x\mu = \sum_{i=1}^N \frac {\partial L}{\partial y} * \gamma * x\mu,即 \frac {\partial L}{\partial y} * \gamma * x\mu在第0轴上的累加值 ∂ivar∂L=i=1∑N∂xi^∂L∗xμ=i=1∑N∂y∂L∗γ∗xμ,即∂y∂L∗γ∗xμ在第0轴上的累加值 ∂ L ∂ x μ 1 = ∂ L ∂ x ^ ∗ i v a r = ∂ L ∂ y ∗ γ ∗ i v a r \frac {\partial L}{\partial x\mu_1} = \frac {\partial L}{\partial \hat {x}} * ivar = \frac {\partial L}{\partial y} * \gamma * ivar ∂xμ1∂L=∂x^∂L∗ivar=∂y∂L∗γ∗ivar
注:
- x μ x\mu xμ 为 x − μ x - \mu x−μ, i v a r ivar ivar 为 1 σ 2 + ϵ \frac {1}{\sqrt {\sigma^2 + \epsilon}} σ2+ϵ1
- step 7 的反向传播过程与上一步一模一样
- 之前的博客里有说过,根据链式法则,计算图中,正向传播分叉出去的路径,在反向传播会合时需要把梯度相加,因此这里计算的是 ∂ L ∂ x μ \frac {\partial L}{\partial x\mu} ∂xμ∂L 的一部分 ∂ L ∂ x μ 1 \frac {\partial L}{\partial x\mu_1} ∂xμ1∂L
This step during the forward pass was the final step of the normalization combining the two branches (nominator and denominator) of the computational graph. During the backward pass we will calculate the gradients that will flow separately through these two branches backwards.
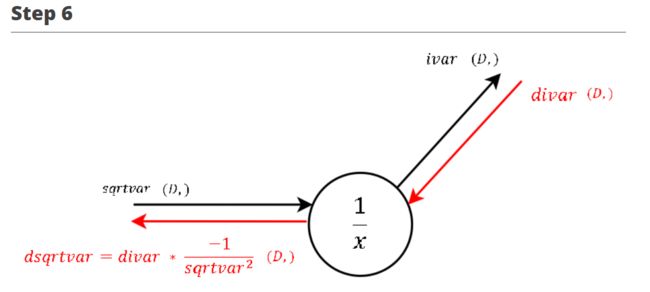
∂ L ∂ s q r t v a r = − 1 s q r t v a r 2 ∗ ∂ L ∂ i v a r \frac {\partial L}{\partial sqrtvar} = \frac {-1}{sqrtvar^2} * \frac {\partial L}{\partial ivar} ∂sqrtvar∂L=sqrtvar2−1∗∂ivar∂L
注:
- s q r t v a r sqrtvar sqrtvar 为 σ 2 + ϵ \sqrt {\sigma^2 + \epsilon} σ2+ϵ
- 因为反向传播得到的梯度表达式越来越复杂,从这里开始就不再把式子全部展开了
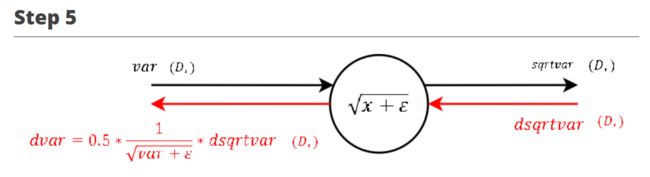
∂ L ∂ v a r = 0.5 ∗ 1 v a r + ϵ ∗ ∂ L ∂ s q r t v a r \frac {\partial L}{\partial var} = 0.5 * \frac {1}{\sqrt {var + \epsilon}} * \frac {\partial L}{\partial sqrtvar} ∂var∂L=0.5∗var+ϵ1∗∂sqrtvar∂L

∂ L ∂ s q = 1 N ∗ o n e s ( N , D ) ∗ ∂ L ∂ v a r \frac {\partial L}{\partial sq} = \frac {1} {N} * ones(N, D) * \frac {\partial L}{\partial var} ∂sq∂L=N1∗ones(N,D)∗∂var∂L
注:
- s q sq sq 为 ( x − μ ) 2 (x-\mu)^2 (x−μ)2
∂ L ∂ s q i , j = ∂ L ∂ v a r j ∂ v a r j ∂ s q i , j = ∂ L ∂ v a r j ∂ 1 N ∑ k = 1 N s q k , j ∂ s q i , j = 1 N ∂ L ∂ v a r j \begin{aligned} \frac {\partial L}{\partial sq_{i,j}} &= \frac {\partial L}{\partial var_j} \frac {\partial var_j}{\partial sq_{i,j}} \\&= \frac {\partial L}{\partial var_j} \frac {\partial \frac {1} {N}\sum^N_{k=1} sq_{k,j}}{\partial sq_{i,j}} \\&= \frac {1} {N} \frac {\partial L}{\partial var_j} \end{aligned} ∂sqi,j∂L=∂varj∂L∂sqi,j∂varj=∂varj∂L∂sqi,j∂N1∑k=1Nsqk,j=N1∂varj∂L - o n e s ( N , D ) ones(N, D) ones(N,D)为 N × D N \times D N×D 维的全一矩阵

∂ L ∂ x μ 2 = 2 ∗ x μ ∗ ∂ L ∂ s q \frac {\partial L}{\partial x\mu_2} = 2 * x\mu * \frac {\partial L}{\partial sq} ∂xμ2∂L=2∗xμ∗∂sq∂L
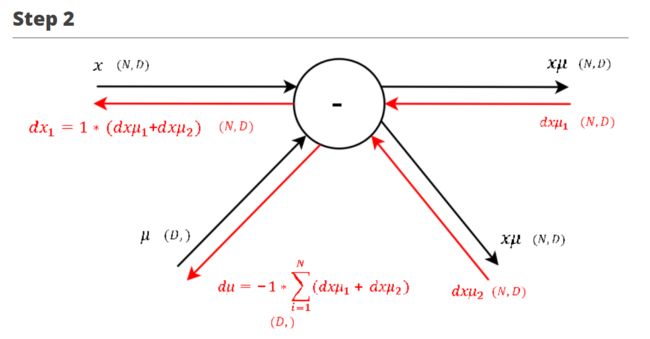
∂ L ∂ x μ = ∂ L ∂ x μ 1 + ∂ L ∂ x μ 2 \frac {\partial L}{\partial x\mu} = \frac {\partial L}{\partial x\mu_1} + \frac {\partial L}{\partial x\mu_2} ∂xμ∂L=∂xμ1∂L+∂xμ2∂L ∂ L ∂ x 1 = ∂ L ∂ x μ \frac {\partial L}{\partial x_1} = \frac {\partial L}{\partial x\mu} ∂x1∂L=∂xμ∂L ∂ L ∂ μ = − 1 ∗ ∑ i = 1 N ∂ L ∂ x μ i \frac {\partial L}{\partial \mu} = -1 * \sum_{i=1}^N \frac {\partial L}{\partial x\mu_i} ∂μ∂L=−1∗i=1∑N∂xμi∂L
注:
- 这里进行之前说的路径汇合梯度相加的操作,同时也要注意这里计算的是 ∂ L ∂ x \frac {\partial L}{\partial x} ∂x∂L 的一部分 ∂ L ∂ x 1 \frac {\partial L}{\partial x_1} ∂x1∂L
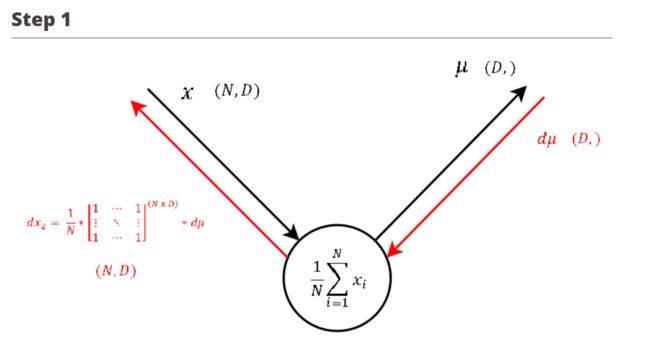
∂ L ∂ x 2 = 1 N ∗ o n e s ( N , D ) ∗ ∂ L ∂ μ \frac {\partial L}{\partial x_2} = \frac {1} {N} * ones(N, D) * \frac {\partial L}{\partial \mu} ∂x2∂L=N1∗ones(N,D)∗∂μ∂L

∂ L ∂ x = ∂ L ∂ x 1 + ∂ L ∂ x 2 \frac {\partial L}{\partial x} = \frac {\partial L}{\partial x_1} + \frac {\partial L}{\partial x_2} ∂x∂L=∂x1∂L+∂x2∂L
不借助计算图,直接推导
本节参考:
What does the gradient flowing through batch normalization looks like?
- 为了推理上方便书写,先引入克罗内克符号:
δ i , j = 1 i f i = j \delta_{i,j} = 1 \ \ \ \ \ \ \ \ \ \ \ \ \ if \ i = j δi,j=1 if i=j δ i , j = 0 i f i ≠ j \delta_{i,j} = 0 \ \ \ \ \ \ \ \ \ \ \ \ \ if \ i \neq j δi,j=0 if i=j下面正式进行推导:
∂ L ∂ x i , j = ∑ k , l ∂ L ∂ y k , l ∂ y k , l ∂ x i , j = ∑ k , l ∂ L ∂ y k , l ∂ y k , l ∂ x ^ k , l ∂ x ^ k , l ∂ x i , j = ∑ k , l ∂ L ∂ y k , l γ l ∂ x ^ k , l ∂ x i , j ( 1 ) \begin{aligned} \frac {\partial L}{\partial x_{i,j}} &= \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \frac {\partial y_{k,l}}{\partial x_{i,j}} \\&= \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \frac {\partial y_{k,l}}{\partial \hat x_{k,l}} \frac {\partial \hat x_{k,l}}{\partial x_{i,j}} \\&= \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \gamma_l \frac {\partial \hat x_{k,l}}{\partial x_{i,j}} \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1) \end{aligned} ∂xi,j∂L=k,l∑∂yk,l∂L∂xi,j∂yk,l=k,l∑∂yk,l∂L∂x^k,l∂yk,l∂xi,j∂x^k,l=k,l∑∂yk,l∂Lγl∂xi,j∂x^k,l (1) ∵ x ^ k , l = x k , l − μ l σ l 2 + ϵ \begin{aligned} \because \hat x_{k,l} = \frac{x_{k,l} - \mu_l}{\sqrt {\sigma_l^2 + \epsilon}} \end{aligned} ∵x^k,l=σl2+ϵxk,l−μl ∴ ∂ x ^ k , l ∂ x i , j = ( x k , l − μ l ) ⋅ − 1 2 ⋅ ( σ l 2 + ϵ ) − 3 2 ∂ σ l 2 ∂ x i , j + ( σ l 2 + ϵ ) − 1 2 ( δ i , k δ j , l − 1 N δ j , l ) \begin{aligned} \therefore \frac {\partial \hat x_{k,l}}{\partial x_{i,j}} = (x_{k,l} - \mu_l) \cdot -\frac{1}{2} \cdot (\sigma_l^2 + \epsilon)^{-\frac{3}{2}} \frac {\partial \sigma_l^2}{\partial x_{i,j}} + (\sigma_l^2 + \epsilon)^{-\frac{1}{2}}(\delta_{i,k} \delta_{j,l } - \frac{1}{N} \delta_{j,l}) \end{aligned} ∴∂xi,j∂x^k,l=(xk,l−μl)⋅−21⋅(σl2+ϵ)−23∂xi,j∂σl2+(σl2+ϵ)−21(δi,kδj,l−N1δj,l) ∵ σ l 2 = 1 N ∑ p = 1 N ( x p , l − μ l ) 2 \begin{aligned} \because \sigma_l^2 = \frac{1}{N}\sum_{p=1}^N(x_{p,l} - \mu_l)^2 \end{aligned} ∵σl2=N1p=1∑N(xp,l−μl)2 ∴ ∂ σ l 2 ∂ x i , j = 2 N ∑ p = 1 N ( x p , l − μ l ) ( δ i , p δ j , l − 1 N δ j , l ) = 2 N ( x i , l − μ l ) δ j , l − 2 N 2 δ j , l ∑ p = 1 N ( x p , l − μ l ) = 2 N ( x i , l − μ l ) δ j , l \begin{aligned} \therefore \frac {\partial \sigma_l^2}{\partial x_{i,j}} &= \frac {2}{N} \sum_{p=1}^N (x_{p,l} - \mu_l)(\delta_{i,p} \delta_{j,l} - \frac{1}{N}\delta_{j,l}) \\&= \frac{2}{N} (x_{i,l} - \mu_l) \delta_{j,l} - \frac{2}{N^2} \delta_{j,l} \sum_{p=1}^N (x_{p,l} - \mu_l) \\&= \frac{2}{N} (x_{i,l} - \mu_l) \delta_{j,l} \end{aligned} ∴∂xi,j∂σl2=N2p=1∑N(xp,l−μl)(δi,pδj,l−N1δj,l)=N2(xi,l−μl)δj,l−N22δj,lp=1∑N(xp,l−μl)=N2(xi,l−μl)δj,l ∴ ∂ x ^ k , l ∂ x i , j = − 1 N ( x k , l − μ l ) ( σ l 2 + ϵ ) − 3 2 ( x i , l − μ l ) δ j , l + ( σ l 2 + ϵ ) − 1 2 ( δ i , k δ j , l − 1 N δ j , l ) \begin{aligned} \therefore \frac {\partial \hat x_{k,l}}{\partial x_{i,j}} = -\frac{1}{N} (x_{k,l} - \mu_l) (\sigma_l^2 + \epsilon)^{-\frac{3}{2}} (x_{i,l} - \mu_l)\delta_{j,l} + (\sigma_l^2 + \epsilon)^{-\frac{1}{2}}(\delta_{i,k} \delta_{j,l } - \frac{1}{N} \delta_{j,l}) \end{aligned} ∴∂xi,j∂x^k,l=−N1(xk,l−μl)(σl2+ϵ)−23(xi,l−μl)δj,l+(σl2+ϵ)−21(δi,kδj,l−N1δj,l) ∴ 代入 ( 1 ) 式,得 ∂ L ∂ x i , j = ∑ k , l ∂ L ∂ y k , l γ l ( − 1 N ( x k , l − μ l ) ( σ l 2 + ϵ ) − 3 2 ( x i , l − μ l ) δ j , l + ( σ l 2 + ϵ ) − 1 2 ( δ i , k δ j , l − 1 N δ j , l ) ) = ∑ k , l ∂ L ∂ y k , l γ l ( σ l 2 + ϵ ) − 1 2 ( δ i , k δ j , l − 1 N δ j , l ) − ∑ k , l ∂ L ∂ y k , l γ l ( − 1 N ( x k , l − μ l ) ( σ l 2 + ϵ ) − 3 2 ( x i , l − μ l ) δ j , l ) = ∂ L ∂ y i , j γ j ( σ j 2 + ϵ ) − 1 2 − 1 N ∑ k = 1 N ∂ L ∂ y k , j γ j ( σ j 2 + ϵ ) − 1 2 − 1 N ∑ k = 1 N ∂ L ∂ y k , j γ j ( x i , j − μ j ) ( x k . j − μ j ) ( σ j 2 + ϵ ) − 3 2 = 1 N γ j ( σ j 2 + ϵ ) − 1 2 ( N ∂ L ∂ y i , j − ∑ k = 1 N ∂ L ∂ y k , j − ( x i , j − μ j ) ( σ j 2 + ϵ ) − 1 ∑ k = 1 N ∂ L ∂ y k , j ( x k , j − μ j ) ) = 1 N γ j ( σ j 2 + ϵ ) − 1 2 ( N ∂ L ∂ y i , j − ∑ k = 1 N ∂ L ∂ y k , j − ( x i , j − μ j ) ( σ j 2 + ϵ ) − 1 2 ∑ k = 1 N ∂ L ∂ y k , j ( x k , j − μ j ) ( σ j 2 + ϵ ) − 1 2 ) = 1 N γ j ( σ j 2 + ϵ ) − 1 2 ( N ∂ L ∂ y i , j − ∑ k = 1 N ∂ L ∂ y k , j − x ^ i , j ∑ k = 1 N ∂ L ∂ y k , j x ^ k , j ) \begin{aligned} \therefore 代入(1)式,得\\ \frac {\partial L}{\partial x_{i,j}} &= \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \gamma_l (-\frac{1}{N} (x_{k,l} - \mu_l) (\sigma_l^2 + \epsilon)^{-\frac{3}{2}} (x_{i,l} - \mu_l)\delta_{j,l} + (\sigma_l^2 + \epsilon)^{-\frac{1}{2}}(\delta_{i,k} \delta_{j,l } - \frac{1}{N} \delta_{j,l})) \\&= \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \gamma_l (\sigma_l^2 + \epsilon)^{-\frac{1}{2}}(\delta_{i,k} \delta_{j,l } - \frac{1}{N} \delta_{j,l}) - \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \gamma_l(-\frac{1}{N} (x_{k,l} - \mu_l) (\sigma_l^2 + \epsilon)^{-\frac{3}{2}} (x_{i,l} - \mu_l)\delta_{j,l}) \\&= \frac {\partial L}{\partial y_{i,j} } \gamma_j(\sigma_j^2 + \epsilon)^{-\frac{1}{2}} - \frac {1}{N} \sum_{k=1}^N \frac{\partial L}{\partial y_{k,j}} \gamma_j (\sigma_j^2 + \epsilon)^{-\frac{1}{2}} - \frac {1}{N} \sum_{k=1}^N \frac{\partial L}{\partial y_{k,j}} \gamma_j (x_{i,j} - \mu_j)(x_{k.j} - \mu_j) (\sigma_j^2 + \epsilon)^{-\frac{3}{2}} \\&= \frac{1}{N} \gamma_j (\sigma_j^2 + \epsilon)^{-\frac{1}{2}}(N \frac{\partial L}{\partial y_{i,j}} - \sum_{k=1}^N \frac{\partial L}{\partial y_{k,j}} - (x_{i,j} - \mu_j)(\sigma_j^2 + \epsilon)^{-1} \sum_{k=1}^N \frac{\partial L}{\partial y_{k,j}}(x_{k,j} - \mu_j)) \\&= \frac{1}{N} \gamma_j (\sigma_j^2 + \epsilon)^{-\frac{1}{2}}(N \frac{\partial L}{\partial y_{i,j}} - \sum_{k=1}^N \frac{\partial L}{\partial y_{k,j}} - (x_{i,j} - \mu_j)(\sigma_j^2 + \epsilon)^{-\frac{1}{2}} \sum_{k=1}^N \frac{\partial L}{\partial y_{k,j}}(x_{k,j} - \mu_j)(\sigma_j^2 + \epsilon)^{-\frac{1}{2}}) \\&= \frac{1}{N} \gamma_j (\sigma_j^2 + \epsilon)^{-\frac{1}{2}}(N \frac{\partial L}{\partial y_{i,j}} - \sum_{k=1}^N \frac{\partial L}{\partial y_{k,j}} - \hat x_{i,j} \sum_{k=1}^N \frac{\partial L}{\partial y_{k,j}}\hat x_{k,j}) \end{aligned} ∴代入(1)式,得∂xi,j∂L=k,l∑∂yk,l∂Lγl(−N1(xk,l−μl)(σl2+ϵ)−23(xi,l−μl)δj,l+(σl2+ϵ)−21(δi,kδj,l−N1δj,l))=k,l∑∂yk,l∂Lγl(σl2+ϵ)−21(δi,kδj,l−N1δj,l)−k,l∑∂yk,l∂Lγl(−N1(xk,l−μl)(σl2+ϵ)−23(xi,l−μl)δj,l)=∂yi,j∂Lγj(σj2+ϵ)−21−N1k=1∑N∂yk,j∂Lγj(σj2+ϵ)−21−N1k=1∑N∂yk,j∂Lγj(xi,j−μj)(xk.j−μj)(σj2+ϵ)−23=N1γj(σj2+ϵ)−21(N∂yi,j∂L−k=1∑N∂yk,j∂L−(xi,j−μj)(σj2+ϵ)−1k=1∑N∂yk,j∂L(xk,j−μj))=N1γj(σj2+ϵ)−21(N∂yi,j∂L−k=1∑N∂yk,j∂L−(xi,j−μj)(σj2+ϵ)−21k=1∑N∂yk,j∂L(xk,j−μj)(σj2+ϵ)−21)=N1γj(σj2+ϵ)−21(N∂yi,j∂L−k=1∑N∂yk,j∂L−x^i,jk=1∑N∂yk,j∂Lx^k,j)
类似地,很容易得到 ∂ L ∂ γ i \frac {\partial L}{\partial \gamma_i} ∂γi∂L与 ∂ L ∂ β i \frac {\partial L}{\partial \beta_i} ∂βi∂L
∂ L ∂ γ i = ∑ k , l ∂ L ∂ y k , l ∂ y k , l ∂ γ i = ∑ k , l ∂ L ∂ y k , l ∂ ( x ^ k , l ∗ γ l + β l ) ∂ γ i = ∑ k , l ∂ L ∂ y k , l x ^ k , l δ i , l = ∑ k = 1 N ∂ L ∂ y k , i x ^ k , i \begin{aligned} \frac {\partial L}{\partial \gamma_i} &= \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \frac {\partial y_{k,l}}{\partial \gamma_i} \\&= \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \frac {\partial (\hat x_{k,l} * \gamma_l + \beta_l)}{\partial \gamma_i} \\&=\sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \hat x_{k,l}\delta_{i,l} \\&= \sum_{k=1}^N \frac {\partial L}{\partial y_{k,i}} \hat x_{k,i} \end{aligned} ∂γi∂L=k,l∑∂yk,l∂L∂γi∂yk,l=k,l∑∂yk,l∂L∂γi∂(x^k,l∗γl+βl)=k,l∑∂yk,l∂Lx^k,lδi,l=k=1∑N∂yk,i∂Lx^k,i ∂ L ∂ β i = ∑ k , l ∂ L ∂ y k , l ∂ y k , l ∂ β i = ∑ k , l ∂ L ∂ y k , l ∂ ( x ^ k , l ∗ γ l + β l ) ∂ β i = ∑ k , l ∂ L ∂ y k , l δ i , l = ∑ k = 1 N ∂ L ∂ y k , i \begin{aligned} \frac {\partial L}{\partial \beta_i} &= \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \frac {\partial y_{k,l}}{\partial \beta_i} \\&= \sum_{k,l} \frac {\partial L}{\partial y_{k,l}} \frac {\partial (\hat x_{k,l} * \gamma_l + \beta_l)}{\partial \beta_i} \\&=\sum_{k,l} \frac {\partial L}{\partial y_{k,l}}\delta_{i,l} \\&= \sum_{k=1}^N \frac {\partial L}{\partial y_{k,i}} \end{aligned} ∂βi∂L=k,l∑∂yk,l∂L∂βi∂yk,l=k,l∑∂yk,l∂L∂βi∂(x^k,l∗γl+βl)=k,l∑∂yk,l∂Lδi,l=k=1∑N∂yk,i∂L
代码实现
class BatchNormalization:
def __init__(self, gamma, beta, momentum=0.9, running_mean=None, running_var=None):
self.gamma = gamma
self.beta = beta
self.momentum = momentum
self.input_shape = None # Conv层的情况下为4维,全连接层的情况下为2维
# 测试时使用的平均值和方差
self.running_mean = running_mean
self.running_var = running_var
# backward时使用的中间数据
self.batch_size = None
self.xc = None # x - mu
self.std = None # 标准差
self.dgamma = None
self.dbeta = None
def forward(self, x, train_flg=True):
self.input_shape = x.shape
if x.ndim != 2:
x = x.reshape(x.shape[0], -1)
out = self.__forward(x, train_flg)
return out.reshape(*self.input_shape)
def __forward(self, x, train_flg):
if self.running_mean is None:
n, d = x.shape
self.running_mean = np.zeros(d)
self.running_var = np.zeros(d)
if train_flg == True:
mu = x.mean(axis=0) # 将数据正规化
xc = x - mu
var = np.mean(xc**2, axis=0)
std = np.sqrt(var + 10e-7)
xn = xc / std
self.batch_size = x.shape[0]
self.xc = xc
self.xn = xn
self.std = std
self.running_mean = self.momentum * self.running_mean + (1-self.momentum) * mu
self.running_var = self.momentum * self.running_var + (1-self.momentum) * var
else:
xc = x - self.running_mean
xn = xc / np.sqrt(self.running_var + 10e-7)
return self.gamma * xn + self.beta
def backward(self, dout):
if dout.ndim != 2:
dout = dout.reshape(dout.shape[0], -1)
dx = self.__backward(dout)
dx = dx.reshape(*self.input_shape)
return dx
def __backward(self, dout):
dbeta = dout.sum(axis=0)
dgamma = np.sum(self.xn * dout, axis=0)
self.dgamma = dgamma
self.dbeta = dbeta
# 利用计算图得到的结论进行反向传播
# dxn = self.gamma * dout
# dxc = dxn / self.std
# dstd = -np.sum((dxn * self.xc) / (self.std**2), axis=0)
# dvar = 0.5 * dstd / self.std
# dxc += (2.0 / self.batch_size) * self.xc * dvar
# dmu = np.sum(dxc, axis=0)
# dx = dxc - dmu / self.batch_size
# 利用直接推得的梯度公式进行反向传播
# 这样的实现更快速,而且更准确
dx = self.batch_size**(-1) * self.gamma * self.std**(-1) * (self.batch_size * dout - dbeta - self.xn * dgamma)
return dx
Group Normalization
- 前面提到,Batch Normalization 因为是在 batch 维度归一化,因此要有较大的 batch 才能有效工作,而例如物体检测等任务由于占用内存较多,限制了 batch 的大小,进而也限制了 BN 层的归一化功能
- GN (Group Normalization) 从通道方向计算均值与方差,使用更为灵活有效,避开了 batch 大小对归一化的影响
S i = { k ∣ k N = i N , ⌊ k C C / G ⌋ = ⌊ i C C / G ⌋ } S_i = \{k | k_N = i_N, \lfloor \frac {k_C}{C/G} \rfloor = \lfloor \frac {i_C}{C/G} \rfloor \} Si={k∣kN=iN,⌊C/GkC⌋=⌊C/GiC⌋} k N = i N k_N = i_N kN=iN 使计算都是在一个样本 (feature map) 上进行的。 G G G 表示将 C C C 分成 G G G 个 g r o u p s groups groups,每个 g r o u p group group 中有 C / / G C // G C//G 个 c h a n n e l channel channel。因此 G G G 是一个超参数。可以看出 G = 1 G=1 G=1 时的 GN 变为 LN,而 G = C G=C G=C 时 GN 变为 IN- 因此 GN 的思想就是在相同 feature map 的相同 g r o u p group group 中进行归一化操作,而 g r o u p group group 只是在 c h a n n e l channel channel 维度上进行划分,因此归一化操作就和 batch size 无关
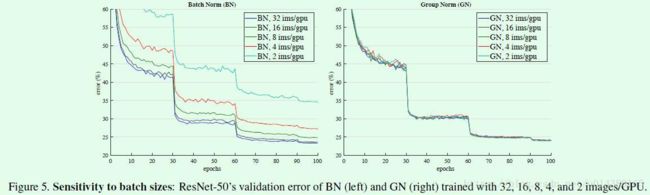
- GN 之所以可以工作,是因为特征图中,不同通道代表形状、边缘和纹理等不同意义,这些不同的通道并不是完全独立地分布,而是可以放到一起进行归一化分析
- 因此 GN 的思想就是在相同 feature map 的相同 g r o u p group group 中进行归一化操作,而 g r o u p group group 只是在 c h a n n e l channel channel 维度上进行划分,因此归一化操作就和 batch size 无关
N, C, H, W = x.shape
x = x.reshape(N, G, C // G, H, W).reshape(N * G, -1)
- 之后的处理与 BN 相同
参考文献
- 《深度学习入门 – 基于 Python 的理论与实现》
- 吴恩达深度学习视频
- Group Normalization 算法笔记
- 《机器学习方法》