yolov5项目初步理解运行
注意-相关资料链接:
(1)yolov5项目简单配置视频讲解:
https://www.bilibili.com/video/BV1nA411k7tN/?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click&vd_source=a01016572f7c0e496180bb9e42ecd34f
(2)yolov5项目代码detect.py与train.py逐行讲解:
https://www.bilibili.com/video/BV1Dt4y1x7Fz?p=2&vd_source=a01016572f7c0e496180bb9e42ecd34f
(3)yolov5格式的口罩数据集Kaggle网站中的下载地址:
https://www.kaggle.com/datasets/furiner/yolov5mask42master1
(4)数据集标签制作工具——Make Sense
用于自己制作yolov5格式的数据集:使用工具https://www.makesense.ai/为图片数据打标签 制作.txt类型的label标签
(5)yolov5项目代码下载地址:
https://github.com/ultralytics/yolov5或者https://gitee.com/wudashuo/yolov5
1.首先运行train.py文件进行训练
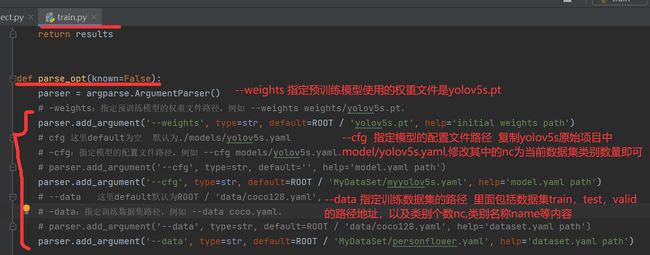
注意其中**def parse_opt(known=False)*函数中的第2-4句代码即如下代码:可以进行相应修改
def parse_opt(known=False):
parser = argparse.ArgumentParser()
# –weights:指定预训练模型的权重文件路径,例如 --weights weights/yolov5s.pt。
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
# cfg 这里default为空 默认为./models/yolov5s.yaml
# –cfg:指定模型的配置文件路径,例如 --cfg models/yolov5s.yaml。
# parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--cfg', type=str, default=ROOT / 'MyDataSet/myyolov5s.yaml', help='model.yaml path')
# --data 这里default默认为ROOT / 'data/coco128.yaml',
# –data:指定训练数据集路径,例如 --data coco.yaml。
# parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'MyDataSet/personflower.yaml', help='dataset.yaml path')
.....
(1)–data 指定训练数据集的路径 MyDataSet/personflower.yaml
train: ../MyDataSet/person-flower/train/images
val: ../MyDataSet/person-flower/valid/images
test: ../MyDataSet/person-flower/test/images
# Classes
nc: 2
#names 的两种设置方式
names: ['flower','Anther']
## 使用的数据集 https://www.kaggle.com/datasets/abhinavmalkoochi/annotated-flower-dataset
# 0: flower
# 1: Anther
(2)–cfg 指定模型配置文件 MyDataSet/myyolov5s.yaml
上述程序代码中–cfg使用的模型配置文件MyDataSet/myyolov5s.yaml:只需要复制model/yolov5s.yaml代码,修改其中的nc数值即可,修改成当前使用数据集涉及的类别种类即可。
# YOLOv5 by Ultralytics, AGPL-3.0 license
# Parameters 80 原始coco128是80个种类
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.train.py运行完后得到的结果(其存储位置,文件夹名称等在train.py中均有相关代码进行设置)
# train.py运行结果保存路径地址
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
# train.py运行结果保存的文件夹名称
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')

3.detect.py代码文件运行
train.py运行完后使用其得到的exp/weights/last.yaml权重文件进行验证,修改运行detect.py文件
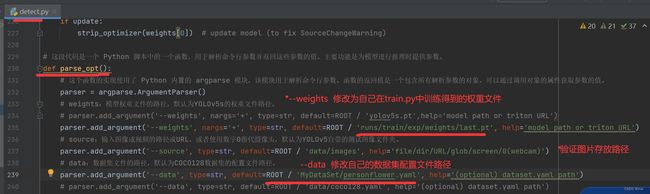
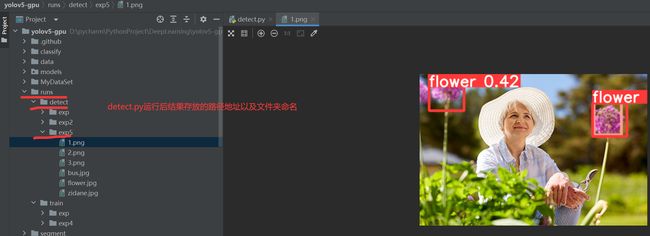
4.detect.py运行结果(其存储位置,文件夹名称等在detect.py中均有相关代码进行设置)
# detect.py运行结果保存路径地址
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
# detect.py运行结果保存的文件夹名称
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
5.制作自己的数据集用于train.py以及detect.py进行测试
(数据集尽可能图片量多(30张以上试试),否则在train.py中运行后得到的权重文件用到detect.py中检测不出图片里的内容)
数据集要求(yolo格式):数据集中包括训练集train,测试集test以及验证集valid,
train,test以及valid文件夹里包括图片数据images以及对应的标签信息label,其中标签应该为.txt格式
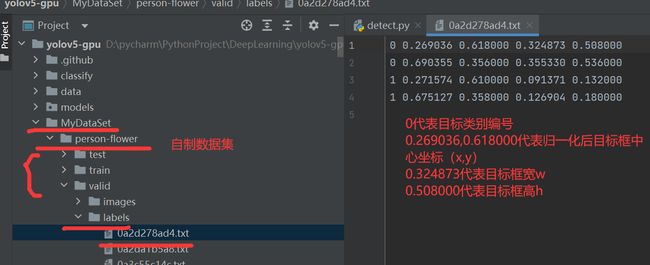
例如1.txt,其内容如下:
yolov5项目中所用数据集标签label格式:
每一行数据代表一个目标框,每一行的5个数据分别代表
类别编号(从0开始的) 归一化后的目标框中心坐标(x,y) 目标框的宽w 目标框的高h
0 0.269036 0.618000 0.324873 0.508000
0 0.690355 0.356000 0.355330 0.536000
1 0.271574 0.610000 0.091371 0.132000
1 0.675127 0.358000 0.126904 0.180000
(1)指定训练数据集的路径—此处是personflower.yaml
仿照yolov5项目中提供的data/coco128.yaml文件进行编辑
# 数据集训练集train,测试集test以及验证集valid存储的位置
train: ../MyDataSet/person-flower/train/images
val: ../MyDataSet/person-flower/valid/images
test: ../MyDataSet/person-flower/test/images
# Classes
nc: 2 # 数据集类别数量
names:
# 数据集各类别名称以及编号 从0开始
# 使用的数据集 https://www.kaggle.com/datasets/abhinavmalkoochi/annotated-flower-dataset
0: flower
1: Anther
(2)指定模型的配置文件----此处使用的是myyolov5s.yaml
仿照yolov5项目中提供的model/yolov5s.yaml文件进行编辑(只需要修改nc的数值即可)**
(直接将原始的model/yolov5s.yaml文件复制,然后修改里面的nc:80这句代码,将80改为与当前数据集类别数量一致的数字即可)
# YOLOv5 by Ultralytics, AGPL-3.0 license
# Parameters 80 原始coco128是80个种类
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
注意:用于yolov5项目的数据集格式要求
数据集文件夹中一般包括images(图片)与label(标签)两部分,images与label中可包括train(训练集),valid(验证集)以及test(测试集)三部分数据
其中标签label中的文件格式为**.txt**
内容包括五项:类别编号 检测框中心点坐标(x,y) 检测框宽w 检测框高h