视频理解学习笔记(四)
视频理解学习笔记(四)
- 3D CNN
-
- C3D
- I3D
- Non-local算子 (Self-attention替换掉LSTM)
- R (2 + 1) D
- SlowFast
- Video Transformer
-
- TimeSformer
- 总结
- Reference
3D CNN
双流的缺点:光流抽取太慢——tvl one算法,0.06s抽取一个光流帧;消耗空间
3D Conv:同时学习空间和时间信息
C3D
论文地址:Learning Spatiotemporal Features with 3D Convolutional Networks_ICCV’15 from FAIR and Dartmouth College
用3D网络来学习时空特征。A simple, yet efficient approach for spatiotemporal feature learning using deep 3-dimensional convolutional networks (3D ConvNets) trained on a large scale supervised video dataset (sports 1M).
不是第一个用3D卷积做视频理解,但是第一个用大规模数据集和更深的网络,达到了比较好的效果。
CSD是指fc6抽取出来的特征,叫做C3D特征。作者给出了现成的实现,给定视频,可以直接返回1 * 4096的C3D特征。

和DeepVideo的区别:直接用3D卷积来处理视频
实验:

I3D
论文概览_CVPR’17
降低了网络训练的难度(如何从2D网络inflate成3D网络,如何利用预训练好的2D模型初始化3D模型bootstrap),提出了Kinetics-400数据集
I3D和C3D的区别:虽然两者都是用3D卷积做处理,但是C3D仅仅是在参考2D模型做3D设计,没办法将2D的模型迁移到3D;而I3D本质上是一个迁移学习,将2D模型和参数inflate到3D,从而实现3D卷积。
实验:

- 证明了2D迁移到3D的有效性。
Non-local算子 (Self-attention替换掉LSTM)
论文地址:Non-local Neural Networks_IEEE’18 by Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He from CMU and FAIR
Non-local是一个可以即插即用(plug and play)的模块(building block),用来建模长距离信息。
Non-local算子:

其实就是将自注意力(self-attention)模块从2D转化(膨胀,inflate)成了3D。
消融实验:

点积最好(transformer本来就用的点积)

在 r e s 5 res_{5} res5上加的效果最差:可能是因为该层特征图已经很小了,空间信息不充分。
考虑到non-local算子的开销,作者只在 r e s 3 res_{3} res3和 r e s 4 res_{4} res4上应用了non-local算子。

说明non-local算子确实有用。10-block:resnet的结构是3、4、6、3,只在 r e s 3 res_{3} res3和 r e s 4 res_{4} res4加non-local算子。

证明【时】【空】注意力是有效的(因为transformer本身是融合空间信息)。
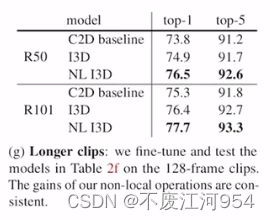
证明non-local在长时序建模上是有效的。
和其他模型对比:

R (2 + 1) D
实验性论文,研究时空卷积到底怎么做比较好。
出发点:对视频用2D卷积一帧一帧抽取特征的效果也很好,而3D卷积计算昂贵,能否使用2D卷积代替部分3D卷积。
- 先2D再3D
- 先3D再2D
- ……
结论:拆分成空间上的2D + 时间上的1D
论文地址:A Closer Look at Spatiotemporal Convolutions for Action Recognition_CVPR’18 from Facebook Research and Dartmouth College
方法:


模型确实更容易训练了:

结果对比:

R (2 + 1) D的结果不比I3D好。主要亮点在于参数大大减少,训练速度更快。输入是112 * 112,对显存友好。

SlowFast
论文地址:SlowFast Networks for Video Recognition_ICCV’19 by Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik and Kaiming He from FAIR
启发:人的视觉系统中有两种细胞,一种叫P细胞,一种叫M细胞。其中P细胞占据80%,主要负责处理静态图像;M细胞负责处理高频运动信息。和双流系统类似。将以上内容借鉴到3D网络上。
方法:
- 慢分支(Slow Pathway):隔得比较远抽帧,且该分支网络较大(标准的I3D网络)。
- 快分支(Fast Pathway):隔得比较近抽帧,且该分支网络较小。
- 最后将两个分支的信息融合起来。


实验结果:

精度高,推理高效,但训练时间依旧很长。
Video Transformer
TimeSformer
第一篇将ViT从图像迁移到视频的实验性paper,能处理超过1min的视频。
Is Space-Time Attention All You Need for Video Understanding_ICML’21 from FAIR and Dartmouth College.
方法:

上述方法的可视化理解:

实验结果:

总结

- Beyond Short Snippets:LSTM
- TDD:按照光流轨迹去做叠加
- TSN:把长视频分成短的clip
- I3D:Inflate和K400
Reference
Bilibili-视频理解论文串讲(下)