从入门到进阶 之 ElasticSearch 文档、分词器 进阶篇
以上分享 ElasticSearch 文档、分词器 进阶篇,如有问题请指教写。
如你对技术也感兴趣,欢迎交流。
如有需要,请点赞收藏分享 核心概念
 索引
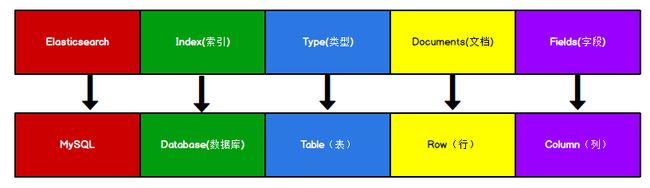
索引
一个拥有几分相似特征的文档的集合。一个索引由一个名字来标识(必须全部是小写字母),对索引文档进行索引、搜索、更新和删除(CRUD)时,使用该索引名。可以定义任意多的索引。
搜索的数据必须索引,可以提高查询速度
Elasticsearch 索引
一切设计都是为了提高搜索的性能。
类型
在一个索引中,你可以定义一种或多种类型。
| 版本 | Type |
|---|---|
| 5.x | 支持多种 type |
| 6.x | 只能有一种 type |
| 7.x | 默认不再支持自定义索引类型(默认类型为: _doc) |
文档
一个文档是一个可被索引的基础信息单元,也就是一条数据。
字段
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
映射
mapping 是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引,都是映射里面可以设置的,按着最优规则处理数据对性能提高很大,建立映射需要思考如何建立映射才能对性能更好。
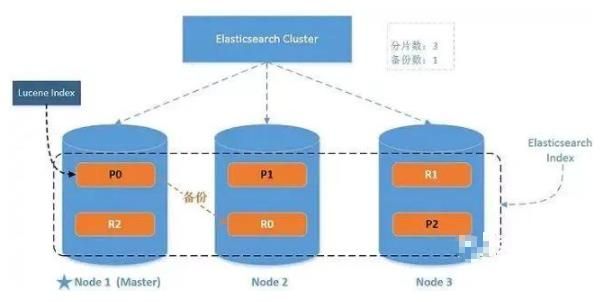
分片
分片是 Elasticsearch 最小的工作单元。 单个索引可存储超出单个节点硬件限制的大量数据。Elasticsearch 提供了将索引分片划分成多份的能力。当创建一个索引,指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
- 允许水平分割 / 扩展你的内容容量。
- 允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
副本
Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
- 在分片/节点失败的情况下,提供了高可用性。
- 注意到复制分片从不与原/主要(original/primary)分片置于同一节点上。
- 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
分配
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
架构
单节点集群
#PUT http://127.0.0.1:1001/goods
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}

故障转移

水平扩容
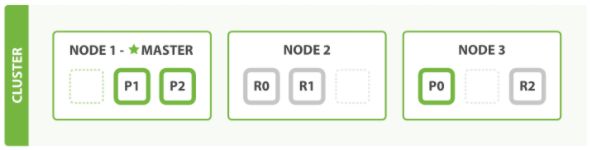
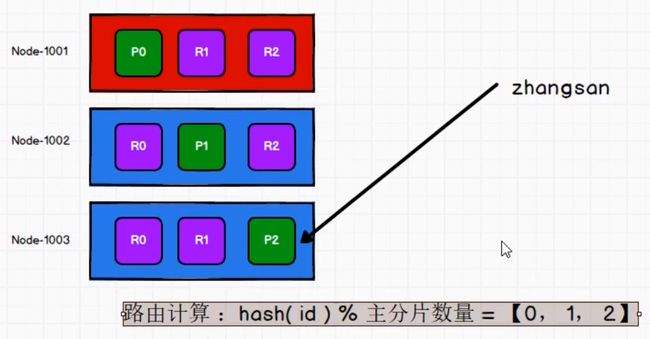
路由计算
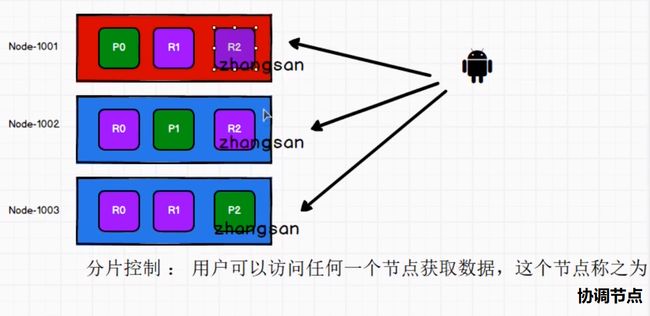
分片控制
数据流程
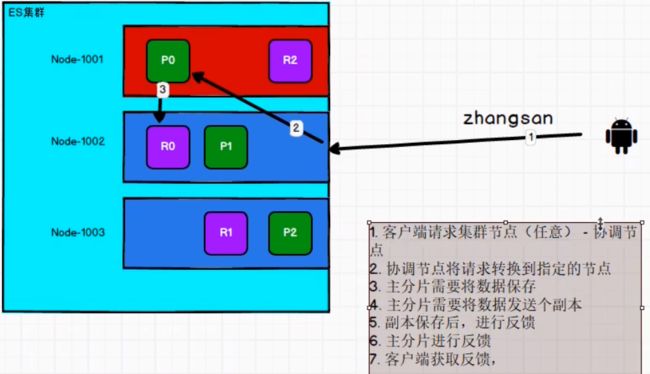
写
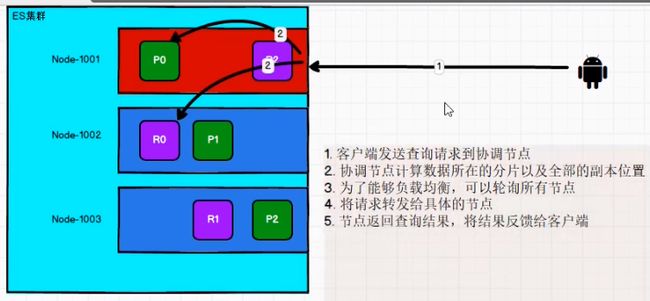
读
 更新
更新
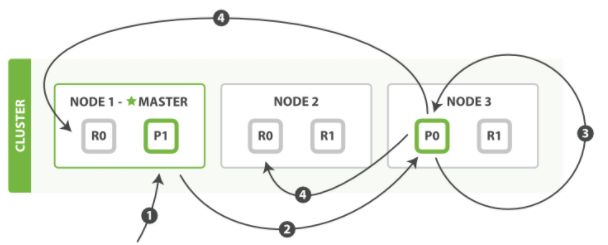
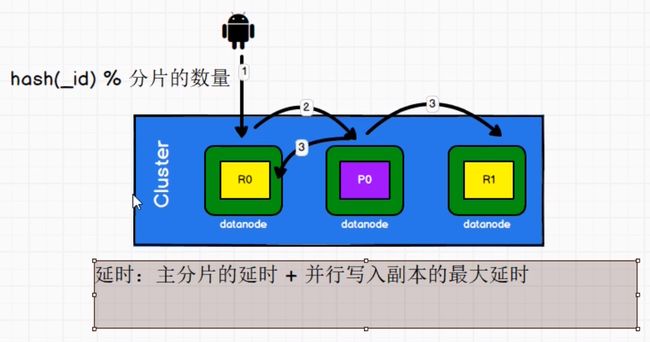
1. 客户端向Node 1 发送更新请求
2. 将请求转发到主分片所在的Node 3上
多文档操作
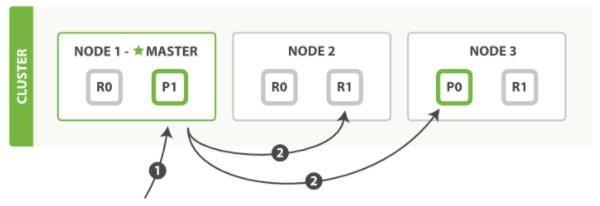
mget 和 bulk API 的模式类似于单文档模式。
区别在于协调节点知道每个文档存在于哪个分片中。它将整个多文档请求分解成 每个分片 的多文档请求,并且将这些请求并行转发到每个参与节点。
协调节点一旦收到来自每个节点的应答,就将每个节点的响应收集整理成单个响应,返回给客户端
倒排索引
Elasticsearch使用一种称为倒排索引的结构,它适用于快速的全文搜索。
正向索引:就是搜索引擎会将待搜索的文件都对应一个文件ID,搜索时将这个ID和搜索关键字进行对应,形成K-V对,然后对关键字进行统计计数 。
倒排索引:一个倒排索引由文档中所有不重复词的列表构成,用其中的不重复的词跟文档唯一标识关联。(涉及到分词:分词器)
keyword : 不能拆分
text:可拆分(根据分词器的算法进行拆分)

文档操作
文档搜索
倒排索引被写入磁盘后是 不可改变 的:它永远不会修改
不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
一旦索引被读入内核的文件系统缓存,由于其不变性。只要文件系统缓存中还有足够的空间,大部分读请求会直接请求内存,不会命中磁盘。很大的性能提升。
其它缓存(像 filter 缓存),在索引的生命周期内始终有效。不需要在每次数据改变时被重建,因数据不会变化。
写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量
动态更新索引
按段搜索
通过增加新的补充索引来反映新近的修改,不直接重写整个倒排索引。每一个倒排索引都会被轮流查询到,从最早的开始查询完后再对结果进行合并。
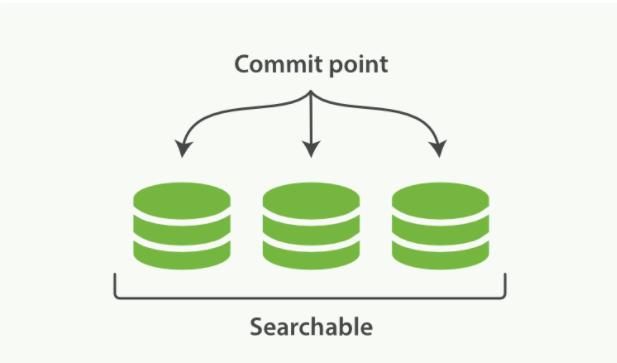
- 新文档被收集到内存索引缓存
- 不时地, 缓存被提交
- 一个新的段,一个追加的倒排索引,被写入磁盘。
- 一个新的包含新段名字的提交点被写入磁盘。
- 磁盘进行同步,所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件
- 新的段被开启,让它包含的文档可见以被搜索
- 内存缓存被清空,等待接收新的文档
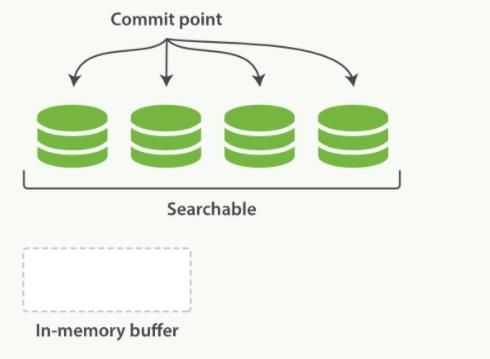
逻辑删除:当一个查询被触发,已知的段按顺序被查询。词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算。用相对较低的成本将新文档添加到索引。
段是不可改变的,既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。每个提交点会包含一个.del 文件,文件中会列出这些被删除文档的段信息。
物理删除:当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
刷新、刷写、合并
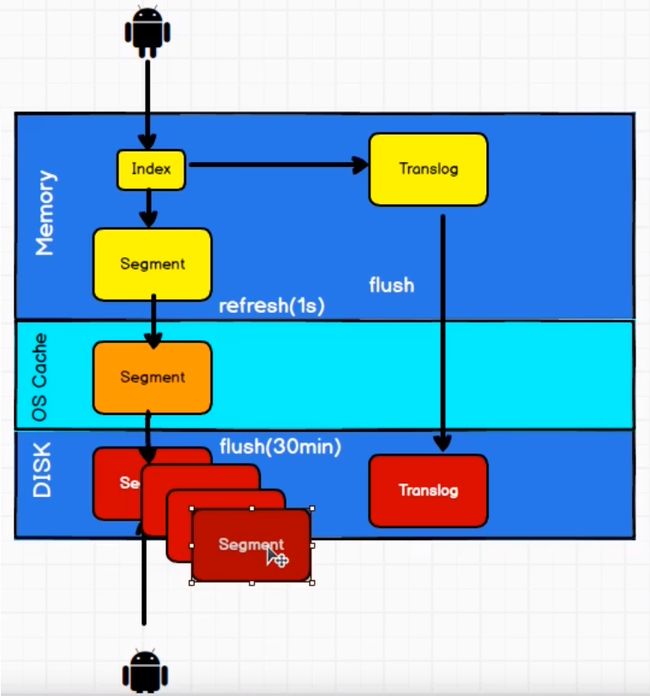
一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了 translog
刷新(refresh)使分片每秒被刷新(refresh)一次
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行fsync操作。
- 这个段被打开,使其可被搜索。
- 内存缓冲区被清空。
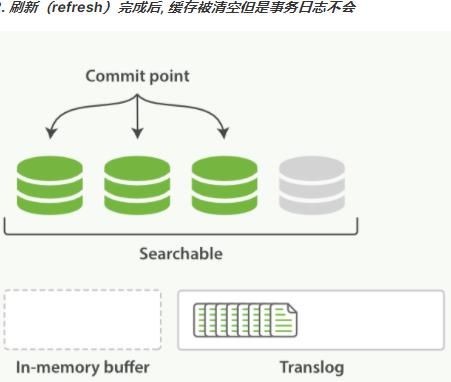
这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志。
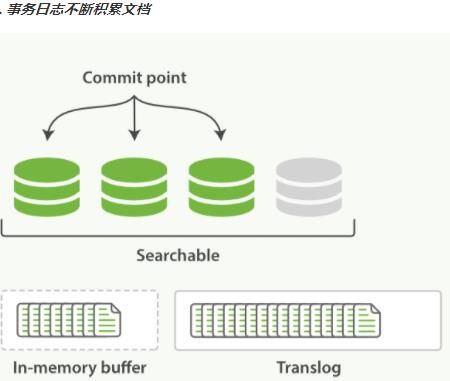
每隔一段时间—例如translog变得越来越大,索引被刷新(flush)
一个新的translog被创建,并且一个全量提交被执行。
-
所有在内存缓冲区的文档都被写入一个新的段。
-
缓冲区被清空。
-
一个提交点被写入硬盘。
-
文件系统缓存通过fsync被刷新(flush) 。
-
老的translog被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当Elasticsearch启动的时候,它会从磁盘中使用最后一个提交点去恢复己知的段,并且会重放translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时CRUD。通过ID查询、更新、删除一个文档,它会在尝试从相应的段中检索之前,首先检查 translog任何最近的变更。能够实时地获取到文档的最新版本。
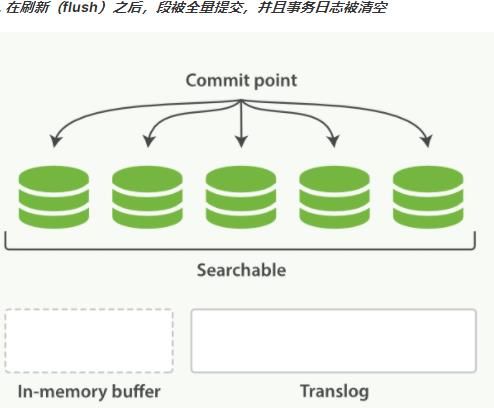
分析
- 将一块文本分成适合于倒排索引的独立的 词条
- 将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
分析器
字符过滤器
字符串按顺序通过每个字符过滤器 。在分词前整理字符串。一个字符过滤器可以用来去掉 HTML,或者将 & 转化成 and。
分词器
字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点可能会将文本拆分成词条。
Token 过滤器
词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像 jump和 leap 这种同义词)
内置分析器
标准分析器
标准分析器是 Elasticsearch 默认使用的分析器。它是分析各种语言文本最常用的选择。它根据 Unicode 联盟 定义的 单词边界 划分文本。删除绝大部分标点。将词条小写.
set, the, shape, to, semi, transparent, by, calling, set trans, 5
简单分析器
简单分析器在任何不是字母的地方分隔文本,将词条小写。
set, the, shape, to, semi, transparent, by, calling, set, trans
空格分析器
空格分析器在空格的地方划分文本。
Set, the, shape, to, semi-transparent, by, calling, set trans(5)
语言分析器
特定语言分析器可用于 很多语言。它们可以考虑指定语言的特点。
测试分析器
内置分析器
 IK 分词器
IK 分词器
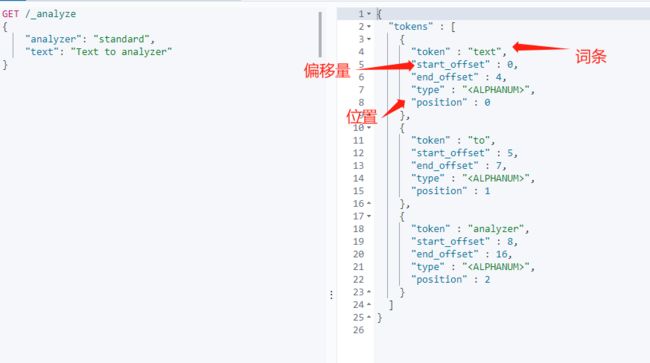
# GET http://localhost:9201/_analyze
{
"text":"测试单词",
"analyzer":"ik_max_word"
}
{
"tokens": [
{
"token": "测试",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "单词",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}
]
}
- 首先进入 ES 根目录中的 plugins 文件夹下的 ik 文件夹,进入 config 目录,创建 custom.dic文件,写入“小老儿最帅”。
- 同时打开 IKAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中。
- 重启 ES 服务器 。
IK Analyzer 扩展配置
custom.dic
自定义分析器
#PUT http://localhost:9200/my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [
"&=> and "
]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [
"the",
"a"
]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"html_strip",
"&_to_and"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"my_stopwords"
]
}
}
}
}
}
# GET http://127.0.0.1:9200/my_index/_analyze
{
"text":"The quick & brown fox",
"analyzer": "my_analyzer"
}