python基础入门练习(字符串练习)
字符串练习题
- 去掉字符串中所有的空格
- 获取字符串中汉字的个数
- 将字母全部转换为大写和小写
- 根据标点符号对字符串进行分行
- 去掉字符串数组中每个字符串的空格(循环)
- 随意输入心中想到的一个书名,然后输出它的字符串长度(len属性)
- 接收用户输入的字符串,将其中的字符进行排序,并以逆序输出,例如:acdefb - abcdef-
fedcba - 用户输入一句英文,将其中的单词以反序输出 例如:hello c sharp — sharp c hello
- 用户输入一句话,找出所有”呵“的位置
- 有个字符串数组,存储了10个书名,书名有长有短,现在将他们统一处理,若长度大于10,则
截取长度为8的子串,将统一处理后的结果输出 - 用户输入一句话,找出所有”呵呵“的位置
- 如何判断一个字符串是否是另一个字符串的子串
- 如何验证一个字符串中的每一个字符均在另一个字符串中出现
- 如何生成无数字的全字母的字符串
- 如何随机生成带数字和字母的字符串
- 如何判定一个字符串中既有数字又有字母
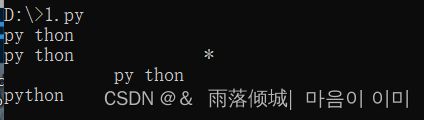
1.去掉字符串中所有的空格
代码:
#strip() ---- 清除字符串两侧空格
s=" py thon "
print(s.strip())
#lstrip() ----- 清除字符串左侧空格
s=" py thon *"
print(s.lstrip())
#rstrip()----- 清除字符串右侧空格
s=" py thon "
print(s.rstrip())
#清除所有的空格
s=" py thon "
print(s.replace(" ",""))
运行结果:
2. 获取字符串中汉字的个数
在python3中,str默认是unicode编码
用 ord() 函数判断单个字符的unicode编码是否大于255即可。
一般来说,中文常用字的范围是:[\u4e00-\u9fa5]
代码:
def get_char(char):
count=0
for i in char:
if 0x4E00 <= ord(i) <= 0x9FA5:
count+=1
return count
c=get_char("你知道shabi吗")
print("汉字的个数为:%s" % c)
运行结果:

3. 将字母全部转换为大写和小写
| lower() | 将字符串中字母转换为小写 |
|---|---|
| upper() | 将字符串中字母转换为大写 |
代码:
s="l love you"
print(s.upper())
t="YOU LOVE ME"
print(t.lower())
运行结果:

4. 根据标点符号对字符串进行分行
代码:
s="python,l need you,okk"
print(s.replace(",","\n"))
运行结果:

5.去掉字符串数组中每个字符串的空格(循环)
代码:
s=["p y thin","a hsa a","h hg a"]
t=[]
for i in s:
a=i.replace(" ","")
t.append(a)
print(t)
运行结果:

6. 随意输入心中想到的一个书名,然后输出它的字符串长度(len属性)
代码:
book=input("请输入一个书名:")
print("长度为:%s"% len(book))
运行结果:

7.接收用户输入的字符串,将其中的字符进行排序,并以逆序输出,例如:acdefb - abcdef-fedcba
| sort() | 列表排序字母按照ASCII的值进行排序,元素类型必须是一致 |
|---|---|
| reverse() | 将列表进行翻转 |
| join() | 按照特定的格式将一个可迭代对象拼接为字符串 |
代码:
word = input("请输入一个字符串:")
word_list = list(word)
word_list.sort()
word_list.reverse()
print("".join(word_list))
运行结果:

8.用户输入一句英文,将其中的单词以反序输出 例如:hello c sharp — sharp c hello
split() -----根据指定的字符格式将字符串进行分割,注意:返回的是列表
代码:
word = input("请输入一句英文:")
t=word.split(" ")
t.reverse()
print(" ".join(t))
运行结果:

9.用户输入一句话,找出所有”呵“的位置
代码:
word = input("请输入一句话,找出呵的位置:")
index = 1
for i in word:
if i =="呵":
print("第%s个呵在这个位置" % index)
index += 1
运行结果:

10.有个字符串数组,存储了10个书名,书名有长有短,现在将他们统一处理,若长度大于10,则截取长度为8的子串,将统一处理后的结果输出
代码:
book = ["The Old Man and the Sea","Le Comte de Monte-Cristo","The adventures of Robinson Crusoe","Uncle Tom's Cabin"]
for i in book:
if len(i)>9:
print(i[0:9])
else:
print(j)
运行结果:

11. 用户输入一句话,找出所有”呵呵“的位置
代码:
words = input("请输入一句话,找出所有呵呵的位置:")
for i in range(1,len(words)):
if words[i]=="呵" and words[i+1]=="呵":
print("呵呵在%s,%s的位置" % (i,i+1))
运行结果:

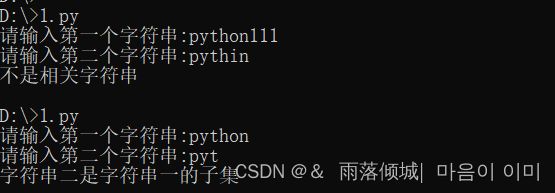
12. 如何判断一个字符串是否是另一个字符串的子串
代码:
word_one = input("请输入第一个字符串:")
word_two = input("请输入第二个字符串:")
if word_one in word_two:
print("字符串一是字符串二的子集")
if word_two in word_one:
print("字符串二是字符串一的子集")
else:
print("不是相关字符串")
运行结果:
13. 如何验证一个字符串中的每一个字符均在另一个字符串中出现
代码:
word_one = input("请输入第一个字符串:")
word_two = input("请输入第二个字符串:")
flag = "true"
if len(word_one) < len(word_two):
for i in word_one:
index = 0
for j in word_two:
index += 1
if i == j:
break
if index == len(word_two):
flag = "false"
if len(word_two) <= len(word_one):
for i in word_two:
index = 0
for j in word_one:
index += 1
if i == j:
break
if index == len(word_one):
flag = "false"
if flag == "true":
print("字符串中的每一个字符均在另一个字符串中出现")
else:
print("字符串中的每一个字符没有都在另一个字符串中出现")
运行结果:

14. 如何生成无数字的全字母的字符串
字符串常量:此模块中定义的常量
| string.ascii_letters | 下文所述 ascii_lowercase 和 ascii_uppercase 常量的拼连 |
|---|---|
| string.ascii_lowercase | 小写字母 ‘abcdefghijklmnopqrstuvwxyz’。 |
| string.ascii_uppercase | 大写字母 ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’。 |
| random.choice(seq) | 从非空序列 seq 返回一个随机元素。 如果 seq 为空,则引发 IndexError。 |
代码:
import random
import string
for i in range(0,random.randint(1,10)):
print(random.choice(string.ascii_letters),end="")
运行结果:

15.如何随机生成带数字和字母的字符串
代码:
import string
import random
for i in range(0,random.randint(1,4)):
for j in range(0,random.randint(1,4)):
print(random.choice(string.ascii_letters),end="")
for j in range(0,random.randint(1,4)):
print(random.randint(1,10),end="")
运行结果:

16.16. 如何判定一个字符串中既有数字又有字母
代码:
word = input("请输入一个字符串,如何判定一个字符串中既有数字又有字母:")
if word.isalnum() and (not word.isdigit() and not word.isalpha()):
print("既有数字和字母")
else:
print("不是既有数字和字母")
运行结果:
