数据序列化
目录
一、概述
二、数据序列化的意义
三、数据序列化方案
3.1 序列化框架 Thrift
3.2 序列化框架 Protobuf
3.3 序列化框架 Avro
四、序列化框架对比
4.1 性能方面
4.2 非功能方面
一、概述
数据序列化:数据序列化是将内存对象转化为字节流的过程,它直接决定了数据解析效率以及模式演化能力(数据格式发生变化时,比如增加或删除字段,是否仍能够保持兼容性)。
二、数据序列化的意义
当需要将数据存入文件或者通过网络发送出去时,需将数据对象转化为字节流,即对数据序列化。考虑到性能、占用空间以及兼容性等因素,我们通常会经历以下几个阶段的技术演化,最终找到解决该问题的最优方案:
阶段 1:不考虑任何复杂的序列化方案,直接将数据转化成字符串,以文本形式保存或传输,如果一条数据存在多个字段,则使用分隔符(比如“,”)。该方案存储简单数据绰绰有余,但对于复杂数据,且数据模式经常变动时,将变得非常繁琐,通常会面临以下问题。
(1)难以表达嵌套数据:如果每条数据是嵌套式的,比如类似于map,list数据结构时,以文本方式存储是非常困难的。
(2)无法表达二进制数据:图片、视频等二进制数据无法表达,因为这类数据无法表达成简单的文本字符串。
(3)难以应对数据模式变化:在实际应用过程中,由于用户考虑不周全或需求发生变化,数据模式可能会经常发生变化。而每次发生变化,之前所有写入和读出(解析)模块均不可用,所有解析程序均需要修改,非常繁琐。
阶段 2:采用编程语言内置的序列化机制,比如 Java Serialization,Python pickle 等。这种方式解决了阶段 1 面临的大部分问题,但随着使用逐步深入,可以发现这种方式将数据表示方式跟某种特定语言绑定在一起,很难做到跨语言数据的写入和读取。
阶段 3:为了解决阶段 2 面临的问题,我们决定使用应用范围广、跨语言的数据表示格式,比如JSON 和 XML。但使用一段时间后,你会发现这种方式存在严重的性能问题:解析速度太慢,同时数据存储冗余较大,比如JSON会重复存储每个属性的名称等。
阶段 4:到这一阶段,我们期望出现一种带有schema描述的数据表示格式,通过统一化的schema描述,可约束每个字段的类型,进而为存储和解析数据带来优化的可能。此外,统一schema的引入,可减少属性名称重复存储带来的开销,同时,也有利于数据共享。
阶段 4 提到的方式便是序列化框架,常用的有 Thrift,Protocol Buffers 和 Avro,它们被称为“Language Of Data”。它们通过引入 schema,使得数据跨序列化变得非常高效,同时提供了代码生成工具,为用户自动生成各种语言的代码。总结起来,“Language Of Data”具备以下基本特征:
(1)提供 IDL(Interface Description language)用以描述数据 schema,能够很容易地描述任意结构化数据和非结构化数据。
(2)支持跨语言读写,至少支持 C++、Java 和 Python 三种主流语言。
(3)数据编码存储(整数可采用变长编码,字符串可采用压缩编码等),以尽可能避免不必要的存储浪费。
(4)支持schema演化,即允许按照一定规则修改数据的schema,仍可保证读写模块向前向后的兼容性。如下图所示

解释:图(1) 读写两端采用相同schema,Writer 生成文件,Reader 可读出对应的数据;图(2) Writer 端采用旧 schema,Reader端采用新 schema,Reader 可根据新 schema 读出数据,并自动将新增字段设置为默认值;图(3) Writer 端采用新 schema,Reader 端采用旧 schema,Reader 可根据旧 schema 读出数据,并自动过滤掉新增字段。
三、数据序列化方案
目前存在很多开源序列化方案,其中比较著名的有 Facebook Thrift,Google Protocol Buffers(简称“Protobuf”)以及 Apache Avro,这些序列化方案大同小异,彼此之间不存在压倒性优势,在实际应用中,需结合具体应用场景作出选择。
3.1 序列化框架 Thrift
Thrift 是 Facebook 开源的 RPC(Remote Produre Call Protocol)框架,同时具有序列化和 RPC 两个功能,它几乎支持所有编程语言,包括 C++、Java、Python、PHP、Ruby、Erlang、Perl、Haskel 等。
Thrift提供了一套 IDL 语法用以定义和描述数据类型和服务。IDL文件由专门的代码生成器生成对应的目标语言代码,以供用户在应用中使用。Thrift IDL 语法类似于 C语言。
(网页是一种非结构化数据,包括网页URL、标题、主体、pagerank值、网页级别(用以辨识网页内容健康状况)、入链(链接到该网页的网页)以及出链(该网页指向的网页)等)
使用 Thrift IDL 描述网页数据如下:
namespace java com.hadoopspark.generated.thrift
//定义枚举类型 DocLevel,表示网页内容级别
enum DocLevel {
CLEAN = 0,
NORMAL = 1,
MAYBE = 2,
BAD = 3,
}
//定义网页,类似于 Java 和 C++ 中的类
struct MergeDoc {
1:required i64 docId, //每个网页被赋予一个64为唯一ID
2:required string url, //网页URL
3:optional string title, //网页标题
4:optional string segBody, //经分词后的网页主体
5:optional i32 pagerank, //网页pagerank,网页排名使用
10:optional DocLevel docLevel, //网页级别
11:optional list inLinks, //网页入链,只保存入链网页的docId
12:optional list outLinks //网页出链
} Thrift 用 struct 关键字描述一类对象的统称,经 Thrift 编译器编译后,将被翻译成目标语言中的类。Thrift struct 中每个域由四个属性构成:
(1)域编号:每个域必须是唯一(但可以不连续)的整数,Thrift 用该编号实现向后向前兼容性。在 schema 演变过程中,不要删除和修改已有域的编号,只需为新的域赋予新的编号即可。
(2)域修饰:包括 required 和 optional 两个关键字,用以对域的数值进行限制,required 表示必须为该域设置数值,“optional”表示该域数值可有可无。
(3)域类型:Thrift 支持非常丰富的数据类型,既支持 int,long 等基本类型,也支持set、list 及 map 等复杂容器类型,具体可参考Thrift官网文档描述。
(4)域名称:同一 struct 下每个域名称必须唯一,可为域设置默认数值。
3.2 序列化框架 Protobuf
Protocol Buffers 是 Google 公司开源的序列化框架,主要支持 Java,C++ 和 Python 三种语言,语法和使用方式与 Thrift 非常类似,但不包含 RPC 实现。由于采用了更加紧凑的数据编码方式,大部分情况下,对于相同数据集,ProtoBuf 比 Thrift 占用存储空间更小,且解析速度更快。
使用 Protobuf 描述网页数据如下:
option java_package = "com.hadoopspark.generated.proto"; //生成 java 代码的包名
option java_outer_classname = "MergeDocHolder"; //生成代码后外部类名称
option optimize_for = SPEED; //显示指明,对速度进行优化
//定义网页,类似于Java和C++中的类
message MergeDoc {
required int64 docId = 1;
required string url = 2;
optional string title = 3;
optional string segBody = 4;
optional int32 pagerank = 5;
//定义枚举类型DocLevel;表示网页内容级别
enum DocLevel {
CLEAN = 0;
NORMAL = 1;
MAYBE = 2;
BAD = 3;
}
optional DocLevel docLevel = 10;
repeated int64 inLinks = 11;
repeated int64 outLinks = 12;
}Protocol Buffers 用 “message” 关键字描述一类对象的统称,经 Protobuf 编译器编译后,将被翻译成目标语言中的类。Protobuf message中每个域也由四个属性构成:
(1)域编号:每个域必须是唯一(但可以不连续)的整数,Protobuf 用该编号实现向后向前兼容性。在 schema 演变过程中,不要删除和修改已有域的编号,只需为新的域赋予新的编号即可。
(2)域修饰:包括 “required” ,“ optional”和“repeated” 三个关键字,用以对域的数值进行限制,required 表示必须为该域设置数值,“optional”表示该域数值可有可无,“repeated”表示该域数值可有多个,由于Protobuf没有显式提供数组这种容器数据结构,用户可使用该关键字定义数组。
(3)域类型:Protobuf 支持常用数据类型,包括 bool, int32,float,double,和string 等基本类型,自定义类型,数组等,在proto3开始,增加了对map容器的支持,具体可参考Protobuf官网文档描述。
(4)域名称:同一 message 下每个域名称必须唯一,可为域设置默认数值。
3.3 序列化框架 Avro
Avro 是Hadoop生态系统中的序列化及RPC框架,设计之初的意图是为Hadoop提供一个高效、灵活且易于演化的序列化及RPC基础库,目前已经发展成一个独立的项目。相比于 Thrift 和 Protobuf,Avro具有以下几个特点:
(1)动态类型:Avro不需要生成代码,它将数据和schema存放在一起,这样数据处理过程并不需要生成代码,方便构建通用的数据处理系统和语言。
(2)未标记的数据:读取 Avro 数据时schema是已知的,这使得编码到数据中的类型信息变少,进而使得序列化后的数据量变少。
(3)不需要显式指定域编号:处理数据时新旧schema都是已知的,因此通过使用字段名称即可解决兼容性问题。
使用 Avro 描述网页数据如下:
@namespace("com.hadoopspark.generated.avro")
protocol MergedDocHolder {
enum DocLevel {
CLEAN,NORMAL,MAYBE,BAD
}
record MergeDoc {
long docId;
string url;
string title;
string segBody;
int pagerank;
DocLevel docLevel;
array inLinks;
array outLinks;
}
} 四、序列化框架对比
4.1 性能方面
(1)解析速度
测试三种序列化框架解析 100 万个 MergedDoc 对象所花时间,三者所花时间从小到大依次是:Protobuf、Thrift 和 Avro。
(2)序列化后数据大小
对于一条相同数据,采用三种序列化框架进行序列化,Thrift支持两种二进制形式的序列化方式,分别为原生方法(binary)和优化编码后的方法(compact)。对于MergeDoc而言,四者序列化后由小到大依次为 Avro、Protobuf、Thrift(comoact)和 Thrift(binary)。
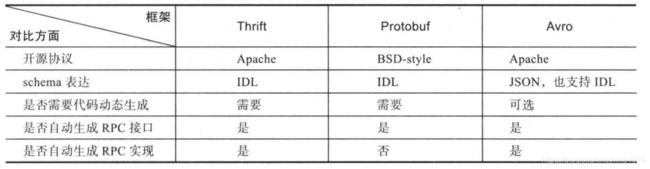
4.2 非功能方面
---内容主要来自于《大数据技术体系详解:原理、架构与实践》