工作5年后我才发现:90%的技术问题,可以解决
01、前言
现在市面上的智能电子产品千千万,为了达到人们使用更加方便的目的,很多智能产品都开发了语音识别功能,用来语音唤醒进行交互;另外,各大公司也开发出来了各种智能语音机器人,比如小米公司的“小爱”,百度公司的“小度”,三星公司的“bixby”,苹果的“siri”等等。这些语音识别的功能,提高人们使用电子的产品的体验,但是作为一名测试员,给你一款语音识别产品,要怎么进行测试呢?
接下来,我就以小米手机为例,给大家介绍小米手机语音识别如何测试。
小米语音识别功能如何进行测试?
要知道语音识别功能如何测试,我们先了解智能产品语音交互流程:

如果你想学习自动化测试,我这边给你推荐一套视频,这个视频可以说是B站播放全网第一的自动化测试教程,同时在线人数到达1000人,并且还有笔记可以领取及各路大神技术交流:798478386
【已更新】B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)_哔哩哔哩_bilibili【已更新】B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)共计200条视频,包括:1、接口自动化之为什么要做接口自动化、2、接口自动化之request全局观、3、接口自动化之接口实战等,UP主更多精彩视频,请关注UP账号。 https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337
https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337
所以,要进行测试的话,我们需要从以下几个维度来准备测试点:
02、基础功能测试:
1、声纹的录入:
语音唤醒,为了确保每个人的声音、每个人在不同场景下的声音都能成功语音唤醒,测试一定要有各种不同的声纹来进行测试。
所以,就需要录入各种不同的声纹,来丰富测试场景的覆盖;
2、语音唤醒:
正常唤醒:使用正常的声纹进行语音唤醒,检查可以成功;
异常唤醒:使用异常的声音,比如视频/录音进行唤醒,音乐声进行唤醒,确保不会有误唤醒。
3 唤醒后的功能:
a、语音找设备:可以唤醒设备,比如手机,通过语音找到设备。
b、音量调节:可以通过语音对设备进行音量调节
c、连续对话:唤醒设备后,可以与其进行持续的语音对话,功能正常。
d、指令识别:唤醒后,可以下发指令比如播放音乐,查询天气,拨打电话、定闹钟等,检查指令可以正常被执行。
4、功能冲突交互测试
a、中断测试:语音识别过程中,有中断干扰,比如手机唤醒的时候有电话中断;有闹钟中断、低电量中断等,确保这些中断能被正常处理,不会造成异常;
b、麦克风冲突:如果麦克风被占用了,测试是否能被唤醒;
5、多用户场景
因为用户使用语音识别的场景非常多,测试很难进行完全的覆盖。所以,我们需要通过分析用户的主流使用场景,来覆盖主要的场景。
通过一些数据的采集,发现用户使用的场景屏幕分布如下
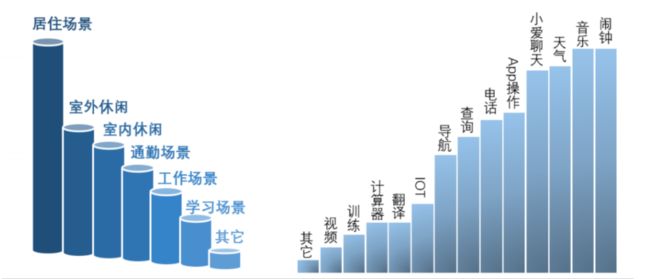
调查结果发现,用户使用语音功能主要覆盖以下场景:
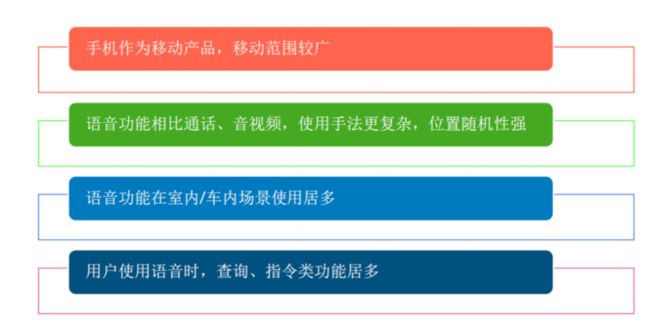
所以测试就主要优先去覆盖这些用户场景,其他的场景用例优先级可以逐步降低,调整测试权重,保证用户主流场景的稳定性和准确性。
03、UI 测试
语音唤醒的有 UI 界面需要进行 UI 测试。
比如手机的语音唤醒功能,需要进行 UI 界面的检查,保持 UI 的友好型和美观性;
04、兼容性测试
1,第三方应用的兼容性测试
如果设备里有安装其他的应用,比如手机里的其他应用,是否可以通过语音识别唤醒后进行指定的动作操作;第三方应用兼容性需要保证;
2,外界设备兼容
a、三段式耳机接入
b、四段式耳机接入
c、type-c 数字耳机接入
d、蓝牙耳机接入
通过接入这些第三方的耳机设备,可以进行语音识别并且功能正常。
05、自动化语音识别测试
以上都是通过手工进行测试的,要进行一个比较完整的语音识别覆盖,至少需要以下配置:
测试人数:10/20 人(男女各一半)
测试次数:每个场景 50 次
测试环境:办公室、会议室
测试场景:亮屏唤醒、灭屏唤醒、手机播放音乐唤醒、声纹误唤醒、基本语句识别率
但是手工测试是有不可忽视的一些严重缺陷的:
1、测试手法不统一:不同的距离和不同的角度都会导致识别结果不一样。
2、测试过程中人员声音波动大
同一算法,同一产品,在测试人员不变,场景一致的情况下,多轮测试的数据差异大;
由此可见,手工测试耗时耗力、测试数据参考价值低。所以,语音识别测试也可以进行一些自动化测试。
06、自动化测试的关键点
1、实现半自动化语音测试
因为手工测试就是没有办法提供那么多人进行不同语料的测试,所以需要实现语料自动合成和模拟。可以采用 python+pyaudio 开发 + 音箱模拟人声,来对语音进行识别测试。
而且通过增加语料量级(至少 40 组声纹),降低唤醒/识别频次;增加不同的噪音环境,不同噪音 + 不同距离,模拟用户真实环境。
这样,就可以覆盖更多的不同的语料以及场景,大大提高识别的正确率。
2、语料自动化播放 + 自动化检测
现在有了语料,但是需要手动播放的话,工作量依然很大,所以需要实现语料自动播放和自动化监测。
3、增加噪声播放系统 + 滑轨控制系统
因为用户的使用场景往往有很多的噪音,如果测试不模拟这种噪音环境,是没有办法真正还原用户场景的。所以,需要设置一些噪音源,可以自动化增加噪音,并可以调整距离。
如下图,就是小米公司的专为为测试语言识别造的混响室,以及自动化调节人头系统
