【Note】CNN与现代卷积神经网络part2(附Pytorch代码)
文章目录
-
- 1.4 多输入多输出通道
-
- 1.4.1 多输入通道
- 1.4.2 多输出通道
- 1.4.3 1×1卷积层
- 1.4.4 Summary
- 1.5 汇聚层
-
- 1.5.1 最大汇聚层和平均汇聚层
- 1.5.2 填充和步幅
- 1.5.3 多个通道
- 1.5.4 Summary
- 1.6 卷积神经网络(LeNet)
-
- 1.6.1 LeNet
- 1.6.2 模型训练
- 1.6.3 Summary
本《CNN与现代卷积神经网络》Note系列会共分为四个part,本文为part2。全文markdown10k字。
1.4 多输入多输出通道
虽然我在 1.1.4 节中描述了构成每个图像的多个通道和多层卷积层。例如彩色图像具有标准的RGB通道来代表红、绿和蓝。 但是到目前为止,我们仅展示了单个输入和单个输出通道的简化例子。 这使得我们可以将输入、卷积核和输出看作二维张量。
当我们添加通道时,我们的输入和隐藏的表示都变成了三维张量。例如,每个RGB输入图像具有3×h×w的形状。我们将这个大小为3的轴称为通道(channel)维度。本节将更深入地研究具有多输入和多输出通道的卷积核。
1.4.1 多输入通道
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。假设输入的通道数为 c i c_i ci,那么卷积核的输入通道数也需要为 c i c_i ci。如果卷积核的窗口形状是 k h × k w k_h×k_w kh×kw,那么当 c i = 1 c_i=1 ci=1时,我们可以把卷积核看作形状为 k h × k w k_h×k_w kh×kw的二维张量。
然而,当 c i > 1 c_i>1 ci>1时,我们卷积核的每个输入通道将包含形状为 k h × k w k_h×k_w kh×kw的张量。
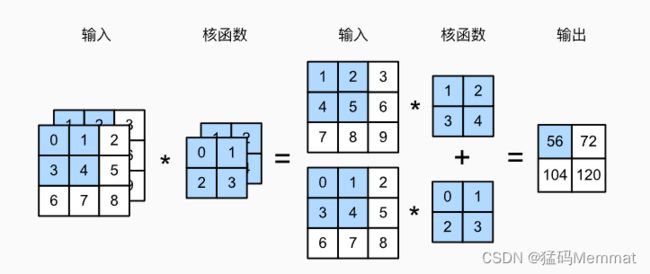
为了加深理解,我们实现一下多输入通道互相关运算。 简而言之,我们所做的就是对每个通道执行互相关操作,然后将结果相加。
import torch
from d2l import torch as d2l
def corr2d_multi_in(X, K):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
我们可以构造相对应的输入张量X和核张量K,以验证互相关运算的输出。
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
corr2d_multi_in(X, K)

1.4.2 多输出通道
到目前为止,不论有多少输入通道,我们还只有一个输出通道。然而,正如我们在 1.1.4.1节中所讨论的,每一层有多个输出通道是至关重要的。在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。

如下所示,我们实现一个计算多个通道的输出的互相关函数。
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
通过将核张量K与K+1(K中每个元素加1)和K+2连接起来,构造了一个具有3个输出通道的卷积核。
K = torch.stack((K, K + 1, K + 2), 0)
K.shape
![]()
下面,我们对输入张量X与卷积核张量K执行互相关运算。现在的输出包含3个通道,第一个通道的结果与先前输入张量X和多输入单输出通道的结果一致。
corr2d_multi_in_out(X, K)

1.4.3 1×1卷积层
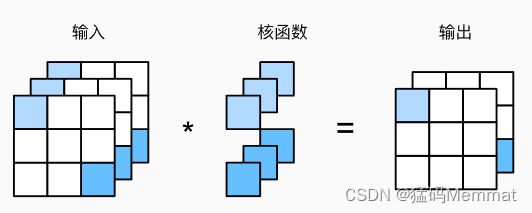
互相关计算使用了具有3个输入通道和2个输出通道的 1 × 1 1\times1 1×1卷积核。其中,输入和输出具有相同的高度和宽度。
下面,我们使用全连接层实现 1 × 1 1\times1 1×1卷积。 请注意,我们需要对输入和输出的数据形状进行调整。
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
当执行 1 × 1 1\times1 1×1卷积运算时,上述函数相当于先前实现的互相关函数corr2d_multi_in_out。让我们用一些样本数据来验证这一点。
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
1.4.4 Summary
- 多输入多输出通道可以用来扩展卷积层的模型。
- 当以每像素为基础应用时, 1 × 1 1\times1 1×1卷积层相当于全连接层。
- 卷积层通常用于调整网络层的通道数量和控制模型复杂性。
1.5 汇聚层
通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大。
而我们的机器学习任务通常会跟全局图像的问题有关(例如,“图像是否包含一只猫呢?”),所以我们最后一层的神经元应该对整个输入的全局敏感。通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层。
此外,当检测较底层的特征时(例如 1.2节中所讨论的边缘),我们通常希望这些特征保持某种程度上的平移不变性。例如,如果我们拍摄黑白之间轮廓清晰的图像X,并将整个图像向右移动一个像素,即Z[i, j] = X[i, j + 1],则新图像Z的输出可能大不相同。而在现实中,随着拍摄角度的移动,任何物体几乎不可能发生在同一像素上。即使用三脚架拍摄一个静止的物体,由于快门的移动而引起的相机振动,可能会使所有物体左右移动一个像素(除了高端相机配备了特殊功能来解决这个问题)。
本节将介绍汇聚(pooling)层,它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
1.5.1 最大汇聚层和平均汇聚层
与卷积层类似,汇聚层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出。 然而,不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。 相反,池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值。这些操作分别称为最大汇聚层(maximum pooling)和平均汇聚层(average pooling)。
在这两种情况下,与互相关运算符一样,汇聚窗口从输入张量的左上角开始,从左往右、从上往下的在输入张量内滑动。在汇聚窗口到达的每个位置,它计算该窗口中输入子张量的最大值或平均值。计算最大值或平均值是取决于使用了最大汇聚层还是平均汇聚层。
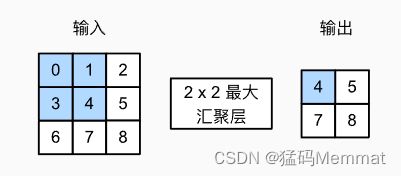
在下面的代码中的pool2d函数,我们实现汇聚层的前向传播。 这类似于 1.2节中的corr2d函数。 然而,这里我们没有卷积核,输出为输入中每个区域的最大值或平均值。
import torch
from torch import nn
from d2l import torch as d2l
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
我们可以构建 图1.5.1中的输入张量X,验证二维最大汇聚层的输出。
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
pool2d(X, (2, 2))

此外,我们还可以验证平均汇聚层。
pool2d(X, (2, 2), 'avg')

1.5.2 填充和步幅
与卷积层一样,汇聚层也可以改变输出形状。和以前一样,我们可以通过填充和步幅以获得所需的输出形状。 下面,我们用深度学习框架中内置的二维最大汇聚层,来演示汇聚层中填充和步幅的使用。 我们首先构造了一个输入张量X,它有四个维度,其中样本数和通道数都是1。
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
X

默认情况下,深度学习框架中的步幅与汇聚窗口的大小相同。 因此,如果我们使用形状为(3, 3)的汇聚窗口,那么默认情况下,我们得到的步幅形状为(3, 3)。
pool2d = nn.MaxPool2d(3)
pool2d(X)
![]()
填充和步幅可以手动设定。
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)

当然,我们可以设定一个任意大小的矩形汇聚窗口,并分别设定填充和步幅的高度和宽度。
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)

1.5.3 多个通道
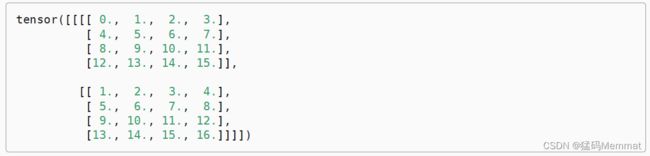
在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总。 这意味着汇聚层的输出通道数与输入通道数相同。 下面,我们将在通道维度上连结张量X和X + 1,以构建具有2个通道的输入。
X = torch.cat((X, X + 1), 1)
X
如下所示,汇聚后输出通道的数量仍然是2。
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)

1.5.4 Summary
- 对于给定输入元素,最大汇聚层会输出该窗口内的最大值,平均汇聚层会输出该窗口内的平均值。
- 汇聚层的主要优点之一是减轻卷积层对位置的过度敏感。
- 我们可以指定汇聚层的填充和步幅。
- 使用最大汇聚层以及大于1的步幅,可减少空间维度(如高度和宽度)。
- 汇聚层的输出通道数与输入通道数相同。
1.6 卷积神经网络(LeNet)
现在,我们已经掌握了卷积层的处理方法,我们可以在图像中保留空间结构。 同时,用卷积层代替全连接层的另一个好处是:模型更简洁、所需的参数更少。
本节将介绍LeNet,它是最早发布的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。 这个模型是由AT&T贝尔实验室的研究员Yann LeCun在1989年提出的(并以其命名),目的是识别图像 (LeCun et al., 1998)中的手写数字。 当时,Yann LeCun发表了第一篇通过反向传播成功训练卷积神经网络的研究,这项工作代表了十多年来神经网络研究开发的成果。
当时,LeNet取得了与支持向量机(support vector machines)性能相媲美的成果,成为监督学习的主流方法。 LeNet被广泛用于自动取款机(ATM)机中,帮助识别处理支票的数字。 时至今日,一些自动取款机仍在运行Yann LeCun和他的同事Leon Bottou在上世纪90年代写的代码呢!
1.6.1 LeNet
总体来看,LeNet(LeNet-5)由两个部分组成:
- 卷积编码器:由两个卷积层组成;
- 全连接层密集块:由三个全连接层组成。
该架构如图所示。
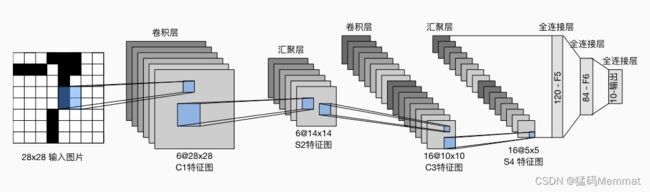
LeNet中的数据流。输入是手写数字,输出为10种可能结果的概率。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。换言之,我们将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们在执行分类任务,所以输出层的10维对应于最后输出结果的数量。
通过下面的LeNet代码,可以看出用深度学习框架实现此类模型非常简单。我们只需要实例化一个Sequential块并将需要的层连接在一起。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
我们对原始模型做了一点小改动,去掉了最后一层的高斯激活。除此之外,这个网络与最初的LeNet-5一致。
下面,我们将一个大小为 28 × 28 28\times28 28×28的单通道(黑白)图像通过LeNet。通过在每一层打印输出的形状,我们可以检查模型,以确保其操作与我们期望的一致。
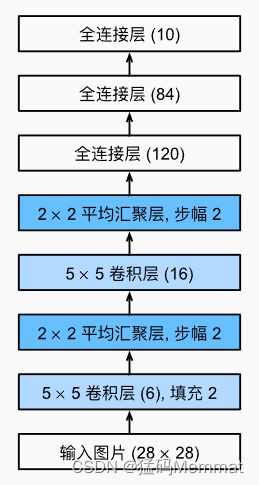
LeNet 的简化版。
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
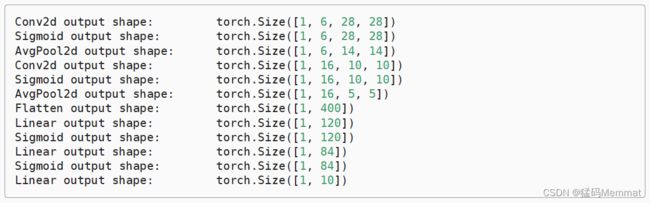
在整个卷积块中,与上一层相比,每一层特征的高度和宽度都减小了。第一个卷积层使用2个像素的填充,来补偿 5 × 5 5\times5 5×5卷积核导致的特征减少。 相反,第二个卷积层没有填充,因此高度和宽度都减少了4个像素。 随着层叠的上升,通道的数量从输入时的1个,增加到第一个卷积层之后的6个,再到第二个卷积层之后的16个。 同时,每个汇聚层的高度和宽度都减半。最后,每个全连接层减少维数,最终输出一个维数与结果分类数相匹配的输出。
1.6.2 模型训练
现在我们已经实现了LeNet,让我们看看LeNet在Fashion-MNIST数据集上的表现。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
虽然卷积神经网络的参数较少,但与深度的多层感知机相比,它们的计算成本仍然很高,因为每个参数都参与更多的乘法。 通过使用GPU,可以用它加快训练。
为了进行评估,我们需要对evaluate_accuracy函数进行轻微的修改。 由于完整的数据集位于内存中,因此在模型使用GPU计算数据集之前,我们需要将其复制到显存中。
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
为了使用GPU,我们还需要一点小改动。 与train_epoch_ch3不同,在进行正向和反向传播之前,我们需要将每一小批量数据移动到我们指定的设备(例如GPU)上。
如下所示,训练函数train_ch6类似于定义的train_ch3。 由于我们将实现多层神经网络,因此我们将主要使用高级API。 以下训练函数假定从高级API创建的模型作为输入,并进行相应的优化。我们使用Xavier随机初始化模型参数。 与全连接层一样,我们使用交叉熵损失函数和小批量随机梯度下降。
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
现在,我们训练和评估LeNet-5模型。
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
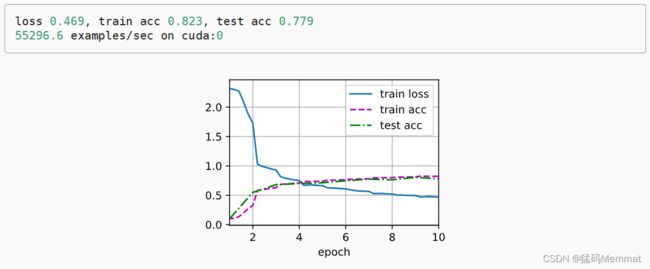
1.6.3 Summary
- 卷积神经网络(CNN)是一类使用卷积层的网络。
- 在卷积神经网络中,我们组合使用卷积层、非线性激活函数和汇聚层。
- 为了构造高性能的卷积神经网络,我们通常对卷积层进行排列,逐渐降低其表示的空间分辨率,同时增加通道数。
- 在传统的卷积神经网络中,卷积块编码得到的表征在输出之前需由一个或多个全连接层进行处理。
- LeNet是最早发布的卷积神经网络之一。