Spark大数据分与实践笔记(第二章 Spark基础-01)
第二章 Spark基础
Spark于 2009 年诞生于美国加州大学伯克利分校的 AMP 实验室,它是一个可应用于大规模数据 处理的统一分析引擎。 Spark 不仅计算速度快,而且内置了丰富的 API ,使得我们能够更加容易编写程序 。
2.1 初识Spark
2.1.1 Spark的概述
Spark在2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。

●Spark Core:Spark核心组件,实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含对弹性分布式数据集的API定义。
●Spark SQL:用来操作结构化数据的核心组件,通过Spark SQL可直接查询Hive、HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD。
●Spark Streaming:Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业。
●MLlib:Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能。
●GraphX:Spark提供的分布式图处理框架,拥有对图计算和图挖掘算法的API接口及丰富的功能和运算符,便于对分布式图处理的需求,能在海量数据上运行复杂的图算法。
●独立调度器、Yarn、Mesos:集群管理器,负责Spark框架高效地在一个到数千个节点之间进行伸缩计算的资源管理。
Spark生态系统各个组件关系密切,并且可以相互调用,这样设计具有以下显著优势:
●Spark生态系统包含的所有程序和高级组件都可以从Spark核心引擎的改进中获准。
●不需要运行多套独立的软件系统,能够大大减少运行整个系统的资源代价。
●能够无缝整合各个系统,构建不同处理模型的应用。
综上所述,Spark框架对大数据的支持从内存计算、实时处理到交互式查询,进而发展到图计算和机器学习模块。
2.1.2 Spark的特点
Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。所以说,Spark是一个更加快速、高效的大数据计算平台。
- 速度快
根据官方数据统计得出,Spark的运行速度比Hadoop要快的多,并且Spark实现了高效的DAG执行引擎。 - 易用性
Spark编程支持Java、Python、Scala或R语言,并且还拥有超过80种的高级算法,除此之前,Spark还支持交互式的Shell操作。 - 通用性
Spark提供了统一的解决方案,适用于批处理、交互式查询(Spark SQL)、实例流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。 - 兼容性
Spark可以运行在Hadoop模式、Mesos模式、Standalone独立模式或Cloud中,并且还可以访问各种数据源,包括本地文件系统、HDFS、Cassandra、HBase和Hive等。
2.1.3 Spark应用场景
在数据科学应用中,数据工程师可以利用Spark进行数据分析与建模,由于Spark具有良好的易用性,数据工程师只需要具备一定的SQL语言基础、统计学、机器学习等方面的经验,以及使用Python、Matlab或者R语言的基础编程能力,就可以使用Spark进行上述工作。
在数据处理应用中,大数据工程师将Spark技术应用于广告、报表、推荐系统等业务中,在广告业务中,利用Spark系统进行应用分析、效果分析、定向优化等业务,在推荐系统业务中,利用Spark内置机器学习算法训练模型数据,进行个性化推荐及热点点击分析等业务。
Spark拥有完整而强大的技术栈,如今已吸引了国内外各大公司的研发与使用,淘宝技术团队使用Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等,应用于商品推荐、社区发现等功能。
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在"数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通投放系统上。
优酷土豆则将Spark应用于视频推荐(图计算)、广告等业务的研发与拓展,相信在将来,Spark会在更多的应用场景中发挥重要作用。
2.1.4 Spark与Hadoop对比
Hadoop与Spark两者都是大数据计算框架,但是两者各自都有自己的优势,关于Spark与Hadoop的对比,主要有以下几点:
1.编程方式
Hadoop的MapReduce在计算数据时,计算过程必须要转化为Map和Reduce两个过程,而Spark的计算模型不局限于Map和Reduce操作,还提供了多种数据集的操作类型,编程模型比MapReduce更加灵活。
2.数据存储
Hadoop的MapReduce进行计算时,每次产生的中间结果都是存储在本地磁盘中;而Spark在计算时产生的中间结果存储在内存中。
3.数据处理
Hadoop在每次执行数据处理时,都需要从磁盘中加载数据,导致磁盘的IO开销较大;而Spark在执行数据处理时,只需要将数据加载到内存中,之后直接在内存中加载中间结果数据集即可,减少了磁盘的IO开销。
4.数据容错
MapReduce计算的中间结果数据,保存在磁盘中,并且Hadoop框架底层实现了备份机制,从而保证了数据容错;同样Spark RDD实现了基于Lineage的容错机制和设置检查点两种方式的容错机制,弥补数据在内存处理时断电数据丢失的问题。

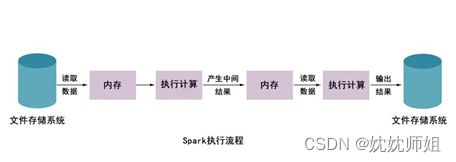
从上图可以看出,使用Hadoop MapReduce进行计算时,每次计算产生的中间结果都需要从磁盘中读取并写入,大大增加了磁盘的I/O开销。
而使用Spark进行计算时,需要先将磁盘中的数据读取到内存中,产生的数据不再写入磁盘,直接在内存中迭代处理,这样就避免了从磁盘中频繁读取数据造成的不必要开销。通过官方计算测试,Hadoop与Spark执行逻辑回归所需的时间对比,如图所示。

从上图可以看出,Hadoop与Spark执行的所需时间相差超过100倍。
2.2 搭建Spark开发环境
请参考《Hadoop大数据技术与应用》完成Hadoop集群构建。
搭建Spark环境是开展Spark编程的基础。在深入学习Spark编程之 前,我们需要的先搭建Spark开发环境
2.2.1 环境准备
由于Spark仅仅是一种计算框架,负责数据的存储和管理,因此,通常都会将Spark和Hadoop进行统一部署,由Hadoop中的HDFS、HBase等组件负责数据的存储管理,Spark负责数据计算。
安装Spark集群之前,需要安装Hadoop环境,我们当前采用如下配置环境。
Linux系统:CentOS_6.7版本
Hadoop:2.7.4版本 http://archive.apache.org/dist/hadoop/common/
JDK:1.8版本
Spark:2.3.2版本
2.2.2 Spark的部署方式
Spark部署模式分为Local模式(本地单机模式)和集群模式,在Local模式下, 常用于本地开发程序与测试,而集群模式又分为Standalone模式(集群单机模式)、 Yarn模式和Mesos模式,关于这三种集群模式的相关介绍具体如下:
- Standalone模式
Standalone模式被称为集群单机模式,在该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker。(主节点只有一个,所以存在单点故障问题,要搭建高可用的Spark集群) - Yarn模式
Yarn模式被称为Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务, Yarn模式又分为Yarn Cluster模式和Yarn Client模式,具体介绍如下:
●Yarn Cluster: 用于生产环境,所有的资源调度和计算都在集群上运行。
●Yarn Client: 用于交互、调试环境。 - Mesos模式
Mesos模式被称为Spark on Mesos模式,Mesos 与Yarn同样是一款资源调度管理系统, 可以为Spark提供服务, 由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到了对Mesos的集成,但如果你同时运行Hadoop和Spark,从兼容性的角度来看,Spark on Yarn是更好的选择。
2.2.3 Spark集群安装部署
我们将以图所示的Spark集群为例,阐述Standalone模式下,Spark集群的安装与配置方式。

规划的Spark集群包含一台Master节点和两台Slave节点。其中,主机名hadoop01是Master节点,hadoop02和hadoop03是Slave节点。
接下来,分步骤演示Spark集群的安装与配置,具体如下。
2.2.3.1下载Spark安装包
Spark是Apache基金会面向全球开源的产品之一,用户都可以从Apache Spark官网https://spark.apache.org/downloads.html下载使用。本书截稿时,Spark最新且稳定的版本是2.3.2,所以本书将以Spark2.3.2版本为例介绍Spark的安装。Spark安装包 下载页面如图所示。
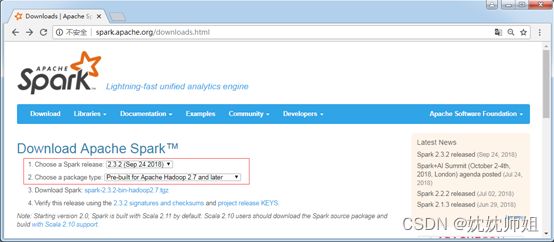
可以将页面向下拉,找到release archives.点击进去找历史版本下载。


2.2.3.2 解压Spark安装包
首先将下载的spark-2.3.2-bin-hadoop2.7.tgz安装包上传到主节点hadoop01的/export/software目录下,然后解压到/export/servers/目录,解压命令如下。
tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz -C /export/servers/
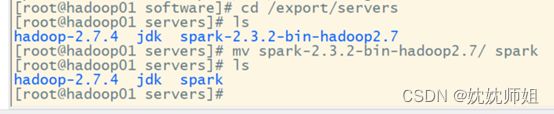
为了便于后面操作,我们使用mv命令将Spark的目录重命名为spark,命令如下。
mv spark-2.3.2-bin-hadoop2.7/ spark
2.2.3.3 修改配置文件
(1)进入spark/conf目录修改Spark的配置文件spark-env.sh,将spark-env.sh.template配置模板文件复制一份并命名为spark-env.sh,具体命令如下。
cp spark-env.sh.template spark-env.sh
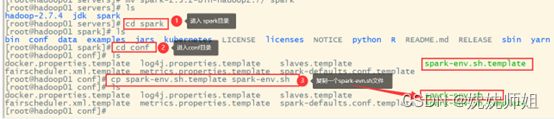
修改spark-env.sh文件,在该文件添加以下内容:
#配置java环境变量
export JAVA_ HOME=/export/servers/jdk
#指定Master的IP
export SPARK_ MASTER_ HOST=hadoop01
#指定Master的端口
export SPARK_ MASTER_ PORT=7077
上述添加的配置参数主要包括JDK环境变量、Master节 点的IP地址和Master端口号,由于当前节点服务器已经在/etc/hosts文件配置了IP和主机名的映射关系,因此可以直接填写主机名。
(2)复制slaves.template文件, 并重命名为slaves,具体命令如下。
cp slaves.template slaves

(3)通过“vi slaves’命令编辑slaves配置文件,主要是指定Spark集群中的从节点IP,由于在hosts文件中已经配置了IP和主机名的映射关系,因此直接使用主机名代替IP,添加内容如下。
hadoop02
hadoop03

2.2.3.4 分发文件
修改完成配置文件后,将spark目录分发至hadoop02和hadoop03节点,具体命令如下。
scp -r /export/servers/ spark/ hadoop02:/export/servers/
scp -r /export/servers/spark/ hadoop03:/export/servers/
至此,Spark集群配置完成了 。
2.2.3.5 启动Spark集群
Spark集群的启动方式和启动Hadoop集群方式类似,直接使用spark/sbin/start- al.sh脚本即可,在spark根目录下执行下列命令:
sbin/start-all.sh

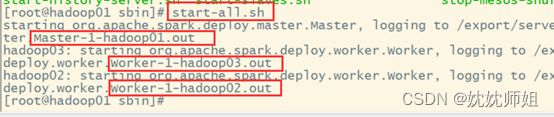
可以看到进程被启动了。

访问Spark管理界面http://hadoop01:8080来查看集群状态(主节点), Spark集群管理界面如图所示。
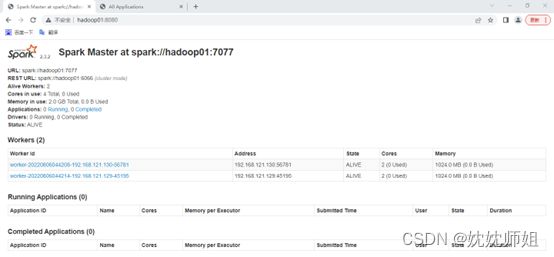
至此,Spark集群安装完毕,为了在任何路径下可以执行Spark脚本程序,可以通过执行“vi /etc/profile’命令编辑profile文件,并在文件中配置Spark环境变量即可,这里就不再演示。
2.2.4 Spark HA集群部署
Spark Standalone集群是主从架构的集群模式,因此同样存在单点故障问题,解决这个问题就需要用到Zookeeper服务,其基本原理是将Standalone集群连接到同一个Zookeeper实例并启动多个Master节点,利用Zookeeper提供的选举和状态保存功能,可以使一台Master节点被选举, 另外一台Master节 点处于Standby状态。当活跃的Master发生故障时,Standby状态的Master就会被激活, 然后恢复集群调度,整个恢复过程可能需要1-2分钟。
Spark HA方案配置简单,首先启动一个Zookeeper集群,然后在不同节点上启动Master服务,如果有读者未安装Zookeeper集群,请参考《Hadoop大数据技术与应用》完成Zookeeper集群环境的安装及配置,下面仅提供当前虚拟机中修改后的Zookeeper核心配置文件,如文件2-1所示。
文件2-1 zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/export/data/zookeeper /zkdata
clientPort=2181
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
接下来,我们分步骤讲解配置Spark HA集群的操作方式。
1.修改spark-env.sh配置文件
在spark-env.sh文件中,将指定Master节点的配置参数注释,即在SPARK_ MASTER_ HOST配置参数前加“#”,表示注释当前行,添加SPARK_ DAEMON_ JAVA OPTS配置参数,具体内容如下。
#指定Master的IP
#export SPARK_MASTER_HOST=hadoop01
#指定Master的端口
export SPARK_MASTER_PORT=7077
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181
-Dspark.deploy.zookeeper.dir=/spark"
关于上述参数的具体说明如下所示:
●spark.deploy.recoveryMode:设置Zookeeper去启动备用Master模式。
●spark.deploy.zookeeper.url:指定ZooKeeper的Server地址。
●spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。
配置完成后,将spark-env.sh分发至hadoop02、hadoop03节点上,保证配置文件统一,命令如下。
scp spark-env.sh hadoop02:/ekport/servers/spark/conf
scp spark-env.sh hadoop03:/export/servers/spark/conf
2.启动Spark HA集群
在高可用模式下启动Spark集群,首先需要启动Zookeeper集群,然后在任意一台主节点上执行start-all.sh命令启动Spark集群,最后在多外一台主节点上单独启动Master服务。具体步骤如下。
(1)启动Zookeeper服务
依次在三台节点上启动Zookeeper(进入到/export/servers/zookeeper-3.4.10/bin目录下),命令如下。
zkServer.sh start
(2)启动Spark集群
在hadoop01主节点使用—键启动脚本启动,命令如下。
/export/servers/spark/sbin/start-all.sh

(3)单独启动Master节点
在hadoop02节点再次启动Master服务,命令如下。
/export/servers/spark/sbin/start-master.sh

启动成功后,通过浏览器访问http://hadoop02:8080,查看备用Master节点状态,如图所示。
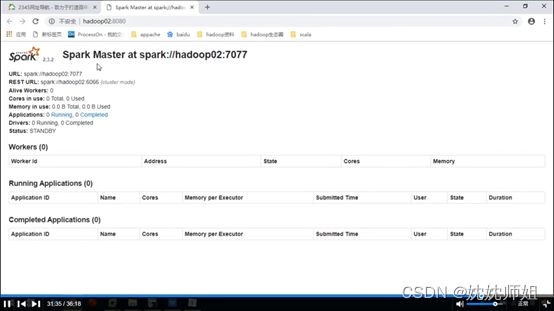
启动Spark HA集群
3.测试Spark HA集群
Spark HA集群启动完毕后,为了演示是否解决了单点故障问题,可以关闭在hadoopo1节点中的Master进程,用来模拟在生产环境中hadoop01突然宕机,命令如下所示。
/export/servers/spark/sbin/stop-master.sh
执行命令后,通过浏览器查看http://hadoop01:8080,发现已经无法通过hadoop001节点访问Spark集群管理界面。大约经过1-2分钟后,刷新 http://hadoop02:8080页面,可以发现hadoop02节点中的Status值更改为ALIVE,Spark集群恢复正常,说明Spark HA配置有效解决了单点故障问题,具体如图所示。

多学一招:脚本启动Zookeeper集群
在集群中启动Zookeeper服务时,需要依次在三台服务器上执行启动命令,然而在实际工作应用中,集群数量并非3台,当遇到数十台甚至更多的服务器时,就不得不编写脚本来启动服务了,编写脚本的语言有多种,这里采用Shelli语言开发一键启动Zookeeper服务脚本, 使用vi创建start.zk.sh文件,如文件所示。
文件2-2 start _zk.sh
#!/bin/sh
for host in hadoop01 hadoop02 hadoop03
do
ssh $host "source /etc/profile;zkServer.sh start"
echo "$host zk is running"
done
执行该文件只需要输入"sh start._zk.sh" 即可启动集群中的Zookeeper服务。